
La computación en la nube está penetrando cada vez más en nuestras vidas y probablemente no haya una sola persona que no haya utilizado ningún servicio en la nube al menos una vez. Sin embargo, qué es una nube y cómo funciona en su mayor parte, pocas personas lo saben incluso al nivel de una idea. 5G ya se está convirtiendo en una realidad y la infraestructura de telecomunicaciones está comenzando a pasar de soluciones pilares a soluciones en la nube, como cuando pasaba de soluciones totalmente férreas a “pilares” virtualizados.
Hoy hablaremos sobre el mundo interior de la infraestructura en la nube, en particular, analizaremos los conceptos básicos de la parte de red.
¿Qué es una nube? La misma virtualización: ¿vista de perfil?
Más que una pregunta lógica. No, esto no es virtualización, aunque no fue sin ella. Considere dos definiciones:
La computación en la nube (en lo sucesivo, la nube) es un modelo para proporcionar acceso fácil de usar a los recursos informáticos distribuidos que deben implementarse y lanzarse bajo demanda con la latencia más baja posible y el costo mínimo del proveedor de servicios (traducción de la definición del NIST).
Virtualización- esta es la capacidad de dividir una entidad física (por ejemplo, un servidor) en varias virtuales, aumentando así la utilización de recursos (por ejemplo, tenía 3 servidores cargados en un 25-30 por ciento, después de la virtualización obtiene 1 servidor cargado en un 80-90 por ciento). Naturalmente, la virtualización consume algunos de los recursos; necesita alimentar el hipervisor, sin embargo, como ha demostrado la práctica, el juego vale la pena. Un ejemplo ideal de virtualización es VMWare, que prepara perfectamente las máquinas virtuales, o por ejemplo KVM, que prefiero, pero esto ya es cuestión de gustos.
Nosotros mismos usamos la virtualización sin darnos cuenta de esto, e incluso los enrutadores de hierro ya usan la virtualización; por ejemplo, en las últimas versiones de JunOS, el sistema operativo se instala como una máquina virtual sobre el kit de distribución de Linux en tiempo real (Wind River 9). Pero la virtualización no es la nube, pero la nube no puede existir sin virtualización.
La virtualización es uno de los pilares sobre los que se construye la nube.
No funcionará hacer una nube simplemente recopilando varios hipervisores en un dominio L2, agregando un par de libros de jugadas yaml para registrar automáticamente vlans a través de algún ansible y llenándolo con algo así como un sistema de orquestación para crear automáticamente máquinas virtuales. Más precisamente, resultará, pero el Frankenstein resultante no es la nube que necesitamos, aunque como otra persona, tal vez para alguien este sea el sueño definitivo. Además, si toma el mismo Openstack, de hecho, sigue siendo Frankenstein, pero bueno, no hablemos de eso todavía.
Pero entiendo que de la definición anterior no está del todo claro qué se puede llamar realmente una nube.
Por ello, el documento del NIST (Instituto Nacional de Estándares y Tecnología) enumera 5 características principales que debe tener una infraestructura en la nube:
Prestación de servicios bajo demanda. El usuario debe tener acceso gratuito a los recursos informáticos que se le asignan (como redes, discos virtuales, memoria, núcleos de procesador, etc.) y estos recursos deben proporcionarse automáticamente, es decir, sin la intervención del proveedor de servicios.
Amplia disponibilidad de servicios. El acceso a los recursos debe proporcionarse mediante mecanismos estándar para poder utilizar tanto PC estándar como clientes ligeros y dispositivos móviles.
Mancomunidad de recursos.Los grupos de recursos deben poder proporcionar recursos a varios clientes al mismo tiempo, asegurando el aislamiento del cliente y la ausencia de influencia mutua y contención por los recursos. Las redes también se incluyen en los grupos, lo que indica la posibilidad de utilizar direccionamiento superpuesto. Las piscinas deben escalar a pedido. El uso de grupos permite proporcionar el nivel necesario de resiliencia de recursos y abstracción de recursos físicos y virtuales: el destinatario del servicio simplemente recibe el conjunto de recursos solicitado (dónde se encuentran estos recursos físicamente, en cuántos servidores y conmutadores, al cliente no le importa). Sin embargo, hay que tener en cuenta el hecho de que el proveedor debe garantizar la reserva transparente de estos recursos.
Rápida adaptación a diversas condiciones.Los servicios deben ser flexibles: provisión rápida de recursos, su reasignación, adición o reducción de recursos a solicitud del cliente, y el cliente debe sentir que los recursos de la nube son infinitos. Para facilitar la comprensión, por ejemplo, no ve una advertencia de que ha perdido una parte del espacio en disco en Apple iCloud debido al hecho de que el disco duro del servidor está roto y los discos se están rompiendo. Además, por tu parte, las posibilidades de este servicio son casi infinitas - necesitas 2 TB - no hay problema, pagaste y recibiste. Del mismo modo, puede dar un ejemplo con Google.Drive o Yandex.Disk.
La capacidad de medir el servicio prestado.Los sistemas en la nube deben controlar y optimizar automáticamente los recursos consumidos, mientras que estos mecanismos deben ser transparentes tanto para el usuario como para el proveedor de servicios. Es decir, siempre puede verificar cuántos recursos están consumiendo usted y sus clientes.
Vale la pena considerar el hecho de que estos requisitos son en su mayoría requisitos para una nube pública, por lo tanto, para una nube privada (es decir, una nube lanzada para las necesidades internas de una empresa), estos requisitos pueden ajustarse ligeramente. Sin embargo, aún deben ejecutarse, de lo contrario no obtendremos todas las ventajas de la computación en la nube.
¿Por qué necesitamos una nube?
Sin embargo, cualquier tecnología nueva o existente, cualquier protocolo nuevo se crea para algo (bueno, excepto para RIP-ng, por supuesto). Protocolo por el protocolo: nadie lo necesita (bueno, excepto RIP-ng, por supuesto). Es lógico que la Nube se cree para brindar algún tipo de servicio al usuario / cliente. Todos estamos familiarizados con al menos un par de servicios en la nube, como Dropbox o Google.Docs, y creo que la mayoría de ellos los utilizan con éxito; por ejemplo, este artículo se escribió utilizando el servicio en la nube Google.Docs. Pero los servicios en la nube que conocemos son solo una parte de las capacidades de la nube; más precisamente, es solo un servicio de tipo SaaS. Podemos proporcionar un servicio en la nube de tres formas: en forma de SaaS, PaaS o IaaS. El servicio que necesita depende de sus deseos y capacidades.
Consideremos cada uno en orden:
El software como servicio (SaaS) es un modelo para brindar un servicio completo a un cliente, por ejemplo, un servicio de correo como Yandex.Mail o Gmail. En tal modelo de prestación de servicios, usted, como cliente, de hecho no hace nada más que utilizar los servicios, es decir, no necesita pensar en configurar un servicio, su tolerancia a fallas o reserva. Lo principal es no comprometer su contraseña, el proveedor de este servicio hará el resto por usted. Desde el punto de vista del proveedor de servicios, es totalmente responsable de todo el servicio, desde el hardware del servidor y los sistemas operativos host hasta la configuración de la base de datos y el software.
Plataforma como servicio (PaaS)- cuando se utiliza este modelo, el proveedor de servicios proporciona al cliente una plantilla para el servicio, por ejemplo, tomemos un servidor web. El proveedor de servicios proporcionó al cliente un servidor virtual (de hecho, un conjunto de recursos, como RAM / CPU / Storage / Nets, etc.), e incluso instaló el sistema operativo y el software necesario en este servidor, pero el cliente mismo configura todo esto, y para el desempeño del servicio ya responde el cliente. El prestador del servicio, como en el caso anterior, es responsable de la operatividad de los equipos físicos, hipervisores, la propia máquina virtual, su disponibilidad de red, etc., pero el servicio en sí ya está fuera de su área de responsabilidad.
Infraestructura como servicio (IaaS)- este enfoque ya es más interesante, de hecho, el proveedor de servicios proporciona al cliente una infraestructura virtualizada completa, es decir, algún tipo de conjunto (grupo) de recursos, como núcleos de CPU, RAM, redes, etc. recursos dentro del grupo asignado (cuota): el proveedor no es particularmente importante. El cliente quiere crear su propio vEPC o incluso hacer un mini operador y proporcionar servicios de comunicación, sin duda, hágalo. En tal escenario, el proveedor de servicios es responsable de la provisión de recursos, su tolerancia a fallas y disponibilidad, así como del sistema operativo que le permite combinar estos recursos en grupos y brindarles al cliente la capacidad de aumentar o disminuir los recursos en cualquier momento a solicitud del cliente. El cliente configura todas las máquinas virtuales y otros tinsel él mismo a través del portal de autoservicio y las consolas,incluido el registro de redes (excepto para redes externas).
¿Qué es OpenStack?
En las tres opciones, el proveedor de servicios necesita un sistema operativo que habilite la infraestructura en la nube. De hecho, en SaaS, ningún departamento es responsable de toda la pila de esta pila de tecnología, hay un departamento que es responsable de la infraestructura, es decir, proporciona IaaS a otro departamento, este departamento proporciona el cliente SaaS. OpenStack es uno de los sistemas operativos en la nube que le permite recopilar un grupo de conmutadores, servidores y sistemas de almacenamiento en un solo grupo de recursos, dividir este grupo común en subpools (inquilinos) y proporcionar estos recursos a los clientes a través de la red.
OpenstackEs un sistema operativo en la nube que le permite controlar grandes grupos de recursos informáticos, almacenamiento de datos y recursos de red, cuyo aprovisionamiento y administración se realiza a través de una API utilizando mecanismos de autenticación estándar.
En otras palabras, este es un conjunto de proyectos de software libre que están diseñados para crear servicios en la nube (tanto públicos como privados), es decir, un conjunto de herramientas que le permiten combinar servidores y equipos de conmutación en un solo grupo de recursos, administrar estos recursos y brindar el nivel necesario de tolerancia a fallas. ...
En el momento de escribir este artículo, la estructura de OpenStack se ve así:

Imagen tomada de openstack.org
Cada uno de los componentes que componen OpenStack realiza una función específica. Esta arquitectura distribuida te permite incluir en la solución el conjunto de componentes funcionales que necesitas. Sin embargo, algunos de los componentes son componentes raíz y su eliminación conducirá a la inoperancia total o parcial de la solución en su conjunto. Es habitual referirse a dichos componentes:
- Panel de control: GUI basada en web para administrar los servicios OpenStack
- Keystone es un servicio de identidad centralizado que proporciona funciones de autenticación y autorización para otros servicios, además de administrar las credenciales y roles de los usuarios.
- Neutron — , OpenStack ( VM )
- Cinder —
- Nova —
- Glance —
- Swift —
- Ceilometer — ,
- Heat —
Puede encontrar una lista completa de todos los proyectos y su propósito aquí .
Cada uno de los componentes de OpenStack es un servicio que es responsable de una función específica y proporciona una API para administrar esa función y para comunicar ese servicio con otros servicios del sistema operativo en la nube para crear una infraestructura unificada. Por ejemplo, Nova proporciona administración de recursos informáticos y API para acceder a la configuración de estos recursos, Glance proporciona administración de imágenes y API para administrarlos, Cinder proporciona almacenamiento en bloque y API para administrarlos, y así sucesivamente. Todas las funciones están interconectadas de forma muy estrecha.
Sin embargo, si lo juzga, entonces todos los servicios que se ejecutan en OpenStack son, en última instancia, algún tipo de máquina virtual (o contenedor) conectada a la red. Surge la pregunta: ¿por qué necesitamos tantos elementos?
Repasemos el algoritmo para crear una máquina virtual y conectarla a la red y al almacenamiento persistente en Openstack.
- Cuando crea una solicitud para crear una máquina, ya sea una solicitud a través de Horizon (Tablero) o una solicitud a través de la CLI, lo primero que sucede es su solicitud de autorización para Keystone: ¿puede crear una máquina, tiene o tiene el derecho de usar esta red, tiene suficiente proyecto de cuotas, etc.
- Keystone autentica su solicitud y genera un token de autenticación en el mensaje de respuesta, que se utilizará más adelante. Después de recibir una respuesta de Keystone, la solicitud se envía a Nova (nova api).
- Nova-api , Keystone, auth-
- Keystone auth- .
- Nova-api nova-database VM nova-scheduler.
- Nova-scheduler ( ), VM , . VM nova-database.
- nova-scheduler nova-compute . Nova-compute nova-conductor (nova-conductor nova, nova-database nova-compute, nova-database ).
- Nova-conductor nova-database nova-compute.
- nova-compute glance ID . Glace Keystone .
- Nova-compute neutron . glance, neutron Keystone, database ( ), nova-compute.
- Nova-compute cinder volume. glance, cider Keystone, volume .
- Nova-compute libvirt .
De hecho, una operación aparentemente simple para crear una máquina virtual simple se convierte en un torbellino de llamadas de API entre elementos de la plataforma en la nube. Además, como puede ver, incluso los servicios previamente designados también constan de componentes más pequeños, entre los cuales tiene lugar la interacción. Crear una máquina es solo una pequeña parte de lo que puede hacer una plataforma en la nube: existe un servicio responsable de equilibrar el tráfico, un servicio responsable del almacenamiento en bloque, un servicio responsable del DNS, un servicio responsable del aprovisionamiento de servidores bare metal, etc. La nube permite trata a sus máquinas virtuales como un rebaño de ovejas (a diferencia de la virtualización). Si algo le sucedió a su máquina en un entorno virtual, lo restaura desde copias de seguridad, etc., las aplicaciones en la nube se crean de esta manera,para que la máquina virtual no juegue un papel tan importante - la máquina virtual "murió" - no importa - simplemente se crea una nueva máquina basada en la plantilla y, como dicen, el escuadrón no notó la pérdida de un soldado. Naturalmente, esto proporciona la presencia de mecanismos de orquestación: con las plantillas de Heat, puede implementar fácilmente una función compleja que consta de docenas de redes y máquinas virtuales sin ningún problema.
Siempre vale la pena tener en cuenta que no existe una infraestructura en la nube sin una red: cada elemento de una forma u otra interactúa con otros elementos a través de la red. Además, la nube tiene una red completamente no estática. Naturalmente, la red subyacente es incluso más o menos estática: no se agregan nuevos nodos y conmutadores todos los días, sin embargo, el componente de superposición puede cambiar e inevitablemente cambiará constantemente: se agregarán o eliminarán nuevas redes, aparecerán nuevas máquinas virtuales y las antiguas mueren. Y como recordará de la definición de nube, que se da al principio del artículo, los recursos deben asignarse al usuario automáticamente y con la menor (o mejor sin) intervención del proveedor de servicios. Es decir, el tipo de provisión de recursos de red,que ahora tiene la forma de una interfaz en forma de su cuenta personal accesible a través de http / https y el ingeniero de red de servicio Vasily como backend; esto no es una nube, incluso si Vasily tiene ocho manos.
Neutron, al ser un servicio de red, proporciona una API para administrar la parte de red de la infraestructura de la nube. El servicio proporciona el estado y la gestión de la parte de la red Openstack al proporcionar una capa de abstracción llamada Red como servicio (NaaS). Es decir, la red es la misma unidad virtual medible que, por ejemplo, los núcleos virtuales de CPU o RAM.
Pero antes de pasar a la arquitectura de red OpenStack, veamos cómo funciona la red OpenStack y por qué la red es una parte importante e integral de la nube.
Entonces, tenemos dos máquinas virtuales de cliente RED y dos máquinas virtuales de cliente VERDE. Supongamos que estas máquinas están ubicadas en dos hipervisores como este:
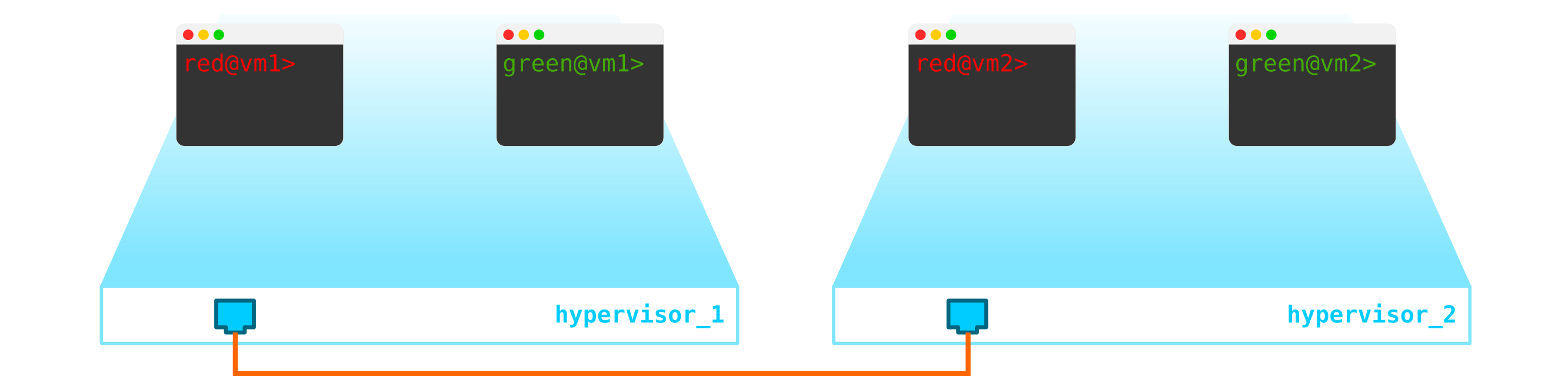
Por el momento, esto es solo virtualización de 4 servidores y nada más, ya que hasta ahora todo lo que hemos hecho es virtualizar 4 servidores, colocándolos en dos servidores físicos. Y hasta ahora ni siquiera están conectados a la red.
Para obtener una nube, necesitamos agregar varios componentes. Primero, virtualizamos la parte de la red; necesitamos conectar estas 4 máquinas en pares y los clientes quieren exactamente la conexión L2. Puede usar el conmutador y configurar un tronco en su dirección y administrar todo usando el puente de Linux, o para usuarios de openvswitch más avanzados (volveremos a él). Pero puede haber muchas redes, y presionar constantemente L2 a través de un conmutador no es la mejor idea, por lo que diferentes divisiones, mesa de servicio, meses de espera para la ejecución de una aplicación, semanas de resolución de problemas, este enfoque no funciona en el mundo moderno. Y cuanto antes la empresa se dé cuenta de esto, más fácil será avanzar. Por tanto, entre los hipervisores, seleccionaremos una red L3 a través de la cual se comunicarán nuestras máquinas virtuales, y ya encima de esta red L3 construiremos redes L2 virtuales superpuestas (overlay),donde se ejecutará el tráfico de nuestras máquinas virtuales. GRE, Geneve o VxLAN se pueden utilizar como encapsulación. Detengámonos en esto último por ahora, aunque esto no es particularmente importante.
