El proyecto ha crecido, la biblioteca ahora resuelve todas las tareas básicas de procesamiento del idioma ruso natural: segmentación en tokens y oraciones, análisis morfológico y sintáctico, lematización, extracción de entidades nombradas.

Para los artículos de noticias, la calidad en todas las tareas es comparable o superior a las soluciones existentes.... Por ejemplo, Natasha hace frente a la tarea NER en 1 punto porcentual peor que Deeppavlov BERT NER (F1 PER 0.97, LOC 0.91, ORG 0.85), el modelo pesa 75 veces menos (27MB), trabaja en la CPU 2 veces más rápido (25 artículos / seg ) que BERT NER en GPU.
Hay 9 repositorios en el proyecto , la biblioteca de Natasha los combina en una interfaz. En el artículo, hablaremos sobre nuevas herramientas, compárelas con soluciones existentes: Deeppavlov , SpaCy , UDPipe .

Este longridu precedido por una serie de publicaciones en el sitio natasha.github.io :Si se siente intimidado por el tamaño del texto a continuación, mire los primeros 20 minutos de la transmisión del tubo sobre la historia del proyecto Natasha, hay un breve recuento:
- Natasha - NER compacto de calidad para el idioma ruso
- Navec - incrustaciones compactas para el idioma ruso
- Corus: recopilación de conjuntos de datos de PNL en ruso
- Razdel: segmentación del texto en ruso en tokens y ofertas
- Naeval: comparación cuantitativa de sistemas para PNL de habla rusa
- Nerus es un gran conjunto de datos sintéticos en ruso con marcado de morfología, sintaxis y entidades con nombre.
El texto utiliza notas y discusiones del chat t.me/natural_language_processing , los enlaces a nuevos materiales aparecen en el mismo lugar:
- Por qué Natasha no está usando Transformers. BERT en 100 líneas
- Modelos Slovnet BERT
- Transmisión de tubo sobre la historia del proyecto Natasha
- Documentación Yargy actualizada
- Recursos adicionales sobre el analizador Yargy
Para aquellos a los que les gusta escuchar más, consulte la charla por hora en Datafest 2020, casi cubre esta publicación:
Contenido:
- Natasha — .
- Razdel —
- Slovnet — deep learning
- Navec —
- Nerus — ,
- Corus — +
- Naeval — NLP
- Yargy- —
- Ipymarkup —
Natasha — .

Anteriormente, la biblioteca de Natasha resolvió el problema de NER para el idioma ruso, se construyó sobre reglas , mostró calidad y rendimiento promedio. Ahora Natasha es un gran proyecto, consta de 9 repositorios . La biblioteca de Natasha los une bajo una interfaz, resuelve las tareas básicas de procesamiento del idioma ruso natural: segmentación en tokens y oraciones, incrustaciones pre-entrenadas, análisis de sintaxis y morfología, lematización, NER. Todas las soluciones muestran los mejores resultados en temas de noticias , se ejecutan rápidamente en la CPU.
Natasha es similar a otras bibliotecas combinadas: SpaCy , UDPipe , Stanza... SpaCy inicializa y llama a los modelos implícitamente, el usuario pasa el texto a la función mágica
nlpy obtiene un documento completamente analizado.
import spacy
# load ,
# , NER
nlp = spacy.load('...')
# ,
text = '...'
doc = nlp(text)
La interfaz de Natasha es más detallada. El usuario inicializa explícitamente los componentes: carga las incrustaciones previamente entrenadas y las pasa a los constructores del modelo. Sam llama a los métodos
segment, tag_morph, parse_syntaxsegmentación en fichas y la demanda, análisis de la morfología y la sintaxis.
>>> from natasha import (
Segmenter,
NewsEmbedding,
NewsMorphTagger,
NewsSyntaxParser,
Doc
)
>>> segmenter = Segmenter()
>>> emb = NewsEmbedding()
>>> morph_tagger = NewsMorphTagger(emb)
>>> syntax_parser = NewsSyntaxParser(emb)
>>> text = ' , , 2019 () ...'
>>> doc = Doc(text)
>>> doc.segment(segmenter)
>>> doc.tag_morph(morph_tagger)
>>> doc.parse_syntax(syntax_parser)
>>> sent = doc.sents[0]
>>> sent.morph.print()
NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Inan|Case=Gen|Gender=Masc|Number=Sing
ADP
PROPN|Animacy=Inan|Case=Loc|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
...
>>> sent.syntax.print()
┌──► nsubj
│
│ ┌► case
│ └─
│ ┌─
│ └► flat:name
┌─────┌─└───
│ │ ┌──► , punct
│ │ │ ┌► mark
│ └►└─└─ ccomp
│ │ ┌► case
│ └──►└─ obl
...
El extractor de entidad nombrado no depende de los resultados morfológicos y del análisis, se puede utilizar por separado.
>>> from natasha import NewsNERTagger
>>> ner_tagger = NewsNERTagger(emb)
>>> doc.tag_ner(ner_tagger)
>>> doc.ner.print()
, ,
LOC──── LOC──── PER───────
2019
LOC──────────────
()
LOC─── ORG───────────────────────────────────────
...
PER────────────
Natasha resuelve el problema de la lematización, utiliza Pymorphy2 y los resultados del análisis morfológico.
>>> from natasha import MorphVocab
>>> morph_vocab = MorphVocab()
>>> for token in doc.tokens:
>>> token.lemmatize(morph_vocab)
>>> {_.text: _.lemma for _ in doc.tokens}
{'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
',': ',',
'': '',
'': ''
...
Para llevar la frase a una forma normal, no es suficiente encontrar los lemas de las palabras individuales, para el Ministerio de Relaciones Exteriores de Rusia resultará ser el Ministerio de Relaciones Exteriores de Rusia, para la Organización de Nacionalistas Ucranianos: la Organización Nacionalista de Ucrania. Natasha usa los resultados del análisis, tiene en cuenta las relaciones entre las palabras, normaliza las entidades nombradas.
>>> for span in doc.spans:
>>> span.normalize(morph_vocab)
>>> {_.text: _.normal for _ in doc.spans}
{'': '',
'': '',
' ': ' ',
' ': ' ',
'': '',
' ()': ' ()',
' ': ' ',
...
Natasha encuentra nombres, organizaciones y nombres de lugares en el texto. Para los nombres en la biblioteca hay un conjunto de reglas listas para usar para el analizador de Yargy , el módulo divide los nombres normalizados en partes, de "Viktor Fedorovich Yushchenko" se obtiene
{first: , last: , middle: }.
>>> from natasha import (
PER,
NamesExtractor,
)
>>> names_extractor = NamesExtractor(morph_vocab)
>>> for span in doc.spans:
>>> if span.type == PER:
>>> span.extract_fact(names_extractor)
>>> {_.normal: _.fact.as_dict for _ in doc.spans if _.type == PER}
{' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
'': {'last': ''},
' ': {'first': '', 'last': ''}}
La biblioteca contiene reglas para analizar fechas, cantidades de dinero y direcciones, que se describen en la documentación y el libro de referencia .
La biblioteca de Natasha es muy adecuada para demostrar tecnologías de proyectos, que se utilizan en educación. Los archivos con pesos de modelo están integrados en el paquete, después de la instalación no es necesario descargar ni configurar nada.
Natasha combina otras bibliotecas de proyectos en una interfaz. Para resolver problemas prácticos, debe usarlos directamente:
- Razdel : segmentación del texto en oraciones y tokens;
- Navec : empotrables compactos de alta calidad;
- Slovnet : modelos compactos modernos para morfología, sintaxis, NER;
- Yargy : reglas y vocabularios para extraer información estructurada;
- Ipymarkup : visualización de NER y marcado sintáctico;
- Corus : recopilación de enlaces a conjuntos de datos públicos en ruso;
- Nerus es un corpus grande con marcado automático de entidades nombradas, morfología y sintaxis.
Razdel: segmentación del texto en ruso en tokens y ofertas

La biblioteca Razdel es parte del proyecto Natasha, divide el texto en ruso en fichas y oraciones. Instrucciones de instalación , ejemplo de uso y medidas de rendimiento en el repositorio de Razdel.
>>> from razdel import tokenize, sentenize
>>> text = '- 0.5 (50/64 ³, 516;...)'
>>> list(tokenize(text))
[Substring(start=0, stop=13, text='-'),
Substring(start=14, stop=16, text=''),
Substring(start=17, stop=20, text='0.5'),
Substring(start=20, stop=21, text=''),
Substring(start=22, stop=23, text='(')
...]
>>> text = '''
... - " ?" - " --".
... . . . . ,
... '''
>>> list(sentenize(text))
[Substring(start=1, stop=23, text='- " ?"'),
Substring(start=24, stop=40, text='- " --".'),
Substring(start=41, stop=56, text=' . . . .'),
Substring(start=57, stop=76, text=' , ')]
Los modelos modernos a menudo no se preocupan por la segmentación, usan BPE , muestran resultados notables, recuerdan todas las versiones de GPT y el zoológico BERT . Natasha resuelve los problemas de analizar la morfología y la sintaxis, solo tienen sentido para palabras separadas dentro de una oración. Por lo tanto, nos acercamos responsablemente a la etapa de segmentación, intentamos repetir el marcado de conjuntos de datos abiertos populares: SynTagRus , OpenCorpora , GICRYA .
La velocidad y la calidad de Razdel son comparables o mejores que otras soluciones de código abierto para el idioma ruso.
| Soluciones de segmentación de tokens | Errores por 1000 tokens | Tiempo de procesamiento, segundos |
| Regexp-línea de base | 19 | 0,5 |
| ESPACIO
|
17 | 5.4 |
| NLTK
|
130 | 3.1 |
| MyStem
|
19 | 4.5 |
| Moisés
|
once | 1,9 |
| SegTok
|
12 | 2.1 |
| SpaCy Russian Tokenizer
|
8 | 46.4 |
| RuTokenizer
|
15 | 1.0 |
| Razdel
|
7 | 2.6 |
| 1000 | , | |
| Regexp-baseline | 76 | 0.7 |
| SegTok
|
381 | 10.8 |
| Moses
|
166 | 7.0 |
| NLTK
|
57 | 7.1 |
| DeepPavlov
|
41 | 8.5 |
| Razdel | 43 | 4.8 |
Número medio de errores para 4 conjuntos de datos : SynTagRus , OpenCorpora , GICRYA y RNC . Más detalles en el repositorio de Razdel .
