Gran parte de la vida de un proyecto depende de qué tan bien pensado el modelo de objeto y la estructura de la base al principio.
El enfoque generalmente aceptado ha sido y sigue siendo varias opciones para combinar el esquema "estrella" con la tercera forma normal. Como regla general, de acuerdo con el principio: datos iniciales - 3NF, vitrinas - estrella. Este enfoque probado por el tiempo, respaldado por una gran cantidad de investigación, es lo primero (y a veces lo único) en lo que piensa una persona con experiencia en DWH cuando piensa en cómo debería ser un repositorio analítico.
Por otro lado, las empresas en general y los requisitos de los clientes en particular tienden a cambiar rápidamente, y los datos crecen tanto "en profundidad" como "en amplitud". Y aquí es donde se manifiesta el principal inconveniente de la estrella: flexibilidad limitada .
Y si en su tranquila y acogedora vida como desarrollador de DWH, de repente:
- surgió la tarea de “hacer al menos algo rápido, y luego ya veremos”;
- apareció un proyecto de rápido desarrollo, con la conexión de nuevas fuentes y la reelaboración del modelo de negocio al menos una vez por semana;
- ha aparecido un cliente que no imagina cómo debería verse el sistema y qué funciones debería realizar al final, pero que está listo para experimentos y un refinamiento constante del resultado deseado con un enfoque coherente;
- el director del proyecto vino con la buena noticia: "¡Y ahora tenemos ágil!"
O si solo tiene curiosidad por saber de qué otra manera puede construir almacenamiento, ¡bienvenido debajo del gato!

¿Qué significa flexibilidad?
Primero, definamos qué propiedades debe tener el sistema para ser llamado "flexible".
Por separado, cabe señalar que las propiedades descritas deben relacionarse específicamente con el sistema y no con el proceso de su desarrollo. Por lo tanto, si desea leer sobre Agile como metodología de desarrollo, es mejor leer otros artículos. Por ejemplo, allí mismo, en Habré, hay muchos materiales interesantes (tanto generales como prácticos y problemáticos ).
Esto no significa que el proceso de desarrollo y la estructura del CD no estén conectados en absoluto. En general, debería ser mucho más fácil desarrollar un almacenamiento ágil de arquitectura flexible. Sin embargo, en la práctica, hay más opciones con el desarrollo ágil del clásico DWH por Kimbal y DataVault por cascada que felices coincidencias de flexibilidad en sus dos hipóstasis en un proyecto.
Entonces, ¿qué capacidades debería tener el almacenamiento flexible? Aquí hay tres puntos:
- La entrega temprana y el seguimiento rápido significan que, idealmente, el primer resultado comercial (por ejemplo, los primeros informes de trabajo) debe recibirse lo antes posible, es decir, incluso antes de que todo el sistema esté completamente diseñado e implementado. Además, cada revisión posterior también debería llevar el menor tiempo posible.
- — , . — , , . , , — .
- Adaptación constante a los requisitos comerciales cambiantes : la estructura general del objeto debe diseñarse no solo teniendo en cuenta la posible expansión, sino con la expectativa de que la dirección de esta próxima expansión ni siquiera sueñe con usted en la etapa de diseño.
Y sí, el cumplimiento de todos estos requisitos en un solo sistema es posible (por supuesto, en ciertos casos y con algunas reservas).
A continuación, consideraré dos de las metodologías de diseño ágil más populares para HD: modelo Anchor y Data Vault.... Detrás de paréntesis hay técnicas tan excelentes como EAV, 6NF (en su forma pura) y todo lo relacionado con las soluciones NoSQL, no porque sean de alguna manera peores, y ni siquiera porque en este caso el artículo amenazaría con adquirir el volumen de la media. disera. Es solo que todo esto se refiere a soluciones de una clase ligeramente diferente, ya sea a técnicas que puede aplicar en casos específicos, independientemente de la arquitectura general de su proyecto (como EAV), oa otros paradigmas globales de almacenamiento de información (como bases de datos de gráficos y otras opciones). NoSQL).
Problemas del enfoque "clásico" y sus soluciones en metodologías ágiles
Por el enfoque "clásico" me refiero a una buena estrella vieja (independientemente de la implementación específica de las capas subyacentes, perdóneme los seguidores de Kimball, Inmon y CDM).
