Pero todas estas soluciones no tenían lo que necesitaba:
- Instalación centralizada
- Resultados de búsqueda teniendo en cuenta los derechos de acceso
- Buscar por contenido del documento
- Morfología
Y decidí hacer el mío.
Revelaré punto por punto lo que tengo en el formulario para evitar diferencias de interpretación y malos entendidos.
Instalación centralizada: ejecución cliente-servidor. Todas las soluciones anteriores tienen un problema fundamental: cada usuario crea su propio índice de búsqueda local, que, en el caso de grandes volúmenes de almacenamiento, retrasa la indexación, el perfil del usuario en la máquina crece y, en general, es inconveniente en el caso de que un nuevo empleado llegue o se mude a una nueva máquina.
Resultados de la búsqueda teniendo en cuenta los derechos; aquí todo es simple; los resultados deben corresponder a los derechos del empleado sobre el recurso del archivo. De lo contrario, resulta que incluso si el empleado no tiene derechos sobre el recurso, puede leer todo desde el caché de búsqueda. Va a resultar incómodo, ¿de acuerdo? Busque por el contenido del documento - busque por el texto del documento, todo es obvio, me parece, y no puede haber discrepancias.
La morfología es aún más sencilla. Especificado en la consulta "cuchillo" y recibió tanto "cuchillo" y "cuchillos", "cuchillo" y "cuchillo". Es deseable que esto funcione para ruso e inglés.
Hemos decidido la formulación del problema, podemos proceder a la implementación.
Como motor de búsqueda, elegí el sistema Sphinx, y el lenguaje de desarrollo de la interfaz fue C # y .net, y como resultado el proyecto se llamó Vidocq (Vidocq) por el nombre del detective francés. Bueno, encuentra todo y eso es todo.
Arquitectónicamente, la aplicación se ve así: el
robot de búsqueda rastrea de forma recursiva el recurso de archivo y procesa los archivos de acuerdo con la lista de extensiones especificada. El procesamiento consiste en recuperar el contenido del archivo, comprimir el texto: se eliminan las comillas, comas, espacios adicionales, etc. del texto, luego se coloca el contenido en la base de datos (MS SQL), se marca la fecha de colocación y el robot sigue adelante.
El indexador de Sphinsa trabaja directamente con la base recibida, formando su propio índice y devolviendo un puntero al archivo encontrado y un fragmento del fragmento de texto encontrado como respuesta.
Se desarrolló un formulario en C # que se comunicaba con Sphinx a través del conector MySQL. Sphinx proporciona una matriz de archivos de acuerdo con la solicitud, luego la matriz se filtra por el derecho de acceso del usuario que está buscando, la salida se formatea y se muestra al usuario.
Necesitamos almacenar la siguiente información sobre el archivo:
- ID de archivo
- Nombre del archivo
- La ruta al archivo
- Contenido del archivo
- Expansión
- Fecha agregada a la base de datos
Todo esto se hace en una tabla y el robot de búsqueda agregará todo. La fecha de adición es necesaria para que cuando el robot en la siguiente ronda compare la fecha de la modificación del archivo con la fecha en que se colocó en la base de datos, y si las fechas difieren, actualice la información sobre el archivo.
Luego configure el motor de búsqueda. No describiré la configuración completa, estará disponible en el archivo del proyecto, pero solo cubriré los puntos principales.
La solicitud principal que forma la base de
documentos fuente: base_documentos
{
sql_query = \
select \
DocumentId as 'Id', \
DocumentPath as 'Path', \
DocumentTitle as 'Title', \
DocumentExtention as 'Extension', \
DocumentContent as 'Content' \
from \
VidocqDocs
}Configurando la morfología a través de un lematizador.
index documents
{
source = documents
path = D:/work/VidocqSearcher/Sphinx/data/index
morphology = lemmatize_ru_all, lemmatize_en_all
}Después de eso, puede colocar el indexador en la base y verificar el trabajo.
d:\work\VidocqSearcher\Sphinx\bin\indexer.exe documents --config D:\work\VidocqSearcher\Sphinx\bin\main.conf –rotateAquí, la ruta al indexador es seguida por el nombre del índice en el que colocar el procesado, la ruta a la configuración y el indicador –rotate significa que la indexación se realizará con una ganancia, es decir. con el servicio de búsqueda en ejecución. Una vez completada la indexación, el índice se reemplazará por el actualizado.
Comprobamos el trabajo en la consola. Como interfaz, puede utilizar un cliente MySQL, tomado, por ejemplo, del kit del servidor web.
mysql -h 127.0.0.1 -P 9306después de esa solicitud, seleccione la identificación de los documentos; debería devolver una lista de documentos indexados, si, por supuesto, inició el servicio Sphinx en sí e hizo todo bien.