¿Por qué necesitamos Razdel en absoluto, si una línea de base con una línea regular ofrece una calidad similar y hay muchas soluciones listas para usar para el idioma ruso? De hecho, Razdel no es solo un tokenizador, sino un pequeño motor de segmentación basado en reglas. La segmentación es una tarea básica que se encuentra a menudo en la práctica. Por ejemplo, hay un acto judicial, es necesario resaltar la parte operativa del mismo y dividirlo en párrafos. Naturalmente, las soluciones estándar no pueden hacer eso. Lea cómo escribir sus propias reglas en el código fuente . Además, hablaremos sobre cómo esforzarse y crear una solución superior para tokens y ofertas en nuestro motor.
Cual es la dificultad?
En ruso, las oraciones suelen terminar con un punto, un signo de interrogación o un signo de exclamación. Dividamos el texto con una expresión regular
[.?!]\s+. Esta solución dará 76 errores por 1000 frases. Tipos y ejemplos de errores:
Abreviaturas
... cualquier sitio con una audiencia de 3.000 o más personas es un blogger.
... un latido se apoderó de ellos desde finales del siglo XVII;
… En el Teatro Musical de Cámara que lleva el nombre de ▒B.A. Pokrovsky.
Las iniciales
a raíz de la ópera "Idomeneo" V.A.▒Motsarta - R.▒Shtrausa ...
Listas
2.▒dumal estará en el consulado finlandés en una cola bastante larga ...
g.▒bilety entrena los ferrocarriles rusos ...
El final de la frase emoticón o puntos tipográficos
Quien proponga una forma de deshacerse de los inconvenientes, gracias a eso :) ▒ Miré, pensativo ... ▒ Ahora esto es más desagradable, ya que el contenido se romperá.
Citas, discurso directo, al final de la oración entre comillas
: ¿tienes novia en la ciudad? ”” “¿Para quién tiene novia?”
“¡Qué bueno que yo no soy así!” ▒Ahora, mientras traducía, cometí un error freudiano: “idología”.
Razdel tiene en cuenta estos matices, reduciendo el número de errores de 76 a 43 por 1000 frases.
La situación es similar con las fichas. Una buena solución básica es una expresión regular
[--]+|[0-9]+|[^-0-9 ], comete 19 errores por cada 1000 tokens. Ejemplos:
números fraccionarios, puntuación compleja
... A finales de la década de 1980 y principios de la de 1990
... BS-▒3 se puede notar con una masa ligeramente menor (3▒, ▒6 t)
- y ella murió ▒.▒. ¿Entiendes a la niña, halcón? ▒!
Razdel está reduciendo la tasa de error a 7 por cada 1000 tokens.
Principio de funcionamiento
El sistema se basa en reglas. El principio de segmentación en tokens y ofertas es el mismo.
Colección de candidatos
Encontramos en el texto todos los candidatos para el final de la oración: puntos, puntos suspensivos, paréntesis, comillas.
6.▒La opción de respuesta más frecuente y a la vez mejor valorada “Me alegro” ▒ (13 afirmaciones, 25 puntos) ▒– Situaciones de recibir aprobación y aliento. ▒7.▒ Cabe destacar que en la respuesta “Yo sé” se estima como la más estereotipada , pero solo una vez hay la respuesta "Soy una mujer" ▒; ▒ hay declaraciones "un matrimonio es todo lo que me espera en esta vida" ▒ y "tarde o temprano tendré que dar a luz" ▒.▒ Compiladores: V.▒P.▒Golovin , F.▒V.▒Zanichev, A.▒L.▒Rastorguev, R.▒V.▒Savko, I.▒I.▒Tuchkov.
Para los tokens, dividimos el texto en átomos. El borde del token no pasa exactamente dentro del átomo.
A finales de 1980▒-▒▒-begin1990▒-▒▒
BS▒-▒3▒ es posible▒ marcar una masamas ligeramente▒ más pequeña▒ (▒3▒, ▒6▒▒)
▒ ▒— "Sí" y "murió". ""
Unión
Omitimos constantemente a los candidatos para la separación, eliminamos los innecesarios. Usamos una lista de heurísticas.
Elemento de lista. El separador es un punto o un paréntesis, a la izquierda hay un número o una letra
6.▒La respuesta más frecuente y al mismo tiempo altamente calificada “Me alegro” (13 declaraciones, 25 puntos) es una situación de recibir aprobación y recompensa. 7.▒ Cabe destacar que en la respuesta "Yo sé" ...
Iniciales. Separador - punto, una letra mayúscula a la izquierda
... Compiladores: V.▒P.▒Golovin, F.▒V.▒Zanichev, A.▒L.▒Rastorguev, R.▒V.▒Savko, I.▒I.▒Tuchkov ...
No hay espacio a la derecha del separador
... pero solo una vez es la respuesta "Soy una mujer" ▒; hay declaraciones “un matrimonio es todo lo que me espera en esta vida” y “tarde o temprano tendré que dar a luz” ▒.
No hay un signo de final de oración antes de la comilla de cierre o el paréntesis, esto no es una cita o un discurso directo
6. La respuesta más frecuente y muy apreciada es “Me alegro” «(13 declaraciones, 25 puntos) ▒ - situaciones de obtener aprobación y aliento. ... "un matrimonio es todo lo que me espera en esta vida" y "tarde o temprano tendré que dar a luz".
Como resultado, quedan dos separadores, los consideramos finales de oraciones.
6. La variante más frecuente y al mismo tiempo muy apreciada de respuestas “Me alegro” (13 afirmaciones, 25 puntos) es una situación de recibir aprobación y aliento.▒7. Es de destacar que en la respuesta “Yo sé” se evalúa como la más estereotipada, pero solo una vez que se encuentra la respuesta “Soy mujer”; hay declaraciones "un matrimonio es todo lo que me espera en esta vida" y "tarde o temprano tendré que dar a luz". ▒Componentes: V.P. Golovin, F.V. Zanichev, A.L. Rastorguev, R.V. Savko, I. I. Tuchkov.
El procedimiento es similar para los tokens, las reglas son diferentes.
Fracción o número racional
... (3▒, ▒6 t) ... Puntuación
compleja
- sí, y murió.▒.▒. ¿Entiendes a la niña, halcón? ▒!
No hay espacios alrededor del guión, este no es el comienzo del discurso directo
A finales de 1980▒-▒ - principios de 1990▒-▒
BS▒-▒3 se puede notar ...
Todo lo que queda se considera los límites de los tokens.
A finales de la década de 1980-x▒-principios▒1990-x▒
BS-3▒ es posible▒tonar una masa ligeramente inferior▒ (▒3,6▒t▒) ▒ ▒
- sí y murió. ..▒¡Lo tienes▒li▒girl, ▒sokol▒?!
Limitaciones
Las reglas de Razdel están optimizadas para un texto bien escrito con la puntuación correcta. La solución funciona bien con artículos de noticias, textos literarios. En publicaciones de redes sociales, transcripciones de conversaciones telefónicas, la calidad es menor. Si no hay espacio entre oraciones o ningún punto al final, o la oración comienza con una letra minúscula, Razdel cometerá un error. Lea
cómo escribir reglas para sus tareas en el código fuente , este tema aún no se ha revelado en la documentación.
Slovnet: modelado de aprendizaje profundo para el procesamiento natural del idioma ruso

En el proyecto, Natasha Slovnet se dedica a la enseñanza e inferencia de modelos modernos para la PNL de habla rusa. La biblioteca contiene modelos compactos de alta calidad para extraer entidades con nombre, analizar la morfología y la sintaxis. La calidad en todas las tareas es comparable o superior a otras soluciones abiertas para el idioma ruso en textos de noticias. Instrucciones de instalación , ejemplos de uso : en el repositorio de Slovnet . Echemos un vistazo más de cerca a cómo se organiza la solución para el problema NER, para morfología y sintaxis todo es por analogía.
A finales de 2018, después de un artículo de Google sobre BERT , hubo muchos avances en la PNL en inglés. En 2019, los chicos del proyecto DeepPavlovBERT multilingüe adaptado para ruso, apareció RuBERT . Se entrenó una cabeza de CRF en la parte superior , resultó DeepPavlov BERT NER - SOTA para el idioma ruso. El modelo tiene una calidad excelente, 2 veces menos errores que el perseguidor más cercano DeepPavlov NER , pero el tamaño y el rendimiento dan miedo: 6GB - consumo de RAM GPU, 2GB - tamaño del modelo, 13 artículos por segundo - rendimiento en una buena GPU.
En 2020, en el proyecto Natasha, logramos acercarnos en calidad a DeepPavlov BERT NER, el tamaño del modelo resultó ser 75 veces menor (27 MB), el consumo de memoria es 30 veces menor (205 MB), la velocidad es 2 veces mayor en la CPU (25 artículos por segundo) ).
| Natasha, Slovnet NER | DeepPavlov BERT NER | |
| PER / LOC / ORG F1 por tokens, promedio por Collection5, factRuEval-2016, BSNLP-2019, Gareev | 0,97 / 0,91 / 0,85 | 0,98 / 0,92 / 0,86 |
| Tamaño del modelo | 27 MB | 2GB |
| Consumo de memoria | 205 MB | 6 GB (GPU) |
| Rendimiento, artículos de noticias por segundo (1 artículo ≈ 1KB) | 25 por CPU (Core i5) | 13 GPU (RTX 2080 Ti), 1 CPU |
| Tiempo de inicialización, segundos | 1 | 35 |
| La biblioteca admite | Python 3.5+, PyPy3 | Python 3.6+ |
| Dependencias | NumPy | TensorFlow |
La calidad de Slovnet NER es 1 punto porcentual menor que la de SOTA DeepPavlov BERT NER, el tamaño del modelo es 75 veces menor, el consumo de memoria es 30 veces menor, la velocidad es 2 veces mayor en la CPU. Comparación con SpaCy, PullEnti y otras soluciones para NER de habla rusa en el repositorio de Slovnet .
