Los científicos de datos descubren en qué están interesadas las personas y en qué gastan su dinero
En el curso de la investigación de varias audiencias, los científicos de datos observan hechos tanto naturales como sorprendentes que caracterizan vívidamente a la sociedad que nos rodea. En este artículo hablaré de aquellas curiosidades y casos insólitos que noté al realizar tareas relacionadas con el análisis de auditorías, investigando los intereses de los internautas y el comportamiento de compra de diversos grupos sociales.
¿Qué características sociológicas se han identificado mediante el uso de modelos de aprendizaje automático? ¿Qué sabemos de los clientes?

¿Perfil de cliente de su cheque? ¡Fácil!
Trabajo como analista de datos en CleverDATA y generalmente me enfrento a las siguientes tareas: clasificación de datos sin procesar, análisis de auditoría y construcción de modelos de apariencia similar (LaL), cuando el cliente tiene su propia audiencia y le gustaría encontrar una similar. Tiene una gran demanda para varias campañas publicitarias en línea.
Tenemos 1DMC DATA Exchange donde los miembros pueden enriquecer y monetizar sus datos. Contiene datos despersonalizados de dos tipos, agregados a los atributos de nuestra taxonomía: compras en línea y flujo de clics, es decir, la secuencia de visitas a la página que pudimos rastrear. El formato de los datos cumple con el estándar europeo GDPR para la protección de datos personales.
Los atributos de nuestra taxonomía son los hechos de propiedad de una cosa o la presencia de cierto interés en una persona. Esta es información binaria, ya sea allí o no.
A continuación, se muestran algunos ejemplos de nuestros atributos de taxonomía:

Una de las tareas más importantes es la agregación de datos sin procesar del proveedor en atributos de taxonomía, es decir, la tarea de clasificación.
Necesito sacar conclusiones sobre las compras de las personas sobre su estilo de vida y la presencia de ciertas cosas (condicionalmente, un cheque para un modelo de Street Rod de marca probablemente indica que el comprador es el propietario de una motocicleta Harley-Davidson) o identificar el interés potencial en compras de a través de las páginas de Internet que visitan. Esta información se utilizará luego para publicidad dirigida.

En el transcurso de mi trabajo, aparecen las siguientes cadenas:
- comprobar - mis modelos de IA - perfil de comprador;
- haga clic en flujo - mis modelos de IA - perfil de visitante del sitio.
La herramienta que usamos en CleverDATA construirá automáticamente un clasificador binario para cualquier atributo de nuestra taxonomía. A partir del nombre mismo del atributo de taxonomía (el propietario del atributo de motocicleta chopper), terminamos con un clasificador binario ya evaluado automáticamente (si el modelo es bueno o si es necesario mejorar la analítica), que puede determinar la presencia o ausencia de dicho elemento en una persona mediante un cheque. Puedes leer más sobre esto en nuestro artículo sobre Habré .

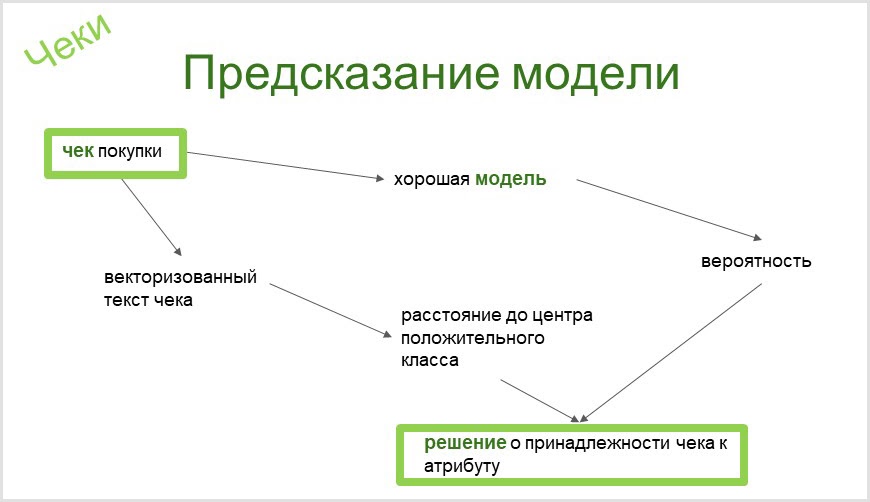
Al clasificar cheques, necesita una herramienta que le permita separar cheques que son similares en palabras de los que tienen un significado similar. Entonces, de alguna manera construí un modelo para captar el interés en los cursos de reciclaje profesional. E identificó el cheque por la compra del libro infantil de Paolo Cossi "Un curso de lecciones de magia para un gato ordinario" como un interés en el tema. Este es, por supuesto, un gracioso error. Por cierto, me enteré de la existencia del libro a partir de este cheque.

