
El propósito de este artículo es compartir nuestra primera experiencia con MLflow .
Comenzaremos nuestra revisión de MLflow desde su servidor de seguimiento y continuaremos con todas las iteraciones del estudio. Luego, compartiremos nuestra experiencia de conectar Spark a MLflow usando UDF.
Contexto
En Alpha Health, utilizamos el aprendizaje automático y la inteligencia artificial para capacitar a las personas para que se ocupen de su salud y bienestar. Es por eso que los modelos de aprendizaje automático están en el corazón de los productos de datos que desarrollamos, razón por la cual nuestra atención se centró en MLflow, una plataforma de código abierto que cubre todos los aspectos del ciclo de vida del aprendizaje automático.
MLflow
El objetivo principal de MLflow es proporcionar una capa adicional sobre el aprendizaje automático que permitiría a los científicos de datos trabajar con casi cualquier biblioteca de aprendizaje automático ( h2o , keras , mleap , pytorch , sklearn y tensorflow ), llevando su trabajo al siguiente nivel.
MLflow proporciona tres componentes:
- Seguimiento : registro y consulta de experimentos: código, datos, configuración y resultados. Es muy importante seguir el proceso de creación del modelo.
- Proyectos : formato de empaquetado para ejecutar en cualquier plataforma (por ejemplo, SageMaker )
- Modelos es un formato común para enviar modelos a varias herramientas de implementación.
MLflow (alfa en el momento de escribir este artículo) es una plataforma de código abierto que le permite administrar el ciclo de vida del aprendizaje automático, incluida la experimentación, la reutilización y la implementación.
Configurar MLflow
Para usar MLflow, primero debe configurar todo el entorno de Python, para eso usaremos PyEnv (para instalar Python en Mac, eche un vistazo aquí ). Entonces podemos crear un entorno virtual donde instalaremos todas las bibliotecas necesarias para ejecutar.
```
pyenv install 3.7.0
pyenv global 3.7.0 # Use Python 3.7
mkvirtualenv mlflow # Create a Virtual Env with Python 3.7
workon mlflow
```Instale las bibliotecas necesarias.
```
pip install mlflow==0.7.0 \
Cython==0.29 \
numpy==1.14.5 \
pandas==0.23.4 \
pyarrow==0.11.0
```Nota: estamos usando PyArrow para ejecutar modelos como UDF. Las versiones de PyArrow y Numpy debían arreglarse ya que las últimas versiones estaban en conflicto.
Iniciar la interfaz de usuario de seguimiento
MLflow Tracking nos permite registrar y realizar solicitudes de experimentos utilizando Python y API REST . Además, puede definir dónde almacenar los artefactos del modelo (localhost, Amazon S3 , Azure Blob Storage , Google Cloud Storage o servidor SFTP ). Dado que usamos AWS en Alpha Health, S3 se utilizará como almacenamiento para los artefactos.
# Running a Tracking Server
mlflow server \
--file-store /tmp/mlflow/fileStore \
--default-artifact-root s3://<bucket>/mlflow/artifacts/ \
--host localhost
--port 5000MLflow recomienda usar almacenamiento de archivos persistente. El almacenamiento de archivos es donde el servidor almacenará los metadatos de ejecución y experimentación. Al iniciar el servidor, asegúrese de que apunte al almacenamiento de archivos persistente. Aquí solo lo usaremos para experimentar
/tmp.
Recuerde que si queremos usar el servidor mlflow para ejecutar experimentos antiguos, deben estar presentes en el almacén de archivos. Sin embargo, incluso sin esto, podríamos usarlos en la UDF, ya que solo necesitamos la ruta al modelo.
Nota: Tenga en cuenta que la IU de seguimiento y el cliente modelo deben tener acceso a la ubicación del artefacto. Es decir, independientemente del hecho de que la IU de seguimiento esté ubicada en la instancia EC2, cuando MLflow se inicia localmente, la máquina debe tener acceso directo a S3 para escribir modelos de artefactos.
La IU de seguimiento almacena artefactos en un depósito de S3
Ejecutando modelos
Una vez que el servidor de seguimiento se esté ejecutando, puede comenzar a entrenar los modelos.