¿Cómo se obtiene este resultado? Receta corta:
Slovnet NER = Slovnet BERT NER - análogo de DeepPavlov BERT NER + destilación mediante marcado sintético ( Nerus ) en WordCNN-CRF con incrustaciones cuantificadas ( Navec ) + motor para inferencia en NumPy.
Ahora en orden. El plan es el siguiente: entrenar un modelo pesado con arquitectura BERT en un pequeño conjunto de datos anotado manualmente. Lo marcamos con un corpus de noticias y obtenemos un gran conjunto de datos de entrenamiento sintético sucio. Entrenemos un modelo primitivo compacto en él. Este proceso se llama destilación: el modelo pesado es el maestro, el modelo compacto es el alumno. Creemos que la arquitectura BERT es redundante para el problema de NER, el modelo compacto no perderá mucho en calidad frente al pesado.
Maestro modelo
DeepPavlov BERT NER consta de un codificador RuBERT y un cabezal CRF. Nuestro modelo de profesor pesado repite esta arquitectura con pequeñas mejoras.
Todos los puntos de referencia miden la calidad de NER en textos de noticias. Entrenemos a RuBERT en las noticias. El repositorio de Corus contiene enlaces a corpus de noticias públicas en ruso, un total de 12 GB de textos. Usamos técnicas del artículo de Facebook sobre RoBERTa : grandes lotes agregados, máscara dinámica, negativa a predecir la siguiente oración (NSP). RuBERT utiliza un enorme diccionario de 120.000 subtokens, un legado del BERT multilingüe de Google. Reduciendo el tamaño a las 50.000 noticias más frecuentes, la cobertura disminuirá un 5%. Obtener noticias, el modelo predice subtokens disfrazados en las noticias 5 puntos porcentuales mejor que RuBERT (63% en el top 1).
Entrenemos el codificador NewsRuBERT y el cabezal CRF para 1000 artículos de Collection5 . Obtenemos Slovnet BERT NER , la calidad es 0,5 puntos porcentuales mejor que la de DeepPavlov BERT NER, el tamaño del modelo es 4 veces más pequeño (473 MB), funciona 3 veces más rápido (40 artículos por segundo).
NewsRuBERT = RuBERT + 12GB de noticias + técnicas del diccionario RoBERTa + 50K.
Slovnet BERT NER (análogo de DeepPavlov BERT NER) = NewsRuBERT + CRF head + Collection5.
Ahora, para entrenar modelos con arquitectura similar a BERT, se acostumbra usar Transformers de Hugging Face. Los transformadores son 100.000 líneas de código Python. Cuando la pérdida o la basura explotan en la inferencia, es difícil averiguar qué salió mal. De acuerdo, hay mucho código duplicado allí. Incluso si entrenamos a RoBERTa, podemos localizar rápidamente el problema en ~ 3000 líneas de código, pero esto también es mucho. Con PyTorch moderno, la biblioteca de Transformers no es tan relevante. Con
torch.nn.TransformerEncoderLayerel código de modelo similar a RoBERTa toma 100 líneas:
class BERTEmbedding(nn.Module):
def __init__(self, vocab_size, seq_len, emb_dim, dropout=0.1, norm_eps=1e-12):
super(BERTEmbedding, self).__init__()
self.word = nn.Embedding(vocab_size, emb_dim)
self.position = nn.Embedding(seq_len, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.drop = nn.Dropout(dropout)
def forward(self, input):
batch_size, seq_len = input.shape
position = torch.arange(seq_len).expand_as(input).to(input.device)
emb = self.word(input) + self.position(position)
emb = self.norm(emb)
return self.drop(emb)
def BERTLayer(emb_dim, heads_num, hidden_dim, dropout=0.1, norm_eps=1e-12):
layer = nn.TransformerEncoderLayer(
d_model=emb_dim,
nhead=heads_num,
dim_feedforward=hidden_dim,
dropout=dropout,
activation='gelu'
)
layer.norm1.eps = norm_eps
layer.norm2.eps = norm_eps
return layer
class BERTEncoder(nn.Module):
def __init__(self, layers_num, emb_dim, heads_num, hidden_dim,
dropout=0.1, norm_eps=1e-12):
super(BERTEncoder, self).__init__()
self.layers = nn.ModuleList([
BERTLayer(
emb_dim, heads_num, hidden_dim,
dropout, norm_eps
)
for _ in range(layers_num)
])
def forward(self, input, pad_mask=None):
input = input.transpose(0, 1) # torch expects seq x batch x emb
for layer in self.layers:
input = layer(input, src_key_padding_mask=pad_mask)
return input.transpose(0, 1) # restore
class BERTMLMHead(nn.Module):
def __init__(self, emb_dim, vocab_size, norm_eps=1e-12):
super(BERTMLMHead, self).__init__()
self.linear1 = nn.Linear(emb_dim, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.linear2 = nn.Linear(emb_dim, vocab_size)
def forward(self, input):
x = self.linear1(input)
x = F.gelu(x)
x = self.norm(x)
return self.linear2(x)
class BERTMLM(nn.Module):
def __init__(self, emb, encoder, head):
super(BERTMLM, self).__init__()
self.emb = emb
self.encoder = encoder
self.head = head
def forward(self, input):
x = self.emb(input)
x = self.encoder(x)
return self.head(x)
Este no es un prototipo, el código se copia del repositorio de Slovnet . Los transformadores son útiles para leer, hacen mucho trabajo, rellenan el código de los artículos con Arxiv, a menudo la fuente de Python es más clara que la explicación en un artículo científico.
Conjunto de datos sintéticos
Marquemos 700.000 artículos del corpus Lenta.ru con un modelo pesado. Obtenemos un enorme conjunto de datos de entrenamiento sintético. El archivo está disponible en el repositorio de Nerus del proyecto Natasha. El marcado es de muy alta calidad, F1 estima por tokens: PER - 99,7%, LOC - 98,6%, ORG - 97,2%. Ejemplos raros de errores:
ORG────────────── LOC────────────────────────────
241- 4- 10-
<
LOC─── LOC──────
>.
───────────~~~~~~~~~~~
ORG────────────────────~~~~~~~~~~~~~~~~
.
LOC───
<>
~~~~~~~~ LOC──────────────────
.
~~~~ ~~~~~~ LOC───
.
LOC────
-
PER─────────────────────
M&A.
~~~
:
~~~~~~~~~~~~ORG─── LOC──
,
PER─────── LOC───
,
ORG─ LOC─────────────
.
LOC
Alumno modelo
No hubo problemas con la elección de la arquitectura del modelo de maestro pesado, solo había una opción: transformadores. El modelo de estudiante compacto es más difícil, hay muchas opciones. De 2013 a 2018, desde la aparición de word2vec hasta el artículo sobre BERT, la humanidad ideó un montón de arquitecturas de redes neuronales para resolver el problema de NER. Todos tienen un esquema común:
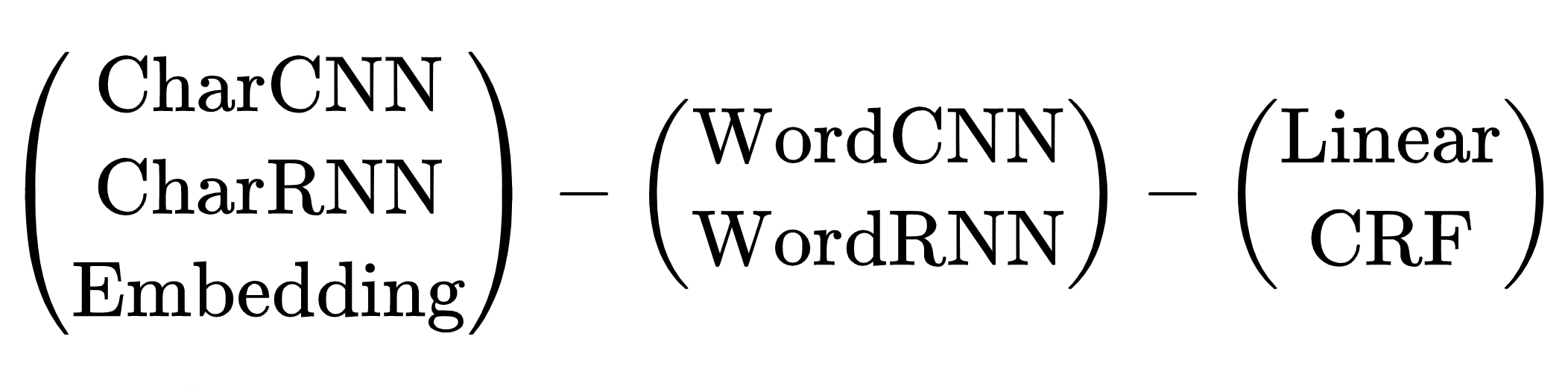
Esquema de arquitecturas de redes neuronales para la tarea NER: codificador de tokens, codificador de contexto, decodificador de etiquetas. Explicaciones de abreviaturas en un artículo de revisión de Yang (2018) .
Hay muchas combinaciones de arquitecturas. ¿Cuál elegir? Por ejemplo, (CharCNN + Embedding) -WordBiLSTM-CRF es un diagrama modelo de un artículo sobre DeepPavlov NER , SOTA para el idioma ruso hasta 2019.
