 ¡Hola habitantes! Las computadoras cuánticas han provocado una nueva revolución informática y usted tiene una gran oportunidad de unirse al avance tecnológico en este momento. Los desarrolladores, especialistas en gráficos por computadora y aspirantes a profesionales de TI encontrarán información práctica sobre la computación cuántica que los programadores necesitan en este libro. En lugar de estudiar teoría y fórmulas, se centrará inmediatamente en problemas específicos que demuestren las capacidades únicas de la tecnología cuántica.
¡Hola habitantes! Las computadoras cuánticas han provocado una nueva revolución informática y usted tiene una gran oportunidad de unirse al avance tecnológico en este momento. Los desarrolladores, especialistas en gráficos por computadora y aspirantes a profesionales de TI encontrarán información práctica sobre la computación cuántica que los programadores necesitan en este libro. En lugar de estudiar teoría y fórmulas, se centrará inmediatamente en problemas específicos que demuestren las capacidades únicas de la tecnología cuántica.
Eric Johnston, Nick Harrigan y Mercedes Gimeno-Segovia ayudan a desarrollar las habilidades y la intuición necesarias, además de dominar las herramientas necesarias para crear aplicaciones cuánticas. Comprenderá de qué son capaces las computadoras cuánticas y cómo aplicarlo en la vida real. El libro consta de tres partes: - Programación QPU: conceptos básicos de programación de procesadores cuánticos, realización de operaciones con qubits y teletransportación cuántica. - Primitivas QPU: primitivas y métodos algorítmicos, amplificación de amplitud, transformada cuántica de Fourier y estimación de fase. - Práctica QPU: resolución de problemas específicos utilizando primitivas QPU, métodos de búsqueda cuántica y algoritmo de descomposición de Shor.
Estructura del libro
. , , (GPU), , .
— , QPU. , ( , ). (QPU) , QPU.
. I , .
I. QPU
, QPU: , , . QPU.
II. QPU
. , , . « », . , , QPU. QPU, , .
III. QPU
QPU — II — , QPU. .
, , , , .
— , QPU. , ( , ). (QPU) , QPU.
. I , .
I. QPU
, QPU: , , . QPU.
II. QPU
. , , . « », . , , QPU. QPU, , .
III. QPU
QPU — II — , QPU. .
, , , , .
Datos reales
Las aplicaciones QPU completas están diseñadas para trabajar con datos reales que no son de entrenamiento. Los datos reales no siempre se limitan a los números enteros básicos a los que hemos llegado hasta ahora. Por lo tanto, la cuestión de cómo representar datos más complejos en QPU vale la pena, y las buenas estructuras de datos pueden ser tan importantes como los buenos algoritmos. En este capítulo, intentaremos responder dos preguntas que se han pasado por alto anteriormente:
- ¿Cómo representar tipos de datos complejos en el registro QPU? Un número entero positivo se puede representar en codificación binaria simple. Pero, ¿qué pasa con los números irracionales o incluso los tipos de datos compuestos como vectores o matrices? Esta pregunta adquiere una nueva profundidad cuando consideramos que la superposición y la fase relativa pueden proporcionar nuevas opciones de codificación cuántica para estos tipos de datos.
- , QPU? , WRITE . , QPU . , , , QPU , .
Comencemos con la primera pregunta. Al describir las representaciones de QPU para tipos de datos de complejidad creciente, llegaremos a la introducción de estructuras de datos cuánticas completas y al concepto de memoria cuántica de acceso aleatorio (QRAM). Quantum RAM es un recurso fundamental para muchas aplicaciones prácticas de QPU.
El material de los capítulos siguientes dependerá en gran medida de las estructuras de datos presentadas en este capítulo. Por ejemplo, la denominada codificación de amplitud compleja que se describirá para los datos vectoriales es fundamental para todas las aplicaciones de aprendizaje automático cuántico presentadas en el Capítulo 13.
Datos inapropiados
¿Cómo codificar datos numéricos no enteros en el registro QPU? Las dos formas estándar de representar dichos valores en binario son las representaciones de coma fija y de coma flotante. Aunque la representación de punto flotante es más flexible (y adaptable al rango de valores que necesitan ser representados con un cierto número de bits), debido al alto valor de los qubits y nuestro deseo de simplicidad, la representación de punto fijo es un mejor lugar para comenzar.