Como ejemplo, usaremos la modificación de vino del ejemplo de MLflow en Sklearn .
MLFLOW_TRACKING_URI=http://localhost:5000 python wine_quality.py \
--alpha 0.9
--l1_ration 0.5
--wine_file ./data/winequality-red.csvComo ya dijimos, MLflow le permite registrar parámetros, métricas y artefactos de modelos para que pueda rastrear cómo se desarrollan a medida que itera. Esta característica es extremadamente útil, porque de esta manera podemos reproducir el mejor modelo contactando al servidor de seguimiento o entendiendo qué código ha realizado la iteración requerida usando los registros de confirmación de hash de git.
with mlflow.start_run():
... model ...
mlflow.log_param("source", wine_path)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.set_tag('domain', 'wine')
mlflow.set_tag('predict', 'quality')
mlflow.sklearn.log_model(lr, "model")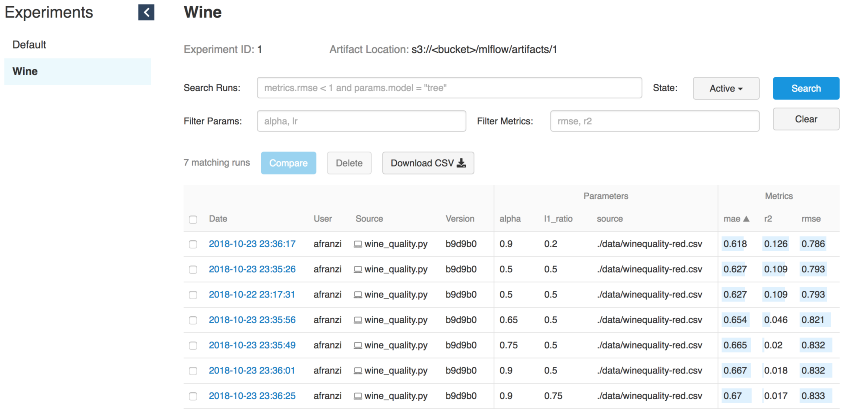
Iteraciones de vino
Parte del servidor para el modelo
El servidor de seguimiento MLflow, iniciado con el comando "mlflow server", tiene una API REST para realizar un seguimiento de los lanzamientos y escribir datos en el sistema de archivos local. Puede especificar la dirección del servidor de seguimiento mediante la variable de entorno "MLFLOW_TRACKING_URI" y la API de seguimiento de MLflow se comunicará automáticamente con el servidor de seguimiento en esta dirección para crear / obtener información de lanzamiento, métricas de registro, etc.Para proporcionar un servidor al modelo, necesitamos un servidor de seguimiento en ejecución (consulte la interfaz de inicio) y un ID de ejecución del modelo.
Fuente: Docs // Ejecutando un servidor de seguimiento

Ejecutar ID
# Serve a sklearn model through 127.0.0.0:5005
MLFLOW_TRACKING_URI=http://0.0.0.0:5000 mlflow sklearn serve \
--port 5005 \
--run_id 0f8691808e914d1087cf097a08730f17 \
--model-path modelPara servir modelos utilizando la funcionalidad de servicio MLflow, necesitamos acceso a la IU de seguimiento para obtener información sobre el modelo simplemente especificando
--run_id.
Una vez que el modelo se comunica con el servidor de seguimiento, podemos obtener el nuevo modelo de punto final.
# Query Tracking Server Endpoint
curl -X POST \
http://127.0.0.1:5005/invocations \
-H 'Content-Type: application/json' \
-d '[
{
"fixed acidity": 3.42,
"volatile acidity": 1.66,
"citric acid": 0.48,
"residual sugar": 4.2,
"chloridessssss": 0.229,
"free sulfur dsioxide": 19,
"total sulfur dioxide": 25,
"density": 1.98,
"pH": 5.33,
"sulphates": 4.39,
"alcohol": 10.8
}
]'
> {"predictions": [5.825055635303461]}Ejecución de modelos de Spark
A pesar de que el servidor de seguimiento es lo suficientemente potente como para servir modelos en tiempo real, entrenarlos y usar la funcionalidad de servicio (fuente: mlflow // docs // modelos # local ), usar Spark (por lotes o transmisión) es una solución aún más poderosa para cuenta de distribución.
