Analizando
¿Qué es el análisis sintáctico? Se trata de la recopilación y sistematización de información que se publica en sitios web mediante programas especiales que automatizan el proceso.
El análisis se usa comúnmente para el análisis de precios y la recuperación de contenido.
comienzo
Para cobrar dinero de las casas de apuestas, tuve que recibir de inmediato información sobre las probabilidades de ciertos eventos de varios sitios. No entraremos en la parte matemática.
Como estudié C # en mi sharaga, decidí escribir todo en él. Los chicos de Stack Overflow aconsejaron usar Selenium WebDriver. Es un controlador de navegador (biblioteca de software) que le permite desarrollar programas que controlan el comportamiento del navegador. Eso es lo que necesitamos, pensé.
Instalé la biblioteca y corrí a ver las guías en Internet. Después de un tiempo, escribí un programa que podía abrir un navegador y seguir algunos enlaces.
¡Hurra! Aunque pare, ¿cómo presionar los botones, cómo obtener la información necesaria? XPath nos ayudará aquí.
XPath
En términos simples, es un lenguaje para consultar elementos de documentos XML y XHTML.
Para este artículo, usaré Google Chrome. Sin embargo, otros navegadores modernos deberían tener, si no el mismo, una interfaz muy similar.
Para ver el código de la página en la que se encuentra, presione F12.

Para ver en qué parte del código hay un elemento en la página (texto, imagen, botón), haga clic en la flecha en la esquina superior izquierda y seleccione este elemento en la página. Ahora pasemos a la sintaxis.
Sintaxis estándar para escribir XPath:
// nombre de etiqueta [@ atributo = 'valor']
// : Selecciona todos los nodos en el documento html comenzando desde el nodo actual
Nombre de etiqueta: Etiqueta del nodo actual.
@ : Selecciona atributos
Atributo : el nombre del atributo del nodo.
Valor : el valor del atributo.
Puede resultar confuso al principio, pero después de los ejemplos, todo debería encajar.
Veamos algunos ejemplos simples:
// input [@ type = 'text']
// label [@ id = 'l25']
// input [@ value = '4']
// a [@ href = 'www.walmart. com ']
Considere ejemplos más complejos para el html'i dado:
<div class ='contentBlock'>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habr</span>
</a>
<div class = 'textConainer'>
<span class='description'>cool site</span>
"text2"
</div>
</div>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habrhabr</span>
</a>
<div class = 'textConainer'>
<span class='description'>the same site</span>
"text1"
</div>
</div>
</div>XPath = // div [@ class = 'contentBlock'] // div
Se seleccionarán los siguientes elementos para este XPath:
<div class = 'listItem'>
<div class = 'textConainer'>
<div class = 'listItem'>
<div class = 'textConainer'>XPath = // div [@ class = 'contentBlock'] / div
<div class = 'listItem'>
<div class = 'listItem'>Tenga en cuenta la diferencia entre / (obtiene del nodo raíz) y // (obtiene los nodos del nodo actual independientemente de su ubicación). Si no está claro, vuelva a mirar los ejemplos anteriores.
// div [@ class = 'contentBlock'] / div [@ class = 'listItem'] / a [@ class = 'link'] / span [@ class = 'name']
Esta solicitud es la misma con este html :
// div / div / a / span
// span [@ class = 'name']
// a [@ class = 'link'] / span [@ class = 'name']
// a [@ class = ' enlace 'yhref= 'habr.com'] / span
// span [text () = 'habr' o text () = 'habrhabr']
// div [@ class = 'listItem'] // span [@ class = 'nombre' ]
// a [contiene (href, 'habr')] / span
// span [contiene (text (), 'habr')]
Resultado:
<span class='name'>habr</span>
<span class='name'>habrhabr</span>// span [text () = 'habr'] / parent :: a / parent :: div
Equivalente a
// div / div [@ class = 'listItem'] [1]
Resultado:
<div class = 'listItem'>parent :: - Devuelve el padre un nivel más arriba.
También hay una característica genial como siguiente-hermano :: - devuelve muchos elementos en el mismo nivel después del actual, similar a precedente-hermano :: - devuelve muchos elementos en el mismo nivel antes del actual.
// span [@ class = 'nombre'] / siguiente-sibiling :: text () [1]
Resultado:
"text1"
"text2"Creo que ahora está más claro. Para consolidar el material, le aconsejo que vaya a este sitio y escriba varias consultas para encontrar algunos elementos de este html'i.