Los números de punto fijo a menudo se describen en notación Q (desafortunadamente, Q en este caso no significa "cuántico"). Esto ayuda a eliminar la ambigüedad sobre dónde terminan los bits fraccionarios y comienzan los bits enteros. La notación Qn.m denota un registro de n bits, los m bits de los cuales son para la parte fraccionaria (y por lo tanto, el resto (n - m) contiene la parte entera). Por supuesto, puede usar la misma notación para especificar cómo se debe usar el registro QPU para codificar un número de punto fijo. Por ejemplo, en la Fig. 9.1 muestra un registro QPU de ocho qubit, que codifica el valor 3.640625 en la representación de coma fija Q8.6.
En el ejemplo dado, el número seleccionado se puede codificar con precisión en representación de punto fijo, porque 3.640625 =
 Por supuesto, esa suerte no siempre se encuentra. Aumentar el número de bits en la parte entera de un registro de punto fijo expande el rango de valores enteros que pueden ser representados por él, mientras que aumentar el número de bits en la parte fraccionaria mejora la precisión de la parte fraccionaria de un número. Cuantos más qubits haya en la parte fraccionaria, más probable es que alguna combinación
Por supuesto, esa suerte no siempre se encuentra. Aumentar el número de bits en la parte entera de un registro de punto fijo expande el rango de valores enteros que pueden ser representados por él, mientras que aumentar el número de bits en la parte fraccionaria mejora la precisión de la parte fraccionaria de un número. Cuantos más qubits haya en la parte fraccionaria, más probable es que alguna combinación 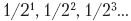 pueda representar con precisión el número dado.
pueda representar con precisión el número dado.

Aunque mencionaremos brevemente el uso de la representación de punto fijo en los próximos capítulos, juega un papel extremadamente importante en la experimentación con datos reales en pequeños registros de QPU. Cuando trabaje con diferentes métodos de codificación, debe monitorear cuidadosamente qué codificación específica se usó para los datos en un registro QPU particular para interpretar correctamente el estado de sus qubits.
QRAM
Los registros de QPU pueden almacenar representaciones de diferentes valores numéricos, pero ¿cómo se almacenan estos valores en ellos? Los datos inicializados a mano se vuelven obsoletos muy rápidamente. Lo que realmente necesitamos es la capacidad de leer valores de la memoria, obteniendo valores almacenados en una dirección binaria. El programador trabaja con la memoria de acceso aleatorio tradicional utilizando dos registros: uno se inicializa con una dirección de memoria y el otro permanece sin inicializar. La memoria de acceso aleatorio escribe en el segundo registro los datos binarios almacenados en la dirección especificada por el primer registro, como se muestra en la Fig. 9.2.
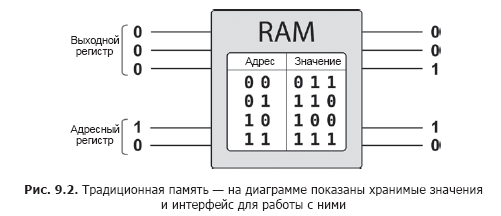
¿Se puede utilizar la memoria tradicional para almacenar los valores destinados a inicializar registros QPU? Por supuesto, la idea parece atractiva.
Si desea inicializar el registro QPU con solo un valor tradicional (complemento a dos, codificación de punto fijo o binario simple), entonces la RAM está bien. El valor deseado simplemente se almacena en la memoria, y write () y read () se utilizan para escribir o leer desde el registro QPU. Es este mecanismo limitado el que ha sido utilizado por el código JavaScript de QCEngine para interactuar con los registros de QPU hasta ahora.
Por ejemplo, el código de muestra del Listado 9.1, que recibe una matriz ay implementa la operación a [2] + = 1;, implícitamente obtiene esta matriz de valores de la RAM para inicializar el registro QPU. El circuito se muestra en la Fig. 9.3.

Código de muestra
Este ejemplo se puede hacer en línea en http://oreilly-qc.github.io?p=9-1.
Listado 9.1. Usando QPU para aumentar el número en memoria
var a = [4, 3, 5, 1];
qc.reset(3);
var qreg = qint.new(3, 'qreg');
qc.print(a);
increment(2, qreg);
qc.print(a);
function increment(index, qreg)
{
qreg.write(a[index]);
qreg.add(1);
a[index] = qreg.read();
}Vale la pena señalar que en este simple caso, no solo se usa la RAM tradicional para almacenar el entero, sino que también el procesador tradicional indexa la matriz para seleccionar y transmitir la QPU del valor deseado.