Omitimos las opciones con CharCNN, CharRNN, el lanzamiento de una pequeña red neuronal mediante símbolos en cada token no es nuestro camino, demasiado lento. También me gustaría evitar WordRNN, la solución debería funcionar en la CPU, multiplicar las matrices en cada token lentamente. Para NER, la elección entre Lineal y CRF es condicional. Usamos codificación BIO, el orden de las etiquetas es importante. Tenemos que soportar unos frenos terribles, use CRF. Queda una opción: incrustación de WordCNN-CRF. Este modelo no distingue entre mayúsculas y minúsculas, para NER es importante, "esperanza" es solo una palabra, "esperanza" es posiblemente un nombre. Agregue ShapeEmbedding: incrustación con contornos de token, por ejemplo: "NER" - EN_XX, "Vainovich" - RU_Xx, "!" - PUNCT_!, "Y" - RU_x, "5.1" - NUM, "Nueva York" - RU_Xx-Xx. Esquema Slovnet NER - (WordEmbedding + ShapeEmbedding) -WordCNN-CRF.
Destilación
Entrenemos Slovnet NER en un enorme conjunto de datos sintéticos. Comparemos el resultado con el modelo de maestro pesado Slovnet BERT NER. La calidad se calcula y se promedia sobre la colección 5 marcada manualmente, Gareev, factRuEval-2016, BSNLP-2019. El tamaño de la muestra de entrenamiento es muy importante: para 250 artículos de noticias (factRuEval-2016), el promedio para PER, LOC, LOG F1 es 0.64, para 1000 (análogo a Collection5) - 0.81, para el conjunto de datos completo - 0.91, calidad Slovnet BERT NER - 0.92.
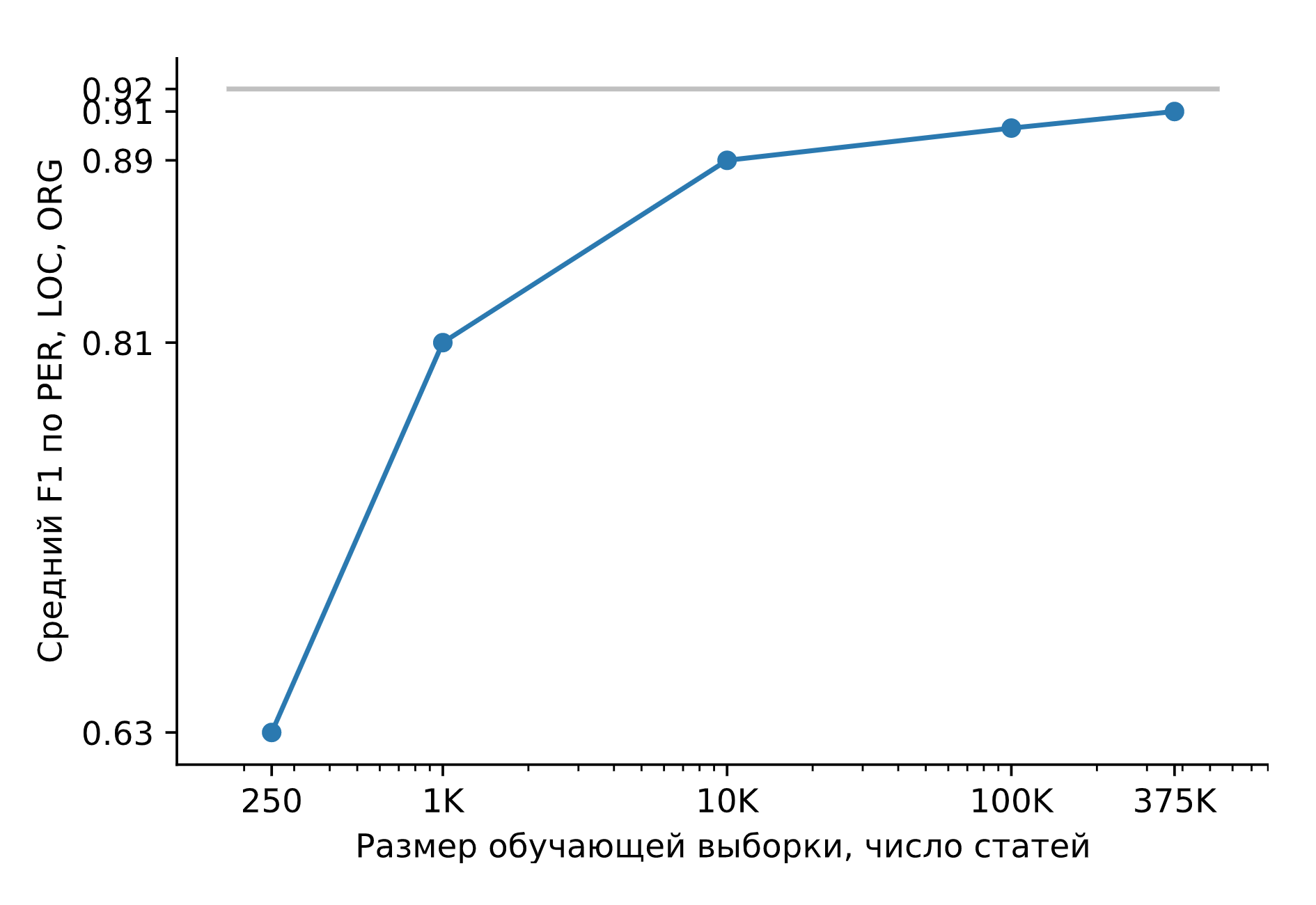
Calidad de Slovnet NER, dependencia del número de ejemplos de entrenamiento sintéticos. Línea gris: calidad Slovnet BERT NER. Slovnet NER no ve ejemplos etiquetados manualmente, solo entrena con datos sintéticos.
El modelo de estudiante primitivo es 1 punto porcentual peor que el modelo de maestro duro. Este es un resultado maravilloso. Se sugiere una receta universal:
Marcamos algunos datos manualmente. Entrenamos un transformador pesado. Generamos muchos datos sintéticos. Entrenamos un modelo simple en una muestra grande. Obtenemos la calidad del transformador, el tamaño y el rendimiento de un modelo simple.
En la biblioteca de Slovnet hay dos modelos más entrenados de acuerdo con esta receta: Slovnet Morph - etiquetador morfológico, Slovnet Syntax - analizador sintáctico. Slovnet Morph está por detrás del modelo de maestro pesado en 2 puntos porcentuales , Slovnet Syntax, en 5 . Ambos modelos tienen mejor calidad y rendimiento que las soluciones rusas existentes para artículos de noticias.
Cuantificación
Slovnet NER tiene un tamaño de 289 MB. 287 MB está ocupado por una mesa con incrustaciones. El modelo utiliza un amplio vocabulario de 250.000 líneas y cubre el 98% de las palabras en los textos de noticias. Usando la cuantificación , reemplace los vectores flotantes de 300 dimensiones con los de 8 bits de 100 dimensiones. El tamaño del modelo se reducirá 10 veces (27 MB), la calidad no cambiará. La biblioteca Navec es parte del proyecto Natasha, una colección de incrustaciones cuantificadas previamente entrenadas. Los pesos entrenados en ficción ocupan 50 MB, sin pasar por todos los modelos estáticos de RusVectores según estimaciones sintéticas .
Inferencia
Slovnet NER usa PyTorch para entrenar. El paquete PyTorch pesa 700 MB, no quiero arrastrarlo a producción para inferencias. PyTorch tampoco funciona con el intérprete de PyPy . Slovnet se usa junto con un analizador Yargy, un análogo del analizador Yandex Tomita . Con PyPy, Yargy trabaja de 2 a 10 veces más rápido, dependiendo de la complejidad de las gramáticas. No quiero perder velocidad debido a la dependencia de PyTorch.
La solución estándar es usar TorchScript o convertir el modelo a ONNX , hacer la inferencia en ONNXRuntime . Slovnet NER utiliza bloques no estándar: incrustaciones cuantificadas, decodificador CRF. TorchScript y ONNXRuntime no son compatibles con PyPy.
Slovnet NER es un modelo simple,implemente manualmente todos los bloques en NumPy , use pesos calculados por PyTorch. Apliquemos un poco de magia NumPy, implementemos cuidadosamente el bloque CNN , el decodificador CRF , desempaquetando la incrustación cuantizada toma 5 líneas . La velocidad de inferencia en la CPU es la misma que con ONNXRuntime y PyTorch, 25 artículos de noticias por segundo en Core i5.
La técnica funciona en modelos más complejos: Slovnet Morph y Slovnet Syntax también se implementan en NumPy. Slovnet NER, Morph y Syntax comparten una tabla de incrustación común. Saquemos los pesos en un archivo separado, la tabla no está duplicada en la memoria y en el disco:
>>> navec = Navec.load('navec_news_v1_1B.tar') # 25MB
>>> morph = Morph.load('slovnet_morph_news_v1.tar') # 2MB
>>> syntax = Syntax.load('slovnet_syntax_news_v1.tar') # 3MB
>>> ner = NER.load('slovnet_ner_news_v1.tar') # 2MB
# 25 + 2 + 3 + 2 25+2 + 25+3 + 25+2
>>> morph.navec(navec)
>>> syntax.navec(navec)
>>> ner.navec(navec)
Limitaciones
Natasha extrae entidades estándar: nombres, nombres de topónimos y organizaciones. La solución muestra buena calidad en las noticias. ¿Cómo trabajar con otras entidades y tipos de textos? Necesitamos entrenar un nuevo modelo. No es fácil de hacer. Pagamos el tamaño compacto y la velocidad del trabajo por la complejidad de la preparación del modelo. Computadora portátil de secuencias de comandos para preparar un modelo de profesor pesado , computadora portátil de secuencias de comandos para un modelo de estudiante , instrucciones para preparar incrustaciones cuantificadas .