Está bien, la consola es genial, pero no vamos a obligar a los usuarios a escribir comandos, ¿verdad?
Esbocé un formulario como este
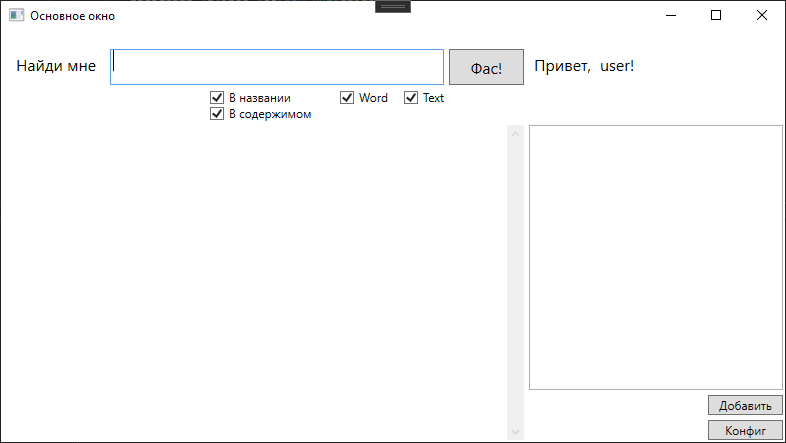
Y aquí con los resultados de la búsqueda.

Cuando haces clic en un resultado específico, se abre un documento.
Cómo se implementó.
using MySql.Data.MySqlClient;
string connectionString = "Server=127.0.0.1;Port=9306";
var query = "select id, title, extension, path, snippet(content, '" + textBoxSearch.Text.Trim() + "', 'query_mode=1') as snippet from documents " +
"where ";
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == true)
{
query += "match ('@(title,content)" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == false && checkBoxContent.IsChecked == true)
{
query += "match ('@content" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == false)
{
query += "match ('@title" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == true)
{
query += "and extension in ('.docx', '.doc', '.txt');";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == false)
{
query += "and extension in ('.docx', '.doc');";
}
if (checkBoxWord.IsChecked == false && checkBoxText.IsChecked == true)
{
query += "and extension in ('.txt');";
}Sí, hay un código bydloc, pero este es un MVP.
En realidad, aquí se forma una solicitud a la Esfinge, dependiendo de las casillas de verificación establecidas. Las casillas de verificación indican el tipo de archivos en los que buscar y el área de búsqueda.
Luego, la solicitud va a la Sphinx y luego se analiza el resultado.
using (var command = new MySqlCommand(query, connection))
{
connection.Open();
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
var id = reader.GetUInt16("id");
var title = reader.GetString("title");
var path = reader.GetString("path");
var extension = reader.GetString("extension");
var snippet = reader.GetString("snippet");
bool isFileExist = File.Exists(path);
if (isFileExist == true)
{
System.Windows.Controls.RichTextBox textBlock = new RichTextBox();
textBlock.IsReadOnly = true;
string xName = "id" + id.ToString();
textBlock.Name = xName;
textBlock.Tag = path;
textBlock.GotFocus += new System.Windows.RoutedEventHandler(ShowClickHello);
snippet = System.Text.RegularExpressions.Regex.Replace(snippet, "<.*?>", String.Empty);
Paragraph paragraph = new Paragraph();
paragraph.Inlines.Add(new Bold(new Run(path + "\r\n")));
paragraph.Inlines.Add(new Run(snippet));
textBlock.Document = new FlowDocument(paragraph);
StackPanelResult.Children.Add(textBlock);
}
else
{
counteraccess--;
}
}
}
}En la misma etapa, se genera el problema. Cada elemento del problema es un cuadro de texto enriquecido con un evento para abrir un documento al hacer clic. Los elementos se colocan en el StackPanel y antes de que el usuario compruebe el archivo. Por lo tanto, un archivo inaccesible para el usuario no se incluirá en la salida.
Las ventajas de esta solución:
- La indexación se realiza de forma centralizada
- Visualización precisa basada en derechos de acceso
- Búsqueda personalizable por tipo de documento
Por supuesto, para el funcionamiento completo de dicha solución, un archivo de archivo debe estar organizado correctamente en la empresa. Idealmente, deberían configurarse perfiles de usuario itinerantes, etc. Y sí, conozco SharePoint, Windows Search y probablemente algunas soluciones más. Luego, puede discutir interminablemente la elección de una plataforma de desarrollo, el motor de búsqueda Sphinx, Manticore o Elastic, etc. Pero fue interesante para mí resolver el problema con las herramientas en las que entiendo un poco. Actualmente se está ejecutando en modo MVP, pero lo estoy desarrollando.
Pero en cualquier caso, estoy dispuesto a escuchar sus sugerencias sobre qué puntos se pueden mejorar o rehacer de raíz.