Imagine que acaba de realizar un entrenamiento sin conexión y luego aplica el modelo de salida a todos sus datos. Aquí es donde Spark y MLflow mostrarán lo mejor.
Instalar PySpark + Jupyter + Spark
Fuente: Comenzar PySpark - Jupyter
Para mostrar cómo aplicamos los modelos MLflow a los marcos de datos de Spark, necesitamos configurar los cuadernos de Jupyter para que funcionen junto con PySpark.
Comience instalando la última versión estable de Apache Spark :
cd ~/Downloads/
tar -xzf spark-2.4.3-bin-hadoop2.7.tgz
mv ~/Downloads/spark-2.4.3-bin-hadoop2.7 ~/
ln -s ~/spark-2.4.3-bin-hadoop2.7 ~/spark̀Instale PySpark y Jupyter en un entorno virtual:
pip install pyspark jupyterConfigure las variables de entorno:
export SPARK_HOME=~/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook --notebook-dir=${HOME}/Projects/notebooks"Una vez determinado
notebook-dir, podemos almacenar nuestros cuadernos en la carpeta deseada.
Lanzamiento de Jupyter desde PySpark
Como pudimos configurar Jupiter como el controlador de PySpark, ahora podemos ejecutar cuadernos de Jupyter en el contexto de PySpark.
(mlflow) afranzi:~$ pyspark
[I 19:05:01.572 NotebookApp] sparkmagic extension enabled!
[I 19:05:01.573 NotebookApp] Serving notebooks from local directory: /Users/afranzi/Projects/notebooks
[I 19:05:01.573 NotebookApp] The Jupyter Notebook is running at:
[I 19:05:01.573 NotebookApp] http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
[I 19:05:01.573 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 19:05:01.574 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
Como se mencionó anteriormente, MLflow proporciona una función para registrar artefactos de modelos en S3. Tan pronto como tengamos el modelo seleccionado en nuestras manos, tendremos la oportunidad de importarlo como UDF usando el módulo
mlflow.pyfunc.
import mlflow.pyfunc
model_path = 's3://<bucket>/mlflow/artifacts/1/0f8691808e914d1087cf097a08730f17/artifacts/model'
wine_path = '/Users/afranzi/Projects/data/winequality-red.csv'
wine_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = spark.read.format("csv").option("header", "true").option('delimiter', ';').load(wine_path)
columns = [ "fixed acidity", "volatile acidity", "citric acid",
"residual sugar", "chlorides", "free sulfur dioxide",
"total sulfur dioxide", "density", "pH",
"sulphates", "alcohol"
]
df.withColumn('prediction', wine_udf(*columns)).show(100, False)
PySpark: generación de predicciones de calidad del vino
Hasta este punto, hemos hablado sobre cómo usar PySpark con MLflow ejecutando predicciones de calidad del vino en todo el conjunto de datos del vino. Pero, ¿qué sucede si necesita utilizar módulos Python MLflow de Scala Spark?
También probamos esto dividiendo el contexto Spark entre Scala y Python. Es decir, registramos MLflow UDF en Python y lo usamos desde Scala (sí, tal vez no sea la mejor solución, pero la que tenemos).
Scala Spark + MLflow
Para este ejemplo, agregaremos el núcleo de Toree al Júpiter existente.
Instalar Spark + Toree + Jupyter
pip install toree
jupyter toree install --spark_home=${SPARK_HOME} --sys-prefix
jupyter kernelspec list
```
```
Available kernels:
apache_toree_scala /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/apache_toree_scala
python3 /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/python3
```Como puede ver en el cuaderno adjunto, la UDF se comparte entre Spark y PySpark. Esperamos que esta parte sea útil para aquellos que aman Scala y desean implementar modelos de aprendizaje automático en producción.