<div class="item">
<a class="link" data-uid="A8" href="https://www.walmart.com/grocery/?veh=wmt" title="Pickup & delivery">
<span class="g_b">Pickup and delivery</span>
</a>
<a class="link" data-uid="A9" href="https://www.walmart.com/" title="Walmart.com">
<span class="g_b">Walmart.com</span>
</a>
</div>
<div class="item">
<a class="link" data-uid="B8" href="https://www.walmart.com/grocery/?veh=wmt" title="Savings spotlight">
<span class="g_b">Savings spotlight</span>
</a>
<a class="link" data-uid="B9" href="https://www.walmartethics.com/content/walmartethics/it_it.html" title="Walmart.com">
<span class="g_b">Walmart.com(Italian)</span>
"italian virsion"
</a>
</div>Ahora que sabemos qué es XPath, volvamos a escribir el código. Dado que a los moderadores de Habr no les gustan las casas de apuestas, analizarán los precios del café en Walmart
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
IWebDriver driver = new ChromeDriver(pathToFile);
driver.Navigate().GoToUrl("https://walmart.com");
Thread.Sleep(5000);
IWebElement element = driver.FindElement(By.XPath("//button[@id='header-Header sparkButton']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//button[@data-tl-id='GlobalHeaderDepartmentsMenu-deptButtonFlyout-10']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//div[text()='Coffee']/parent::a"));
driver.Navigate().GoToUrl(element.GetAttribute("href"));
Thread.Sleep(10000);
List<string> names = new List<string>(), prices = new List<string>();
List<IWebElement> listOfElements =driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-title']/div")).ToList();
foreach (IWebElement a in listOfElements)
names.Add(a.Text);
listOfElements = driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-price']/span/span[contains(text(),'$')]")).ToList();
foreach (IWebElement a in listOfElements)
prices.Add(a.Text);
for (int i = 0; i < prices.Count; i++)
Console.WriteLine(names[i] + " " + prices[i]);Thread.Sleep se escribieron para que la página web tuviera tiempo de cargarse.
El programa abrirá el sitio web de la tienda Walmart, presionará un par de botones, abrirá la sección de café y obtendrá el nombre y los precios de los productos.
Si la página web es bastante grande y, por lo tanto, los XPath toman mucho tiempo o son difíciles de escribir, entonces necesita usar algún otro método.
Solicitudes HTTP
Primero, veamos cómo aparece el contenido en el sitio.

En pocas palabras, el navegador realiza una solicitud al servidor con una solicitud para proporcionar la información necesaria, y el servidor, a su vez, proporciona esta información. Todo esto se hace mediante solicitudes HTTP.
Para ver las solicitudes que envía su navegador en un sitio específico, simplemente abra este sitio, presione F12 y vaya a la pestaña Red, luego vuelva a cargar la página.

Ahora queda por encontrar la solicitud que necesitamos.
¿Cómo hacerlo? - considere todas las solicitudes con el tipo de recuperación (tercera columna en la imagen de arriba) y observe la pestaña Vista previa.

Si no está vacío, entonces debe estar en formato XML o JSON, si no, sigue buscando. Si es así, vea si la información que necesita está aquí. Para comprobar esto, le aconsejo que utilice algún tipo de visor JSON o visor XML (busque en Google y abra el primer enlace, copie el texto de la pestaña Respuesta y péguelo en el visor). Cuando encuentre la solicitud que necesita, guarde su nombre (columna izquierda) o el host de URL (pestaña Encabezados) en algún lugar, para que no busque más tarde. Por ejemplo, si se abre un departamento de café en el sitio web de Walmart, se enviará una solicitud, cuya legalidad comienza con walmart.com/cp/api/wpa. Allí estará toda la información sobre el café a la venta.
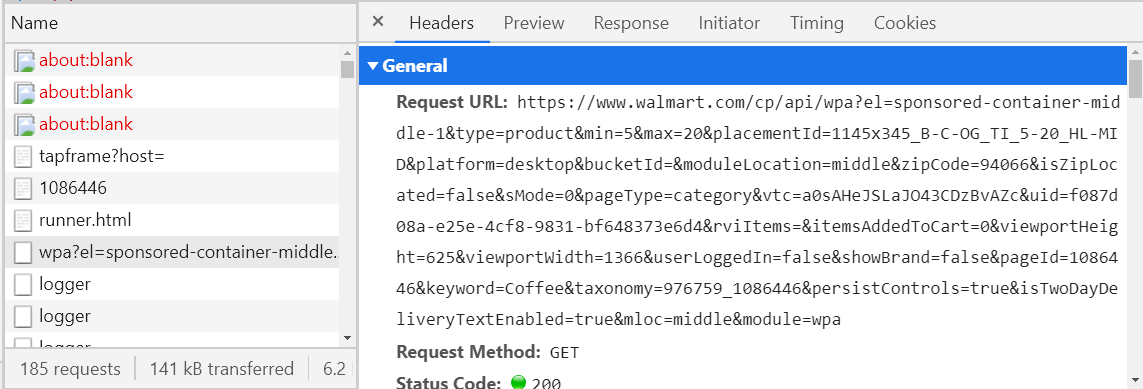
A mitad de camino, ahora esta solicitud puede ser "falsificada" y enviada inmediatamente a través del programa, recibiendo la información necesaria en cuestión de segundos. Queda por analizar JSON o XML, y esto es mucho más fácil que escribir XPaths. Pero a menudo la formación de tales solicitudes es algo bastante desagradable (mire la URL en la imagen de arriba) y si incluso tiene éxito, en algunos casos recibirá esa respuesta.