Para evitar tales curiosidades, usamos modelos de lenguaje para evaluar los clasificadores binarios resultantes y cortamos aquellos ejemplos que son similares en palabras, pero no en significado.
De vez en cuando tengo que revisar los recibos con los ojos para encontrar algunas coincidencias falsas y, posteriormente, automatizar la búsqueda de conexiones construidas erróneamente. Puede ser útil llegar al fondo porque quizás un solo caso incomprensible me permitirá mejorar todo el proceso.
A lo largo de toda mi práctica, he acumulado un conjunto completo de verificaciones de acertijos que no solo pude clasificar, sino incluso descifrar qué compró exactamente el comprador. Comparto regularmente estos divertidos casos con colegas e incluso comencé la columna de "bromas de IA".
La pista más común es la indicación en el cheque del título del libro sin el nombre del producto. Esto es exactamente lo que vemos en el caso de "magia para un gato común". Y qué compras se registran en el cheque "Fence Novosibirsk 1029 rublos". y "Contract-box 5000 rublos". Todavía no entiendo. Acepto sus versiones en los comentarios de este artículo.
A continuación, pasemos a la clasificación del flujo de clics.
Perfil del cliente por sus movimientos en el sitio web
El sistema de clasificación de flujo de clics fue introducido por nosotros en 2019, que fue rico en avances en el campo de la PNL (procesamiento del lenguaje natural). Uno de los inventos más exitosos y de más alto perfil en esta área es la red BERT ( Representaciones de codificador bidireccional de Transformers ). Entonces habrá un poco de Bertología por delante.

