El lenguaje Go se anunció por primera vez a fines de 2009 y se lanzó oficialmente en 2012, pero solo en los últimos años ha comenzado a ganar un reconocimiento serio. Go fue uno de los lenguajes de más rápido crecimiento en 2018 y el tercer lenguaje de programación más popular en 2019 .
Dado que el lenguaje Go en sí es bastante nuevo, la comunidad de desarrolladores no es muy estricta sobre cómo escribir código. Si observamos convenciones similares en las comunidades de lenguajes más antiguos, como Java, resulta que la mayoría de los proyectos tienen una estructura similar. Esto puede resultar muy útil al escribir grandes bases de código, sin embargo, muchos podrían argumentar que sería contraproducente en contextos prácticos modernos. A medida que avanzamos hacia la escritura de microsistemas y el mantenimiento de bases de código relativamente compactas, la flexibilidad de Go para estructurar proyectos se vuelve muy atractiva.
Todo el mundo conoce un ejemplo con hello world http en Golang , y se puede comparar con ejemplos similares en otros idiomas, por ejemplo, en Java.... No hay una diferencia significativa entre el primero y el segundo, ni en complejidad ni en la cantidad de código que debe escribirse para implementar el ejemplo. Pero hay una diferencia fundamental en el enfoque. Go nos anima a " escribir código simple siempre que sea posible ". Aparte de los aspectos orientados a objetos de Java, creo que la conclusión más importante de estos fragmentos de código es la siguiente: Java requiere una instancia separada para cada operación (instancia
HttpServer), mientras que Go nos anima a usar el singleton global.
De esta manera, debe mantener menos código y pasar menos enlaces en él. Si sabe que solo tiene que crear un servidor (y esto suele suceder), ¿por qué molestarse con demasiado? Esta filosofía parece más convincente a medida que crece su base de código. Sin embargo, la vida a veces depara sorpresas :(. El caso es que aún te quedan varios niveles de abstracción entre los que elegir, y si los combinas incorrectamente, puedes hacerte trampas serias.
Por eso quiero llamar tu atención sobre tres enfoques para organizar y estructurar el código Go. Cada uno de estos enfoques implica un nivel diferente de abstracción. En conclusión, compararé los tres y le diré en qué casos de aplicación cada uno de estos enfoques es más apropiado.
Vamos a implementar un servidor HTTP que contiene información sobre los usuarios (denotado como Main DB en la siguiente figura), donde a cada usuario se le asigna un rol (digamos básico, moderador, administrador), y también implementaremos una base de datos adicional (en la siguiente figura, denotado como Base de datos de configuración), que especifica el conjunto de derechos de acceso asignados a cada uno de los roles (por ejemplo, lectura, escritura, edición). Nuestro servidor HTTP debe implementar un punto final que devuelva el conjunto de derechos de acceso que tiene el usuario con el ID dado.
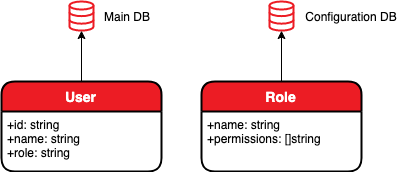
A continuación, supongamos que la base de datos de configuración cambia con poca frecuencia y tarda mucho en cargarse, por lo que la mantendremos en la RAM, la cargaremos cuando se inicie el servidor y la actualizaremos cada hora.
Todo el código está en el repositorio de este artículo ubicado en GitHub.
Enfoque I: paquete único
El enfoque de paquete único utiliza una jerarquía de hermanos en la que todo el servidor se implementa dentro de un solo paquete. Todo el código .
Advertencia: los comentarios en el código son informativos, importantes para comprender los principios de cada enfoque.
/main.go
package main
import (
"net/http"
)
// ,
// , -,
// , .
var (
userDBInstance userDB
configDBInstance configDB
rolePermissions map[string][]string
)
func main() {
// ,
// ,
// .