Necesitamos ubicar VTEP en algún lugar (espero que todos estén familiarizados con la terminología VxLAN). Dado que la red L3 sale de los servidores a la vez, nada nos impide colocar VTEP en los propios servidores, y OVS (OpenvSwitch) puede hacerlo perfectamente. Como resultado, obtuvimos la siguiente construcción:
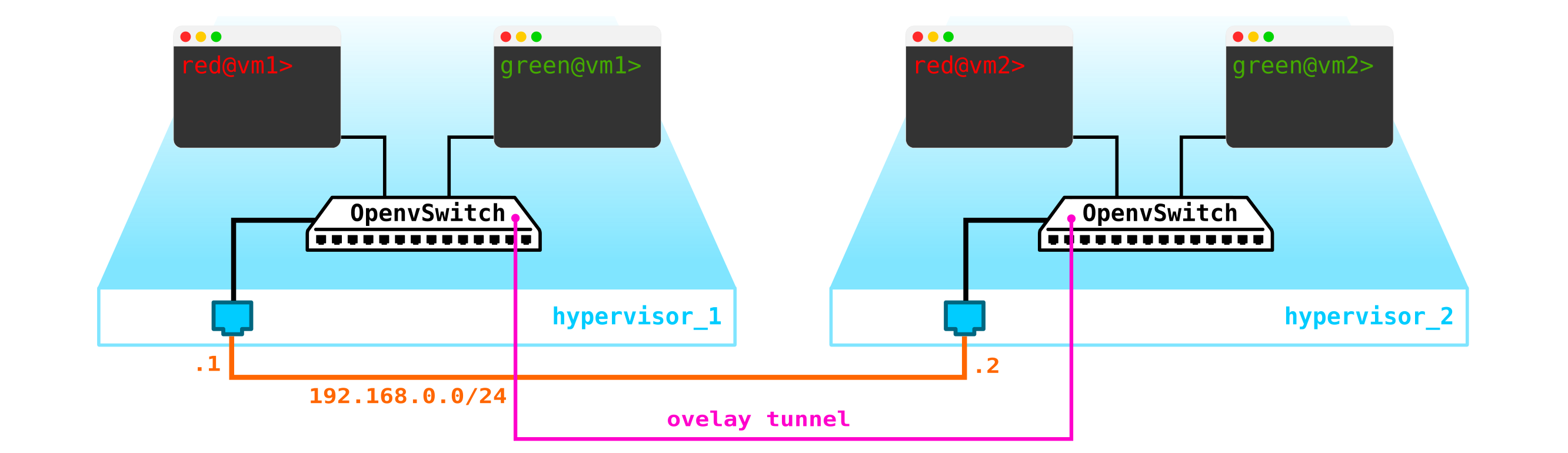
dado que el tráfico entre máquinas virtuales debe dividirse, los puertos hacia las máquinas virtuales tendrán diferentes números de vlan. El número de etiqueta juega un papel solo dentro de un conmutador virtual, ya que al encapsular en VxLAN podemos eliminarlo sin ningún problema, ya que tendremos un VNI.

Ahora podemos procrear nuestras máquinas y redes virtuales para ellos sin ningún problema.
Sin embargo, ¿qué pasa si el cliente tiene otra máquina, pero está en una red diferente? Necesitamos enraizamiento entre redes. Analizaremos una opción simple cuando se usa enraizamiento centralizado, es decir, el tráfico se enruta a través de nodos de red dedicados especiales (bueno, como regla general, se combinan con nodos de control, por lo que tendremos lo mismo).
No parece ser nada complicado: creamos una interfaz de puente en el nodo de control, dirigimos el tráfico hacia él y desde allí lo dirigimos a donde lo necesitamos. Pero el problema es que el cliente RED quiere usar la red 10.0.0.0/24 y el cliente GREEN quiere usar la red 10.0.0.0/24. Es decir, comienza la intersección de espacios de direcciones. Además, los clientes no quieren que otros clientes sean enrutados a sus redes internas, lo cual es lógico. Para separar las redes y el tráfico de datos del cliente, asignaremos un espacio de nombres separado para cada uno de ellos. El espacio de nombres es, de hecho, una copia de la pila de red de Linux, es decir, los clientes en el espacio de nombres ROJO están completamente aislados de los clientes del espacio de nombres VERDE (bueno, el enrutamiento entre estas redes de clientes está permitido a través del espacio de nombres predeterminado o ya en el equipo de transporte ascendente).
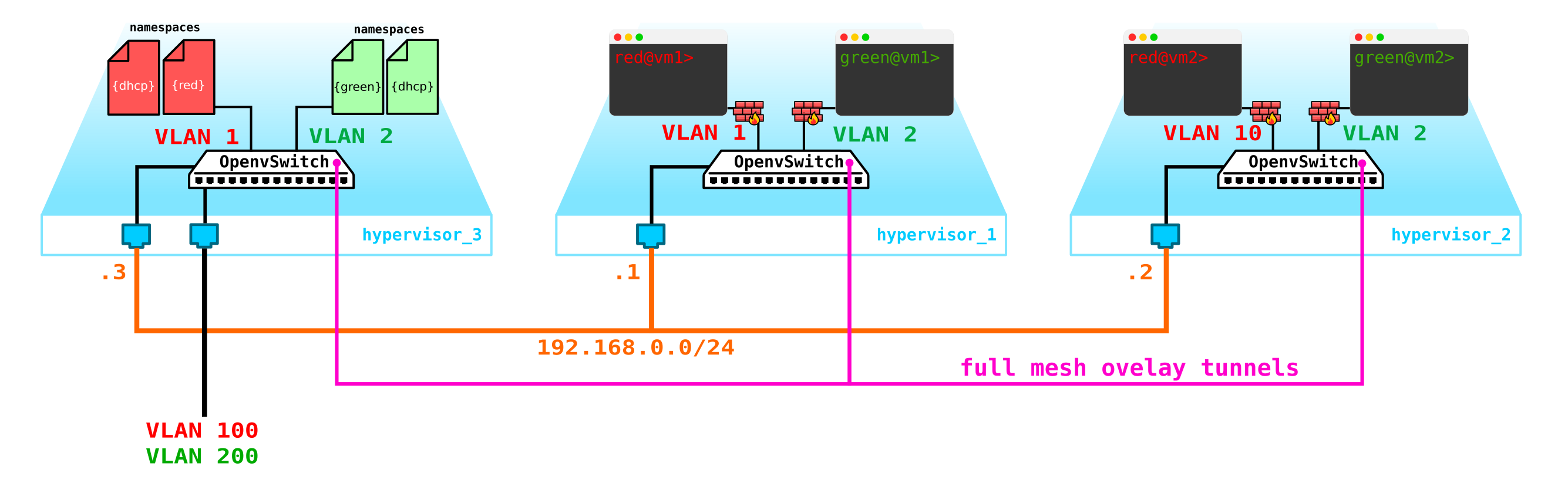
Es decir, obtenemos el siguiente esquema:
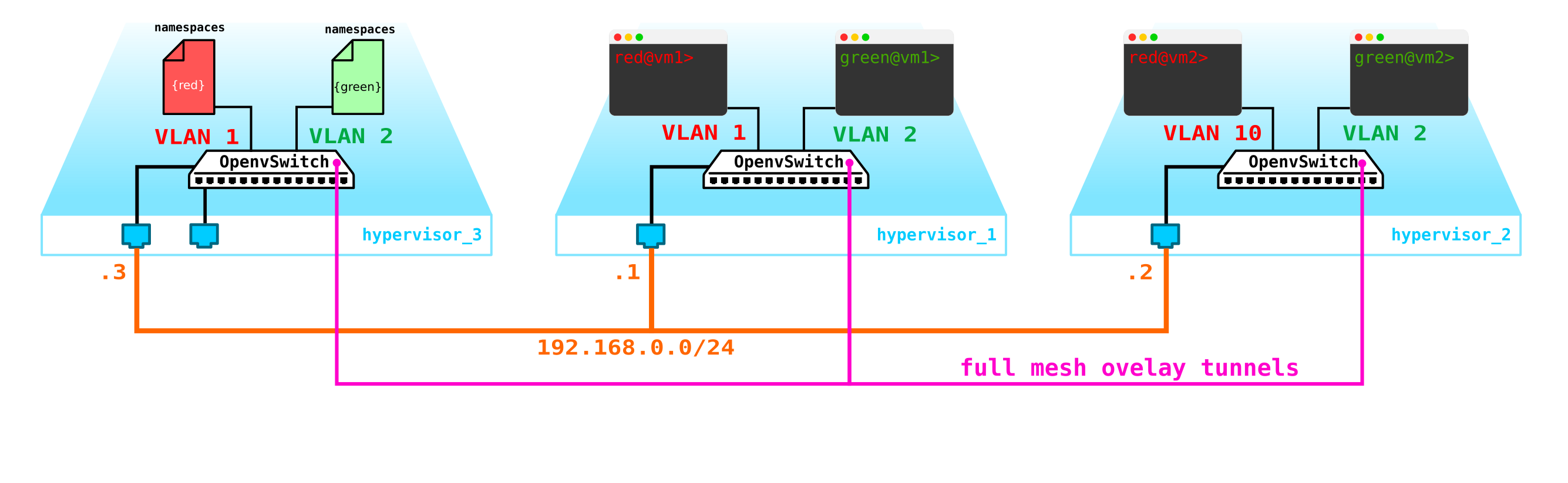
Los túneles L2 convergen desde todos los nodos de cálculo al de control. el nodo donde se encuentra la interfaz L3 para estas redes, cada una en un espacio de nombres dedicado para el aislamiento.
Sin embargo, nos hemos olvidado de lo más importante. La máquina virtual debe brindar un servicio al cliente, es decir, debe tener al menos una interfaz externa a través de la cual se pueda acceder. Es decir, tenemos que salir al mundo exterior. Aquí hay diferentes opciones. Hagamos la opción más simple. Agreguemos clientes en una red, que será válida en la red del proveedor y no se cruzará con otras redes. Las redes también pueden superponerse y buscar diferentes VRF en el lado de la red del proveedor. Estas redes también vivirán en el espacio de nombres de cada cliente. Sin embargo, aún ingresarán al mundo exterior a través de una interfaz física (o enlace, que es más lógico). Para separar el tráfico del cliente, el tráfico que sale al exterior se etiquetará con una etiqueta VLAN asignada al cliente.
Como resultado, obtuvimos el siguiente esquema:

Una pregunta razonable: ¿por qué no crear puertas de enlace en los nodos informáticos? Esto no es un gran problema, además, cuando enciende el enrutador distribuido (DVR), funcionará así. En este escenario, consideramos la opción más simple con una puerta de enlace centralizada, que es la predeterminada en Openstack. Para las funciones de alta carga, utilizarán un enrutador distribuido y tecnologías de aceleración como SR-IOV y Passthrough, pero como dicen, esta es una historia completamente diferente. Primero, tratemos la parte básica y luego entremos en detalles.
En realidad, nuestro esquema ya está operativo, pero hay un par de matices:
- Necesitamos proteger de alguna manera nuestras máquinas, es decir, colgar un filtro en la interfaz del conmutador hacia el cliente.
- Haga posible que una máquina virtual obtenga automáticamente una dirección IP para que usted no tenga que ingresarla a través de la consola cada vez y registrar la dirección.
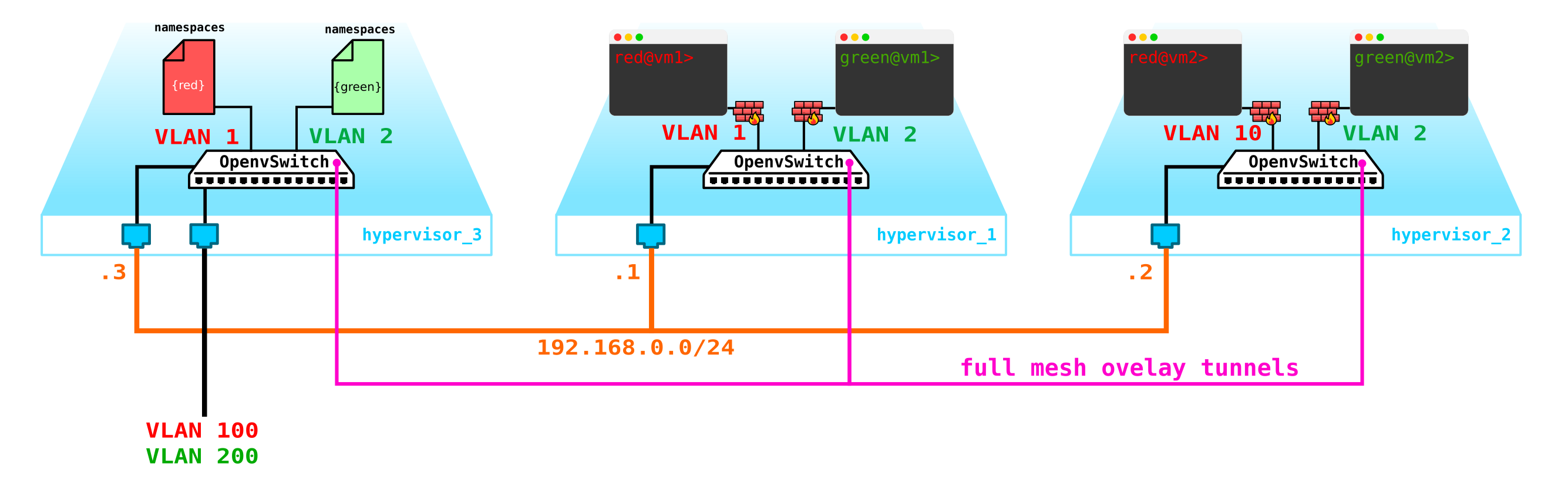
Comencemos por proteger las máquinas. Para ello, puede utilizar iptables banales, ¿por qué no?
Es decir, ahora nuestra topología se ha vuelto un poco más complicada:
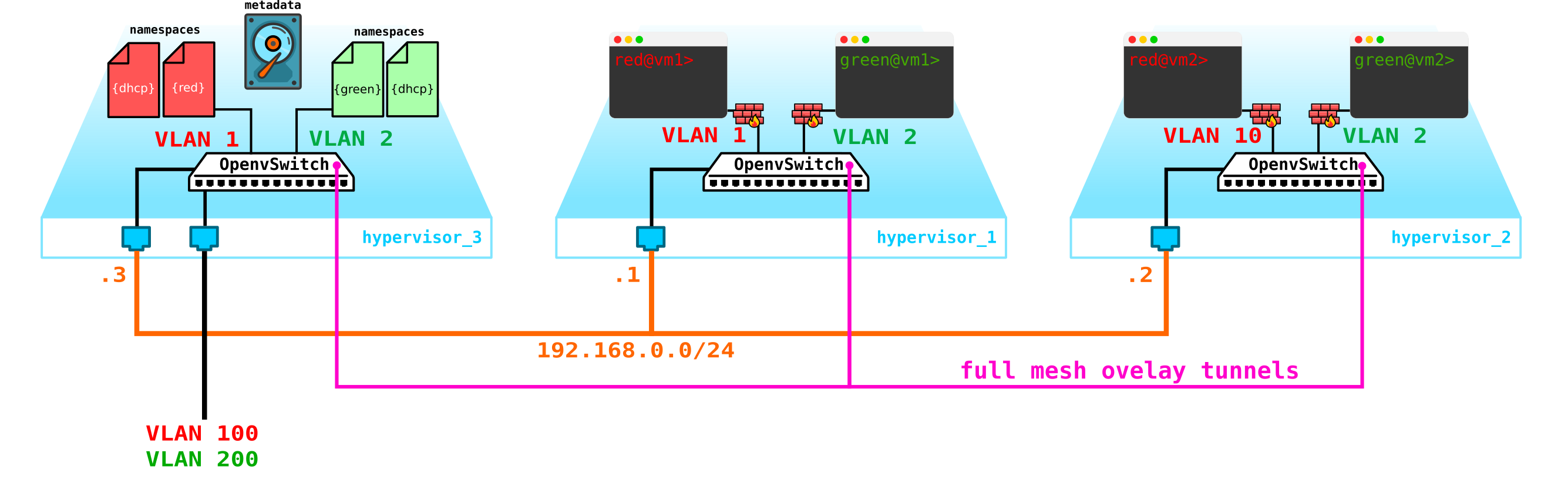
vayamos más allá. Necesitamos agregar un servidor DHCP. El lugar más ideal para la ubicación de los servidores DHCP para cada uno de los clientes será el nodo de control ya mencionado anteriormente, donde se ubican los espacios de nombres:
Sin embargo, existe un pequeño problema. ¿Qué pasa si todo se reinicia y toda la información de concesión de direcciones DHCP desaparece? Es lógico que se envíen nuevas direcciones a las máquinas, lo que no es muy conveniente. Hay dos formas de salir aquí: usar nombres de dominio y agregar un servidor DNS para cada cliente, entonces la dirección no será muy importante para nosotros (por analogía con la parte de red en k8s), pero hay un problema con las redes externas, ya que las direcciones también se pueden emitir en ellas. a través de DHCP: necesita sincronización con servidores DNS en la plataforma en la nube y un servidor DNS externo, que en mi opinión no es muy flexible, pero sí posible. O la segunda opción es usar metadatos, es decir, guardar información sobre la dirección emitida a la máquina para que el servidor DHCP sepa qué dirección enviar a la máquina si la máquina ya ha recibido una dirección. La segunda opción es más simple y flexible, ya que le permite guardar información adicional sobre el automóvil.Ahora agregue los metadatos del agente al esquema:
Otro tema que también debe santificarse es la capacidad de usar una red externa para todos los clientes, ya que las redes externas, si van a ser válidas en toda la red, habrá complejidad: debe asignar y controlar constantemente la asignación de estas redes. La capacidad de utilizar una única red externa preconfigurada para todos los clientes será muy útil al crear una nube pública. Esto facilitará la implementación de máquinas, ya que no tenemos que verificar la base de datos de direcciones y elegir un espacio de direcciones único para la red externa de cada cliente. Además, podemos registrar una red externa con anticipación y en el momento de la implementación solo necesitaremos asociar direcciones externas con las máquinas cliente.