A partir del nombre del atributo, utilizando un modelo de lenguaje probabilístico, obtenemos una lista aumentada (ampliada con sinónimos) de consultas que rastreamos (enviamos a un motor de búsqueda y recopilamos resultados de búsqueda), de ahí se obtiene nuestra muestra de entrenamiento. Vectoricémoslo usando el modelo de lenguaje BERT previamente entrenado. Usando las incrustaciones obtenidas (vectores), entrenamos el clasificador (con la función de pérdida de triplete).
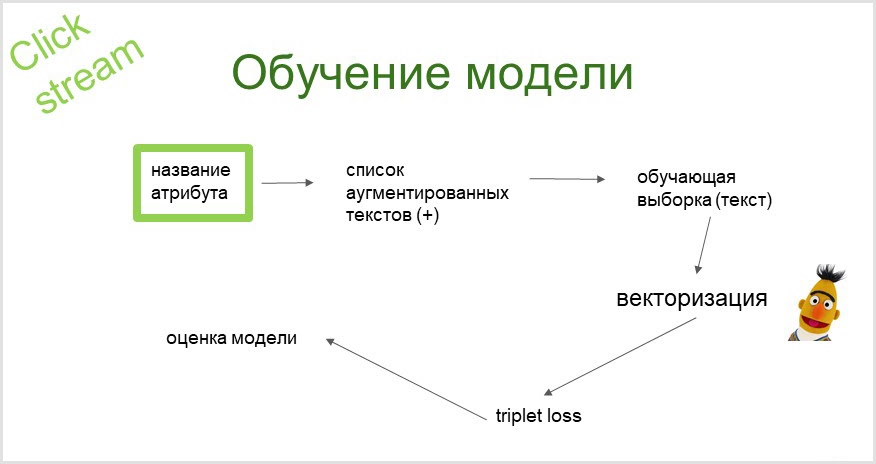
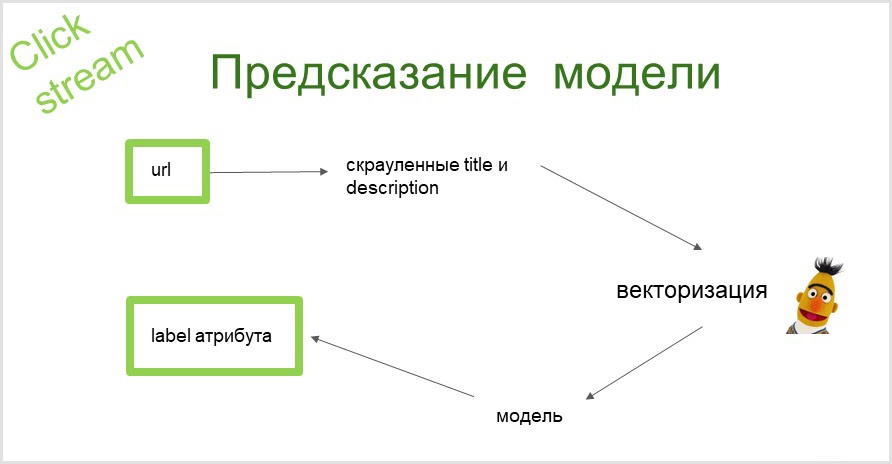
¿Cómo funciona la predicción?
Tomamos la url de la página, recopilamos información de texto (título y descripción de la página). Con la ayuda de BERT, obtenemos una representación vectorial de estos textos. Luego, estos vectores se introducen en el modelo y en la salida obtenemos un atributo al que podemos referirnos a la página.
En general, este sistema tiene mucho éxito, todos los casos divertidos que encontré son más bien excepciones que la regla. Pero trato de prestarles mucha atención, porque un pequeño error puede tener grandes consecuencias desagradables, ya que una gran cantidad de datos pasan por el sistema.
Los datos en línea que investigué mostraron que la gente lee más en Internet. Resultó que este es uno de los temas más populares: astrología, adivinación, etc.

Estas páginas específicas (URL, no dominios) fueron visitadas por más de 5000 mil personas (identificadores únicos) por día. Me llamó especialmente la atención el sitio dedicado a la astrología de los gatos y que revela la conexión entre el carácter del animal y su signo zodiacal.

Todo el mundo conoce las palabras vacías y por lo general conectan diccionarios o filtran por frecuencias sin profundizar en los detalles de los textos. Al principio, también conecté mis diccionarios. El resultado no fue agradable: el sitio de recetas sin utilizar productos horneados se clasificó como un atributo de interés en la repostería (repostería casera). Y esto se debe al hecho de que todas las partículas negativas estaban presentes en mi diccionario de palabras vacías.

Utilizando mi ejemplo, insto a mis colegas a leer detenidamente los diccionarios con los que filtra sus datos.
Otro problema común es que la gente suele utilizar un lenguaje sarcástico que, durante la etapa de rastreo, conduce a frases divertidas en el título y descripción de páginas relacionadas con determinadas consultas en Internet. Por ejemplo, el modelo puede vincular las empanadas y el interés en una dieta vegetariana. Me parece que esto puede explicarse por la abundancia de comentarios sobre artículos sobre el tema del vegetarianismo en el espíritu de "¿Cómo se vive sin empanadas?"