//
// , , ,
// .
userDBInstance = &someUserDB{}
configDBInstance = &someConfigDB{}
initPermissions()
http.HandleFunc("/", UserPermissionsByID)
http.ListenAndServe(":8080", nil)
}
// , , .
func initPermissions() {
rolePermissions = configDBInstance.allPermissions()
go func() {
for {
time.Sleep(time.Hour)
rolePermissions = configDBInstance.allPermissions()
}
}()
}
/database.go
package main
// ,
// .
type userDB interface {
userRoleByID(id string) string
}
// `someConfigDB`.
//
// , MongoDB,
// `mongoConfigDB`.
// `mockConfigDB`.
type someUserDB struct {}
func (db *someUserDB) userRoleByID(id string) string {
// ...
}
type configDB interface {
allPermissions() map[string][]string //
}
type someConfigDB struct {}
func (db *someConfigDB) allPermissions() map[string][]string {
//
}
/handler.go
package main
import (
"fmt"
"net/http"
"strings"
)
func UserPermissionsByID(w http.ResponseWriter, r *http.Request) {
id := r.URL.Query()["id"][0]
role := userDBInstance.userRoleByID(id)
permissions := rolePermissions[role]
fmt.Fprint(w, strings.Join(permissions, ", "))
}Tenga en cuenta: todavía usamos archivos diferentes, esto es para separar preocupaciones. Esto hace que el código sea más legible y más fácil de mantener.
Método II: Paquetes emparejados
En este enfoque, aprendamos qué es el procesamiento por lotes. El paquete debe ser el único responsable de algún comportamiento específico. Aquí permitimos que los paquetes interactúen entre sí , por lo que tenemos que mantener menos código. Sin embargo, debemos asegurarnos de no violar el principio de responsabilidad exclusiva y, por lo tanto, asegurarnos de que cada parte de la lógica se implemente por completo en un paquete separado. Otra pauta importante para este enfoque es que, dado que Go no permite dependencias circulares entre paquetes, debe crear un paquete neutral que contenga solo definiciones de interfaz simples e instancias de singleton . Esto eliminará las dependencias del anillo. Todo el código...
/main.go
package main
// : main – ,
// .
import (
"github.com/myproject/config"
"github.com/myproject/database"
"github.com/myproject/definition"
"github.com/myproject/handler"
"net/http"
)
func main() {
// , ,
// , ,
// .
definition.UserDBInstance = &database.SomeUserDB{}
definition.ConfigDBInstance = &database.SomeConfigDB{}
config.InitPermissions()
http.HandleFunc("/", handler.UserPermissionsByID)
http.ListenAndServe(":8080", nil)
}
/definition/database.go
package definition
// , ,
// .
// , ;
// , , ,
// .
var (
UserDBInstance UserDB
ConfigDBInstance ConfigDB
)
type UserDB interface {
UserRoleByID(id string) string
}
type ConfigDB interface {
AllPermissions() map[string][]string //
}
/definition/config.go
package definition
var RolePermissions map[string][]string
/database/user.go
package database
type SomeUserDB struct{}
func (db *SomeUserDB) UserRoleByID(id string) string {
//
}
/database/config.go
package database
type SomeConfigDB struct{}
func (db *SomeConfigDB) AllPermissions() map[string][]string {
//
}
/config/permissions.go
package config
import (
"github.com/myproject/definition"
"time"
)
// ,
// config.
func InitPermissions() {
definition.RolePermissions = definition.ConfigDBInstance.AllPermissions()
go func() {
for {
time.Sleep(time.Hour)
definition.RolePermissions = definition.ConfigDBInstance.AllPermissions()
}
}()
}
/handler/user_permissions_by_id.go
package handler
import (
"fmt"
"github.com/myproject/definition"
"net/http"
"strings"
)
func UserPermissionsByID(w http.ResponseWriter, r *http.Request) {
id := r.URL.Query()["id"][0]
role := definition.UserDBInstance.UserRoleByID(id)
permissions := definition.RolePermissions[role]
fmt.Fprint(w, strings.Join(permissions, ", "))
}Enfoque III: Paquetes independientes
Con este enfoque, el proyecto también se organiza en paquetes. En este caso, cada paquete debe integrar todas sus dependencias localmente , a través de interfaces y variables . Por lo tanto, no sabe absolutamente nada sobre otros paquetes . Con este enfoque, el paquete con las definiciones mencionadas en el enfoque anterior se distribuirá entre todos los demás paquetes; cada paquete declara su propia interfaz para cada servicio. A primera vista, esto puede parecer una duplicación molesta, pero en realidad no lo es. Cada paquete que usa un servicio debe declarar su propia interfaz, que especifica solo lo que necesita de este servicio y nada más. Todo el código...