Y aquí NAT viene al rescate: simplemente hacemos posible que los clientes salgan al mundo exterior a través del espacio de nombres predeterminado utilizando la traducción NAT. Bueno, aquí hay un pequeño problema. Es bueno si el servidor cliente actúa como cliente y no como servidor, es decir, inicia en lugar de aceptar conexiones. Pero con nosotros será al revés. En este caso, necesitamos hacer NAT de destino para que al recibir tráfico, el nodo de control entienda que este tráfico está destinado a la máquina virtual A del cliente A, lo que significa que necesitamos hacer la traducción NAT desde una dirección externa, por ejemplo 100.1.1.1 a una dirección interna 10.0.0.1. En este caso, aunque todos los clientes utilizarán la misma red, el aislamiento interno se conserva por completo. Es decir, necesitamos hacer dNAT y sNAT en el nodo de control.Utilice una sola red con la asignación de direcciones flotantes o redes externas, o ambas a la vez, debido al hecho de que desea arrastrar a la nube. No agregaremos direcciones flotantes al diagrama, pero dejaremos las redes externas ya agregadas anteriormente: cada cliente tiene su propia red externa (en el diagrama, están designadas como vlan 100 y 200 en la interfaz externa).
Como resultado, obtuvimos una solución interesante y al mismo tiempo bien pensada, que tiene cierta flexibilidad, pero hasta ahora no cuenta con mecanismos de tolerancia a fallas.
En primer lugar, solo tenemos un nodo de control: su falla conducirá al colapso de todos los sistemas. Para solucionar este problema, debe crear al menos un quórum de 3 nodos. Agreguemos esto al diagrama:
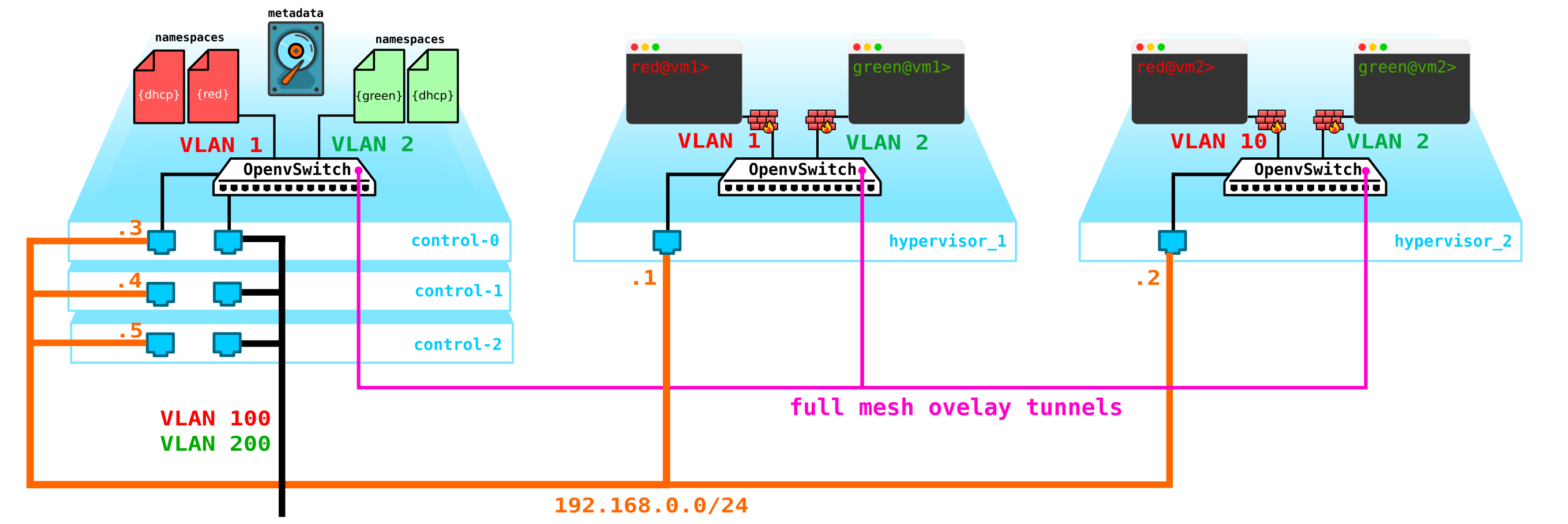
naturalmente, todos los nodos están sincronizados y cuando el nodo activo sale, otro nodo asumirá sus responsabilidades.
El siguiente problema son los discos de la máquina virtual. Por el momento, están almacenados en los propios hipervisores y, en caso de problemas con el hipervisor, perdemos todos los datos, y la presencia de una incursión no ayudará aquí de ninguna manera si perdemos no el disco, sino todo el servidor. Para hacer esto, necesitamos crear un servicio que actúe como una interfaz para algo de almacenamiento. El tipo de almacenamiento que será no es particularmente importante para nosotros, pero debería proteger nuestros datos de fallas tanto del disco como del nodo, y posiblemente de todo el gabinete. Hay varias opciones aquí, por supuesto, hay redes SAN con Fibre Channel, pero seamos honestos, FC ya es una reliquia del pasado, un análogo de E1 en el transporte, sí, estoy de acuerdo, todavía se usa, pero solo donde es absolutamente imposible sin él. Por tanto, no desplegaría voluntariamente la red FC en 2020, sabiendo que hay otras alternativas más interesantes.Aunque a cada uno lo suyo y tal vez haya quien crea que el FC con todas sus limitaciones es todo lo que necesitamos, no voy a discutir, cada uno tiene su propia opinión. Sin embargo, la solución más interesante en mi opinión es usar SDS, por ejemplo Ceph.
Ceph que permite a la solución de almacenamiento de construcción vyskodostupnoe con un montón de opciones para la redundancia, ya que el código de paridad (RAID analógico 5 o 6) que termina con una replicación completa de datos a través de múltiples discos de servidores de localización de disco y servidores en los gabinetes y así sucesivamente base.
Para El ensamblaje de Ceph necesita 3 nodos más. La interacción con el almacenamiento también se llevará a cabo a través de la red utilizando servicios de almacenamiento de bloques, objetos y archivos. Agregue almacenamiento al esquema:
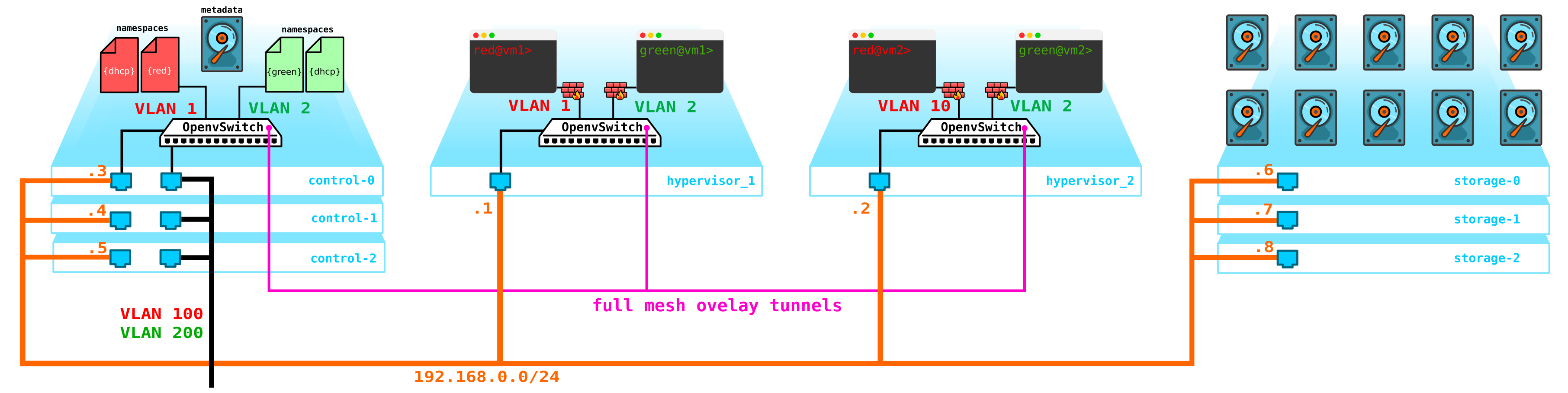
: compute — — storage+compute — ceph storage. — SDS . — — storage ( ) — CPU SDS ( , , ). compute storage.Todo esto bueno debe ser administrado de alguna manera - necesitamos algo a través del cual podamos crear una máquina, red, enrutador virtual, etc. Para hacer esto, agregue un servicio al nodo de control que actuará como un tablero - el cliente podrá conectarse a este portal a través de http / https y hacer lo que sea necesario (bueno, casi).
Como resultado, ahora tenemos un sistema tolerante a fallas. Todos los elementos de esta infraestructura deben gestionarse de alguna manera. Se describió anteriormente que Openstack es un conjunto de proyectos, cada uno de los cuales proporciona una función específica. Como vemos, hay elementos más que suficientes que hay que configurar y controlar. Hoy hablaremos de la parte del networking.
Arquitectura de neutrones
En OpenStack, es Neutron quien se encarga de conectar los puertos de las máquinas virtuales a una red L2 común, asegurando el enrutamiento del tráfico entre VMs ubicadas en diferentes redes L2, así como el enrutamiento hacia afuera, brindando servicios como NAT, IP flotante, DHCP, etc. El funcionamiento de
alto nivel del servicio de red ( parte básica) se puede describir como sigue.
Al iniciar la VM, el servicio de red:
- Crea un puerto para esta VM (o puertos) y notifica al servicio DHCP al respecto;
- Se crea un nuevo dispositivo de red virtual (a través de libvirt);
- VM se conecta al puerto (puertos) creado en el paso 1;
Por extraño que parezca, pero en el corazón del trabajo de Neutron hay mecanismos estándar familiares para todos los que alguna vez se han sumergido en Linux: estos son espacios de nombres, iptables, puentes de Linux, openvswitch, conntrack, etc.
Debe aclararse de inmediato que Neutron no es un controlador SDN.
Neutron consta de varios componentes interconectados:
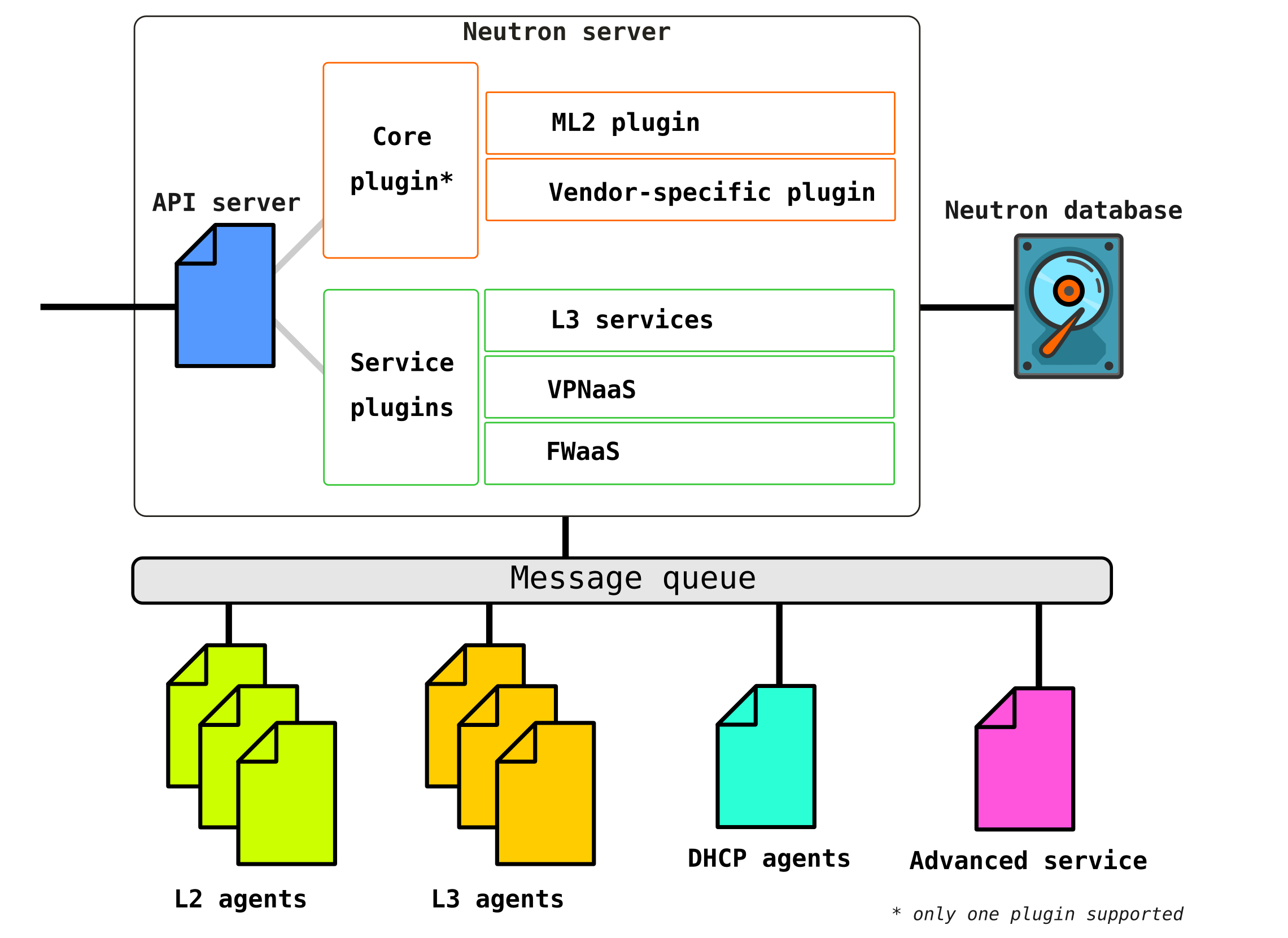
Openstack-neutron-server es un demonio que trabaja con las solicitudes de los usuarios a través de una API. Este demonio no prescribe ninguna conectividad de red, pero proporciona la información necesaria para ello a sus complementos, que luego configuran el elemento de red requerido. Los agentes de Neutron en los nodos de OpenStack se registran en el servidor de Neutron.
Neutron-server es en realidad una aplicación escrita en Python, que consta de dos partes:
- Servicio REST
- Complemento de neutrones (núcleo / servicio)
Un servicio REST está diseñado para recibir llamadas a la API de otros componentes (por ejemplo, una solicitud para proporcionar información, etc.) Los
complementos son componentes / módulos de software complementarios a los que se solicita la API, es decir, la asignación de algún servicio se realiza a través de ellos. Los complementos se dividen en dos tipos: servicio y raíz. Como regla general, el complemento de caballo es el principal responsable de administrar el espacio de direcciones y las conexiones L2 entre las VM, y los complementos de servicio ya brindan funcionalidad adicional, como VPN o FW.
La lista de complementos disponibles para hoy se puede ver, por ejemplo, aquí.
Puede haber varios complementos de servicio, pero solo puede haber un complemento de caballo.
Openstack-neutron-ml2Es el complemento raíz estándar de Openstack. Este complemento tiene una arquitectura modular (a diferencia de su predecesor) y configura el servicio de red a través de los controladores conectados a él. Consideraremos el plugin en sí un poco más adelante, ya que de hecho da la flexibilidad que tiene OpenStack en la parte de red. El complemento raíz se puede reemplazar (por ejemplo, Contrail Networking lo reemplaza).
Servicio RPC (rabbitmq-server) : un servicio que proporciona gestión de colas y comunicación con otros servicios OpenStack, así como comunicación entre agentes de servicios de red.
Los agentes de red son agentes ubicados en cada nodo a través de los cuales se configuran los servicios de red.
Los agentes son de varios tipos.
El agente principal esAgente L2 . Estos agentes se ejecutan en cada uno de los hipervisores, incluidos los nodos de control (más precisamente, en todos los nodos que brindan algún servicio a los inquilinos) y su función principal es conectar máquinas virtuales a una red L2 común, así como generar alertas cuando ocurre algún evento (por ejemplo deshabilitar / habilitar puerto).
El siguiente agente no menos importante es el agente L3... De forma predeterminada, este agente se ejecuta exclusivamente en el nodo de red (a menudo, un nodo de red se combina con un nodo de control) y proporciona enrutamiento entre redes de inquilinos (tanto entre sus redes como entre las redes de otros inquilinos, y está disponible para el mundo exterior, proporcionando servicios NAT y DHCP). Sin embargo, cuando se usa un DVR (enrutador distribuido), la necesidad de un complemento L3 también aparece en los nodos de cómputo.
El agente L3 utiliza espacios de nombres de Linux para proporcionar a cada inquilino un conjunto de sus propias redes aisladas y la funcionalidad de enrutadores virtuales que enrutan el tráfico y brindan servicios de puerta de enlace para las redes de Capa 2.
Base de datos : una base de datos de identificadores de redes, subredes, puertos, grupos, etc.
De hecho, Neutron acepta solicitudes de API desde la creación de cualquier entidad de red, autentica la solicitud, y a través de RPC (si se dirige a algún complemento o agente) o API REST (si se comunica en SDN) envía a los agentes (a través de complementos) las instrucciones necesarias para organizar el servicio solicitado. ...