1. Cardinalidad rígida de los lazos
Este modelo se basa en una clara separación de datos en dimensiones (dimensión) y hechos (hecho) . Y esto, maldita sea, es lógico: después de todo, el análisis de datos en la inmensa mayoría de los casos se reduce al análisis de ciertos indicadores numéricos (hechos) en ciertas secciones (dimensiones).
En este caso, los enlaces entre objetos se establecen en forma de enlaces entre tablas mediante una clave externa. Esto parece bastante natural, pero conduce inmediatamente a la primera limitación de la flexibilidad: una definición rígida de la cardinalidad de las conexiones .
Esto significa que en la etapa de diseño de las tablas, debe definir con precisión para cada par de objetos relacionados si pueden ser de muchos a muchos o solo de 1 a muchos y "en qué dirección". Depende directamente de cuál de las tablas tendrá una clave principal y cuál tendrá una clave externa. Cambiar esta actitud cuando se reciben nuevos requisitos probablemente conducirá a un rediseño de la base.
Por ejemplo, al diseñar el objeto "cheque de caja", usted, confiando en los juramentos del departamento de ventas, estableció la posibilidad de que una promoción actúe en varios puestos de cheques (pero no al revés):
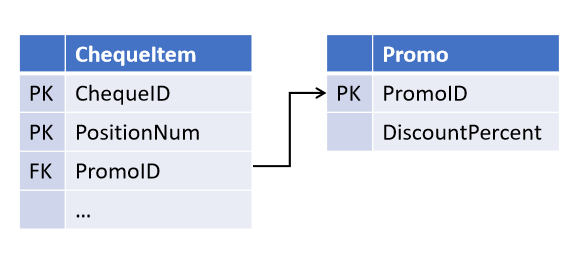
Y después de un tiempo, los compañeros introdujeron una nueva estrategia de marketing, en la que varias promociones pueden actuar en el mismo puesto al mismo tiempo . Y ahora necesita modificar las tablas seleccionando el enlace en un objeto separado.
(Todos los objetos derivados, en los que se realiza una verificación de promoción, ahora también deben mejorarse).
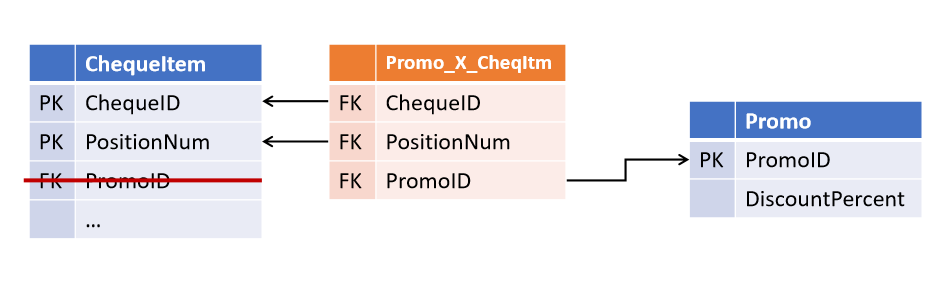
Vínculos en el modelo de ancla y bóveda de datos
Resultó bastante simple evitar tal situación:
Este enfoque fue propuesto por Dan Linstedt como parte del paradigma de Data Vault y es totalmente compatible con Lars Rönnbäck en Anchor Model .
Como resultado, obtenemos la primera característica distintiva de las metodologías ágiles:
Las relaciones entre los objetos no se almacenan en los atributos de las entidades principales, sino que son un tipo de objeto separado.Los Data Vault son tabla-ligamento llamados Link , y los Anchor Models , el Tie . A primera vista son muy similares, aunque sus diferencias no se limitan al nombre (que se comentará a continuación). En ambas arquitecturas, las tablas de vínculos pueden vincular cualquier número de entidades (no necesariamente 2).
A primera vista, esta redundancia proporciona una flexibilidad significativa para las modificaciones. Dicha estructura se vuelve tolerante no solo para cambiar la cardinalidad de los enlaces existentes, sino también para agregar nuevos; si ahora la posición del cheque también tiene un enlace al cajero que lo marcó, la apariencia de dicho enlace simplemente se convertirá en un complemento sobre las tablas existentes sin afectar ningún objeto existente y procesos.

2. Duplicación de datos
El segundo problema, resuelto por arquitecturas flexibles, es menos obvio y es inherente principalmente a las medidas del tipo SCD2 (dimensiones que cambian lentamente del segundo tipo), aunque no solo a ellas.