/main.go
package main
// : – ,
// .
import (
"github.com/myproject/config"
"github.com/myproject/database"
"github.com/myproject/handler"
"net/http"
)
func main() {
userDB := &database.SomeUserDB{}
configDB := &database.SomeConfigDB{}
permissionStorage := config.NewPermissionStorage(configDB)
h := &handler.UserPermissionsByID{UserDB: userDB, PermissionsStorage: permissionStorage}
http.Handle("/", h)
http.ListenAndServe(":8080", nil)
}
/database/user.go
package database
type SomeUserDB struct{}
func (db *SomeUserDB) UserRoleByID(id string) string {
//
}
/database/config.go
package database
type SomeConfigDB struct{}
func (db *SomeConfigDB) AllPermissions() map[string][]string {
//
}
/config/permissions.go
package config
import (
"time"
)
// , ,
// , ,
// `AllPermissions`.
type PermissionDB interface {
AllPermissions() map[string][]string //
}
// ,
// , , ,
//
type PermissionStorage struct {
permissions map[string][]string
}
func NewPermissionStorage(db PermissionDB) *PermissionStorage {
s := &PermissionStorage{}
s.permissions = db.AllPermissions()
go func() {
for {
time.Sleep(time.Hour)
s.permissions = db.AllPermissions()
}
}()
return s
}
func (s *PermissionStorage) RolePermissions(role string) []string {
return s.permissions[role]
}
/handler/user_permissions_by_id.go
package handler
import (
"fmt"
"net/http"
"strings"
)
//
type UserDB interface {
UserRoleByID(id string) string
}
// ... .
type PermissionStorage interface {
RolePermissions(role string) []string
}
// ,
// , .
type UserPermissionsByID struct {
UserDB UserDB
PermissionsStorage PermissionStorage
}
func (u *UserPermissionsByID) ServeHTTP(w http.ResponseWriter, r *http.Request) {
id := r.URL.Query()["id"][0]
role := u.UserDB.UserRoleByID(id)
permissions := u.PermissionsStorage.RolePermissions(role)
fmt.Fprint(w, strings.Join(permissions, ", "))
}¡Eso es todo! Hemos analizado tres niveles de abstracción, el primero de los cuales es el más delgado, que contiene un estado global y una lógica estrechamente acoplada, pero proporciona la implementación más rápida y la menor cantidad de código para escribir y mantener. La segunda opción es un híbrido suave y la tercera es completamente autónoma y adecuada para un uso repetido, pero viene con el máximo esfuerzo con soporte.
Pros y contras
Enfoque I: Paquete único
para
- Menos código, implementación mucho más rápida, menos trabajo de mantenimiento
- Sin paquetes, lo que significa que no tiene que preocuparse por las dependencias del anillo
- Fácil de probar ya que existen interfaces de servicio. Para probar una pieza de lógica, puede configurar el singleton para cualquier implementación de su elección (concreta o simulada) y luego ejecutar la lógica de prueba.
En contra
- El único paquete tampoco proporciona acceso privado, todo está abierto desde todas partes. Como resultado, aumenta la responsabilidad del desarrollador. Por ejemplo, recuerde que no puede instanciar directamente una estructura cuando se requiere una función constructora para realizar alguna lógica de inicialización.
- El estado global (instancias singleton) puede crear suposiciones no cumplidas, por ejemplo, una instancia singleton no inicializada puede desencadenar un pánico de puntero nulo en tiempo de ejecución.
- Dado que la lógica está estrechamente acoplada, nada en este proyecto se puede reutilizar fácilmente y será difícil extraer cualquier componente de él.