Ahora pasemos a la instalación de prueba (cómo se implementa y qué contiene más adelante en la parte práctica) y veamos dónde se encuentra qué componente:
(overcloud) [stack@undercloud ~]$ openstack network agent list
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| ID | Agent Type | Host | Availability Zone | Alive | State | Binary |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| 10495de9-ba4b-41fe-b30a-b90ec3f8728b | Open vSwitch agent | overcloud-novacompute-1.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| 1515ad4a-5972-46c3-af5f-e5446dff7ac7 | L3 agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-l3-agent |
| 322e62ca-1e5a-479e-9a96-4f26d09abdd7 | DHCP agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-dhcp-agent |
| 9c1de2f9-bac5-400e-998d-4360f04fc533 | Open vSwitch agent | overcloud-novacompute-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| d99c5657-851e-4d3c-bef6-f1e3bb1acfb0 | Open vSwitch agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| ff85fae6-5543-45fb-a301-19c57b62d836 | Metadata agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-metadata-agent |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
(overcloud) [stack@undercloud ~]$ 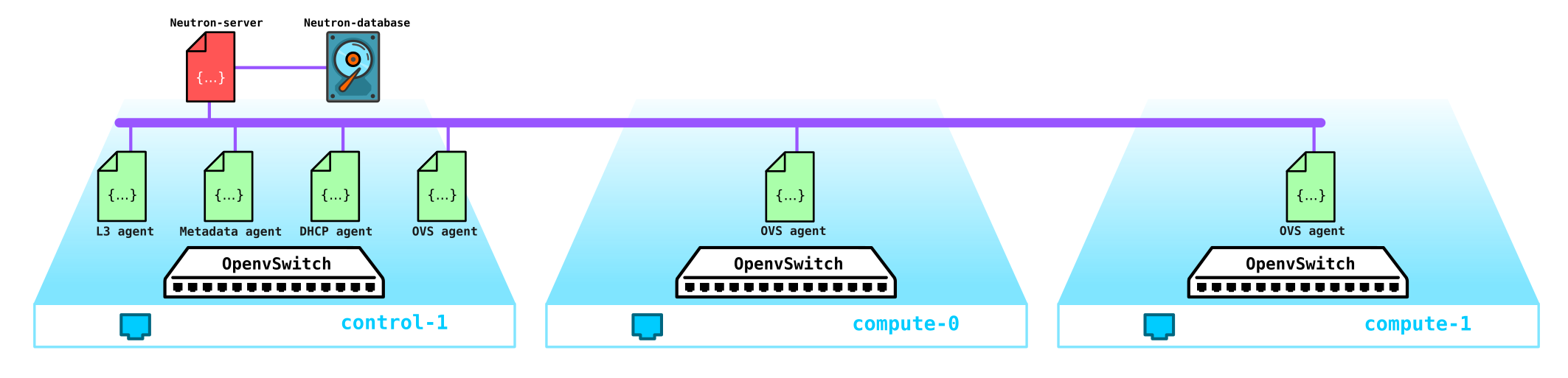
En realidad, esa es toda la estructura de Neutron. Ahora vale la pena tomarse un tiempo para el complemento ML2.
Capa modular 2
Como se indicó anteriormente, el complemento es un complemento raíz estándar de OpenStack y tiene una arquitectura modular.
El predecesor del complemento ML2 tenía una estructura monolítica que no permitía, por ejemplo, utilizar una combinación de varias tecnologías en una instalación. Por ejemplo, no puede usar openvswitch y linuxbridge al mismo tiempo, ni el primero ni el segundo. Por esta razón, se creó el complemento ML2 con su arquitectura.
ML2 tiene dos componentes: dos tipos de controladores: controladores de tipo y controladores de mecanismo.
Los controladores de tipo definen las tecnologías que se utilizarán para organizar la conectividad de la red, por ejemplo, VxLAN, VLAN, GRE. En este caso, el controlador le permite utilizar diferentes tecnologías. La tecnología estándar es la encapsulación VxLAN para redes superpuestas y redes externas vlan.
Los controladores de tipo incluyen los siguientes tipos de redes:
Plano : una red sin
VLAN etiquetada : una red etiquetada
Local : un tipo especial de red para instalaciones todo en uno (tales instalaciones son necesarias para desarrolladores o para capacitación)
GRE : red superpuesta usando túneles GRE
VxLAN - superposición de red utilizando túneles VxLAN
Los controladores de mecanismo definen los medios que proporcionan la organización de las tecnologías especificadas en el controlador de tipo, por ejemplo, openvswitch, sr-iov, opendaylight, OVN, etc.
Dependiendo de la implementación de este controlador, se usarán agentes controlados por Neutron, o se usarán conexiones con un controlador SDN externo, que se ocupa de todos los problemas de organización de redes L2, enrutamiento, etc.
Ejemplo Si usamos ML2 junto con OVS, entonces en cada nodo computacional se configura con un agente L2 que administra el OVS. Sin embargo, si usamos, por ejemplo, OVN u OpenDayLight, entonces el control de OVS queda bajo su jurisdicción: Neutron le da comandos al controlador a través del complemento raíz, y ya hace lo que le dijeron.
Refresquemos nuestra memoria Open vSwitch
Por el momento, uno de los componentes clave de OpenStack es Open vSwitch.
Al instalar OpenStack sin ningún SDN de proveedor adicional como Juniper Contrail o Nokia Nuage, OVS es el componente de red principal de la red en la nube y, junto con iptables, conntrack, espacios de nombres, le permite organizar una red de superposición completa con tenencia múltiple. Naturalmente, este componente se puede reemplazar, por ejemplo, cuando se utilizan soluciones SDN propietarias de terceros (proveedores).
OVS es un conmutador de software de código abierto diseñado para su uso en entornos virtualizados como reenviador de tráfico virtual.
Por el momento, OVS tiene una funcionalidad muy decente, que incluye tecnologías como QoS, LACP, VLAN, VxLAN, GENEVE, OpenFlow, DPDK, etc.
Nota: inicialmente, OVS no se concibió como un interruptor suave para funciones de telecomunicaciones de alta carga y se diseñó más para funciones de TI que requieren menos ancho de banda, como un servidor WEB o un servidor de correo. Sin embargo, se está finalizando OVS y las implementaciones actuales de OVS han mejorado enormemente su desempeño y capacidades, lo que permite que sea utilizado por operadores de telecomunicaciones con funciones de alta carga, por ejemplo, existe una implementación de OVS con soporte de aceleración DPDK.
Hay tres componentes importantes de OVS a tener en cuenta:
- Módulo del kernel : un componente ubicado en el espacio del kernel que procesa el tráfico según las reglas recibidas del control;
- vSwitch daemon (ovs-vswitchd) — , user space, kernel —
- Database server — , , OVS, . OVSDB SDN .
Todo esto también va acompañado de un conjunto de utilidades de diagnóstico y gestión, como ovs-vsctl, ovs-appctl, ovs-ofctl, etc.
Actualmente, Openstack es muy utilizado por los operadores de telecomunicaciones para migrar funciones de red a él, como EPC, SBC, HLR. etc. Algunas funciones pueden vivir sin problemas con OVS en la forma en que está, pero por ejemplo, EPC procesa el tráfico de suscriptores, es decir, pasa una gran cantidad de tráfico a través de sí mismo (ahora los volúmenes de tráfico alcanzan varios cientos de gigabits por segundo). Naturalmente, conducir dicho tráfico a través del espacio del kernel (ya que el reenviador se encuentra allí de forma predeterminada) no es una buena idea. Por lo tanto, OVS a menudo se implementa completamente en el espacio del usuario utilizando la tecnología de aceleración DPDK para reenviar el tráfico desde la NIC al espacio del usuario sin pasar por el kernel.
Nota: para una nube implementada para funciones de telecomunicaciones, es posible generar tráfico desde el nodo de cálculo sin pasar por OVS directamente al equipo de conmutación. Los mecanismos SR-IOV y Passthrough se utilizan para este propósito.
¿Cómo funciona en un diseño real?
Bueno, ahora pasemos a la parte práctica y veamos cómo funciona todo en la práctica.
Comencemos por implementar una instalación simple de Openstack. Como no tengo un conjunto de servidores a mano para experimentos, ensamblaremos el diseño en un servidor físico a partir de máquinas virtuales. Sí, por supuesto, tal solución no es adecuada para fines comerciales, pero para ver un ejemplo de cómo funciona la red en Openstack, tal instalación es suficiente para los ojos. Además, una instalación de este tipo con fines de capacitación es aún más interesante, ya que puede captar tráfico, etc.
Como necesitamos ver solo la parte básica, no podemos usar varias redes, sino subir todo usando solo dos redes, y la segunda red en este diseño se usará exclusivamente para acceder al servidor undercloud y dns. No tocaremos las redes externas por ahora; este es un tema para un artículo grande separado.
Así que comencemos en orden. Primero, un poco de teoría. Instalaremos Openstack usando TripleO (Openstack en Openstack). La esencia de TripleO es que instalamos un Openstack todo en uno (es decir, en un nodo), llamado undercloud, y luego usamos las capacidades del Openstack implementado para instalar un Openstack destinado a la explotación, llamado overcloud. Undercloud utilizará la capacidad inherente de administrar servidores físicos (bare metal), el proyecto Ironic, para aprovisionar hipervisores que actuarán como nodos de almacenamiento, control y computación. Es decir, no utilizamos herramientas de terceros para implementar Openstack, implementamos Openstack con Openstack. Más adelante en el proceso de instalación, se volverá mucho más claro, así que no nos detengamos ahí y sigamos adelante.
: Openstack, . — , , . . ceph ( ) (Storage management Storage) , , QoS , . .
Nota: Dado que vamos a ejecutar máquinas virtuales en un entorno virtual basado en máquinas virtuales, primero debemos habilitar la virtualización anidada.
Puede verificar si la virtualización anidada está habilitada o no así:
[root@hp-gen9 bormoglotx]# cat /sys/module/kvm_intel/parameters/nested N [root@hp-gen9 bormoglotx]#
Si ve la letra N, habilitamos el soporte para la virtualización anidada de acuerdo con cualquier guía que encuentre en la red, por ejemplo, esta .
Necesitamos ensamblar el siguiente esquema desde máquinas virtuales:

En mi caso, para la conectividad de las máquinas virtuales que son parte de la instalación futura (y tengo 7 de ellas, pero puedes arreglártelas con 4 si no tienes muchos recursos), usé OpenvSwitch. Creé un puente ovs y le conecté máquinas virtuales a través de grupos de puertos. Para hacer esto, creé un archivo xml de la siguiente forma:
[root@hp-gen9 ~]# virsh net-dumpxml ovs-network-1
<network>
<name>ovs-network-1</name>
<uuid>7a2e7de7-fc16-4e00-b1ed-4d190133af67</uuid>
<forward mode='bridge'/>
<bridge name='ovs-br1'/>
<virtualport type='openvswitch'/>
<portgroup name='trunk-1'>
<vlan trunk='yes'>
<tag id='100'/>
<tag id='101'/>
<tag id='102'/>
</vlan>
</portgroup>
<portgroup name='access-100'>
<vlan>
<tag id='100'/>
</vlan>
</portgroup>
<portgroup name='access-101'>
<vlan>
<tag id='101'/>
</vlan>
</portgroup>
</network>Aquí se declaran tres puertos del grupo: dos accesos y un enlace troncal (este último era necesario para un servidor DNS, pero puede prescindir de él o activarlo en la máquina host, eso es lo que sea más conveniente para usted). A continuación, utilizando esta plantilla, declaramos que nuestro es a través de virsh net-define:
virsh net-define ovs-network-1.xml
virsh net-start ovs-network-1
virsh net-autostart ovs-network-1 Ahora editemos la configuración de los puertos del hipervisor:
[root@hp-gen9 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens1f0
TYPE=Ethernet
NAME=ens1f0
DEVICE=ens1f0
TYPE=OVSPort
DEVICETYPE=ovs
OVS_BRIDGE=ovs-br1
ONBOOT=yes
OVS_OPTIONS="trunk=100,101,102"
[root@hp-gen9 ~]
[root@hp-gen9 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ovs-br1
DEVICE=ovs-br1
DEVICETYPE=ovs
TYPE=OVSBridge
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.255.200
PREFIX=24
[root@hp-gen9 ~]# Nota: en este escenario, la dirección en el puerto ovs-br1 no estará disponible, ya que no tiene una etiqueta vlan. Para solucionar este problema, ejecute el comando sudo ovs-vsctl set port ovs-br1 tag = 100. Sin embargo, después de reiniciar, esta etiqueta desaparecerá (si alguien sabe cómo hacer que permanezca en su lugar, estaré muy agradecido). Pero esto no es tan importante, porque necesitaremos esta dirección solo para el momento de la instalación y no será necesaria cuando Openstack esté completamente implementado.A continuación, creamos un coche bajo la nube:
virt-install -n undercloud --description "undercloud" --os-type=Linux --os-variant=centos7.0 --ram=8192 --vcpus=8 --disk path=/var/lib/libvirt/images/undercloud.qcow2,bus=virtio,size=40,format=qcow2 --network network:ovs-network-1,model=virtio,portgroup=access-100 --network network:ovs-network-1,model=virtio,portgroup=access-101 --graphics none --location /var/lib/libvirt/boot/CentOS-7-x86_64-Minimal-2003.iso --extra-args console=ttyS0Durante la instalación, estableces todos los parámetros necesarios, como el nombre de la máquina, contraseñas, usuarios, servidores ntp, etc., puedes configurar inmediatamente los puertos, pero después de la instalación es más fácil para mí entrar en la máquina a través de la consola y corregir los archivos necesarios. Si ya tiene una imagen lista para usar, puede usarla o hacer lo que yo hago: descargue la imagen mínima de Centos 7 y úsela para instalar la VM.
Después de una instalación exitosa, debe tener una máquina virtual en la que pueda poner undercloud
[root@hp-gen9 bormoglotx]# virsh list
Id Name State
----------------------------------------------------
6 dns-server running
62 undercloud runningPrimero, instalamos las herramientas necesarias durante el proceso de instalación:
sudo yum update -y
sudo yum install -y net-tools
sudo yum install -y wget
sudo yum install -y ipmitool
Instalación de Undercloud
Cree un usuario de pila, establezca una contraseña, agréguelo a sudoer y dele la capacidad de ejecutar comandos de root a través de sudo sin tener que ingresar una contraseña:
useradd stack
passwd stack
echo “stack ALL=(root) NOPASSWD:ALL” > /etc/sudoers.d/stack
chmod 0440 /etc/sudoers.d/stackAhora especificamos el nombre completo undercloud en el archivo hosts:
vi /etc/hosts
127.0.0.1 undercloud.openstack.rnd localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6A continuación, agregue los repositorios e instale el software que necesitamos:
sudo yum install -y https://trunk.rdoproject.org/centos7/current/python2-tripleo-repos-0.0.1-0.20200409224957.8bac392.el7.noarch.rpm
sudo -E tripleo-repos -b queens current
sudo -E tripleo-repos -b queens current ceph
sudo yum install -y python-tripleoclient
sudo yum install -y ceph-ansibleNota: si no planea instalar ceph, no es necesario que ingrese los comandos relacionados con ceph. Usé el lanzamiento de Queens, pero puedes usar lo que quieras.A continuación, copie el archivo de configuración de la nube al directorio de inicio de la pila del usuario:
cp /usr/share/instack-undercloud/undercloud.conf.sample ~/undercloud.confAhora necesitamos arreglar este archivo ajustándolo a nuestra instalación.
Al principio del archivo, agregue estas líneas:
vi undercloud.conf
[DEFAULT]
undercloud_hostname = undercloud.openstack.rnd
local_ip = 192.168.255.1/24
network_gateway = 192.168.255.1
undercloud_public_host = 192.168.255.2
undercloud_admin_host = 192.168.255.3
undercloud_nameservers = 192.168.255.253
generate_service_certificate = false
local_interface = eth0
local_mtu = 1450
network_cidr = 192.168.255.0/24
masquerade = true
masquerade_network = 192.168.255.0/24
dhcp_start = 192.168.255.11
dhcp_end = 192.168.255.50
inspection_iprange = 192.168.255.51,192.168.255.100
scheduler_max_attempts = 10Por lo tanto, revise la configuración:
undercloud_hostname - el nombre completo del servidor de undercloud debe coincidir con la entrada en el servidor DNS
local_ip - dirección local undercloud hacia la red de suministro
network_gateway - la misma dirección local, que servirá como puerta de enlace para acceder al mundo exterior durante la instalación nodo overcloud, también coincide con la ip local
undercloud_public_host - dirección API externa, se le asigna cualquier dirección libre de la red de aprovisionamiento
undercloud_admin_host dirección API interna, se asigna cualquier dirección libre de la red de aprovisionamiento
undercloud_nameservers - servidor DNS
generate_service_certificate- esta línea es muy importante en el ejemplo actual, porque si no se establece en falso, recibirá un error durante la instalación, el problema se describe en la interfaz
local_interface del rastreador de errores de Red Hat en la red de aprovisionamiento. Esta interfaz se reconfigurará durante la implementación de undercloud, por lo que debe tener dos interfaces en undercloud: una para acceder a ella y la otra para aprovisionar
local_mtu - MTU. Como tenemos un laboratorio de pruebas y MTU tengo 1.500 puertos OVS Svicha, es necesario poner en valor en 1450, que se habría encapsulado en paquetes VxLAN
network_cidr - red de aprovisionamiento
masquerade - el uso de NAT para acceder a la red externa
masquerade_network - una red que hará NAT -sya
dhcp_start : la dirección de inicio del grupo de direcciones desde el que se asignarán direcciones a los nodos durante la implementación en la nube
dhcp_end : la dirección final del grupo de direcciones desde el cual se asignarán direcciones a los nodos durante la implementación overcloud
inspeccion_iprange : el grupo de direcciones necesarias para la introspección (no debe cruzarse con el grupo mencionado anteriormente )
Scheduler_max_attempts : el número máximo de intentos de instalar overcloud (debe ser mayor o igual que el número de nodos)
Una vez que se describe el archivo, puede dar el comando para implementar undercloud:
openstack undercloud install
El procedimiento toma de 10 a 30 minutos, dependiendo de su plancha. En última instancia, debería ver un resultado como este:
vi undercloud.conf
2020-08-13 23:13:12,668 INFO:
#############################################################################
Undercloud install complete.
The file containing this installation's passwords is at
/home/stack/undercloud-passwords.conf.
There is also a stackrc file at /home/stack/stackrc.
These files are needed to interact with the OpenStack services, and should be
secured.
#############################################################################Esta salida dice que ha instalado con éxito undercloud y ahora puede verificar el estado de undercloud y proceder a instalar overcloud.
Si observa la salida de ifconfig, verá que hay una nueva interfaz de puente
[stack@undercloud ~]$ ifconfig
br-ctlplane: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.255.1 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe2c:89e prefixlen 64 scopeid 0x20<link>
ether 52:54:00:2c:08:9e txqueuelen 1000 (Ethernet)
RX packets 14 bytes 1095 (1.0 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 20 bytes 1292 (1.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0La implementación de overcloud ahora se realizará a través de esta interfaz.