En el almacenamiento clásico, una dimensión suele ser una tabla que contiene una clave sustituta (como PK) y un conjunto de claves y atributos comerciales en columnas independientes.

Si la dimensión está versionada, los límites de tiempo de la versión se agregan al conjunto estándar de campos y aparecen varias versiones por línea en la fuente en la tienda (una por cada cambio en los atributos versionados).
Si una dimensión contiene al menos un atributo versionado que cambia con frecuencia, la cantidad de versiones de dicha dimensión será impresionante (incluso si los otros atributos no están versionados o nunca cambian), y si hay varios de esos atributos, el número de versiones puede crecer exponencialmente a partir de su número. Dicha dimensión puede ocupar una cantidad significativa de espacio en disco, aunque la mayoría de los datos almacenados en ella son simplemente valores duplicados de atributos sin cambios de otras filas.

Al mismo tiempo, la desnormalización también se usa con mucha frecuencia : algunos de los atributos se almacenan intencionalmente como un valor y no como una referencia a un directorio u otra dimensión. Este enfoque acelera el acceso a los datos al reducir el número de combinaciones al acceder a una dimensión.
Como regla general, esto lleva al hecho de quela misma información se almacena simultáneamente en varios lugares . Por ejemplo, la información sobre la región de residencia y la pertenencia a la categoría del cliente se puede almacenar simultáneamente en las dimensiones "Cliente" y los hechos "Compra", "Entrega" y "Llamadas al centro de atención telefónica", así como en la tabla de enlace "Cliente - Administrador de clientes".
En general, lo anterior se aplica a las mediciones regulares (no versionadas), pero en las versionadas pueden tener una escala diferente: la aparición de una nueva versión de un objeto (especialmente en retrospectiva) conduce no solo a actualizar todas las tablas relacionadas, sino a la aparición en cascada de nuevas versiones de objetos relacionados - cuando la Tabla 1 se usa para construir la Tabla 2 y la Tabla 2 se usa para construir la Tabla 3, etc. Incluso si ninguno de los atributos de la Tabla 1 participa en la construcción de la Tabla 3 (y otros atributos de la Tabla 2 obtenidos de otras fuentes están involucrados), una actualización versionada de esta construcción al menos conducirá a costos generales adicionales y, como máximo, a versiones innecesarias en la Tabla 3. que no tiene nada que ver con eso y más adelante en la cadena.

3. Complejidad no lineal de la revisión
Además, cada nuevo mercado, construido sobre otro, aumenta el número de lugares en los que los datos pueden "divergir" al realizar cambios en ETL. Esto, a su vez, conduce a un aumento de la complejidad (y duración) de cada revisión posterior.
Si lo anterior se refiere a sistemas con procesos ETL raramente modificados, puede vivir en tal paradigma; solo necesita asegurarse de que las nuevas modificaciones se introduzcan correctamente en todos los objetos relacionados. Si las revisiones ocurren con frecuencia, la probabilidad de "perder" accidentalmente algunos enlaces aumenta significativamente.
Si, además, tenemos en cuenta que el ETL “versionado” es mucho más complicado que el “no versionado”, se vuelve bastante difícil evitar errores con revisiones frecuentes de toda esta economía.
Almacenamiento de objetos y atributos en Data Vault y Anchor Model
El enfoque propuesto por los autores de arquitecturas ágiles se puede formular de la siguiente manera:
Es necesario separar lo que cambia de lo que permanece sin cambios. Es decir, mantenga las claves separadas de los atributos.Al mismo tiempo, no debe confundir un atributo no versionado con uno que no cambia : el primero no almacena el historial de su cambio, pero puede cambiar (por ejemplo, cuando se corrige un error de entrada o se reciben nuevos datos); el segundo nunca cambia.
Los puntos de vista sobre qué exactamente se puede considerar inmutable en Data Vault y Anchor Model son diferentes.
Desde el punto de vista de la arquitectura de Data Vault , todo el conjunto de claves puede considerarse sin cambios : natural (TIN de la organización, código de producto en el sistema de origen, etc.) y sustituto. Al mismo tiempo, los atributos restantes se pueden dividir en grupos por fuente y / o frecuencia de cambios, y se puede mantener una tabla separada con un conjunto independiente de versiones para cada grupo .