Navec - incrustaciones compactas para el idioma ruso

Los modelos compactos son fáciles de trabajar. Se inician rápidamente, usan poca memoria y caben más procesos paralelos en una instancia.
En PNL, el 80-90% de los pesos de los modelos están en la tabla de incrustación. La biblioteca Navec es parte del proyecto Natasha, una colección de incrustaciones previamente entrenadas para el idioma ruso. En términos de métricas de calidad intrínsecas, están ligeramente por debajo de las mejores soluciones de RusVectores , pero el tamaño del archivo con pesos es 5-6 veces más pequeño (51MB), el diccionario es 2-3 veces más grande (500K palabras).
| Calidad * | Tamaño del modelo, MB | Tamaño del diccionario, × 10 3 | |
| Navec | 0,719 | 50,6 | 500 |
| RusVectores | 0,638-0,726 | 220,6–290,7 | 189-249 |
Hablaremos sobre las buenas incorporaciones palabra por palabra que revolucionaron la PNL en 2013. La tecnología sigue siendo relevante hoy. En el proyecto Natasha, los modelos para analizar la morfología , la sintaxis y la extracción de entidades nombradas funcionan en incrustaciones de Navec palabra por palabra y muestran calidad por encima de otras soluciones abiertas .
RusVectores
Para el idioma ruso, se acostumbra utilizar incrustaciones previamente entrenadas de RusVectores , tienen una característica desagradable: la tabla no contiene palabras, sino pares “word_POS-tag”. La idea es buena, para el par "horno_VERB" esperamos un vector similar a "cocinar_VERB", "cocinar_VERB", y para "horno_NOUN" - "hut_NOUN", "horno_NOUN".
En la práctica, es inconveniente utilizar tales incrustaciones. No es suficiente dividir el texto en tokens, para cada uno necesita definir de alguna manera la etiqueta POS. La mesa de empotrar se hincha. En lugar de una palabra "convertirse", almacenamos 6: 2 razonables "convertirse_VERB", "convertirse_NOUN" y 4 extraños "convertirse_ADV", "convertirse_PROPN", "convertirse_NUM", "convertirse_ADJ". Hay 195.000 palabras únicas en una tabla con 250.000 entradas.
Calidad
Estimemos la calidad de las incrustaciones en el problema de proximidad semántica. Tomemos un par de palabras, para cada una encontraremos un vector de incrustación y calcularemos la similitud del coseno. Navec para palabras similares "taza" y "jarra" devolverá 0,49, para "fruta" y "horno" - -0,0047. Recopilemos muchos pares con marcas de referencia de similitud, calculemos la correlación de Spearman con nuestras respuestas.
Los autores de RusVectores utilizan una lista de prueba pequeña, cuidadosamente revisada y revisada de pares SimLex965 . Agreguemos un nuevo Yandex LRWC y conjuntos de datos del proyecto RUSSE : HJ , RT , AE , AE2 :
| Calidad media en 6 conjuntos de datos | Tiempo de carga, segundos | Tamaño del modelo, MB | Tamaño del diccionario, × 10 3 | ||
| Navec | hudlit_12B_500K_300d_100q |
0,719 | 1.0 | 50,6 | 500 |
news_1B_250K_300d_100q |
0,653 | 0,5 | 25,4 | 250 | |
| RusVectores | ruscorpora_upos_cbow_300_20_2019 |
0,692 | 3.3 | 220,6 | 189 |
ruwikiruscorpora_upos_skipgram_300_2_2019 |
0,691 | 5,0 | 290,0 | 248 | |
tayga_upos_skipgram_300_2_2019 |
0,726 | 5.2 | 290,7 | 249 | |
tayga_none_fasttextcbow_300_10_2019 |
0,638 | 8.0 | 2741,9 | 192 | |
araneum_none_fasttextcbow_300_5_2018 |
0,664 | 16,4 | 2752.1 | 195 |
La calidad es
hudlit_12B_500K_300d_100qcomparable o mejor que la de las soluciones de RusVectores, el diccionario es 2-3 veces más grande, el tamaño del modelo es 5-6 veces más pequeño. ¿Cómo obtuviste esta calidad y tamaño?
Principio de funcionamiento
hudlit_12B_500K_300d_100q- Embeddings de GloVe entrenados para 145GB de ficción . Tomaremos el archivo con los textos del proyecto RUSSE . Vamos a utilizar la aplicación Guante original en C y se envuelve en una interfaz de Python conveniente .
¿Por qué no word2vec? Los experimentos en un gran conjunto de datos son más rápidos con GloVe. Una vez que calculemos la matriz de colocación, utilícela para preparar incrustaciones de diferentes dimensiones, elija la mejor opción.
¿Por qué no fastText? En el proyecto Natasha trabajamos con textos de noticias. Hay pocos errores tipográficos en ellos, el problema de los tokens OOV se resuelve con un diccionario grande. 250.000 filas en la tabla
news_1B_250K_300d_100qcubren el 98% de las palabras en los artículos de noticias.
Tamaño del diccionario
hudlit_12B_500K_300d_100q- 500.000 entradas, cubre el 98% de las palabras en textos de ficción. La dimensión óptima de los vectores es 300. Una tabla de 500.000 × 300 de números flotantes ocupa 578 MB, el tamaño del archivo con pesos hudlit_12B_500K_300d_100qes 12 veces menor (48 MB). Se trata de cuantificación.
Cuantificación
Reemplace los números flotantes de 32 bits con códigos de 8 bits: [−∞, −0,86) - código 0, [−0,86, -0,79) - código 1, [-0,79, -0,74) - 2,…, [0,86, ∞) - 255. El tamaño de la mesa se reduce 4 veces (143 MB).
:
-0.220 -0.071 0.320 -0.279 0.376 0.409 0.340 -0.329 0.400
0.046 0.870 -0.163 0.075 0.198 -0.357 -0.279 0.267 0.239
0.111 0.057 0.746 -0.240 -0.254 0.504 0.202 0.212 0.570
0.529 0.088 0.444 -0.005 -0.003 -0.350 -0.001 0.472 0.635
────── ──────
-0.170 0.677 0.212 0.202 -0.030 0.279 0.229 -0.475 -0.031
────── ──────
:
63 105 215 49 225 230 219 39 228
143 255 78 152 187 34 49 204 198
163 146 253 58 55 240 188 191 246
243 155 234 127 127 35 128 237 249
─── ───
76 251 191 188 118 207 195 18 118
─── ───
Los datos son toscos, diferentes valores -0.005 y -0.003 reemplazan un código 127, -0.030 y -0.031 - 118
Reemplacemos con el código no uno, sino 3 números. Agrupamos todos los tripletes de números de la tabla de incrustación usando el algoritmo k-means en 256 grupos, en lugar de cada triplete almacenaremos un código de 0 a 255. La tabla disminuirá 3 veces (48 MB). Navec utiliza la biblioteca PQk-means , divide la matriz en 100 columnas, agrupa cada una por separado, la calidad de las pruebas sintéticas se reducirá en 1 punto porcentual. Es claro acerca de la cuantificación en el artículo Cuantificadores de productos para k-NN .
Las incrustaciones cuantificadas son más lentas que las habituales. El vector comprimido debe desempaquetarse antes de su uso. Implementamos cuidadosamente el procedimiento, aplicamos Numpy magic, en PyTorch usamos torch.gather . En Slovnet NER, el acceso a la tabla de incrustación toma el 0.1% del tiempo total de cálculo.
Un módulo
NavecEmbeddingde la biblioteca Slovnet integra Navec en modelos de PyTorch:
>>> import torch
>>> from navec import Navec
>>> from slovnet.model.emb import NavecEmbedding
>>> path = 'hudlit_12B_500K_300d_100q.tar' # 51MB
>>> navec = Navec.load(path) # ~1 sec, ~100MB RAM
>>> words = ['', '<unk>', '<pad>']
>>> ids = [navec.vocab[_] for _ in words]
>>> emb = NavecEmbedding(navec)
>>> input = torch.tensor(ids)
>>> emb(input) # 3 x 300
tensor([[ 4.2000e-01, 3.6666e-01, 1.7728e-01,
[ 1.6954e-01, -4.6063e-01, 5.4519e-01,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00,
...Nerus es un gran conjunto de datos sintéticos con marcado de morfología, sintaxis y entidades con nombre.

En el proyecto Natasha, la morfología, el análisis de sintaxis y la extracción de entidades nombradas se realizan mediante 3 modelos compactos: Slovnet NER , Slovnet Morph y Slovnet Syntax . La calidad de las soluciones es de 1 a 5 puntos porcentuales peor que la de sus contrapartes pesadas con arquitectura BERT, el tamaño es de 50 a 75 veces menor y la velocidad de la CPU es 2 veces mayor. Los modelos se entrenan en un enorme conjunto de datos sintéticos de Nerus , en un archivo de 700.000 artículos de noticias con marcado CoNLL-U de morfología, sintaxis y entidades con nombre:
# newdoc id = 0
# sent_id = 0_0
# text = - , ...
1 - _ NOUN _ Animacy=Anim|C... 7 nsubj _ Tag=O
2 _ ADP _ _ 4 case _ Tag=O
3 _ ADJ _ Case=Dat|Degre... 4 amod _ Tag=O
4 _ NOUN _ Animacy=Inan|C... 1 nmod _ Tag=O
5 _ PROPN _ Animacy=Anim|C... 1 appos _ Tag=B-PER
6 _ PROPN _ Animacy=Anim|C... 5 flat:name _ Tag=I-PER
7 _ VERB _ Aspect=Perf|Ge... 0 root _ Tag=O
8 , _ PUNCT _ _ 13 punct _ Tag=O
9 _ ADP _ _ 11 case _ Tag=O
10 _ DET _ Case=Loc|Numbe... 11 det _ Tag=O
11 _ NOUN _ Animacy=Inan|C... 13 obl _ Tag=O
12 _ PROPN _ Animacy=Inan|C... 11 nmod _ Tag=B-LOC
13 _ VERB _ Aspect=Perf|Ge... 7 ccomp _ Tag=O
14 _ ADV _ Degree=Pos 15 advmod _ Tag=O
15 _ ADJ _ Case=Nom|Degre... 16 amod _ Tag=O
16 _ NOUN _ Animacy=Inan|C... 13 nsubj _ Tag=O
17 _ ADP _ _ 18 case _ Tag=O
18 _ NOUN _ Animacy=Inan|C... 16 nmod _ Tag=O
19 , _ PUNCT _ _ 20 punct _ Tag=O
20 _ VERB _ Aspect=Imp|Moo... 0 root _ Tag=O
21 _ PROPN _ Animacy=Inan|C... 20 nsubj _ Tag=B-ORG
22 _ PROPN _ Animacy=Inan|C... 21 appos _ Tag=I-ORG
23 . _ PUNCT _ _ 20 punct _ Tag=O
# sent_id = 0_1
# text = , , , ...
1 _ ADP _ _ 2 case _ Tag=O
2 _ NOUN _ Animacy=Inan|C... 9 parataxis _ Tag=O
...Slovnet NER, Morph, Syntax - modelos primitivos. Cuando hay 1000 ejemplos en el conjunto de entrenamiento, Slovnet NER se queda atrás del análogo pesado BERT en 11 puntos porcentuales, cuando 10,000 ejemplos - por 3 puntos, cuando 500,000 - por 1.