En el resultado a continuación, se puede ver que tenemos todos los servicios en un nodo:
(undercloud) [stack@undercloud ~]$ openstack host list
+--------------------------+-----------+----------+
| Host Name | Service | Zone |
+--------------------------+-----------+----------+
| undercloud.openstack.rnd | conductor | internal |
| undercloud.openstack.rnd | scheduler | internal |
| undercloud.openstack.rnd | compute | nova |
+--------------------------+-----------+----------+A continuación se muestra la configuración de la parte de red de la nube:
(undercloud) [stack@undercloud ~]$ python -m json.tool /etc/os-net-config/config.json
{
"network_config": [
{
"addresses": [
{
"ip_netmask": "192.168.255.1/24"
}
],
"members": [
{
"dns_servers": [
"192.168.255.253"
],
"mtu": 1450,
"name": "eth0",
"primary": "true",
"type": "interface"
}
],
"mtu": 1450,
"name": "br-ctlplane",
"ovs_extra": [
"br-set-external-id br-ctlplane bridge-id br-ctlplane"
],
"routes": [],
"type": "ovs_bridge"
}
]
}
(undercloud) [stack@undercloud ~]$Instalación overcloud
Por el momento, solo tenemos undercloud y no tenemos suficientes nodos a partir de los cuales se construirá overcloud. Por tanto, en primer lugar, desplegaremos las máquinas virtuales que necesitemos. Durante la implementación, undercloud mismo instalará el sistema operativo y el software necesario en las máquinas overcloud; es decir, no necesitamos implementar completamente la máquina, sino solo crear un disco (o discos) para ella y determinar sus parámetros, es decir, de hecho, obtenemos un servidor desnudo sin un sistema operativo instalado en él. ...
Vaya a la carpeta con los discos de nuestras máquinas virtuales y cree discos del tamaño requerido:
cd /var/lib/libvirt/images/
qemu-img create -f qcow2 -o preallocation=metadata control-1.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata compute-1.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata compute-2.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata storage-1.qcow2 160G
qemu-img create -f qcow2 -o preallocation=metadata storage-2.qcow2 160GDado que estamos actuando desde la raíz, necesitamos cambiar el propietario de estos discos para no tener problemas con los derechos:
[root@hp-gen9 images]# ls -lh
total 5.8G
drwxr-xr-x. 2 qemu qemu 4.0K Aug 13 16:15 backups
-rw-r--r--. 1 root root 61G Aug 14 03:07 compute-1.qcow2
-rw-r--r--. 1 root root 61G Aug 14 03:07 compute-2.qcow2
-rw-r--r--. 1 root root 61G Aug 14 03:07 control-1.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:03 dns-server.qcow2
-rw-r--r--. 1 root root 161G Aug 14 03:07 storage-1.qcow2
-rw-r--r--. 1 root root 161G Aug 14 03:07 storage-2.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:07 undercloud.qcow2
[root@hp-gen9 images]#
[root@hp-gen9 images]#
[root@hp-gen9 images]# chown qemu:qemu /var/lib/libvirt/images/*qcow2
[root@hp-gen9 images]# ls -lh
total 5.8G
drwxr-xr-x. 2 qemu qemu 4.0K Aug 13 16:15 backups
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 compute-1.qcow2
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 compute-2.qcow2
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 control-1.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:03 dns-server.qcow2
-rw-r--r--. 1 qemu qemu 161G Aug 14 03:07 storage-1.qcow2
-rw-r--r--. 1 qemu qemu 161G Aug 14 03:07 storage-2.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:08 undercloud.qcow2
[root@hp-gen9 images]# Nota: si planeas instalar ceph para estudiarlo, crea al menos 3 nodos con al menos dos discos, y en la plantilla indica que se usarán los discos virtuales vda, vdb, etc.Genial, ahora necesitamos definir todas estas máquinas:
virt-install --name control-1 --ram 32768 --vcpus 8 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/control-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --network network:ovs-network-1,model=virtio,portgroup=trunk-1 --dry-run --print-xml > /tmp/control-1.xml
virt-install --name storage-1 --ram 16384 --vcpus 4 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/storage-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/storage-1.xml
virt-install --name storage-2 --ram 16384 --vcpus 4 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/storage-2.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/storage-2.xml
virt-install --name compute-1 --ram 32768 --vcpus 12 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/compute-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/compute-1.xml
virt-install --name compute-2 --ram 32768 --vcpus 12 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/compute-2.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/compute-2.xml Al final están los comandos --print-xml> /tmp/storage-1.xml, que crea un archivo xml con una descripción de cada máquina en la carpeta / tmp /, si no lo agrega, no podrá definir máquinas virtuales.
Ahora necesitamos definir todas estas máquinas en virsh:
virsh define --file /tmp/control-1.xml
virsh define --file /tmp/compute-1.xml
virsh define --file /tmp/compute-2.xml
virsh define --file /tmp/storage-1.xml
virsh define --file /tmp/storage-2.xml
[root@hp-gen9 ~]# virsh list --all
Id Name State
----------------------------------------------------
6 dns-server running
64 undercloud running
- compute-1 shut off
- compute-2 shut off
- control-1 shut off
- storage-1 shut off
- storage-2 shut off
[root@hp-gen9 ~]#Ahora un pequeño matiz: tripleO usa IPMI para administrar los servidores durante la instalación y la introspección.
La introspección es el proceso de inspeccionar el hardware con el fin de obtener los parámetros necesarios para el aprovisionamiento adicional de nodos. La introspección se realiza mediante ironic, un servicio diseñado para funcionar con servidores bare metal.
Pero aquí está el problema: si los servidores de hierro de IPMI tienen un puerto separado (o un puerto compartido, pero esto no es importante), entonces las máquinas virtuales no tienen tales puertos. Aquí viene a nuestro rescate una muleta llamada vbmc, una utilidad que le permite emular un puerto IPMI. Vale la pena prestar atención a este matiz, especialmente a aquellos que quieren crear un laboratorio de este tipo en un hipervisor ESXI; si, por supuesto, no sé si tiene un análogo de vbmc, esta pregunta debería desconcertarlos antes de implementar todo.
Instale vbmc:
yum install yum install python2-virtualbmcSi su sistema operativo no puede encontrar el paquete, agregue el repositorio:
yum install -y https://www.rdoproject.org/repos/rdo-release.rpmAhora configuramos la utilidad. Todo es trillado para deshonrar aquí. Ahora es lógico que no haya servidores en la lista vbmc
[root@hp-gen9 ~]# vbmc list
[root@hp-gen9 ~]# Para que aparezcan, deben declararse manualmente de esta forma:
[root@hp-gen9 ~]# vbmc add control-1 --port 7001 --username admin --password admin
[root@hp-gen9 ~]# vbmc add storage-1 --port 7002 --username admin --password admin
[root@hp-gen9 ~]# vbmc add storage-2 --port 7003 --username admin --password admin
[root@hp-gen9 ~]# vbmc add compute-1 --port 7004 --username admin --password admin
[root@hp-gen9 ~]# vbmc add compute-2 --port 7005 --username admin --password admin
[root@hp-gen9 ~]#
[root@hp-gen9 ~]# vbmc list
+-------------+--------+---------+------+
| Domain name | Status | Address | Port |
+-------------+--------+---------+------+
| compute-1 | down | :: | 7004 |
| compute-2 | down | :: | 7005 |
| control-1 | down | :: | 7001 |
| storage-1 | down | :: | 7002 |
| storage-2 | down | :: | 7003 |
+-------------+--------+---------+------+
[root@hp-gen9 ~]#Creo que la sintaxis del comando es clara y sin explicación. Sin embargo, por ahora, todas nuestras sesiones están en estado ABAJO. Para que pasen al estado UP, debe habilitarlos:
[root@hp-gen9 ~]# vbmc start control-1
2020-08-14 03:15:57,826.826 13149 INFO VirtualBMC [-] Started vBMC instance for domain control-1
[root@hp-gen9 ~]# vbmc start storage-1
2020-08-14 03:15:58,316.316 13149 INFO VirtualBMC [-] Started vBMC instance for domain storage-1
[root@hp-gen9 ~]# vbmc start storage-2
2020-08-14 03:15:58,851.851 13149 INFO VirtualBMC [-] Started vBMC instance for domain storage-2
[root@hp-gen9 ~]# vbmc start compute-1
2020-08-14 03:15:59,307.307 13149 INFO VirtualBMC [-] Started vBMC instance for domain compute-1
[root@hp-gen9 ~]# vbmc start compute-2
2020-08-14 03:15:59,712.712 13149 INFO VirtualBMC [-] Started vBMC instance for domain compute-2
[root@hp-gen9 ~]#
[root@hp-gen9 ~]#
[root@hp-gen9 ~]# vbmc list
+-------------+---------+---------+------+
| Domain name | Status | Address | Port |
+-------------+---------+---------+------+
| compute-1 | running | :: | 7004 |
| compute-2 | running | :: | 7005 |
| control-1 | running | :: | 7001 |
| storage-1 | running | :: | 7002 |
| storage-2 | running | :: | 7003 |
+-------------+---------+---------+------+
[root@hp-gen9 ~]#Y el toque final: debe corregir las reglas del firewall (bueno, o deshabilitarlo por completo):
firewall-cmd --zone=public --add-port=7001/udp --permanent
firewall-cmd --zone=public --add-port=7002/udp --permanent
firewall-cmd --zone=public --add-port=7003/udp --permanent
firewall-cmd --zone=public --add-port=7004/udp --permanent
firewall-cmd --zone=public --add-port=7005/udp --permanent
firewall-cmd --reload
Ahora vayamos a Undercloud y comprobemos que todo funciona. La dirección de la máquina host es 192.168.255.200, agregamos el paquete ipmitool necesario a undercloud durante la preparación para la implementación:
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power status
Chassis Power is off
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power on
Chassis Power Control: Up/On
[stack@undercloud ~]$
[root@hp-gen9 ~]# virsh list
Id Name State
----------------------------------------------------
6 dns-server running
64 undercloud running
65 control-1 runningComo puede ver, hemos lanzado con éxito el nodo de control a través de vbmc. Ahora apágalo y sigue adelante:
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power off
Chassis Power Control: Down/Off
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power status
Chassis Power is off
[stack@undercloud ~]$
[root@hp-gen9 ~]# virsh list --all
Id Name State
----------------------------------------------------
6 dns-server running
64 undercloud running
- compute-1 shut off
- compute-2 shut off
- control-1 shut off
- storage-1 shut off
- storage-2 shut off
[root@hp-gen9 ~]#El siguiente paso es la introspección de los nodos en los que se instalará el overcloud. Para hacer esto, necesitamos preparar un archivo json con una descripción de nuestros nodos. Tenga en cuenta que, a diferencia de la instalación en servidores simples, el archivo especifica el puerto en el que se ejecuta vbmc para cada una de las máquinas.
[root@hp-gen9 ~]# virsh domiflist --domain control-1
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:20:a2:2f
- network ovs-network-1 virtio 52:54:00:3f:87:9f
[root@hp-gen9 ~]# virsh domiflist --domain compute-1
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:98:e9:d6
[root@hp-gen9 ~]# virsh domiflist --domain compute-2
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:6a:ea:be
[root@hp-gen9 ~]# virsh domiflist --domain storage-1
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:79:0b:cb
[root@hp-gen9 ~]# virsh domiflist --domain storage-2
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:a7:fe:27Nota: hay dos interfaces en el nodo de control, pero en este caso no es importante, en esta instalación nos bastará una.Ahora estamos preparando un archivo json. Necesitamos especificar la dirección poppy del puerto a través del cual se realizará el aprovisionamiento, los parámetros del nodo, darles nombres e indicar cómo llegar a ipmi:
{
"nodes":[
{
"mac":[
"52:54:00:20:a2:2f"
],
"cpu":"8",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"control-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7001"
},
{
"mac":[
"52:54:00:79:0b:cb"
],
"cpu":"4",
"memory":"16384",
"disk":"160",
"arch":"x86_64",
"name":"storage-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7002"
},
{
"mac":[
"52:54:00:a7:fe:27"
],
"cpu":"4",
"memory":"16384",
"disk":"160",
"arch":"x86_64",
"name":"storage-2",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7003"
},
{
"mac":[
"52:54:00:98:e9:d6"
],
"cpu":"12",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"compute-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7004"
},
{
"mac":[
"52:54:00:6a:ea:be"
],
"cpu":"12",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"compute-2",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7005"
}
]
}Ahora tenemos que preparar imágenes para irónico. Para hacer esto, descárguelos a través de wget e instálelos:
(undercloud) [stack@undercloud ~]$ sudo wget https://images.rdoproject.org/queens/delorean/current-tripleo-rdo/overcloud-full.tar --no-check-certificate
(undercloud) [stack@undercloud ~]$ sudo wget https://images.rdoproject.org/queens/delorean/current-tripleo-rdo/ironic-python-agent.tar --no-check-certificate
(undercloud) [stack@undercloud ~]$ ls -lh
total 1.9G
-rw-r--r--. 1 stack stack 447M Aug 14 10:26 ironic-python-agent.tar
-rw-r--r--. 1 stack stack 1.5G Aug 14 10:26 overcloud-full.tar
-rw-------. 1 stack stack 916 Aug 13 23:10 stackrc
-rw-r--r--. 1 stack stack 15K Aug 13 22:50 undercloud.conf
-rw-------. 1 stack stack 2.0K Aug 13 22:50 undercloud-passwords.conf
(undercloud) [stack@undercloud ~]$ mkdir images/
(undercloud) [stack@undercloud ~]$ tar -xpvf ironic-python-agent.tar -C ~/images/
ironic-python-agent.initramfs
ironic-python-agent.kernel
(undercloud) [stack@undercloud ~]$ tar -xpvf overcloud-full.tar -C ~/images/
overcloud-full.qcow2
overcloud-full.initrd
overcloud-full.vmlinuz
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ ls -lh images/
total 1.9G
-rw-rw-r--. 1 stack stack 441M Aug 12 17:24 ironic-python-agent.initramfs
-rwxr-xr-x. 1 stack stack 6.5M Aug 12 17:24 ironic-python-agent.kernel
-rw-r--r--. 1 stack stack 53M Aug 12 17:14 overcloud-full.initrd
-rw-r--r--. 1 stack stack 1.4G Aug 12 17:18 overcloud-full.qcow2
-rwxr-xr-x. 1 stack stack 6.5M Aug 12 17:14 overcloud-full.vmlinuz
(undercloud) [stack@undercloud ~]$Subiendo imágenes a undercloud:
(undercloud) [stack@undercloud ~]$ openstack overcloud image upload --image-path ~/images/
Image "overcloud-full-vmlinuz" was uploaded.
+--------------------------------------+------------------------+-------------+---------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+------------------------+-------------+---------+--------+
| c2553770-3e0f-4750-b46b-138855b5c385 | overcloud-full-vmlinuz | aki | 6761064 | active |
+--------------------------------------+------------------------+-------------+---------+--------+
Image "overcloud-full-initrd" was uploaded.
+--------------------------------------+-----------------------+-------------+----------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+-----------------------+-------------+----------+--------+
| 949984e0-4932-4e71-af43-d67a38c3dc89 | overcloud-full-initrd | ari | 55183045 | active |
+--------------------------------------+-----------------------+-------------+----------+--------+
Image "overcloud-full" was uploaded.
+--------------------------------------+----------------+-------------+------------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+----------------+-------------+------------+--------+
| a2f2096d-c9d7-429a-b866-c7543c02a380 | overcloud-full | qcow2 | 1487475712 | active |
+--------------------------------------+----------------+-------------+------------+--------+
Image "bm-deploy-kernel" was uploaded.
+--------------------------------------+------------------+-------------+---------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+------------------+-------------+---------+--------+
| e413aa78-e38f-404c-bbaf-93e582a8e67f | bm-deploy-kernel | aki | 6761064 | active |
+--------------------------------------+------------------+-------------+---------+--------+
Image "bm-deploy-ramdisk" was uploaded.
+--------------------------------------+-------------------+-------------+-----------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+-------------------+-------------+-----------+--------+
| 5cf3aba4-0e50-45d3-929f-27f025dd6ce3 | bm-deploy-ramdisk | ari | 461759376 | active |
+--------------------------------------+-------------------+-------------+-----------+--------+
(undercloud) [stack@undercloud ~]$Compruebe que todas las imágenes estén cargadas
(undercloud) [stack@undercloud ~]$ openstack image list
+--------------------------------------+------------------------+--------+
| ID | Name | Status |
+--------------------------------------+------------------------+--------+
| e413aa78-e38f-404c-bbaf-93e582a8e67f | bm-deploy-kernel | active |
| 5cf3aba4-0e50-45d3-929f-27f025dd6ce3 | bm-deploy-ramdisk | active |
| a2f2096d-c9d7-429a-b866-c7543c02a380 | overcloud-full | active |
| 949984e0-4932-4e71-af43-d67a38c3dc89 | overcloud-full-initrd | active |
| c2553770-3e0f-4750-b46b-138855b5c385 | overcloud-full-vmlinuz | active |
+--------------------------------------+------------------------+--------+
(undercloud) [stack@undercloud ~]$Un toque más: debe agregar un servidor dns:
(undercloud) [stack@undercloud ~]$ openstack subnet list
+--------------------------------------+-----------------+--------------------------------------+------------------+
| ID | Name | Network | Subnet |
+--------------------------------------+-----------------+--------------------------------------+------------------+
| f45dea46-4066-42aa-a3c4-6f84b8120cab | ctlplane-subnet | 6ca013dc-41c2-42d8-9d69-542afad53392 | 192.168.255.0/24 |
+--------------------------------------+-----------------+--------------------------------------+------------------+
(undercloud) [stack@undercloud ~]$ openstack subnet show f45dea46-4066-42aa-a3c4-6f84b8120cab
+-------------------+-----------------------------------------------------------+
| Field | Value |
+-------------------+-----------------------------------------------------------+
| allocation_pools | 192.168.255.11-192.168.255.50 |
| cidr | 192.168.255.0/24 |
| created_at | 2020-08-13T20:10:37Z |
| description | |
| dns_nameservers | |
| enable_dhcp | True |
| gateway_ip | 192.168.255.1 |
| host_routes | destination='169.254.169.254/32', gateway='192.168.255.1' |
| id | f45dea46-4066-42aa-a3c4-6f84b8120cab |
| ip_version | 4 |
| ipv6_address_mode | None |
| ipv6_ra_mode | None |
| name | ctlplane-subnet |
| network_id | 6ca013dc-41c2-42d8-9d69-542afad53392 |
| prefix_length | None |
| project_id | a844ccfcdb2745b198dde3e1b28c40a3 |
| revision_number | 0 |
| segment_id | None |
| service_types | |
| subnetpool_id | None |
| tags | |
| updated_at | 2020-08-13T20:10:37Z |
+-------------------+-----------------------------------------------------------+
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ neutron subnet-update f45dea46-4066-42aa-a3c4-6f84b8120cab --dns-nameserver 192.168.255.253
neutron CLI is deprecated and will be removed in the future. Use openstack CLI instead.