En el paradigmaAnchor Model se considera clave sustituta de entidad única inmutable . Todo lo demás (incluidas las claves naturales) es solo un caso especial de sus atributos. Al mismo tiempo, todos los atributos por defecto son independientes entre sí , por lo tanto, se debe crear una tabla separada para cada atributo .
En Data Vault, las tablas que contienen claves de entidad se denominan Hubs . Los concentradores siempre contienen un conjunto fijo de campos:
- Claves naturales de entidad
- Clave sustituta
- Enlace a la fuente
- Registro de tiempo de adición
Las entradas en Hubs nunca se modifican y no tienen versión . Exteriormente, los concentradores son muy similares a las tablas del tipo de mapa de ID que se usan en algunos sistemas para generar sustitutos, sin embargo, se recomienda no usar una secuencia entera como sustitutos en Data Vault, sino un hash de un conjunto de claves comerciales. Este enfoque simplifica la carga de enlaces y atributos de las fuentes (no necesita unirse al concentrador para obtener un sustituto, solo necesita calcular el hash a partir de la clave natural), pero puede causar otros problemas (relacionados, por ejemplo, con colisiones, mayúsculas y minúsculas y caracteres no imprimibles en claves de cadena, etc. .p.), por lo que no es generalmente aceptado.
Todos los demás atributos de las entidades se almacenan en tablas especiales llamadas satélites.... Un hub puede tener varios satélites que almacenan diferentes conjuntos de atributos.
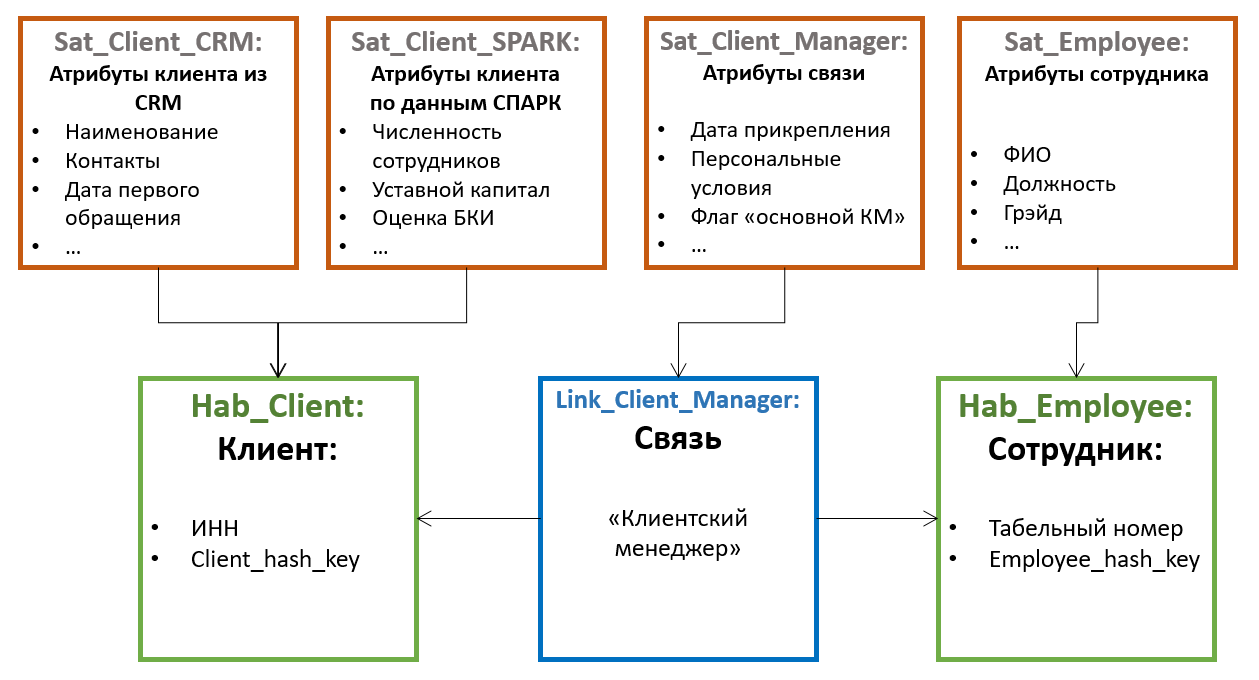
La distribución de atributos entre satélites se basa en el principio de cambio conjunto : un satélite puede almacenar atributos no versionados (por ejemplo, fecha de nacimiento y SNILS para un individuo), en otro, rara vez cambian los versionados (por ejemplo, apellido y número de pasaporte), en el tercero, a menudo cambiar (por ejemplo, dirección de entrega, categoría, fecha del último pedido, etc.). En este caso, el versionado se realiza a nivel de satélites individuales, y no de la entidad en su conjunto; por lo tanto, es recomendable distribuir los atributos de manera que la intersección de versiones dentro de un satélite sea mínima (lo que reduce el número total de versiones almacenadas).