Aunque este uso de RAM permite que los registros de QPU se inicialicen a valores binarios simples, tiene serias limitaciones. ¿Qué sucede si necesita inicializar el registro QPU con la superposición de valores almacenados? Por ejemplo, suponga que en la RAM, el valor 3 (110) se almacena en la dirección 0x01 y el valor 5 (111) se almacena en la dirección 0x11. ¿Cómo preparo el registro de entrada en una superposición de estos dos valores?
Con la RAM tradicional y la torpe operación tradicional write (), esto no funcionará. Los procesadores cuánticos, al igual que sus antepasados de tubos, necesitarán fundamentalmente nuevos equipos de memoria, de naturaleza cuántica. Conozca Quantum Random Access Memory (QRAM) le permite leer y escribir datos a nivel cuántico. Ya hay algunas ideas sobre cómo construir físicamente QRAM, pero vale la pena señalar que la historia bien puede repetirse, y pueden aparecer procesadores cuánticos increíblemente poderosos mucho antes de que exista un hardware de memoria cuántica viable.
Vale la pena explicar con más precisión qué hace QRAM. Al igual que la memoria tradicional, QRAM recibe dos registros como entrada: el registro de dirección QPU para la dirección de memoria y el registro de salida QPU, que devuelve el valor almacenado en la dirección dada. Para QRAM, ambos registros se componen de qubits. Esto significa que en el registro de direcciones es posible establecer una superposición de celdas de memoria y, como consecuencia, obtener una superposición de los valores correspondientes en el registro de salida (Fig. 9.4).

Entonces QRAM realmente le permite leer los valores almacenados en superposición. Las amplitudes complejas exactas de la superposición que se obtendrán en el registro de salida están determinadas por la superposición proporcionada en el registro de direcciones. En la Fig. La Figura 9.2 muestra las diferencias cuando se realiza la misma operación de incremento en el Listado 9.1 (Figura 9.5), pero usando QRAM para acceder a los datos en lugar de las operaciones de lectura / escritura de QPU. La letra "A" denota el registro en el que se transmite la dirección QRAM (o superposición). La letra "D" denota el registro en el que QRAM devuelve la superposición correspondiente de valores almacenados (datos).
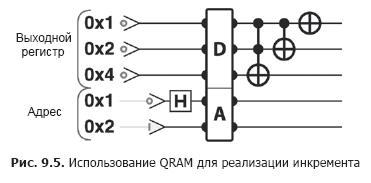
Código de muestra
Este ejemplo se puede hacer en línea en oreilly-qc.github.io?p=9-2 .
Listado 9.2. Usar QPU para incrementar un número de QRAM: el registro de dirección puede contener superposición, lo que hará que el registro de salida contenga una superposición de valores almacenados
var a = [4, 3, 5, 1];
var reg_qubits = 3;
qc.reset(2 + reg_qubits + qram_qubits());
var qreg = qint.new(3, 'qreg');
var addr = qint.new(2, 'addr');
var qram = qram_initialize(a, reg_qubits);
qreg.write(0);
addr.write(2);
addr.hadamard(0x1);
qram_load(addr, qreg);
qreg.add(1);Esta descripción de QRAM puede parecer demasiado vaga: ¿qué es el hardware de memoria cuántica? En este libro, no daremos una descripción de cómo construir QRAM en la práctica (ya que, por ejemplo, la mayoría de los libros sobre C ++ no proporcionan una descripción detallada de cómo funciona la memoria tradicional). Los ejemplos de código como el del Listado 9.2 se ejecutan utilizando un modelo simplificado que imita el comportamiento de QRAM. Sin embargo, existen prototipos de tecnologías QRAM.
Si bien la memoria cuántica será un componente crítico de cualquier QPU serio, es probable que los detalles de implementación cambien, como con cualquier dispositivo de computación cuántica. Lo importante para nosotros es la idea misma de un recurso fundamental que se comporta como se muestra en la Fig. 9.4 y las potentes aplicaciones que se pueden construir sobre él.
Con la memoria cuántica a su disposición, puede pasar a la construcción de estructuras complejas de datos cuánticos. De particular interés son las estructuras que le permiten representar datos vectoriales y matriciales.
Codificación vectorial
Supongamos que desea inicializar el registro QPU para representar un vector simple como la Ecuación 9.1.
Fórmula 9.1. Un ejemplo de un vector para inicializar el registro QPU.

Los datos en esta forma se encuentran a menudo en aplicaciones de aprendizaje automático cuántico.
Quizás el método más obvio para codificar datos vectoriales es representar cada componente como un registro QPU separado con una representación binaria adecuada. A este método (probablemente el más obvio) lo llamaremos codificación de estado para vectores. El vector del ejemplo anterior se puede codificar en cuatro registros de dos qubit, como se muestra en la Fig. 9.6.