{
"detail": "No authorization token provided",
"status": 401,
"title": "Unauthorized",
"type": "about:blank"
}Ahora aprenderá cómo puede evitar problemas al imitar una solicitud utilizando una alternativa: un servidor proxy.
Servidor proxy
Un servidor proxy es un dispositivo que media entre una computadora e Internet.
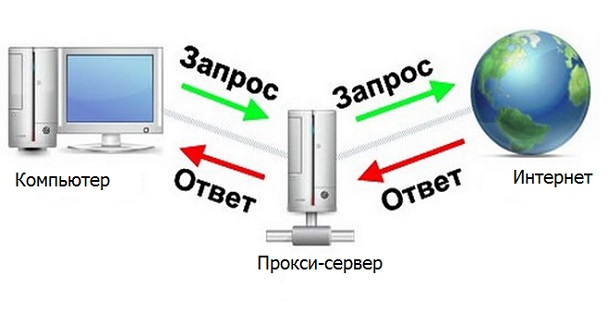
Sería genial si nuestro programa fuera un servidor proxy, entonces puede procesar rápida y convenientemente las respuestas necesarias del servidor. Entonces habría una cadena de navegador - Programa - Internet (servidor de sitio que se analiza).
Afortunadamente para si sharp, existe una biblioteca maravillosa para tales necesidades: Titanium Web Proxy.
Creemos la clase PServer
class PServer
{
private static ProxyServer proxyServer;
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")){
Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}
}Ahora repasemos cada método por separado.
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}proxyServer.BeforeRepsone + = OnRespone : agregue un método para procesar una respuesta del servidor. Se llamará automáticamente cuando llegue la respuesta.
ExplícitaEndPoint : configuración del servidor proxy,
ExplicitProxyEndPoint (IPAddress ipAddress, int port, bool decryptSsl = true)
IPAddress y puerto en el que se ejecuta el servidor proxy.
decryptSsl : si se debe descifrar SSL. En otras palabras, si decrtyptSsl = true, el servidor proxy procesará todas las solicitudes y respuestas.
ExplícitaEndPoint.BeforeTunnelConnectRequest + = OnBeforeTunnelConnectRequest : agregue un método para procesar la solicitud antes de enviarla al servidor. También se llamará automáticamente antes de que se envíe la solicitud.
proxyServer.Start () - "iniciando" el servidor proxy, a partir de este momento comienza a procesar solicitudes y respuestas.
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}e.DecryptSsl = false : la solicitud y la respuesta actuales no se procesarán.
Si no estamos interesados en la solicitud o la respuesta a ella (por ejemplo, una imagen o algún tipo de guión), ¿por qué descifrarlo? Se gastan muchos recursos en esto, y si se descifran todas las solicitudes y respuestas, el programa funcionará durante mucho tiempo. Por lo tanto, si la solicitud actual no contiene el host de la solicitud que nos interesa, no tiene sentido descifrarla.
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")) Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}await e.GetResponseBodyAsString () : devuelve una respuesta como una cadena.
Para que WebDriver se conecte al servidor proxy, debe escribir lo siguiente:
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
ChromeOptions options = new ChromeOptions();
options.AddArguments("--proxy-server=" + IPAddress.Loopback + ":8000");
IWebDriver driver = new ChromeDriver(pathToFile, options);Ahora puede manejar las solicitudes que desee.
Conclusión
Con WebDriver, puede navegar por las páginas, hacer clic en los botones e imitar el comportamiento de un usuario habitual. Con XPaths, puede extraer la información que necesita de las páginas web. Si los XPath no funcionan, entonces un servidor proxy siempre puede ayudar, que puede interceptar solicitudes entre el navegador y el sitio.