Además, para optimizar el proceso de carga de datos, los atributos obtenidos de diversas fuentes a menudo se colocan en satélites separados.
Los satélites se comunican con el Hub mediante una clave externa (que corresponde a una cardinalidad de 1 a muchos). Esto significa que esta arquitectura "predeterminada" admite varios valores de atributos (por ejemplo, varios números de teléfono de contacto para el mismo cliente).
En el modelo Anchor, las tablas que contienen claves se denominan Anchor . Y mantienen:
- Solo llaves sustitutas
- Enlace a la fuente
- Registro de tiempo de adición
Las claves naturales se consideran atributos ordinarios desde el punto de vista del modelo de anclaje . Esta opción puede parecer más difícil de entender, pero ofrece mucho más espacio para la identificación de objetos.

Por ejemplo, si los datos sobre la misma entidad pueden provenir de diferentes sistemas, cada uno de los cuales usa su propia clave natural. En Data Vault, esto puede llevar a estructuras bastante engorrosas de varios hubs (uno por fuente + la versión maestra unificadora), mientras que en el modelo Anchor, la clave natural de cada fuente cae en su propio atributo y se puede usar durante la carga independientemente de todas las demás.
Pero hay un punto insidioso aquí: si los atributos de diferentes sistemas se combinan en una entidad, lo más probable es que haya algunosreglas de "pegado" , según las cuales el sistema debe entender que los registros de diferentes fuentes corresponden a una instancia de una entidad.
En Data Vault, estas reglas probablemente determinarán la formación del "centro sustituto" de la entidad maestra y no afectarán de ninguna manera a los centros que almacenan las claves naturales de las fuentes y sus atributos originales. Si en algún momento cambian las reglas de empalme (o llega una actualización de los atributos por los que se realiza), será suficiente para reformar los hubs sustitutos.
En el modelo Anchor, sin embargo, es muy probable que dicha entidad se almacene en un único ancla.... Esto significa que todos los atributos, independientemente de la fuente de donde provengan, estarán vinculados al mismo sustituto. Separar registros fusionados erróneamente y, en general, hacer un seguimiento de la relevancia de la fusión en un sistema de este tipo puede ser significativamente más difícil, especialmente si las reglas son lo suficientemente complejas y cambian a menudo, y el mismo atributo se puede obtener de diferentes fuentes (aunque definitivamente es posible, ya que cada la versión del atributo conserva un enlace a su fuente).
En cualquier caso, si se supone que su sistema debe implementar la funcionalidad de deduplicación, combinación de registros y otros elementos de MDM, vale la pena observar de cerca los aspectos del almacenamiento de claves naturales en metodologías ágiles. Es probable que el diseño más engorroso de Data Vault resulte de repente más seguro en términos de errores de fusión.
El modelo de ancla también proporciona un tipo adicional de objeto llamado Nudo, de hecho, es un tipo de ancla degenerado especial que puede contener solo un atributo. Se supone que los nodos se utilizan para almacenar directorios planos (por ejemplo, género, estado civil, categoría de servicio al cliente, etc.). A diferencia de Anchor, Node no tiene tablas de atributos asociadas, y su único atributo (nombre) siempre se almacena en la misma tabla con la clave. Los nodos están vinculados a las tablas Anchors by Tie, al igual que los anclajes entre sí.
No hay una opinión inequívoca sobre el uso de Nodos. Por ejemplo, Nikolai Golov , que está promoviendo activamente el uso del modelo Anchor en Rusia, cree (no sin razón) que para ningún libro de referencia es imposible decir con certeza que siempre será estático y de un solo nivel, por lo tanto, es mejor usar un Anchor completo para todos los objetos a la vez.
Otra diferencia importante entre el modelo Data Vault y el modelo Anchor es la presencia de atributos para los enlaces :
En Data Vault, los enlaces son los mismos objetos completos que los Hubs y pueden tenerpropios atributos . En el modelo de ancla, los enlaces se utilizan solo para conectar anclajes y no pueden tener sus propios atributos . Esta diferencia proporciona enfoques significativamente diferentes para modelar hechos , que se discutirán a continuación.
