Le diremos por qué apareció esta herramienta y qué puede hacer.

Falta de algoritmos
Uno de los desafíos clave en el aprendizaje automático es la reducción de la dimensionalidad de los datos. Los científicos de datos reducen el número de variables aislando entre ellas los valores que tienen el mayor impacto en el resultado. Después de esta operación, el modelo de aprendizaje automático requiere menos memoria, funciona más rápido y mejor. El siguiente ejemplo muestra que la eliminación de características duplicadas aumenta la precisión de la clasificación de 0.903 a 0.943.
>>> from sklearn.linear_model import SGDClassifier
>>> from ITMO_FS.embedded import MOS
>>> X, y = make_classification(n_samples=300, n_features=10, random_state=0, n_informative=2)
>>> sel = MOS()
>>> trX = sel.fit_transform(X, y, smote=False)
>>> cl1 = SGDClassifier()
>>> cl1.fit(X, y)
>>> cl1.score(X, y)
0.9033333333333333
>>> cl2 = SGDClassifier()
>>> cl2.fit(trX, y)
>>> cl2.score(trX, y)
0.9433333333333334Hay dos enfoques para la reducción de dimensionalidad: diseño de características y selección de características. En campos como la bioinformática y la medicina, este último se usa a menudo, ya que permite resaltar características significativas conservando la semántica, es decir, no cambia el significado original de las características. Sin embargo, las bibliotecas de aprendizaje automático de Python más comunes ( scikit-learn, pytorch, keras, tensorflow ) carecen de un conjunto completo de métodos de selección de funciones.
Para resolver este problema, los estudiantes y posgrados de la Universidad ITMO han desarrollado una biblioteca abierta: ITMO_FS. Un equipo está trabajando en ello bajo el liderazgo de Ivan Smetannikov, profesor asociado de la Facultad de Tecnologías de la Información y Programación., Subdirector del laboratorio de aprendizaje automático. Desarrollador principal: Nikita Pilnenskiy, se graduó de la maestría en aprendizaje automático y análisis de datos . Ahora va a la escuela de posgrado.
« , . , , , (-) .
, , , . , , , ».
—
ITMO_FS está implementado en Python y es compatible con scikit-learn, que se considera la principal herramienta de análisis de datos de facto. Sus selectores de funciones toman los mismos parámetros:
data: array-like (2-D list, pandas.Dataframe, numpy.array);
targets: array-like (1-D list, pandas.Series, numpy.array).La biblioteca admite todos los enfoques clásicos para la selección de características: filtros, envoltorios y métodos en línea. Entre ellos se encuentran algoritmos tales como filtros basados en correlaciones de Spearman y Pearson, Fit Criterion, QPFS, filtro de escalada y otros .

La biblioteca también admite conjuntos de entrenamiento mediante la combinación de algoritmos de selección de características en función de las medidas de importancia utilizadas en ellos. Este enfoque le permite obtener resultados predictivos más altos con una baja inversión de tiempo.
Que son los análogos
No hay muchas bibliotecas de algoritmos de selección de características, especialmente en Python. Uno de los más importantes se considera el desarrollo de ingenieros de la Universidad Estatal de Arizona (ASU). Admite una gran cantidad de algoritmos, pero apenas se ha actualizado recientemente.