Nerus es el resultado del trabajo, modelos pesados con arquitectura BERT: Slovnet BERT NER , Slovnet BERT Morph , Sintaxis de Slovnet BERT . Procesar 700.000 artículos de noticias lleva 20 horas en el Tesla V100. Ahorramos el tiempo de otros investigadores, ponemos el archivo terminado en acceso abierto. En SpaCy-Ru enseñe en Nerus el modelo cualitativo para el SpaCy de habla rusa, prepare un parche en el repositorio oficial.

El marcado sintético tiene una alta calidad: la precisión para determinar las etiquetas morfológicas es del 98%, los enlaces sintácticos, el 96%. Para NER, F1 estimaciones por tokens: PER - 99%, LOC - 98%, ORG - 97%. Para evaluar la calidad, marcamos SynTagRus , Collection5 y el segmento de noticias GramEval2020 , comparamos el marcado de referencia con el nuestro, para más detalles en el repositorio de Nerus . Debido a errores en el marcado de sintaxis, hay bucles y raíces múltiples, las etiquetas POS a veces no se corresponden con los bordes sintácticos. Es útil usar el validador de Universal Dependencies , omita estos ejemplos.
El paquete de Python Nerus organiza una interfaz conveniente para cargar y representar el marcado:
>>> from nerus import load_nerus
>>> docs = load_nerus('nerus_lenta.conllu.gz')
>>> doc = next(docs)
>>> doc
NerusDoc(
id='0',
sents=[NerusSent(
id='0_0',
text='- , ...',
tokens=[NerusToken(
id='1',
text='-',
pos='NOUN',
feats={'Animacy': 'Anim',
'Case': 'Nom',
'Gender': 'Masc',
'Number': 'Sing'},
head_id='7',
rel='nsubj',
tag='O'
),
NerusToken(
id='2',
text='',
pos='ADP',
...
>>> doc.ner.print()
- ,
PER───────────── LOC───
, . ,
ORG──────── PER──────
...
>>> sent = doc.sents[0]
>>> sent.morph.print()
- NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
ADP
ADJ|Case=Dat|Degree=Pos|Number=Plur
NOUN|Animacy=Inan|Case=Dat|Gender=Masc|Number=Plur
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
VERB|Aspect=Perf|Gender=Fem|Mood=Ind|Number=Sing
...
>>> sent.syntax.print()
┌►┌─┌───── - nsubj
│ │ │ ┌──► case
│ │ │ │ ┌► amod
│ │ └►└─└─ nmod
│ └────►┌─ appos
│ └► flat:name
┌─└─────────
│ ┌──────► , punct
│ │ ┌──► case
│ │ │ ┌► det
│ │ ┌►└─└─ obl
│ │ │ └──► nmod
└──►└─└───── ccomp
│ ┌► advmod
│ ┌►└─ amod
└►┌─└─── nsubj:pass
│ ┌► case
└──►└─ nmod
┌► , punct
┌─┌─└─
│ └►┌─ nsubj
│ └► appos
└────► . punct
Instrucciones de instalación, ejemplos de uso , evaluaciones de calidad en el repositorio de Nerus.
Corus: una colección de enlaces a conjuntos de datos públicos en ruso + funciones para descargar

La biblioteca Corus es parte del proyecto Natasha, una colección de enlaces a conjuntos de datos públicos de PNL en idioma ruso + paquete Python con funciones de carga. Lista de enlaces a fuentes , instrucciones de instalación y ejemplos de uso en el repositorio de Corus.
>>> from corus import load_lenta
# Corus Lenta.ru, :
# wget https://github.com/yutkin/Lenta.Ru-News-Dataset/...
>>> path = 'lenta-ru-news.csv.gz'
>>> records = load_lenta(path) # 2, 750 000
>>> next(records)
LentaRecord(
url='https://lenta.ru/news/2018/12/14/cancer/',
title=' \xa0 ...',
text='- ...',
topic='',
tags=''
)
Los conjuntos de datos abiertos útiles para el idioma ruso están tan bien ocultos que pocas personas los conocen.
Ejemplos de
Corpus de artículos periodísticos
Queremos entrenar el modelo de lenguaje en artículos periodísticos, necesitamos muchos textos. Lo primero que me viene a la mente es una porción de noticias del conjunto de datos de Taiga (~ 1GB). Mucha gente conoce el volcado de Lenta.ru (2GB). Otras fuentes son más difíciles de encontrar. En 2019, Dialogue organizó una competencia para generar titulares , los organizadores prepararon un volcado de RIA Novosti durante 4 años (3.7GB). En 2018, Yuri Baburov publicó una carga de 40 recursos de noticias en ruso (7,5 GB). Los voluntarios de ODS comparten archivos (7GB) recopilados para el proyecto sobre el análisis de la agenda de noticias .
En el registro de Corusenlaces a esos conjuntos de datos etiquetados «noticias», para todas las fuentes tienen una función de cargadores:
load_taiga_*, load_lenta, load_ria, load_buriy_*, load_ods_*.
NER
Queremos enseñar NER para el idioma ruso, necesitamos textos anotados. En primer lugar, recordamos los datos de la competencia factRuEval-2016 . El marcado tiene inconvenientes: su formato complejo, los tramos de entidad se superponen, hay categorías de "LocOrg" ambiguas. No todo el mundo conoce la colección Named Entities 5, la sucesora de Persons-1000 . Diseño en formato estándar , los tramos no se cruzan, ¡belleza! Las otras tres fuentes son conocidas solo por los fanáticos más dedicados de la NER de habla rusa. Escribiremos a Rinat Gareev por correo, adjuntaremos un enlace a su artículo de 2013 , en respuesta recibiremos 250 artículos de noticias con nombres y organizaciones etiquetados. El concurso BSNLP-2019 se celebró en 2019sobre NER para lenguas eslavas, escribiremos a los organizadores, obtendremos 450 textos más marcados. Al proyecto WiNER se le ocurrió la idea de hacer un marcado NER semiautomático a partir de volcados de Wikipedia , una gran descarga para ruso está disponible en Github .
Enlaces y funciones para cargar el registro Corus:
load_factru, load_ne5, load_gareev, load_bsnlp, load_wikiner.
Colección de enlaces
Antes de obtener un gestor de arranque e ingresar al registro, los enlaces a las fuentes se acumulan en la sección de Tickets . La colección de 30 conjuntos de datos: una nueva versión de Taiga , texto 568GB rusa de rastreo del Común , opiniones c Banki.ru y Auto.ru . Te invitamos a compartir tus hallazgos, crear tickets con enlaces.
Funciones del cargador
El código para un conjunto de datos simple es fácil de escribir. El volcado de Lenta.ru está bien formado, la implementación es simple . Taiga consta de ~ 15 millones de archivos CoNLL-U , empaquetados en archivos zip. Para que la descarga funcione rápidamente, no use mucha memoria y no arruine el sistema de archivos, debe confundirse, implementar cuidadosamente el trabajo con archivos zip en un nivel bajo .
Para 35 fuentes, el paquete Corus Python tiene funciones de cargador. La interfaz para acceder a Taiga no es más complicada que el volcado de Lenta.ru:
>>> from corus import load_taiga_proza_metas, load_taiga_proza
>>> path = 'taiga/proza_ru.zip'
>>> metas = load_taiga_proza_metas(path)
>>> records = load_taiga_proza(path, metas)
>>> next(records)
TaigaRecord(
id='20151231005',
meta=Meta(
id='20151231005',
timestamp=datetime.datetime(2015, 12, 31, 23, 40),
genre=' ',
topic='',
author=Author(
name='',
readers=7973,
texts=92681,
url='http://www.proza.ru/avtor/sadshoot'
),
title=' !',
url='http://www.proza.ru/2015/12/31/1875'
),
text='... ...\n... ..\n...
)
Invitamos a los usuarios a realizar solicitudes de extracción, enviar sus funciones de cargador, una breve instrucción en el repositorio de Corus.
Naeval: comparación cuantitativa de sistemas para PNL de habla rusa

Natasha no es un proyecto científico, no hay un objetivo para vencer a SOTA, pero es importante verificar la calidad en los puntos de referencia públicos, para tratar de tomar un lugar destacado sin perder mucho en rendimiento. Como hacen en la academia: miden la calidad, obtienen un número, toman tabletas de otros artículos, comparan estos números con los suyos. Este esquema tiene dos problemas:
- Olvídate del rendimiento. No comparan el tamaño del modelo, la velocidad de trabajo. El énfasis está solo en la calidad.