Uno de los problemas con la codificación de estado ingenua es que desperdicia qubits, el recurso más valioso de una QPU. Sin embargo, una de las ventajas de los vectores codificados por estado tradicionales es que no requieren memoria cuántica. Los componentes vectoriales se pueden almacenar simplemente en la memoria estándar y sus valores separados se pueden usar para controlar la preparación de cada registro QPU individual. Pero esta ventaja también subyace a la falla más seria en la codificación de estado vectorial: almacenar datos vectoriales de esta manera tradicional nos impide usar las capacidades no tradicionales de las QPU. Para aprovechar el poder de QPU, debe poder manipular las fases relativas de las superposiciones, y esto no es fácil de hacer.¡si cada componente de un vector realmente trata su procesador cuántico como una colección de registros binarios tradicionales!
En cambio, necesitas descender al nivel cuántico. Suponga que los componentes vectoriales se almacenan en la superposición de las amplitudes de un registro QPU. Dado que un registro QPU de n qubits puede existir en una superposición con 2n amplitudes (y por lo tanto, habrá 2n círculos para experimentos con registro circular), es posible representar la codificación de un vector con n componentes en un registro QPU con ceil (log (n)) qubits.
Para el ejemplo de vector de la Fórmula 9.1, este enfoque requeriría un registro de dos qubit; la idea es encontrar un circuito cuántico adecuado para codificar los datos vectoriales en la Figura 1. 9,7.

Llamemos a esta codificación de datos vectoriales cuánticos únicos codificación de amplitud compleja. Es importante apreciar las diferencias entre la codificación de amplitud compleja y la codificación de estado más convencional. Mesa 9.1 compara los dos métodos de codificación para diferentes datos vectoriales. El último ejemplo de codificación de estado necesitará cuatro registros de 7 bits, cada uno de los cuales utiliza una representación de punto fijo de Q7.7.
Cuadro 9.1. Diferencias entre los métodos de codificación de datos vectoriales (codificación de amplitud compleja y codificación de estado)

Para obtener vectores con codificación de amplitud compleja en QCEngine, puede utilizar la conveniente función amplitude_encode (). El programa del Listado 9.3 toma un vector de valores y una referencia a un registro QPU (que debe ser lo suficientemente grande) y prepara ese registro realizando una codificación de amplitud compleja en el vector.
Código de muestra
Este ejemplo se puede hacer en línea en oreilly-qc.github.io?p=9-3 .
Listado 9.3. Preparación de vectores con codificación de amplitud compleja en QCEngine
// ,
// 2
var vector = [-1.0, 1.0, 1.0, 5.0, 5.0, 6.0, 6.0, 6.0];
//
//
var num_qubits = Math.log2(vector.length);
qc.reset(num_qubits);
var amp_enc_reg = qint.new(num_qubits, 'amp_enc_reg');
// amp_enc_reg
amplitude_encode(vector, amp_enc_reg);En este ejemplo, el vector simplemente se pasa como una matriz de JavaScript almacenada en la memoria tradicional, aunque hemos indicado que la codificación de amplitud compleja depende de QRAM. ¿Cómo realiza QCEngine la codificación de amplitud compleja cuando solo la RAM de su computadora está disponible para el programa? Si bien es posible generar un esquema de codificación de amplitud complejo sin QRAM, ciertamente no se puede hacer de manera eficiente. QCEngine proporciona un modelo lento pero viable de lo que se puede lograr con el acceso QRAM.
Limitaciones de la codificación de amplitud compleja
La idea detrás de la codificación de amplitud compleja se ve muy bien al principio: utiliza menos qubits y proporciona herramientas cuánticas para trabajar con datos vectoriales. En cualquier aplicación que utilice este mecanismo, hay dos factores importantes a considerar.
Problema 1: resultados cuánticos
Es posible que ya haya notado la primera de estas restricciones: las superposiciones cuánticas generalmente no se pueden leer con READ. ¡Nuestro principal enemigo de nuevo! Si distribuye los componentes vectoriales sobre la superposición cuántica, no se pueden volver a leer. Naturalmente, esto no crea ningún problema especial al transferir datos vectoriales a la entrada de otro programa QPU desde la memoria. Pero muy a menudo, las aplicaciones QPU que reciben datos vectoriales complejos codificados en AM en la entrada también generarán datos vectoriales complejos codificados en AM en la salida.