Updated subnet: f45dea46-4066-42aa-a3c4-6f84b8120cab
(undercloud) [stack@undercloud ~]$Ahora podemos emitir el comando de introspección:
(undercloud) [stack@undercloud ~]$ openstack overcloud node import --introspect --provide inspection.json
Started Mistral Workflow tripleo.baremetal.v1.register_or_update. Execution ID: d57456a3-d8ed-479c-9a90-dff7c752d0ec
Waiting for messages on queue 'tripleo' with no timeout.
5 node(s) successfully moved to the "manageable" state.
Successfully registered node UUID b4b2cf4a-b7ca-4095-af13-cc83be21c4f5
Successfully registered node UUID b89a72a3-6bb7-429a-93bc-48393d225838
Successfully registered node UUID 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e
Successfully registered node UUID bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8
Successfully registered node UUID 766ab623-464c-423d-a529-d9afb69d1167
Waiting for introspection to finish...
Started Mistral Workflow tripleo.baremetal.v1.introspect. Execution ID: 6b4d08ae-94c3-4a10-ab63-7634ec198a79
Waiting for messages on queue 'tripleo' with no timeout.
Introspection of node b89a72a3-6bb7-429a-93bc-48393d225838 completed. Status:SUCCESS. Errors:None
Introspection of node 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e completed. Status:SUCCESS. Errors:None
Introspection of node bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 completed. Status:SUCCESS. Errors:None
Introspection of node 766ab623-464c-423d-a529-d9afb69d1167 completed. Status:SUCCESS. Errors:None
Introspection of node b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 completed. Status:SUCCESS. Errors:None
Successfully introspected 5 node(s).
Started Mistral Workflow tripleo.baremetal.v1.provide. Execution ID: f5594736-edcf-4927-a8a0-2a7bf806a59a
Waiting for messages on queue 'tripleo' with no timeout.
5 node(s) successfully moved to the "available" state.
(undercloud) [stack@undercloud ~]$Como puede ver en la salida, todo terminó sin errores. Comprobemos que todos los nodos estén disponibles:
(undercloud) [stack@undercloud ~]$ openstack baremetal node list
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
| UUID | Name | Instance UUID | Power State | Provisioning State | Maintenance |
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | None | power off | available | False |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | None | power off | available | False |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | None | power off | available | False |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | None | power off | available | False |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | None | power off | available | False |
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
(undercloud) [stack@undercloud ~]$ Si los nodos están en un estado diferente, como regla general, manejables, entonces algo salió mal y necesita mirar el registro para averiguar por qué sucedió. Tenga en cuenta que en este escenario estamos usando virtualización y puede haber errores asociados con el uso de máquinas virtuales o vbmc.
A continuación, debemos especificar qué nodo realizará qué función, es decir, indicar el perfil con el que se implementará el nodo:
(undercloud) [stack@undercloud ~]$ openstack overcloud profiles list
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| Node UUID | Node Name | Provision State | Current Profile | Possible Profiles |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | available | None | |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | available | None | |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | available | None | |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | available | None | |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | available | None | |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
(undercloud) [stack@undercloud ~]$ openstack flavor list
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
| ID | Name | RAM | Disk | Ephemeral | VCPUs | Is Public |
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
| 168af640-7f40-42c7-91b2-989abc5c5d8f | swift-storage | 4096 | 40 | 0 | 1 | True |
| 52148d1b-492e-48b4-b5fc-772849dd1b78 | baremetal | 4096 | 40 | 0 | 1 | True |
| 56e66542-ae60-416d-863e-0cb192d01b09 | control | 4096 | 40 | 0 | 1 | True |
| af6796e1-d0c4-4bfe-898c-532be194f7ac | block-storage | 4096 | 40 | 0 | 1 | True |
| e4d50fdd-0034-446b-b72c-9da19b16c2df | compute | 4096 | 40 | 0 | 1 | True |
| fc2e3acf-7fca-4901-9eee-4a4d6ef0265d | ceph-storage | 4096 | 40 | 0 | 1 | True |
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
(undercloud) [stack@undercloud ~]$Indicamos el perfil para cada nodo:
openstack baremetal node set --property capabilities='profile:control,boot_option:local' b4b2cf4a-b7ca-4095-af13-cc83be21c4f5
openstack baremetal node set --property capabilities='profile:ceph-storage,boot_option:local' b89a72a3-6bb7-429a-93bc-48393d225838
openstack baremetal node set --property capabilities='profile:ceph-storage,boot_option:local' 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e
openstack baremetal node set --property capabilities='profile:compute,boot_option:local' bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8
openstack baremetal node set --property capabilities='profile:compute,boot_option:local' 766ab623-464c-423d-a529-d9afb69d1167Comprobamos que hemos hecho todo correctamente:
(undercloud) [stack@undercloud ~]$ openstack overcloud profiles list
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| Node UUID | Node Name | Provision State | Current Profile | Possible Profiles |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | available | control | |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | available | ceph-storage | |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | available | ceph-storage | |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | available | compute | |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | available | compute | |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
(undercloud) [stack@undercloud ~]$Si todo está correcto, damos el comando para implementar overcloud:
openstack overcloud deploy --templates --control-scale 1 --compute-scale 2 --ceph-storage-scale 2 --control-flavor control --compute-flavor compute --ceph-storage-flavor ceph-storage --libvirt-type qemuEn una instalación real naturalmente se utilizarán plantillas personalizadas, en nuestro caso esto complicará mucho el proceso, ya que será necesario explicar cada edición en la plantilla. Como se escribió anteriormente, incluso una simple instalación será suficiente para que veamos cómo funciona.
Nota: la variable --libvirt-type qemu es necesaria en este caso, ya que usaremos virtualización anidada. De lo contrario, no tendrá máquinas virtuales en ejecución.
Ahora tiene aproximadamente una hora, o tal vez más (dependiendo de las capacidades del hardware) y solo puede esperar que después de este tiempo vea la siguiente inscripción:
2020-08-14 08:39:21Z [overcloud]: CREATE_COMPLETE Stack CREATE completed successfully
Stack overcloud CREATE_COMPLETE
Host 192.168.255.21 not found in /home/stack/.ssh/known_hosts
Started Mistral Workflow tripleo.deployment.v1.get_horizon_url. Execution ID: fcb996cd-6a19-482b-b755-2ca0c08069a9
Overcloud Endpoint: http://192.168.255.21:5000/
Overcloud Horizon Dashboard URL: http://192.168.255.21:80/dashboard
Overcloud rc file: /home/stack/overcloudrc
Overcloud Deployed
(undercloud) [stack@undercloud ~]$Ahora tienes una versión casi completa de openstack, en la que puedes aprender, experimentar, etc.
Comprobemos que todo funciona bien. En la pila del directorio de inicio del usuario hay dos archivos: uno stackrc (para administrar undercloud) y el otro overcloudrc (para administrar overcloud). Estos archivos deben especificarse como fuente, ya que contienen la información necesaria para la autenticación.
(undercloud) [stack@undercloud ~]$ openstack server list
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
| fd7d36f4-ce87-4b9a-93b0-add2957792de | overcloud-controller-0 | ACTIVE | ctlplane=192.168.255.15 | overcloud-full | control |
| edc77778-8972-475e-a541-ff40eb944197 | overcloud-novacompute-1 | ACTIVE | ctlplane=192.168.255.26 | overcloud-full | compute |
| 5448ce01-f05f-47ca-950a-ced14892c0d4 | overcloud-cephstorage-1 | ACTIVE | ctlplane=192.168.255.34 | overcloud-full | ceph-storage |
| ce6d862f-4bdf-4ba3-b711-7217915364d7 | overcloud-novacompute-0 | ACTIVE | ctlplane=192.168.255.19 | overcloud-full | compute |
| e4507bd5-6f96-4b12-9cc0-6924709da59e | overcloud-cephstorage-0 | ACTIVE | ctlplane=192.168.255.44 | overcloud-full | ceph-storage |
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ source overcloudrc
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$ openstack project list
+----------------------------------+---------+
| ID | Name |
+----------------------------------+---------+
| 4eed7d0f06544625857d51cd77c5bd4c | admin |
| ee1c68758bde41eaa9912c81dc67dad8 | service |
+----------------------------------+---------+
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$ openstack network agent list
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| ID | Agent Type | Host | Availability Zone | Alive | State | Binary |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| 10495de9-ba4b-41fe-b30a-b90ec3f8728b | Open vSwitch agent | overcloud-novacompute-1.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| 1515ad4a-5972-46c3-af5f-e5446dff7ac7 | L3 agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-l3-agent |
| 322e62ca-1e5a-479e-9a96-4f26d09abdd7 | DHCP agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-dhcp-agent |
| 9c1de2f9-bac5-400e-998d-4360f04fc533 | Open vSwitch agent | overcloud-novacompute-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| d99c5657-851e-4d3c-bef6-f1e3bb1acfb0 | Open vSwitch agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| ff85fae6-5543-45fb-a301-19c57b62d836 | Metadata agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-metadata-agent |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
(overcloud) [stack@undercloud ~]$En mi instalación, se requiere un pequeño toque más: agregar una ruta en el controlador, ya que la máquina con la que estoy trabajando está en una red diferente. Para hacer esto, vaya a control-1 en la cuenta heat-admin y escriba la ruta
(undercloud) [stack@undercloud ~]$ ssh heat-admin@192.168.255.15
Last login: Fri Aug 14 09:47:40 2020 from 192.168.255.1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ip route add 10.169.0.0/16 via 192.168.255.254Bueno, ahora puedes ir al horizonte. Toda la información (direcciones, nombre de usuario y contraseña) se encuentra en el archivo / home / stack / overcloudrc. El esquema final se ve así:

Por cierto, en nuestra instalación las direcciones de las máquinas se emitieron a través de DHCP y, como puede ver, se emiten "al azar". Puede codificar en la plantilla qué dirección debe adjuntarse a qué máquina durante la implementación, si lo necesita.
¿Cómo fluye el tráfico entre máquinas virtuales?
En este artículo consideraremos tres opciones para pasar el tráfico.
- Dos máquinas en un hipervisor en una red L2
- Dos máquinas en diferentes hipervisores en una red L2
- Dos máquinas en diferentes redes (enraizamiento entre redes)
Los casos con acceso al mundo exterior a través de una red externa, utilizando direcciones flotantes, así como enrutamiento distribuido, serán considerados la próxima vez, por ahora nos centraremos en el tráfico interno.
Para probar,
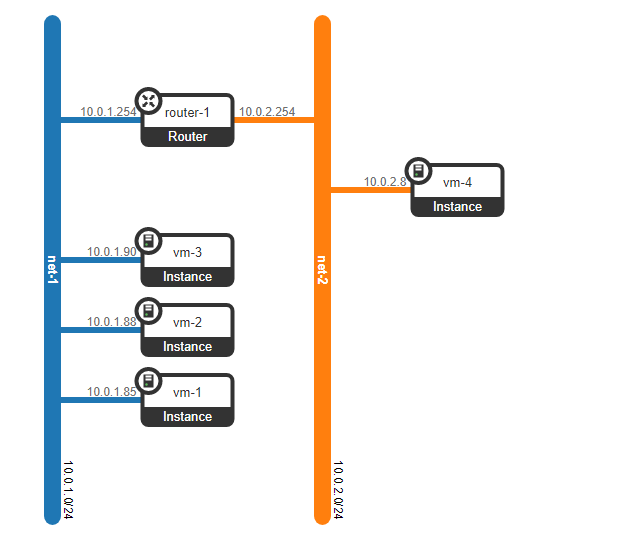
creemos el siguiente esquema: Hemos creado 4 máquinas virtuales - 3 en una red L2 - net-1 y otra 1 en la red net-2
(overcloud) [stack@undercloud ~]$ nova list --tenant 5e18ce8ec9594e00b155485f19895e6c
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
| ID | Name | Tenant ID | Status | Task State | Power State | Networks |
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
| f53b37b5-2204-46cc-aef0-dba84bf970c0 | vm-1 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-1=10.0.1.85 |
| fc8b6722-0231-49b0-b2fa-041115bef34a | vm-2 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-1=10.0.1.88 |
| 3cd74455-b9b7-467a-abe3-bd6ff765c83c | vm-3 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-1=10.0.1.90 |
| 7e836338-6772-46b0-9950-f7f06dbe91a8 | vm-4 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-2=10.0.2.8 |
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
(overcloud) [stack@undercloud ~]$ Veamos en qué hipervisores se ubican las máquinas creadas:
(overcloud) [stack@undercloud ~]$ nova show f53b37b5-2204-46cc-aef0-dba84bf970c0 | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-1 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-0.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000001 |(overcloud) [stack@undercloud ~]$ nova show fc8b6722-0231-49b0-b2fa-041115bef34a | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-2 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-1.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000002 |(overcloud) [stack@undercloud ~]$ nova show 3cd74455-b9b7-467a-abe3-bd6ff765c83c | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-3 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-0.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000003 |(overcloud) [stack@undercloud ~]$ nova show 7e836338-6772-46b0-9950-f7f06dbe91a8 | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-4 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-1.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000004 |(overcloud) [stack @ undercloud ~] $ Las
máquinas vm-1 y vm-3 están ubicadas en compute-0, las máquinas vm-2 y vm-4 están ubicadas en el nodo compute-1.
Además, se ha creado un enrutador virtual para permitir el enrutamiento entre las redes especificadas:
(overcloud) [stack@undercloud ~]$ openstack router list --project 5e18ce8ec9594e00b155485f19895e6c
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
| ID | Name | Status | State | Distributed | HA | Project |
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
| 0a4d2420-4b9c-46bd-aec1-86a1ef299abe | router-1 | ACTIVE | UP | False | False | 5e18ce8ec9594e00b155485f19895e6c |
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
(overcloud) [stack@undercloud ~]$ El enrutador tiene dos puertos virtuales que actúan como puertas de enlace para las redes:
(overcloud) [stack@undercloud ~]$ openstack router show 0a4d2420-4b9c-46bd-aec1-86a1ef299abe | grep interface
| interfaces_info | [{"subnet_id": "2529ad1a-6b97-49cd-8515-cbdcbe5e3daa", "ip_address": "10.0.1.254", "port_id": "0c52b15f-8fcc-4801-bf52-7dacc72a5201"}, {"subnet_id": "335552dd-b35b-456b-9df0-5aac36a3ca13", "ip_address": "10.0.2.254", "port_id": "92fa49b5-5406-499f-ab8d-ddf28cc1a76c"}] |
(overcloud) [stack@undercloud ~]$ Pero antes de ver cómo va el tráfico, veamos lo que tenemos en este momento en el nodo de control (que también es un nodo de red) y en el nodo de cálculo. Comencemos con un nodo de cálculo.
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-vsctl show
[heat-admin@overcloud-novacompute-0 ~]$ sudo sudo ovs-appctl dpif/show
system@ovs-system: hit:3 missed:3
br-ex:
br-ex 65534/1: (internal)
phy-br-ex 1/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/2: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
br-tun:
br-tun 65534/3: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff0f 3/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.15)
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$Por el momento, el nodo tiene tres puentes ovs: br-int, br-tun, br-ex. Entre ellos, como podemos ver, hay un conjunto de interfaces. Para facilitar la percepción, colocaremos todas estas interfaces en el diagrama y veremos qué sucede.

A partir de las direcciones a las que se elevan los túneles VxLAN, puede ver que se genera un túnel en compute-1 (192.168.255.26), el segundo túnel mira control-1 (192.168.255.15). Pero lo más interesante es que br-ex no tiene interfaces físicas, y si miras qué flujos están configurados, puedes ver que este puente en este momento solo puede eliminar tráfico.
[heat-admin@overcloud-novacompute-0 ~]$ ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.255.19 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe6a:eabe prefixlen 64 scopeid 0x20<link>
ether 52:54:00:6a:ea:be txqueuelen 1000 (Ethernet)
RX packets 2909669 bytes 4608201000 (4.2 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1821057 bytes 349198520 (333.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-novacompute-0 ~]$ Como puede ver en la salida, la dirección se atornilla directamente al puerto físico y no a la interfaz del puente virtual.
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-ex
port VLAN MAC Age
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-ex
cookie=0x9169eae8f7fe5bb2, duration=216686.864s, table=0, n_packets=303, n_bytes=26035, priority=2,in_port="phy-br-ex" actions=drop
cookie=0x9169eae8f7fe5bb2, duration=216686.887s, table=0, n_packets=0, n_bytes=0, priority=0 actions=NORMAL
[heat-admin@overcloud-novacompute-0 ~]$ Según la primera regla, se debe descartar todo lo que provenga del puerto phy-br-ex.
En realidad, no hay ningún otro lugar para que el tráfico llegue a este puente, excepto desde esta interfaz (cruce con br-int) y, a juzgar por las caídas, el tráfico BUM ya ha llegado al puente.
Es decir, el tráfico de este nodo solo puede pasar por el túnel VxLAN y nada más. Sin embargo, si enciende el DVR, la situación cambiará, pero lo resolveremos en otro momento. Cuando use aislamiento de red, por ejemplo, usando vlans, no tendrá una interfaz L3 en el vlan 0, sino varias interfaces. Sin embargo, el tráfico de VxLAN saldrá del nodo de la misma manera, pero también se encapsulará en algún tipo de vlan dedicado.
Descubrimos el nodo de cálculo, vamos al nodo de control.
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl dpif/show
system@ovs-system: hit:930491 missed:825
br-ex:
br-ex 65534/1: (internal)
eth0 1/2: (system)
phy-br-ex 2/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/3: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
br-tun:
br-tun 65534/4: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff13 3/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.19)
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$De hecho, podemos decir que todo es igual, pero la dirección IP ya no está en la interfaz física, sino en el puente virtual. Esto se debe a que este puerto es un puerto a través del cual el tráfico irá al mundo exterior.