- No publiques el código. Por lo general, hay un millón de matices en el cálculo de una métrica de calidad. ¿Cómo se contó exactamente en otros artículos? Desconocido.
Naeval es parte del proyecto Natasha, un conjunto de scripts para evaluar la calidad y la velocidad de las herramientas de código abierto para procesar el idioma ruso natural:
| Tarea | Conjuntos de datos | Soluciones |
| Tokenización | SynTagRus, OpenCorpora, GICRYA, RNC
|
SpaCy, NLTK, MyStem, Moses, SegTok, SpaCy Russian Tokenizer, RuTokenizer, Razdel
|
| SynTagRus, OpenCorpora, GICRYA, RNC
|
SegTok, Moses, NLTK, RuSentTokenizer, Razdel
|
|
| SimLex965, HJ, LRWC, RT, AE, AE2
|
RusVectores, Navec
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov Morph, DeepPavlov BERT Morph, RuPosTagger, RNNMorph, Maru, UDPipe, SpaCy, Stanza, Slovnet Morph, Slovnet BERT Morph
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov BERT Syntax, UDPipe, SpaCy, Stanza, Slovnet Syntax, Slovnet BERT Syntax
|
|
| NER | factRuEval-2016, Collection5, Gareev, BSNLP-2019, WiNER
|
DeepPavlov NER , DeepPavlov BERT NER , DeepPavlov Slavic BERT NER , PullEnti , SpaCy , Stanza , Texterra , Tomita , MITIE , Slovnet NER , Slovnet BERT NER
|
Echemos un vistazo más de cerca al problema NER a continuación.
Conjuntos de datos
Hay 5 puntos de referencia públicos para el NER de habla rusa: factRuEval-2016 , Collection5 , Gareev , BSNLP-2019 , WiNER . Los enlaces de origen se recopilan en el registro de Corus . Todos los conjuntos de datos consisten en artículos de noticias, subcadenas con nombres, nombres de organizaciones y nombres de lugares que están marcados en los textos. ¿Qué podría ser más fácil?
Todas las fuentes tienen un formato de marcado diferente. Collection5 utiliza el formato Standoff de las utilidades Brat , Gareev y WiNER: diferentes dialectos de marcado BIO , BSNLP-2019 tiene su propio formato , factRuEval-2016 también tiene su propia especificación no trivial... Naeval convierte todas las fuentes a un formato común. El marcado consta de intervalos. Intervalo: tres: tipo de entidad, comienzo y final de la subcadena.
Tipos de entidad. factRuEval-2016 y Collection5 marcan por separado medios nombres-semi-organizaciones: "Kremlin", "UE", "URSS". BSNLP-2019 y WiNER destacan los nombres de los eventos: "Campeonato de Rusia", "Brexit". Naeval adapta y elimina algunas de las etiquetas, deja las etiquetas de referencia PER, LOC, ORG: nombres de personas, nombres de topónimos y organizaciones.
Tramos anidados. De hecho RuEval-2016, los tramos se superponen. Naeval simplifica el marcado:
:
, 5 Retail Group,
org_name───────
Org────────────
"", "" "",
org_descr───── org_name─ org_name─── org_name
Org──────────────────────
org_descr─────
Org─────────────────────────────────────
org_descr─────
Org──────────────────────────────────────────────────
, .
:
, 5 Retail Group,
ORG────────────
"", "" "",
ORG────── ORG──────── ORG─────
, .
Modelos
Naeval compara 12 soluciones abiertas con el problema NER ruso. Todas las herramientas están empaquetadas en contenedores Docker con una interfaz web:
$ docker run -p 8080:8080 natasha/tomita-algfio
2020-07-02 11:09:19 BIN: 'tomita-linux64', CONFIG: 'algfio'
2020-07-02 11:09:19 Listening http://0.0.0.0:8080
$ curl -X POST http://localhost:8080 --data \
' \
\
'
<document url="" di="5" bi="-1" date="2020-07-02">
<facts>
<Person pos="18" len="16" sn="0" fw="2" lw="3">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
<Person pos="67" len="14" sn="0" fw="8" lw="9">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
</facts>
</document>
Algunas soluciones son tan difíciles de ejecutar y configurar que pocas personas las usan. PullEnti , un sofisticado sistema basado en reglas, ocupó el primer lugar en la competencia factRuEval en 2016. La herramienta se distribuye como un SDK para C #. El trabajo en Naeval se convirtió en un proyecto separado con un conjunto de envoltorios para PullEnti: PullentiServer - un servidor web en C #, pullenti-client - un cliente Python para PullentiServer:
$ docker run -p 8080:8080 pullenti/pullenti-server
2020-07-02 11:42:02 [INFO] Init Pullenti v3.21 ...
2020-07-02 11:42:02 [INFO] Load lang: ru, en
2020-07-02 11:42:03 [INFO] Load analyzer: geo, org, person
2020-07-02 11:42:05 [INFO] Listen prefix: http://*:8080/
>>> from pullenti_client import Client
>>> client = Client('localhost', 8080)
>>> text = ' ' \
... ' ' \
... ' '
>>> result = client(text)
>>> result.graph
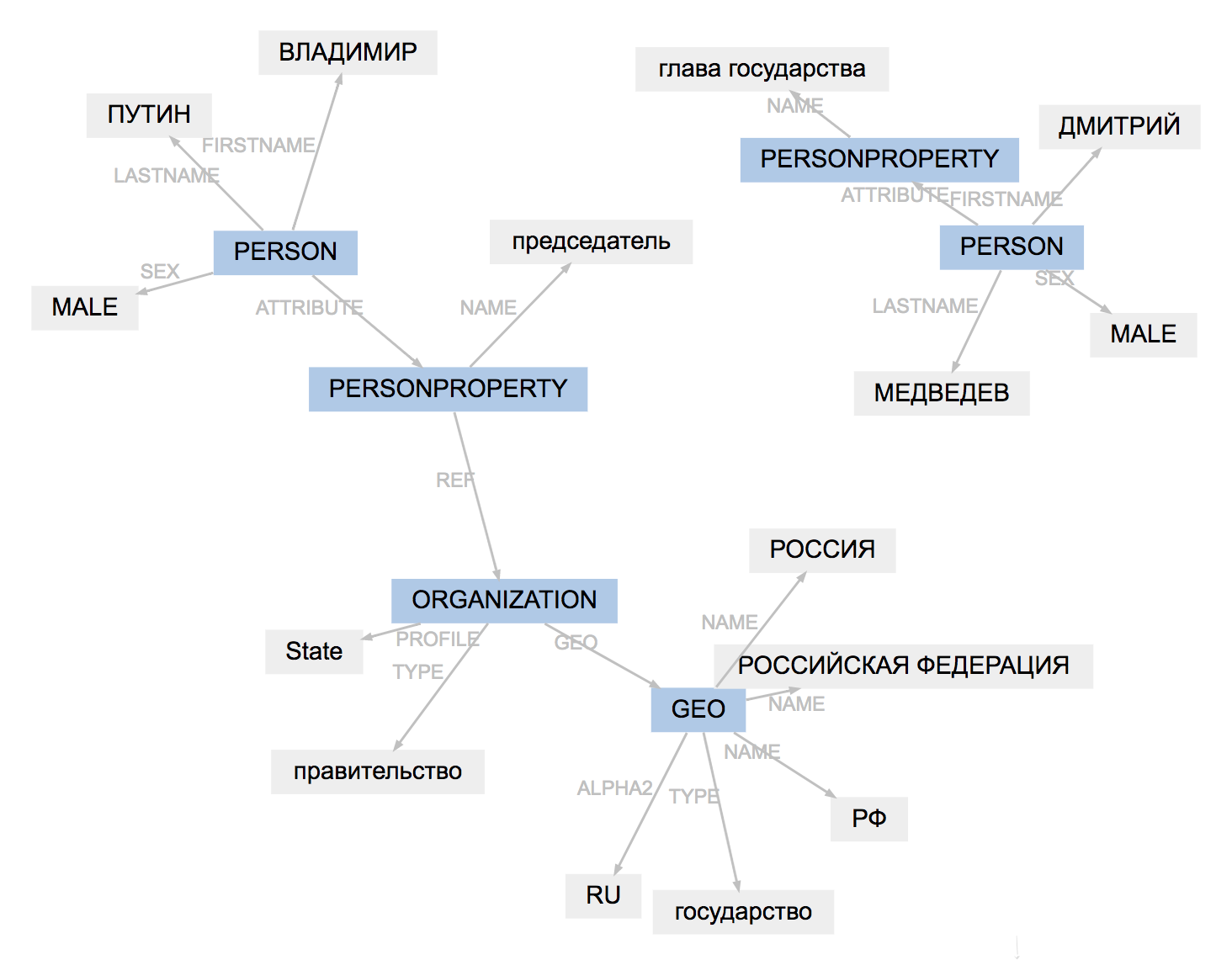
El formato de marcado para todas las herramientas es ligeramente diferente. Resultados de cargas navales, adapta tipos de entidades, simplifica la estructura de vanos:
(PullEnti):
, 19
ORGANIZATION──────────
GEO─────────
PERSON────────────────
PERSONPROPERTY───────
──────────────── PERSON───────────────────────
PERSONPROPERTY──────────────
ORGANIZATION───
.
────────────────
:
, 19
ORG────── LOC─────────
PER───────────── ORG────────────
.
PER─────────────
El resultado del trabajo de PullEnti es más difícil de adaptar que el marcado factRuEval-2016. El algoritmo elimina la etiqueta PERSONPROPERTY, divide la PERSON, ORGANIZATION y GEO anidados en PER, LOC, ORG que no se superponen.
Comparación
Para cada par de "modelo, conjunto de datos", Naeval calcula la medida F1 mediante fichas y publica una tabla con puntuaciones de calidad .