Por lo tanto, el uso de codificación de amplitud compleja limita severamente nuestra capacidad para leer la salida de aplicaciones con una operación READ. Afortunadamente, a menudo es posible extraer información útil de resultados complejos de codificación de amplitud. Como verá en los siguientes capítulos, aunque no puede reconocer los componentes individuales, puede averiguar las propiedades globales de los vectores codificados de esta manera. Sin embargo, la codificación de amplitud compleja no es una panacea y su aplicación exitosa requiere atención e ingenio.
Problema 2: el requisito de normalizar vectores
El segundo problema asociado con la codificación de amplitud compleja está oculto en la tabla. 9.1. Observe más de cerca la codificación de amplitud compleja de los dos primeros vectores de la tabla: [0,1,2,3] y [6,1,1,4]. ¿Pueden las amplitudes complejas de un registro QPU de dos qubit tomar los valores [0,1,2,3] o los valores [6,1,1,4]? Lamentablemente no. En capítulos anteriores, generalmente hemos pasado por alto la discusión de amplitudes y fases relativas en favor de una notación circular más intuitiva. Si bien este enfoque fue más intuitivo, lo protegió de una regla numérica importante sobre amplitudes complejas: los cuadrados de las amplitudes complejas de un registro deben sumar 1. Este requisito, llamado normalización, tiene sentido cuando recuerda que los cuadrados de las amplitudes en el registro corresponden a las probabilidades de lectura. diferentes resultados.Dado que se debe obtener un resultado, estas probabilidades (y, en consecuencia, los cuadrados de todas las amplitudes complejas) deben sumar 1. Cuando se usa una notación circular conveniente, es fácil olvidarse de la normalización, pero impone una restricción importante sobre qué vector Se puede aplicar una codificación de amplitud compleja a los datos. Las leyes de la física no permiten crear un registro que esté en superposición con amplitudes complejas [0,1,2,3] o [6,1,1,4].estando en superposición con amplitudes complejas [0,1,2,3] o [6,1,1,4].estando en superposición con amplitudes complejas [0,1,2,3] o [6,1,1,4].
Aplicar codificación de amplitud compleja a dos vectores de problemas de la Tabla. 9.1, primero debe normalizarlos dividiendo cada componente por la suma de los cuadrados de todos los componentes. Por ejemplo, en la codificación de amplitud compleja del vector [0,1,2,3], primero debe dividir todos los componentes por 3,74 para obtener un vector normalizado [0,00, 0,27, 0,53, 0,80], que ahora es adecuado para codificar en amplitudes de superposición complejas.
¿La normalización de datos vectoriales tiene algún efecto no deseado? ¡Parece que los datos han cambiado por completo! De hecho, la normalización deja la mayor parte de la información importante sin cambios (en la representación geométrica, simplemente escala la longitud del vector, dejando la dirección sin cambios). ¿Podemos asumir que los datos normalizados reemplazan completamente a los datos originales? Depende de las necesidades de la aplicación QPU particular en la que pretenda utilizarlos. Recuerde que puede almacenar el valor numérico del factor de normalización en un registro diferente si es necesario.
Codificación de amplitud compleja y grabación circular
A medida que empiece a pensar más específicamente en los valores numéricos de las amplitudes complejas de los registros, puede ser útil recordar cómo se representan las amplitudes complejas en notación circular y darse cuenta de un posible error. Las áreas rellenas en notación circular representan los cuadrados de las amplitudes de las amplitudes complejas del estado cuántico. En situaciones como la codificación de amplitud compleja, donde las amplitudes complejas deben representar los componentes de un vector con valores reales, esto significa que las áreas llenas están determinadas por el cuadrado del componente del vector correspondiente, y no por el componente en sí. En la Fig. 9.8 muestra cómo interpretar correctamente la representación del vector [0,1,2,3] después de la normalización en notación circular.

Ahora sabe lo suficiente sobre los vectores complejos codificados en amplitud para comprender las aplicaciones de QPU que se presentarán en el libro. Pero para muchas aplicaciones, especialmente las relacionadas con el aprendizaje automático cuántico, es necesario ir un paso más allá y utilizar QPU para manipular no solo vectores, sino también matrices de datos completas. ¿Cómo se codifican matrices de números bidimensionales?
»Más detalles sobre el libro se pueden encontrar en el sitio web de la editorial
» Tabla de contenido
» Extracto
para los habitantes un 25% de descuento en el cupón - Programación
Tras el pago de la versión impresa del libro, se envía un libro electrónico al correo electrónico.