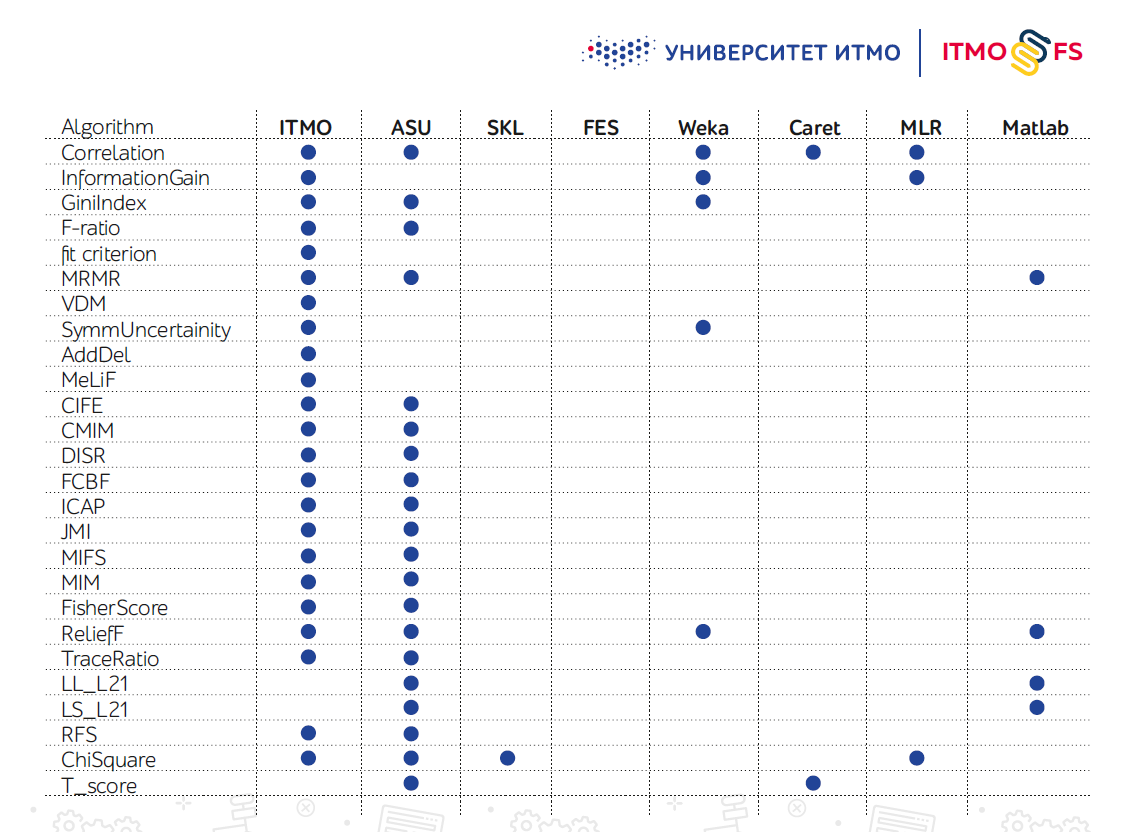
Scikit-learn en sí mismo también tiene varios mecanismos de selección de características, pero en la práctica no son suficientes.
"En general, durante los últimos cinco a siete años, el enfoque se ha desplazado hacia los algoritmos de conjunto para la selección de características, pero no están particularmente representados en tales bibliotecas, que también queremos corregir".
- Ivan Smetannikov
Perspectivas del proyecto
Los autores de ITMO_FS planean integrar su producto con scikit-learn agregándolo a la lista de bibliotecas oficialmente compatibles. Por el momento, la biblioteca ya contiene la mayor cantidad de algoritmos de selección de características entre todas las bibliotecas, pero su adición continúa. Más adelante en la hoja de ruta está la adición de nuevos algoritmos, incluidos nuestros propios desarrollos.
En planes más distantes, existen tareas para introducir la biblioteca en el sistema de metaaprendizaje, agregar algoritmos para el trabajo directo con datos matriciales (llenar vacíos, generar datos espaciales de meta-características, etc.), así como una interfaz gráfica. Paralelamente, se llevarán a cabo hackatones utilizando la biblioteca para interesar a más desarrolladores en el producto y obtener comentarios.
Se espera que ITMO_FS encuentre aplicación en los campos de la medicina y la bioinformática, en problemas como el diagnóstico de varios cánceres, la construcción de modelos predictivos de características fenotípicas (por ejemplo, la edad de una persona) y la síntesis de fármacos.
Donde puedo descargar
Si está interesado en el proyecto ITMO_FS, puede descargar la biblioteca y probarla en la práctica: aquí está el repositorio en GitHub . Una versión inicial de la documentación está disponible en readthedocs . Allí también puede ver las instrucciones de instalación (compatibles con pip). Agradecemos cualquier comentario.
Materiales adicionales de nuestro blog sobre Habré:
- Podcast: lo que les espera a los científicos en ciernes en el campo del ML
- Podcast: piratería cuántica y uso compartido de claves