[heat-admin@overcloud-controller-0 ~]$ ifconfig br-ex
br-ex: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.255.15 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe20:a22f prefixlen 64 scopeid 0x20<link>
ether 52:54:00:20:a2:2f txqueuelen 1000 (Ethernet)
RX packets 803859 bytes 1732616116 (1.6 GiB)
RX errors 0 dropped 63 overruns 0 frame 0
TX packets 808475 bytes 121652156 (116.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-ex
port VLAN MAC Age
3 100 28:c0:da:00:4d:d3 35
1 0 28:c0:da:00:4d:d3 35
1 0 52:54:00:98:e9:d6 0
LOCAL 0 52:54:00:20:a2:2f 0
1 0 52:54:00:2c:08:9e 0
3 100 52:54:00:20:a2:2f 0
1 0 52:54:00:6a:ea:be 0
[heat-admin@overcloud-controller-0 ~]$ Este puerto está vinculado al puente br-ex y dado que no hay etiquetas vlan en él, este puerto es un puerto troncal en el que se permiten todos los vlans, ahora el tráfico sale sin una etiqueta, como lo indica vlan-id 0 en la salida anterior.
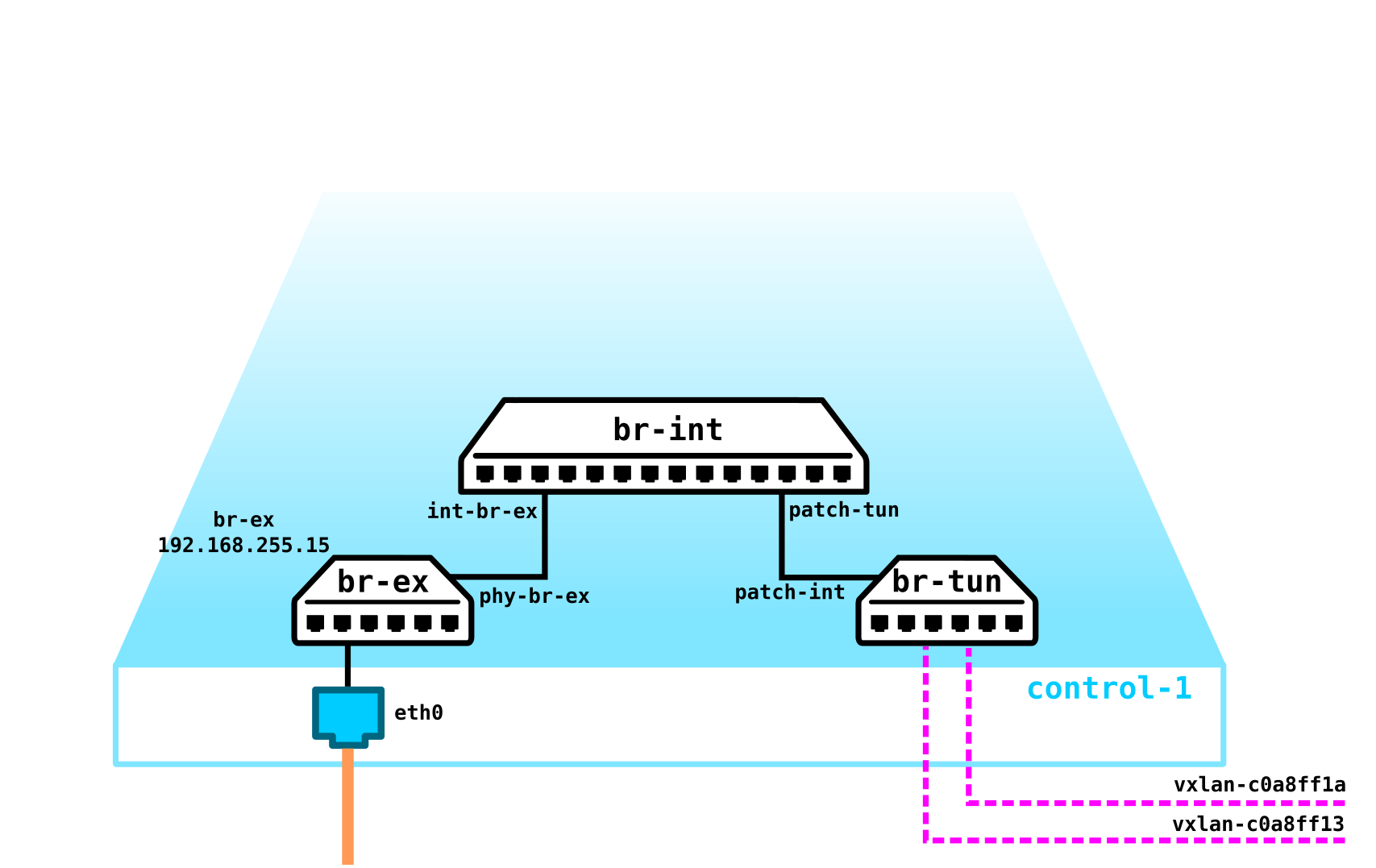
Todo lo demás en este momento es similar al nodo de computación: los mismos puentes, los mismos túneles que van a dos nodos de computación.
No consideraremos los nodos de almacenamiento en este artículo, pero para entenderlo hay que decir que la parte de red de estos nodos es banal hasta el punto de la desgracia. En nuestro caso, solo hay un puerto físico (eth0) con una dirección IP colgada y eso es todo. No hay túneles VxLAN, puentes de túneles, etc., no hay Ovs en absoluto, ya que no tiene sentido. Cuando se usa el aislamiento de red, este nodo tendrá dos interfaces (puertos físicos, baudios o solo dos vlans, no importa, depende de lo que desee): una para la administración, la segunda para el tráfico (escribir en el disco de la VM, leer disco, etc.).
Descubrimos lo que tenemos en los nodos en ausencia de servicios. Ahora comencemos 4 máquinas virtuales y veamos cómo cambia el esquema descrito anteriormente: deberíamos tener puertos, enrutadores virtuales, etc.
Hasta ahora, nuestra red se ve así:
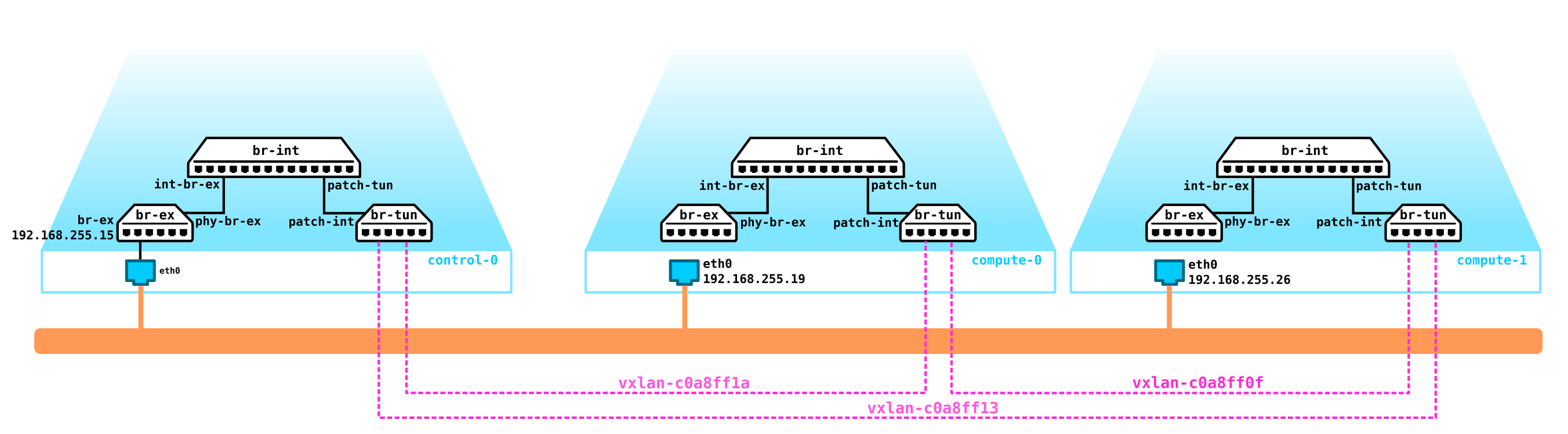
tenemos dos máquinas virtuales en cada computadora. Veamos cómo se incluye todo con compute-0.
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh list
Id Name State
----------------------------------------------------
1 instance-00000001 running
3 instance-00000003 running
[heat-admin@overcloud-novacompute-0 ~]$ La máquina tiene solo una interfaz virtual: tap95d96a75-a0:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Type Source Model MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
Esta interfaz mira el puente de Linux:
[heat-admin@overcloud-novacompute-0 ~]$ sudo brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242904c92a8 no
qbr5bd37136-47 8000.5e4e05841423 no qvb5bd37136-47
tap5bd37136-47
qbr95d96a75-a0 8000.de076cb850f6 no qvb95d96a75-a0
tap95d96a75-a0
[heat-admin@overcloud-novacompute-0 ~]$ Como puede ver en el resultado, solo hay dos interfaces en la brigada: tap95d96a75-a0 y qvb95d96a75-a0.
Vale la penaComo comprenderá, si tenemos un puerto qvb95d96a75-a0 en la brigada, que es un par vEth, entonces, ¿dónde está su contraparte, que lógicamente debería llamarse qvo95d96a75-a0? Veamos qué puertos hay en el OVS.
detenerse un poco en los tipos de dispositivos de red virtual en OpenStack: vtap - una interfaz virtual conectada a una instancia (VM)
qbr - Linux bridge
qvb y qvo - par vEth conectado a un puente Linux y Open vSwitch bridge
br-int, br-tun, br-vlan - Open vSwitch bridges
patch-, int-br-, phy-br- - Open vSwitch patch-interfaces que conectan puentes
qg, qr, ha, fg, sg - Puertos vSwitch abiertos usados por dispositivos virtuales para conectarse a OVS
[heat-admin@overcloud-novacompute-0 ~]$ sudo sudo ovs-appctl dpif/show
system@ovs-system: hit:526 missed:91
br-ex:
br-ex 65534/1: (internal)
phy-br-ex 1/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/2: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
qvo5bd37136-47 6/6: (system)
qvo95d96a75-a0 3/5: (system)
br-tun:
br-tun 65534/3: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff0f 3/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.15)
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$ Como podemos ver, el puerto está en br-int. Br-int actúa como un conmutador que termina los puertos de las máquinas virtuales. Además de qvo95d96a75-a0, la salida muestra el puerto qvo5bd37136-47. Este es el puerto a la segunda máquina virtual. Como resultado, nuestro esquema ahora se ve así: La

pregunta que debería interesar inmediatamente a un lector atento: ¿por qué hay un puente de Linux entre el puerto de la máquina virtual y el puerto OVS? El caso es que para proteger la máquina se utilizan grupos de seguridad, que no son más que iptables. OVS no funciona con iptables, por lo que se inventó esta "muleta". Sin embargo, está sobreviviendo a los suyos: se reemplaza por conntrack en las nuevas versiones.
Es decir, en última instancia, el esquema se ve así:

Dos máquinas en un hipervisor en una red L2
Dado que estas dos VM están en la misma red L2 y en el mismo hipervisor, el tráfico entre ellas lógicamente irá localmente a través de br-int, ya que ambas máquinas estarán en la misma VLAN:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Type Source Model MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000003
Interface Type Source Model MAC
-------------------------------------------------------
tap5bd37136-47 bridge qbr5bd37136-47 virtio fa:16:3e:83:ad:a4
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int
port VLAN MAC Age
6 1 fa:16:3e:83:ad:a4 0
3 1 fa:16:3e:44:98:20 0
[heat-admin@overcloud-novacompute-0 ~]$ Dos máquinas en diferentes hipervisores en la misma red L2
Ahora veamos cómo fluirá el tráfico entre dos máquinas en la misma red L2, pero ubicadas en diferentes hipervisores. Para ser honesto, nada cambiará mucho, solo el tráfico entre los hipervisores pasará por el túnel vxlan. Veamos un ejemplo.
Las direcciones de las máquinas virtuales entre las que vigilaremos el tráfico:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Type Source Model MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo virsh domiflist instance-00000002
Interface Type Source Model MAC
-------------------------------------------------------
tape7e23f1b-07 bridge qbre7e23f1b-07 virtio fa:16:3e:72:ad:53
[heat-admin@overcloud-novacompute-1 ~]$ Observamos la tabla de reenvío en br-int en compute-0:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:72:ad:53
2 1 fa:16:3e:72:ad:53 1
[heat-admin@overcloud-novacompute-0 ~]El tráfico debería ir al puerto 2; veamos qué es este puerto:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:7e:7f:28:1f:bd:54
2(patch-tun): addr:0a:bd:07:69:58:d9
3(qvo95d96a75-a0): addr:ea:50:9a:3d:69:58
6(qvo5bd37136-47): addr:9a:d1:03:50:3d:96
LOCAL(br-int): addr:1a:0f:53:97:b1:49
[heat-admin@overcloud-novacompute-0 ~]$Esto es patch-tun, es decir, la interfaz de br-tun. Veamos qué pasa con el paquete en br-tun:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:72:ad:53
cookie=0x8759a56536b67a8e, duration=1387.959s, table=20, n_packets=1460, n_bytes=138880, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:72:ad:53 actions=load:0->NXM_OF_VLAN_TCI[],load:0x16->NXM_NX_TUN_ID[],output:2
[heat-admin@overcloud-novacompute-0 ~]$ El paquete se empaqueta en VxLAN y se envía al puerto 2. Veamos a dónde conduce el puerto 2:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:b2:d1:f8:21:96:66
2(vxlan-c0a8ff1a): addr:be:64:1f:75:78:a7
3(vxlan-c0a8ff0f): addr:76:6f:b9:3c:3f:1c
LOCAL(br-tun): addr:a2:5b:6d:4f:94:47
[heat-admin@overcloud-novacompute-0 ~]$Este es un túnel vxlan en compute-1:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl dpif/show | egrep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$Vaya a compute-1 y vea qué sucede a continuación con el paquete:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:44:98:20
2 1 fa:16:3e:44:98:20 1
[heat-admin@overcloud-novacompute-1 ~]$ La Mac está en la tabla de reenvío br-int en compute-1 y, como puede ver en la salida anterior, es visible a través del puerto 2, que es puertos hacia br-tun:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:8a:d7:f9:ad:8c:1d
2(patch-tun): addr:46:cc:40:bd:20:da
3(qvoe7e23f1b-07): addr:12:78:2e:34:6a:c7
4(qvo3210e8ec-c0): addr:7a:5f:59:75:40:85
LOCAL(br-int): addr:e2:27:b2:ed:14:46Bueno, entonces vemos que hay un mac de destino en br-int en compute-1:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:72:ad:53
3 1 fa:16:3e:72:ad:53 0
[heat-admin@overcloud-novacompute-1 ~]$ Es decir, el paquete recibido volará al puerto 3, detrás del cual ya se encuentra la máquina virtual instance-00000003.
La belleza de implementar Openstack para aprender en una infraestructura virtual es que podemos captar fácilmente el tráfico entre hipervisores y ver qué sucede con él. Haremos esto ahora, ejecute tcpdump en el puerto vnet hacia compute-0:
[root@hp-gen9 bormoglotx]# tcpdump -vvv -i vnet3
tcpdump: listening on vnet3, link-type EN10MB (Ethernet), capture size 262144 bytes
*****************omitted*******************
04:39:04.583459 IP (tos 0x0, ttl 64, id 16868, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.19.39096 > 192.168.255.26.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 8012, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.1.88: ICMP echo request, id 5634, seq 16, length 64
04:39:04.584449 IP (tos 0x0, ttl 64, id 35181, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.26.speedtrace-disc > 192.168.255.19.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 59124, offset 0, flags [none], proto ICMP (1), length 84)
10.0.1.88 > 10.0.1.85: ICMP echo reply, id 5634, seq 16, length 64
*****************omitted*******************La primera línea muestra que el parche con la dirección 10.0.1.85 va a la dirección 10.0.1.88 (tráfico ICMP), y está envuelto en un paquete VxLAN con vni 22 y el paquete va desde el host 192.168.255.19 (compute-0) al host 192.168.255.26 ( compute-1). Podemos comprobar que el VNI coincide con el especificado en los ovs.
Regresemos a esta línea actions = load: 0-> NXM_OF_VLAN_TCI [], load: 0x16-> NXM_NX_TUN_ID [], salida: 2. 0x16 es vni hexadecimal. Traduzcamos este número al décimo sistema:
16 = 6*16^0+1*16^1 = 6+16 = 22Es decir, vni corresponde a la realidad.
La segunda línea muestra el tráfico de retorno, bueno, no tiene sentido explicarlo ahí, y todo está claro.
Dos máquinas en diferentes redes (enrutamiento entre redes)
El último caso de hoy es el enrutamiento entre redes dentro de un proyecto utilizando un enrutador virtual. Estamos considerando un caso sin DVR (lo veremos en otro artículo), por lo que el enrutamiento ocurre en el nodo de la red. En nuestro caso, el nodo de red no es una entidad separada y está ubicado en el nodo de control.