Natasha no es un proyecto científico, la practicidad de la solución es importante para nosotros. Naeval mide el tiempo de inicio, la velocidad de ejecución, el tamaño del modelo y el consumo de RAM. Tabla con resultados en el repositorio .
Preparamos conjuntos de datos, envolvimos 20 sistemas en contenedores Docker y calculamos métricas para otras 5 tareas de PNL en ruso, resultados en el repositorio Naeval: tokenización , segmentación en oraciones , incrustaciones , morfología y análisis de sintaxis .
Yargy- —

El analizador Yargy es un análogo del analizador Yandex Tomita para Python. Instrucciones de instalación , ejemplo de uso , documentación en el repositorio de Yargy. Las reglas para extraer entidades se describen utilizando gramáticas y diccionarios libres de contexto . Hace dos años escribí en Habr un artículo sobre Yargy y la biblioteca de Natasha , hablando de cómo resolver el problema de NER para el idioma ruso. El proyecto fue bien recibido. Yargy-parser reemplazó a Tomita en grandes proyectos dentro de Sberbank, Interfax y RIA Novosti. Han aparecido muchos materiales educativos. Un gran video de un taller en Yandex, una hora y media sobre el proceso de desarrollo de gramáticas con ejemplos:
Se actualizó la documentación, peiné la sección introductoria y el libro de referencia . Lo más importante es que ha aparecido el Cookbook , una sección con prácticas útiles. Contiene respuestas a las preguntas más frecuentes de t.me/natural_language_processing :
- cómo omitir parte del texto ;
- cómo enviar tokens, no texto ;
- qué hacer si el analizador se ralentiza .
El analizador Yargy es una herramienta compleja. El libro de cocina describe los puntos no obvios que surgen cuando se trabaja con grandes conjuntos de reglas:
- orden de argumentos en or_ ;
- gramáticas ambiguas ;
- ¿Por qué está el argumento del etiquetador en Parser ?
Tenemos varios servicios grandes que se ejecutan en el laboratorio de Yargy. Releí el código, los patrones recopilados en el libro de cocina que no se describen en el público:
- generación de reglas ;
- hecho de herencia (especialmente útil, ninguna solución en la práctica puede prescindir de esta técnica).
Después de leer la documentación, es útil mirar el repositorio con ejemplos :
El proyecto Natasha también tiene un repositorio de uso de Natasha . Aquí es donde va el código de los usuarios del analizador Yargy publicado en Github. El 80% de los enlaces son proyectos educativos, pero también hay ejemplos informativos:
- análisis de la información sobre el trabajo del metro en San Petersburgo ;
- análisis de anuncios para la entrega de viviendas en redes sociales ;
- extracción de atributos de los nombres de neumáticos de automóviles ;
- analizar las vacantes del canal de trabajos del chat ODS ;
Los casos más interesantes de uso del analizador Yargy, por supuesto, no se publican públicamente en Github. Escriba a PM si la empresa utiliza Yargy y, si no le importa, agregue su logotipo a natasha.github.io .
Ipymarkup: visualización del marcado de entidades con nombre y relaciones sintácticas

Ipymarkup es una biblioteca primitiva necesaria para resaltar subcadenas en el texto, visualización NER. Instrucciones de instalación , ejemplo de uso en el repositorio de Ipymarkup. La biblioteca es similar a DisplaCy y DisplaCy ENT , invaluable para depurar gramáticas para el analizador Yargy.
>>> from yargy import Parser
>>> from ipymarkup import show_span_box_markup as show_markup
>>> parser = Parser(...)
>>> text = '...'
>>> matches = parser.findall(text)
>>> spans = [_.span for _ in matches]
>>> show_markup(text, spans)

El proyecto Natasha tiene una solución al problema de análisis . Era necesario no solo resaltar palabras en el texto, sino también dibujar flechas entre ellas. Hay muchas soluciones listas para usar, incluso hay un artículo científico sobre el tema .
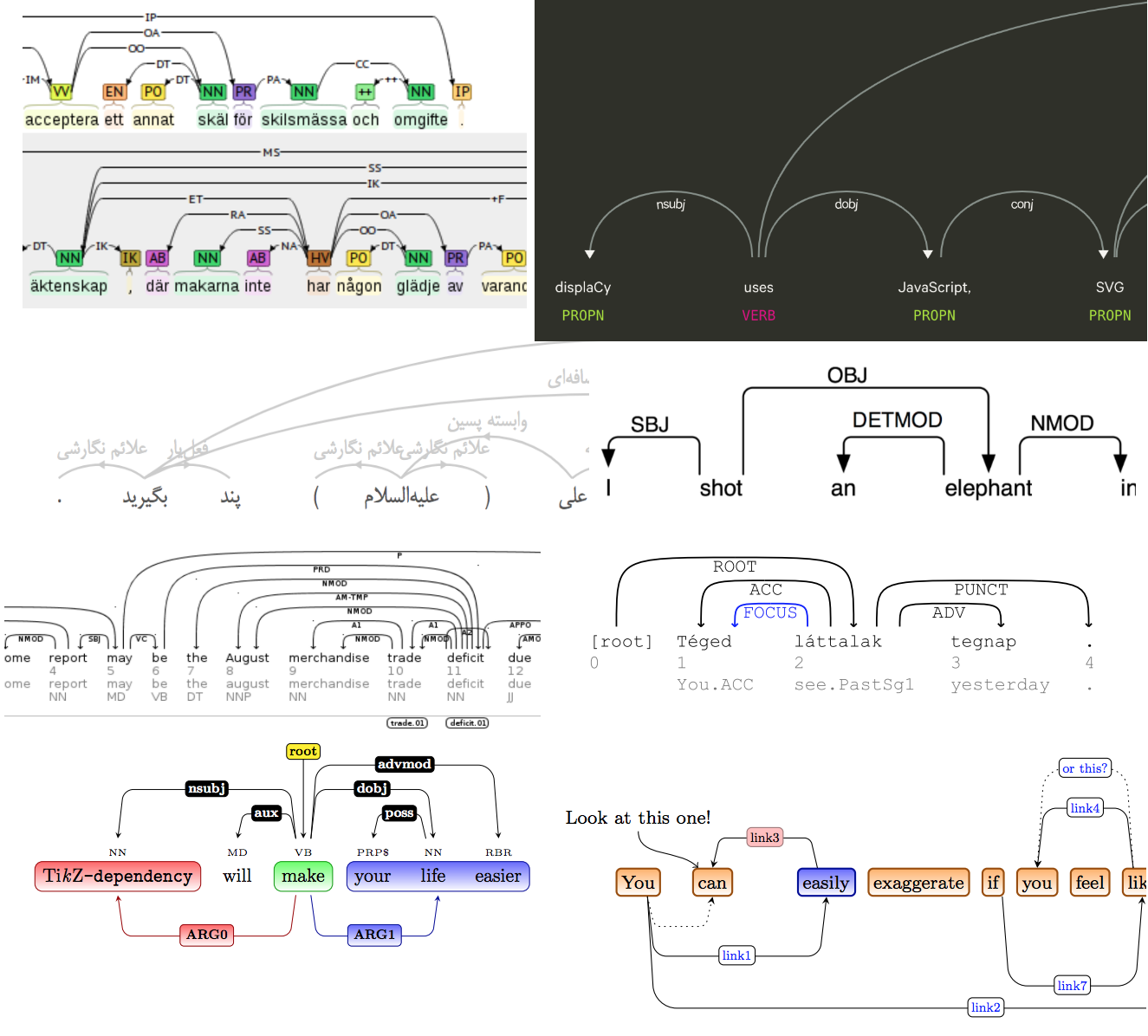
Por supuesto, ninguno de los existentes encajaba, y un día me confundí mucho, apliqué toda la famosa magia de CSS y HTML, agregué una nueva visualización a Ipymarkup. Instrucciones de uso en el muelle.
>>> from ipymarkup import show_dep_markup
>>> words = ['', '', '', '', '', '', '-', '', '', '', '', '', '', '', '.']
>>> deps = [(2, 0, 'case'), (2, 1, 'amod'), (10, 2, 'obl'), (2, 3, 'nmod'), (10, 4, 'obj'), (7, 5, 'compound'), (5, 6, 'punct'), (4, 7, 'nmod'), (9, 8, 'case'), (4, 9, 'nmod'), (13, 11, 'case'), (13, 12, 'nummod'), (10, 13, 'nsubj'), (10, 14, 'punct')]
>>> show_dep_markup(words, deps)
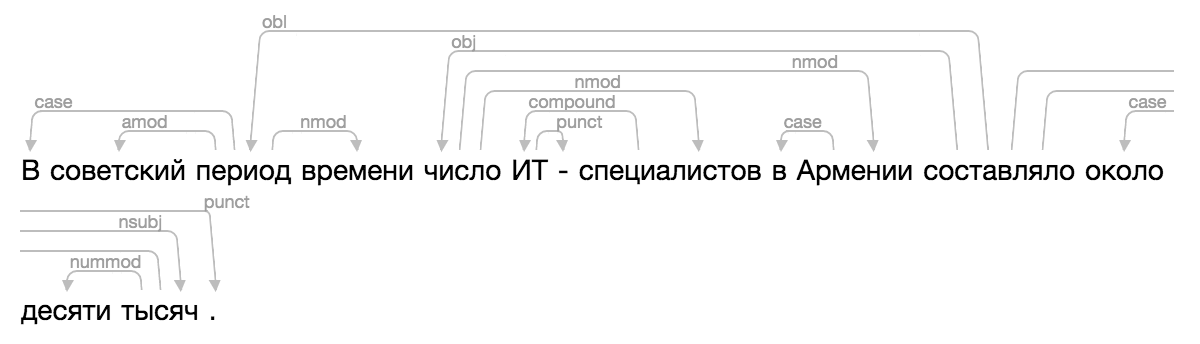
Ahora en Natasha y Nerus es conveniente ver los resultados del análisis.