Y ahora un minuto de humor negro en nuestro título "Bromas de IA": el modelo conectó la discusión sobre la legalización de la eutanasia con el interés en comprar una casa, y el rapero Timati - con un circo. Tuve que rastrear los datos y volver a marcar manualmente la clase.
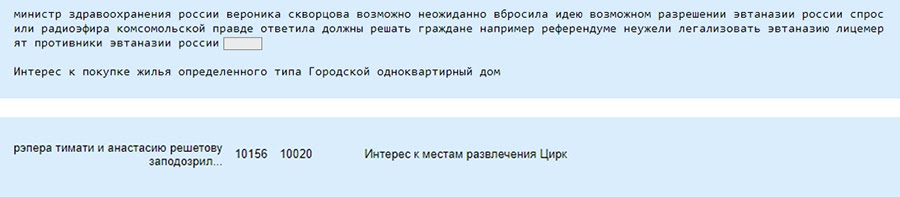
Hay configuraciones que no podemos controlar, dependen de la sociedad en la que vivimos. Y luego el crimen se mezcla con comedias y relaciones familiares.

Y también hay casos polémicos en los que ni siquiera se sabe si merece la pena regañar el modelo y rediseñar algo, luchar con errores, o dejar todo como está.
Es posible que la recepción de paquetes conlleve un riesgo comercial.
Cualquier cosa se puede encontrar en el tablón de anuncios.

Busque una audiencia similar
El siguiente bloque de tareas que yo, como analista, tengo que resolver es la investigación de audiencias / modelos similares. El cliente, por regla general, quiere algún conocimiento nuevo sobre la audiencia, lo que debería ayudarlo a establecer comunicación con ella. Pero incluso si su solicitud no está claramente formulada, siempre tratamos de ayudarlo y, en la mayoría de los casos, lo logramos.
Aquí tiene la opción de centrarse en la investigación de la audiencia, es decir, en los conocimientos internos (análisis de inteligencia de la audiencia) o en un modelo similar, que luego le permitirá acelerar la audiencia de nuestro intercambio y encontrar clientes potenciales en función de los datos internos del cliente sobre la audiencia objetivo. Una audiencia se entiende como un conjunto de identificadores codificados (números de teléfono, direcciones de correo electrónico o identificación en línea). Te recuerdo que no trabajamos con datos de forma abierta, cumplimos con todas las normas de la ley.
Entonces, podemos cruzar muchos identificadores codificados con el intercambio y ver el comportamiento de compra o su flujo de clics. Hacemos clustering para cualquier público objetivo y cualquier tarea. Después de que el modelo agrupó a las personas según su comportamiento de compra, de alguna manera vi un grupo formado solo por personas que apuestan en deportes y ya no compran nada en línea. Aunque, es posible que tengan algún tipo de cuentas separadas para propósitos de creación de apuestas.
Aquí hay una captura de pantalla de este grupo.

Caso "Maternidad feliz"
Para una campaña publicitaria para una marca conocida de pañales, era necesario realizar una investigación de audiencia y encontrar mujeres en el tercer trimestre del embarazo; la clienta sugirió que era a partir del tercer trimestre cuando el producto tenía que publicitarse para que la mayoría de la audiencia lo comprara.
Al comienzo del análisis, la descripción de las circunstancias de la vida de la mujer embarazada se asemejaba a una imagen idílica: una familia joven con mascotas, en vísperas del nacimiento de un hijo, equipa la vivienda.