Primero, veamos que el enrutamiento funciona:
$ ping 10.0.2.8
PING 10.0.2.8 (10.0.2.8): 56 data bytes
64 bytes from 10.0.2.8: seq=0 ttl=63 time=7.727 ms
64 bytes from 10.0.2.8: seq=1 ttl=63 time=3.832 ms
^C
--- 10.0.2.8 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 3.832/5.779/7.727 msDado que en este caso el paquete debe ir a la puerta de enlace y enrutarse allí, necesitamos averiguar la dirección MAC de la puerta de enlace, para lo cual veremos la tabla ARP en la instancia:
$ arp
host-10-0-1-254.openstacklocal (10.0.1.254) at fa:16:3e:c4:64:70 [ether] on eth0
host-10-0-1-1.openstacklocal (10.0.1.1) at fa:16:3e:e6:2c:5c [ether] on eth0
host-10-0-1-90.openstacklocal (10.0.1.90) at fa:16:3e:83:ad:a4 [ether] on eth0
host-10-0-1-88.openstacklocal (10.0.1.88) at fa:16:3e:72:ad:53 [ether] on eth0Ahora veamos dónde se debe enviar el tráfico con el destino (10.0.1.254) fa: 16: 3e: c4: 64: 70:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:c4:64:70
2 1 fa:16:3e:c4:64:70 0
[heat-admin@overcloud-novacompute-0 ~]$ Miramos a dónde conduce el puerto 2:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:7e:7f:28:1f:bd:54
2(patch-tun): addr:0a:bd:07:69:58:d9
3(qvo95d96a75-a0): addr:ea:50:9a:3d:69:58
6(qvo5bd37136-47): addr:9a:d1:03:50:3d:96
LOCAL(br-int): addr:1a:0f:53:97:b1:49
[heat-admin@overcloud-novacompute-0 ~]$ Todo es lógico, el tráfico va a br-tun. Veamos en qué túnel vxlan estará envuelto:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:c4:64:70
cookie=0x8759a56536b67a8e, duration=3514.566s, table=20, n_packets=3368, n_bytes=317072, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:c4:64:70 actions=load:0->NXM_OF_VLAN_TCI[],load:0x16->NXM_NX_TUN_ID[],output:3
[heat-admin@overcloud-novacompute-0 ~]$ El tercer puerto es el túnel vxlan:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:a2:69:00:c5:fa:ba
2(vxlan-c0a8ff1a): addr:86:f0:ce:d0:e8:ea
3(vxlan-c0a8ff13): addr:72:aa:73:2c:2e:5b
LOCAL(br-tun): addr:a6:cb:cd:72:1c:45
[heat-admin@overcloud-controller-0 ~]$ Que mira el nodo de control:
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$ El tráfico llegó al nodo de control, por lo que debemos ir a él y ver cómo se llevará a cabo el enrutamiento.
Como recordará, el nodo de control en el interior se veía exactamente como el nodo de cómputo: los mismos tres puentes, solo br-ex tenía un puerto físico a través del cual el nodo podía enviar tráfico al exterior. La creación de la instancia cambió la configuración en los nodos informáticos: se agregaron puentes linux, iptables e interfaces a los nodos. La creación de redes y un enrutador virtual también dejó su huella en la configuración del nodo de control.
Por lo tanto, es obvio que la dirección de puerta de enlace debe estar en la tabla de reenvío br-int en el nodo de control. Comprobemos que está ahí y dónde se ve:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:c4:64:70
5 1 fa:16:3e:c4:64:70 1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:2e:58:b6:db:d5:de
2(patch-tun): addr:06:41:90:f0:9e:56
3(tapca25a97e-64): addr:fa:16:3e:e6:2c:5c
4(tap22015e46-0b): addr:fa:16:3e:76:c2:11
5(qr-0c52b15f-8f): addr:fa:16:3e:c4:64:70
6(qr-92fa49b5-54): addr:fa:16:3e:80:13:72
LOCAL(br-int): addr:06:de:5d:ed:44:44
[heat-admin@overcloud-controller-0 ~]$ Mac es visible desde el puerto qr-0c52b15f-8f. Si volvemos a la lista de puertos virtuales en Openstack, entonces este tipo de puerto se usa para conectar varios dispositivos virtuales a OVS. Para ser más precisos, qr es un puerto hacia el enrutador virtual, que se representa como un espacio de nombres.
Veamos qué espacios de nombres hay en el servidor:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns
qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe (id: 2)
qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 (id: 1)
qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 (id: 0)
[heat-admin@overcloud-controller-0 ~]$ Hasta tres copias. Pero a juzgar por los nombres, puede adivinar el propósito de cada uno de ellos. Regresaremos a las instancias con los ID 0 y 1 más adelante, ahora estamos interesados en el espacio de nombres qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe ip route
10.0.1.0/24 dev qr-0c52b15f-8f proto kernel scope link src 10.0.1.254
10.0.2.0/24 dev qr-92fa49b5-54 proto kernel scope link src 10.0.2.254
[heat-admin@overcloud-controller-0 ~]$ Este espacio de nombres tiene dos internos que creamos anteriormente. Ambos puertos virtuales se agregan a br-int. Comprobemos la dirección masiva del puerto qr-0c52b15f-8f, ya que el tráfico, a juzgar por la dirección de destino, fue exactamente a esta interfaz.
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe ifconfig qr-0c52b15f-8f
qr-0c52b15f-8f: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.0.1.254 netmask 255.255.255.0 broadcast 10.0.1.255
inet6 fe80::f816:3eff:fec4:6470 prefixlen 64 scopeid 0x20<link>
ether fa:16:3e:c4:64:70 txqueuelen 1000 (Ethernet)
RX packets 5356 bytes 427305 (417.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5195 bytes 490603 (479.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-controller-0 ~]$ Es decir, en este caso, todo funciona según las leyes del enrutamiento estándar. Dado que el tráfico está destinado al host 10.0.2.8, debe salir a través de la segunda interfaz qr-92fa49b5-54 y pasar por el túnel vxlan hasta el nodo de cálculo:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe arp
Address HWtype HWaddress Flags Mask Iface
10.0.1.88 ether fa:16:3e:72:ad:53 C qr-0c52b15f-8f
10.0.1.90 ether fa:16:3e:83:ad:a4 C qr-0c52b15f-8f
10.0.2.8 ether fa:16:3e:6c:ad:9c C qr-92fa49b5-54
10.0.2.42 ether fa:16:3e:f5:0b:29 C qr-92fa49b5-54
10.0.1.85 ether fa:16:3e:44:98:20 C qr-0c52b15f-8f
[heat-admin@overcloud-controller-0 ~]$ Todo es lógico, sin sorpresas. Miramos desde donde la dirección de amapola del host 10.0.2.8 es visible en br-int:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:6c:ad:9c
2 2 fa:16:3e:6c:ad:9c 1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:2e:58:b6:db:d5:de
2(patch-tun): addr:06:41:90:f0:9e:56
3(tapca25a97e-64): addr:fa:16:3e:e6:2c:5c
4(tap22015e46-0b): addr:fa:16:3e:76:c2:11
5(qr-0c52b15f-8f): addr:fa:16:3e:c4:64:70
6(qr-92fa49b5-54): addr:fa:16:3e:80:13:72
LOCAL(br-int): addr:06:de:5d:ed:44:44
[heat-admin@overcloud-controller-0 ~]$ Como era de esperar, el tráfico va a br-tun, veamos a qué túnel se dirige a continuación:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:6c:ad:9c
cookie=0x2ab04bf27114410e, duration=5346.829s, table=20, n_packets=5248, n_bytes=498512, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0002/0x0fff,dl_dst=fa:16:3e:6c:ad:9c actions=load:0->NXM_OF_VLAN_TCI[],load:0x63->NXM_NX_TUN_ID[],output:2
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:a2:69:00:c5:fa:ba
2(vxlan-c0a8ff1a): addr:86:f0:ce:d0:e8:ea
3(vxlan-c0a8ff13): addr:72:aa:73:2c:2e:5b
LOCAL(br-tun): addr:a6:cb:cd:72:1c:45
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$ El tráfico entra en el túnel para compute-1. Bueno, en compute-1 todo es simple: desde br-tun el paquete pasa a br-int y de allí a la interfaz de la máquina virtual:
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:6c:ad:9c
4 2 fa:16:3e:6c:ad:9c 1
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:8a:d7:f9:ad:8c:1d
2(patch-tun): addr:46:cc:40:bd:20:da
3(qvoe7e23f1b-07): addr:12:78:2e:34:6a:c7
4(qvo3210e8ec-c0): addr:7a:5f:59:75:40:85
LOCAL(br-int): addr:e2:27:b2:ed:14:46
[heat-admin@overcloud-novacompute-1 ~]$ Comprobemos que esta sea la interfaz correcta:
[heat-admin@overcloud-novacompute-1 ~]$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02429c001e1c no
qbr3210e8ec-c0 8000.ea27f45358be no qvb3210e8ec-c0
tap3210e8ec-c0
qbre7e23f1b-07 8000.b26ac0eded8a no qvbe7e23f1b-07
tape7e23f1b-07
[heat-admin@overcloud-novacompute-1 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo virsh domiflist instance-00000004
Interface Type Source Model MAC
-------------------------------------------------------
tap3210e8ec-c0 bridge qbr3210e8ec-c0 virtio fa:16:3e:6c:ad:9c
[heat-admin@overcloud-novacompute-1 ~]$En realidad, revisamos todo el paquete. Creo que notó que el tráfico pasó por diferentes túneles vxlan y salió con diferentes VNI. Veamos qué tipo de VNI son, después de lo cual recopilaremos un volcado en el puerto de control del nodo y nos aseguraremos de que el tráfico fluya exactamente como se describe anteriormente.
Entonces, el túnel para compute-0 tiene las siguientes acciones = cargar: 0-> NXM_OF_VLAN_TCI [], cargar: 0x16-> NXM_NX_TUN_ID [], salida: 3. Conversión de 0x16 a notación decimal:
0x16 = 6*16^0+1*16^1 = 6+16 = 22El túnel para compute-1 tiene el siguiente VNI: actions = load: 0-> NXM_OF_VLAN_TCI [], load: 0x63-> NXM_NX_TUN_ID [], output: 2. Conversión de 0x63 en notación decimal:
0x63 = 3*16^0+6*16^1 = 3+96 = 99Bueno, ahora veamos el vertedero:
[root@hp-gen9 bormoglotx]# tcpdump -vvv -i vnet4
tcpdump: listening on vnet4, link-type EN10MB (Ethernet), capture size 262144 bytes
*****************omitted*******************
04:35:18.709949 IP (tos 0x0, ttl 64, id 48650, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.19.41591 > 192.168.255.15.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 49042, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.2.8: ICMP echo request, id 5378, seq 9, length 64
04:35:18.710159 IP (tos 0x0, ttl 64, id 23360, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.15.38983 > 192.168.255.26.4789: [no cksum] VXLAN, flags [I] (0x08), vni 99
IP (tos 0x0, ttl 63, id 49042, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.2.8: ICMP echo request, id 5378, seq 9, length 64
04:35:18.711292 IP (tos 0x0, ttl 64, id 43596, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.26.42588 > 192.168.255.15.4789: [no cksum] VXLAN, flags [I] (0x08), vni 99
IP (tos 0x0, ttl 64, id 55103, offset 0, flags [none], proto ICMP (1), length 84)
10.0.2.8 > 10.0.1.85: ICMP echo reply, id 5378, seq 9, length 64
04:35:18.711531 IP (tos 0x0, ttl 64, id 8555, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.15.38983 > 192.168.255.19.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 63, id 55103, offset 0, flags [none], proto ICMP (1), length 84)
10.0.2.8 > 10.0.1.85: ICMP echo reply, id 5378, seq 9, length 64
*****************omitted*******************El primer paquete es un paquete vxlan desde el host 192.168.255.19 (compute-0) al host 192.168.255.15 (control-1) con vni 22, dentro del cual se empaqueta un paquete ICMP desde el host 10.0.1.85 al host 10.0.2.8. Como calculamos anteriormente, vni corresponde a lo que vimos en las salidas.
El segundo paquete es un paquete vxlan desde el host 192.168.255.15 (control-1) al host 192.168.255.26 (compute-1) con vni 99, dentro del cual se empaqueta un paquete ICMP desde el host 10.0.1.85 al host 10.0.2.8. Como calculamos anteriormente, vni corresponde a lo que vimos en las salidas.
Los siguientes dos paquetes son tráfico de retorno de 10.0.2.8, no 10.0.1.85.
Es decir, como resultado, obtuvimos el siguiente esquema de nodo de control: ¿

Como todo? Olvidamos dos espacios de nombres:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns
qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe (id: 2)
qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 (id: 1)
qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 (id: 0)
[heat-admin@overcloud-controller-0 ~]$ Como hablamos sobre la arquitectura de la plataforma en la nube, sería bueno que las máquinas recibieran direcciones automáticamente desde un servidor DHCP. Estos son dos servidores DHCP para nuestras dos redes 10.0.1.0/24 y 10.0.2.0/24.
Comprobemos que es así. Solo hay una dirección en este espacio de nombres, 10.0.1.1, la dirección del servidor DHCP en sí, y también se incluye en el br-int:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 ifconfig
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 1 bytes 28 (28.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1 bytes 28 (28.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
tapca25a97e-64: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.0.1.1 netmask 255.255.255.0 broadcast 10.0.1.255
inet6 fe80::f816:3eff:fee6:2c5c prefixlen 64 scopeid 0x20<link>
ether fa:16:3e:e6:2c:5c txqueuelen 1000 (Ethernet)
RX packets 129 bytes 9372 (9.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 49 bytes 6154 (6.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0Veamos si los procesos que contienen qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 en sus nombres en el nodo de control:
[heat-admin@overcloud-controller-0 ~]$ ps -aux | egrep qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638
root 640420 0.0 0.0 4220 348 ? Ss 11:31 0:00 dumb-init --single-child -- ip netns exec qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 /usr/sbin/dnsmasq -k --no-hosts --no-resolv --pid-file=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/pid --dhcp-hostsfile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/host --addn-hosts=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/addn_hosts --dhcp-optsfile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/opts --dhcp-leasefile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/leases --dhcp-match=set:ipxe,175 --local-service --bind-dynamic --dhcp-range=set:subnet-335552dd-b35b-456b-9df0-5aac36a3ca13,10.0.2.0,static,255.255.255.0,86400s --dhcp-option-force=option:mtu,1450 --dhcp-lease-max=256 --conf-file= --domain=openstacklocal
heat-ad+ 951620 0.0 0.0 112944 980 pts/0 S+ 18:50 0:00 grep -E --color=auto qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638
[heat-admin@overcloud-controller-0 ~]$ Existe un proceso de este tipo, y en base a la información presentada en el resultado anterior, podemos, por ejemplo, ver lo que tenemos actualmente en alquiler:
[heat-admin@overcloud-controller-0 ~]$ cat /var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/leases
1597492111 fa:16:3e:6c:ad:9c 10.0.2.8 host-10-0-2-8 01:fa:16:3e:6c:ad:9c
1597491115 fa:16:3e:76:c2:11 10.0.2.1 host-10-0-2-1 *
[heat-admin@overcloud-controller-0 ~]$Como resultado, obtenemos tal conjunto de servicios en el nodo de control:

Bueno, tenga en cuenta, son solo 4 máquinas, 2 redes internas y un enrutador virtual ... No tenemos redes externas aquí ahora, montones de proyectos diferentes, cada uno con sus propias redes (superpuestas ), y apagamos el enrutador distribuido, pero al final solo había un nodo de control en el banco de pruebas (para tolerancia a fallas, debe haber un quórum de tres nodos). Es lógico que en el comercio todo sea "un poco" más complicado, pero en este sencillo ejemplo entendemos cómo debería funcionar - si tienes 3 o 300 espacios de nombres, claro, es importante, pero desde el punto de vista del funcionamiento de toda la estructura, nada cambiará mucho ... pero por ahora no pegue algún tipo de proveedor SDN. Pero esa es una historia completamente diferente.
Espero que haya sido interesante. Si hay comentarios / adiciones bien, o en algún lugar mentí abiertamente (soy una persona y mi opinión siempre será subjetiva) - escribe lo que necesita ser corregido / agregado - corregiremos / agregaremos todo.
En conclusión, me gustaría decir algunas palabras sobre la comparación de Openstack (tanto de vainilla como de proveedor) con una solución en la nube de VMWare; con demasiada frecuencia me han hecho esta pregunta durante los últimos años y, para ser honesto, estoy cansado, pero aún así. En mi opinión, estas dos soluciones son muy difíciles de comparar, pero podemos decir de manera inequívoca que hay desventajas en ambas soluciones, y al elegir una solución, hay que sopesar los pros y los contras.
Si OpenStack es una solución impulsada por la comunidad, VMWare tiene derecho a hacer solo lo que quiera (léase, lo que es rentable para él) y esto es lógico, porque es una empresa comercial que está acostumbrada a ganar dinero con sus clientes. Pero hay un PERO grande y gordo: puede dejar OpenStack de Nokia, por ejemplo, y cambiar a una solución de, por ejemplo, Juniper (Contrail Cloud), pero difícilmente podrá salir de VMWare. Para mí, estas dos soluciones se ven así: Openstack (proveedor) es una jaula simple en la que te colocan, pero tienes la llave y puedes salir en cualquier momento. VMWare es una jaula de oro, el propietario tiene la llave de la jaula y te costará mucho.
No estoy haciendo campaña ni para el primer producto ni para el segundo: usted elige lo que necesita. Pero si tuviera esa opción, elegiría ambas soluciones: VMWare para la nube de TI (cargas bajas, administración conveniente), OpenStack de algún proveedor (Nokia y Juniper brindan muy buenas soluciones llave en mano) para las nubes de telecomunicaciones. No usaría Openstack para TI pura; es como disparar a un gorrión con un cañón, pero no veo ninguna contraindicación para usarlo, excepto por redundancia. Sin embargo, usar VMWare en telecomunicaciones, cómo transportar escombros en un Ford Raptor, es hermoso desde el exterior, pero el conductor tiene que hacer 10 viajes en lugar de uno.
En mi opinión, el mayor inconveniente de VMWare es su total cierre: la empresa no le dará ninguna información sobre cómo funciona, por ejemplo, vSAN o lo que hay en el núcleo del hipervisor; simplemente no es rentable para él, es decir, nunca se convertirá en un experto en VMWare. sin el soporte del proveedor, está condenado (muy a menudo me encuentro con expertos de VMWare que están desconcertados por preguntas banales). Para mí, VMWare es comprar un automóvil con el capó cerrado; sí, tal vez tenga especialistas que puedan cambiar la correa de distribución, pero solo el que le vendió esta solución puede abrir el capó. Personalmente, no me gustan las soluciones en las que no puedo encajar. Dirás que es posible que no tengas que pasar por debajo del capó. Sí, esto es posible, pero lo miraré cuando necesite ensamblar una función grande en la nube desde 20-30 máquinas virtuales, 40-50 redes,la mitad quiere salir y la otra mitad pide la aceleración SR-IOV; de lo contrario, necesitará un par de docenas más de estas máquinas; de lo contrario, el rendimiento no será suficiente.
Hay otros puntos de vista, por lo que depende de ti decidir qué elegir y, lo más importante, eres responsable de tu elección más adelante. Esta es solo mi opinión: una persona que ha visto y tocado al menos 4 productos: Nokia, Juniper, Red Hat y VMWare. Es decir, tengo algo con lo que comparar.