- Cuando no tiene paquetes que administren de forma independiente cada parte de la lógica, el desarrollador debe tener mucho cuidado y colocar todas las partes del código correctamente, de lo contrario pueden ocurrir comportamientos inesperados.
Método II: paquetes emparejados
por
- Al empaquetar un proyecto, es más conveniente garantizar la responsabilidad de una lógica específica dentro del paquete, y esto se puede hacer cumplir mediante el compilador. Además, podremos utilizar el acceso privado y controlar qué elementos de código están abiertos para nosotros.
- El uso de un paquete con definiciones le permite trabajar con instancias singleton evitando dependencias circulares. De esta manera, puede escribir menos código, evitar pasar referencias al administrar instancias y evitar perder tiempo en problemas que puedan surgir durante la compilación.
- Este enfoque también favorece las pruebas, porque existen interfaces de servicio. Con este enfoque, es posible realizar pruebas internas de cada paquete.
En contra
- Hay algunos gastos generales al organizar un proyecto en paquetes; por ejemplo, la implementación inicial debería llevar más tiempo que con un enfoque de paquete único.
- El uso de estado global (instancias singleton) con este enfoque también puede causar problemas.
- El proyecto se divide en paquetes, lo que facilita enormemente la extracción y reutilización de elementos individuales. Sin embargo, los paquetes no son completamente independientes ya que todos interactúan con un paquete de definición. Con este enfoque, la extracción y reutilización de código no es completamente automática.
Enfoque III:
Pros independientes
- Cuando usamos paquetes, nos aseguramos de que se implemente una lógica específica dentro de un solo paquete y tenemos un control de acceso completo.
- No debería haber dependencias circulares potenciales ya que los paquetes son completamente autónomos.
- Todos los paquetes son altamente recuperables y reutilizables. En todos esos casos en los que necesitamos un paquete en otro proyecto, simplemente lo transferimos a un espacio compartido y lo usamos sin cambiar nada en él.
- Si no hay un estado global, entonces no hay comportamientos no deseados.
- Este enfoque es el mejor para realizar pruebas. Cada paquete se puede probar completamente sin preocuparse de que pueda depender de otros paquetes a través de interfaces locales.
En contra
- Este enfoque es mucho más lento de implementar que los dos anteriores.
- Es necesario mantener mucho más código. Debido a que se están transfiriendo enlaces, muchos lugares deben actualizarse después de realizar cambios importantes. Además, cuando tenemos varias interfaces que brindan el mismo servicio, tenemos que actualizar esas interfaces cada vez que hacemos cambios en ese servicio.
Conclusiones y ejemplos de uso
Dada la falta de pautas para escribir código en Go, toma muchas formas y formas diferentes, y cada opción tiene sus propios méritos interesantes. Sin embargo, mezclar diferentes patrones de diseño puede causar problemas. Para darle una idea de ellos, he cubierto tres enfoques diferentes para escribir y estructurar el código Go.
Entonces, ¿cuándo debería usarse cada enfoque? Sugiero este arreglo:
Enfoque I : El enfoque de paquete único es quizás más apropiado cuando se trabaja en equipos pequeños y con mucha experiencia en proyectos pequeños que necesitan hacer las cosas rápidamente. Este enfoque es más simple y confiable para un inicio rápido, aunque requiere una atención y coordinación serias en la etapa de apoyo al proyecto.
Enfoque II: El enfoque de paquetes emparejados se puede llamar una síntesis híbrida de los otros dos enfoques: entre sus ventajas se encuentran el inicio relativamente rápido y la facilidad de soporte, mientras que al mismo tiempo, crea las condiciones para el estricto cumplimiento de las reglas. Es apropiado para proyectos relativamente grandes y equipos grandes, pero tiene una reutilización limitada del código y existen ciertas dificultades para mantener.
Enfoque III : El enfoque de paquetes independientes es más apropiado para proyectos que son complejos en sí mismos, a largo plazo, desarrollados por equipos grandes y para proyectos en los que hay piezas de lógica que se crean con miras a una mayor reutilización. Este enfoque lleva mucho tiempo de implementación y es difícil de mantener.