Las mujeres de diferentes grupos poseen dispositivos de diferentes marcas, prefieren diferentes marcas de productos de higiene y, en general, todo está bien. Ver por ti mismo.
El 25,5% de las identificaciones
Los compradores de Huggies Elite Soft tienen tres veces menos probabilidades de comprar Pampers y siete veces menos probabilidades de comprar productos Lovular. Utilizan productos Peligrin. Con una alta probabilidad (0,6) son los padres de las niñas. Suelen pagar los servicios públicos a través de Internet.
El 25,5% de los identificadores están
dispuestos a pagar por servicios de comunicación y seguros a través de Internet. Con una alta probabilidad (0,6) son dueños de perros. Compra productos Helen Harper. Entre la electrónica de consumo, se expresa la marca Xiaomi.
17,5% de identificadores
Usuarios de Ozon Premium. Compran equipos para el cuidado del bebé de Philips Avent y están interesados en equipos e instalaciones de planchado.
Atención, consejos para el futuro: cuidado con las promociones / marcas que generan ruido en la cantidad total de datos.
El estatus Ozon Premium en muchos de nuestros clústeres resultó ser uno de los atributos definitorios. Pero dirigirse a la audiencia de posibles compradores de pañales solo para Ozon Premium está más allá del sentido común. Entonces tuve que quitar el estado de todos los datos. Sí, así bajé las métricas, pero al mismo tiempo aumenté la adecuación del modelo. El primer lugar lo ocuparon los productos para recién nacidos, y no el estatus popular promovido. Fue una experiencia que me enseñó a cortar bienes que eran demasiado importantes para el modelo.
Para el modelado similar, la idea de construir varios clasificadores simples de la audiencia objetivo (clase 1) y generalizados (clase 0) se encuentra en la superficie para resaltar la audiencia objetivo.
Por ejemplo, tomemos las compras del público objetivo y diez veces el volumen de perfiles aleatorios. Traemos esta información en secuencia, compras. Luego trabajamos con los textos resultantes (preprocesamiento): eliminamos todas las palabras no informativas de alta frecuencia y traemos el resto a la forma inicial. A continuación, construimos clasificadores simples de varias familias diferentes - lineales (SVC lineal, regresión logística), "de madera" (RandomForest), etc. - y medimos la importancia de las características, es decir, la importancia de cualquier palabra según los modelos. Encontré valores umbral, por encima de los cuales la importancia de estas señales es inadecuada, es decir, la señal es demasiado ruidosa. Antes de construir algo automático, debe aplicar el sentido común y el método de la mirada cuidadosa muchas veces para recopilar estadísticas internas y comprender qué métodos funcionan y cuáles no.
Examinamos grupos con una imagen idílica en vísperas del nacimiento de un niño, pero también se rastrearon otras historias de vida. Por ejemplo, en uno de los grupos, es muy probable que los compradores potenciales de pañales para recién nacidos (0,65) tengan una cuenta en un sitio de citas. Esta no es una declaración infundada, pagan por los servicios en dichos sitios.
Para que las percepciones "funcionen", siempre hay que interpretar nuevos conocimientos, pero esta vez no quiero buscar la historia interna en absoluto: todos conocen el malestar social y el desorden cotidiano en nuestro país.

Permítanme recordarles que, como parte de este caso, investigamos a toda la audiencia que estaba interesada en comprar pañales para recién nacidos. Y resultó que no solo las mujeres en el tercer trimestre del embarazo.
Llamé a un grupo separado “Sunday Dads”: sus representantes son fanáticos del fútbol, ávidos entusiastas de los autos, compran componentes para autos Sparco y de vez en cuando compran productos Chupa Chups.
Y ahora atención, la pregunta: ¿vale la pena eliminar los "papás del domingo" si no se relacionan con el público objetivo originalmente designado? A menudo hago esta pregunta a mis jefes de proyecto y la tarea se replantea. Quizás no necesitemos realmente un público objetivo específico, sino todos los que puedan convertirse en compradores del producto. En nuestro caso, se trata de papás, abuelos, hermanos y novias de una mujer en trabajo de parto, dispuestos a cuidar al bebé. La respuesta a qué público debe considerarse el objetivo es para los representantes comerciales.
Caso "Emprendedores individuales"