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{Column, DataFrame}
import scala.util.matching.Regex
val FirstAtRe: Regex = "^_".r
val AliasRe: Regex = "[\\s_.:@]+".r
def getFieldAlias(field_name: String): String = {
FirstAtRe.replaceAllIn(AliasRe.replaceAllIn(field_name, "_"), "")
}
def selectFieldsNormalized(columns: List[String])(df: DataFrame): DataFrame = {
val fieldsToSelect: List[Column] = columns.map(field =>
col(field).as(getFieldAlias(field))
)
df.select(fieldsToSelect: _*)
}
def normalizeSchema(df: DataFrame): DataFrame = {
val schema = df.columns.toList
df.transform(selectFieldsNormalized(schema))
}
FirstAtRe = ^_
AliasRe = [\s_.:@]+
getFieldAlias: (field_name: String)String
selectFieldsNormalized: (columns: List[String])(df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
normalizeSchema: (df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
Out[1]:
[\s_.:@]+
In [2]:
val winePath = "~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv"
val modelPath = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
winePath = ~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv
modelPath = /tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
Out[2]:
/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
In [3]:
val df = spark.read
.format("csv")
.option("header", "true")
.option("delimiter", ";")
.load(winePath)
.transform(normalizeSchema)
df = [fixed_acidity: string, volatile_acidity: string ... 10 more fields]
Out[3]:
[fixed_acidity: string, volatile_acidity: string ... 10 more fields]
In [4]:
%%PySpark
import mlflow
from mlflow import pyfunc
model_path = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
wine_quality_udf = mlflow.pyfunc.spark_udf(spark, model_path)
spark.udf.register("wineQuality", wine_quality_udf)
Out[4]:
<function spark_udf.<locals>.predict at 0x1116a98c8>
In [6]:
df.createOrReplaceTempView("wines")
In [10]:
%%SQL
SELECT
quality,
wineQuality(
fixed_acidity,
volatile_acidity,
citric_acid,
residual_sugar,
chlorides,
free_sulfur_dioxide,
total_sulfur_dioxide,
density,
pH,
sulphates,
alcohol
) AS prediction
FROM wines
LIMIT 10
Out[10]:
+-------+------------------+
|quality| prediction|
+-------+------------------+
| 5| 5.576883967129615|
| 5| 5.50664776916154|
| 5| 5.525504822954496|
| 6| 5.504311247097457|
| 5| 5.576883967129615|
| 5|5.5556903912725755|
| 5| 5.467882654744997|
| 7| 5.710602976324739|
| 7| 5.657319539336507|
| 5| 5.345098606538708|
+-------+------------------+
In [17]:
spark.catalog.listFunctions.filter('name like "%wineQuality%").show(20, false)
+-----------+--------+-----------+---------+-----------+
|name |database|description|className|isTemporary|
+-----------+--------+-----------+---------+-----------+
|wineQuality|null |null |null |true |
+-----------+--------+-----------+---------+-----------+
Próximos pasos
Aunque MLflow está en Alpha en el momento de escribir este artículo, parece bastante prometedor. La mera capacidad de ejecutar múltiples marcos de aprendizaje automático y usarlos desde un solo punto final lleva los sistemas de recomendación al siguiente nivel.
Además, MLflow acerca a los ingenieros de datos y a los científicos de datos al crear una capa común entre ellos.
Después de hacer esta investigación sobre MLflow, estamos seguros de que seguiremos adelante y lo usaremos para nuestras canalizaciones Spark y sistemas de recomendación.
Sería bueno sincronizar el almacenamiento de archivos con la base de datos en lugar del sistema de archivos. De esta manera, necesitamos obtener varios puntos finales que puedan usar el mismo almacenamiento de archivos. Por ejemplo, use varias instancias de Prestoy Athena con la misma tienda de Glue.
Para resumir, me gustaría agradecer a la comunidad de MLFlow por hacer que nuestro trabajo con datos sea más interesante.
Si está jugando con MLflow, no dude en escribirnos y decirnos cómo lo usa, y más aún si lo usa en producción.
Obtenga más información sobre los cursos:
aprendizaje automático. Curso básico de
aprendizaje automático. Curso avanzado
Lee mas:
- Riesgos y advertencias al aplicar el método de componentes principales a problemas de aprendizaje supervisado
- Implementación de un modelo de aprendizaje automático con Docker - Parte 1
- Implementación de un modelo de aprendizaje automático con Docker - Parte 2