El siguiente caso, del que les hablaré, es la Investigación de Audiencias para el público objetivo “Emprendedores individuales” que han abierto una cuenta corriente en un banco conocido.
Las principales diferencias entre estas personas y la audiencia del intercambio se pueden ver claramente en sus compras. El más evidente es el pago de regalías (10-15% de los perfiles), servicios de seguridad y facturas de servicios públicos para locales no residenciales. Entre las señales indirectas que apuntan a los emprendedores está la compra de una pieza de equipaje adicional durante los vuelos (en un 15-20% de los casos). En todo el volumen de cheques, una parte significativa está compuesta por libros de psicología, autoconocimiento y autodesarrollo, talleres de comunicación con subordinados y literatura de coaching.
Con la ayuda de la importancia de las características de LaL, obtuvimos señales indirectas del público objetivo: transporte aéreo, compra de un robot aspirador, máquina de café, teléfono inteligente Honor, entrega de flores, pago de primas de seguro. Este caso es uno de esos maravillosos casos en los que las máquinas nos dan un resultado fácilmente interpretable.
La gente ocupada compra robots domésticos. Ninguna oficina puede prescindir de las máquinas de café. La entrega de flores y los vuelos frecuentes también se pueden vincular =).
Caso "Propietarios de automóviles"
Una marca de automóviles conocida en el segmento de precios “por encima del promedio” estaba absolutamente convencida de que sus clientes eran personas completamente excepcionales y querían conocer sus hábitos y preferencias.
Este público objetivo se superpone significativamente con el caso anterior ("Emprendedores individuales"). Pero no todos los empresarios individuales compran esta marca de automóvil.

Resultó que la idea del cliente de la singularidad de los clientes es muy exagerada. Sí, la audiencia no coincide con el promedio, pero solo en algunos detalles, por ejemplo, los automovilistas prefieren comprar té de élite (300 rublos más caro) y generalmente gastan más en belleza y estética que en funcional y práctica.
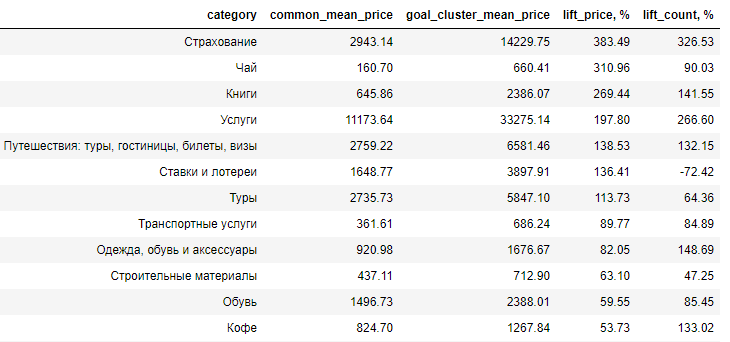
Aquí se presenta la diferencia entre la audiencia objetivo y la audiencia media de compradores en términos de lift, es decir, en qué porcentaje el precio medio de un producto en la audiencia estudiada supera el mismo valor en la audiencia media (lift_price). Como puede ver, el gasto principal es el placer.
Siempre probamos hipótesis de manera justa e imparcial. Es de esperar que en ocasiones la hipótesis del cliente sobre la exclusividad de su audiencia no esté respaldada por los datos obtenidos. No hay nada de qué preocuparse, solo necesita una nueva hipótesis y una nueva investigación.

En conclusión, diré que en mi trabajo me guío por el principio "La rutina calma". Y te aconsejo.
Con tanta variedad de datos, es imperativo tener mucho cuidado y estar atento a las pequeñas cosas, ya que cualquier excepción a primera vista puede convertirse después en la regla y podemos obtener muchos resultados erróneos.
Por lo tanto, si no hubiera visto lo que mi modelo "sin hornear" se refiere a "hornear", el sistema "con fugas" habría entrado en producción. Así que no descuides la rutina: si pasas media hora revisando con los ojos, puedes dormir bien, el modelo no cometerá errores.