Almacenamiento de hechos
Antes de eso, hablamos principalmente sobre modelado de medidas. Con los hechos, la situación es un poco menos sencilla.
En Data Vault, un objeto típico para almacenar hechos es un Enlace , en los Satélites de los cuales se agregan indicadores reales.
Este enfoque parece intuitivo. Proporciona un fácil acceso a los indicadores analizados y generalmente es similar a una tabla de hechos tradicional (solo los indicadores se almacenan no en la tabla en sí, sino en la "adyacente"). Pero también hay dificultades: una de las modificaciones típicas del modelo, expandir la clave de hechos, requiere agregar una nueva clave externa a Link . Y esto, a su vez, "rompe" la modularidad y potencialmente provoca la necesidad de mejoras en otros objetos.
En el modelo de anclaUn enlace no puede tener sus propios atributos, por lo que este enfoque no funcionará: absolutamente todos los atributos e indicadores deben estar vinculados a un ancla específica. La conclusión de esto es simple: cada hecho también necesita su propio ancla . Para algunos de los que estamos acostumbrados a tomar como hechos, puede parecer natural; por ejemplo, el hecho de una compra se reduce perfectamente al objeto "pedido" o "cheque", una visita a un sitio, a una sesión, etc. Pero también hay hechos para los que no es tan fácil encontrar un “objeto portador” tan natural, por ejemplo, los restos de mercancías en los almacenes al comienzo de cada día.
En consecuencia, no hay problemas con la modularidad al expandir la clave de hechos en el modelo de Ancla (basta con agregar un nuevo Enlace al Ancla correspondiente), pero el diseño del modelo para mostrar hechos es menos inequívoco, pueden aparecer Anclas “artificiales” que reflejan el modelo de objeto de negocio no es obvio.
Cómo se logra la flexibilidad
La construcción resultante en ambos casos contiene significativamente más tablas que la dimensión tradicional. Pero puede ocupar mucho menos espacio en disco con el mismo conjunto de atributos versionados que la dimensión tradicional. Naturalmente, aquí no hay magia, se trata de normalización. Al distribuir atributos entre satélites (en el almacén de datos) o tablas separadas (modelo ancla), reducimos (o eliminamos por completo) la duplicación de valores de algunos atributos al cambiar otros .
Para el Data Vault, la ganancia dependerá de la distribución de atributos entre los satélites, y para el modelo de ancla , será casi directamente proporcional al número promedio de versiones por objeto de medición.
Sin embargo, ganar espacio es una ventaja importante, pero no la principal, de almacenar atributos por separado. Junto con el almacenamiento de enlaces por separado, este enfoque hace que el repositorio tenga un diseño modular . Esto significa que la adición de atributos individuales y áreas temáticas completamente nuevas en tal modelo parece un complemento sobre un conjunto de objetos existente sin cambiarlos. Y esto es exactamente lo que hace que las metodologías descritas sean flexibles.
También se asemeja a la transición de la producción de piezas a la producción en masa: si en el enfoque tradicional cada tabla modelo es única y requiere atención separada, en metodologías flexibles ya es un conjunto de “detalles” típicos. Por un lado, hay más tablas, los procesos de carga y obtención de datos deberían parecer más complicados. Por otro lado, se vuelven típicos . Esto significa que pueden automatizarse y gestionarse mediante metadatos . La pregunta “¿cómo lo vamos a plantear?”, Cuya respuesta podría ocupar una parte significativa del diseño de mejoras, ahora simplemente no vale la pena (así como la pregunta sobre el impacto de los cambios de modelo en los procesos de trabajo).
Esto no significa que los analistas no sean necesarios en un sistema de este tipo; alguien todavía tiene que trabajar en un conjunto de objetos con atributos y averiguar dónde y cómo cargar todo esto. Pero la cantidad de trabajo, así como la probabilidad y el costo de un error, se reducen significativamente. Tanto en la etapa de análisis como durante el desarrollo de ETL, que en una parte esencial se puede reducir a la edición de metadatos.
Lado oscuro
Todo lo anterior hace que ambos enfoques sean realmente flexibles, tecnológicamente avanzados y adecuados para un refinamiento iterativo. Por supuesto, también hay un “barril de ungüento”, del que creo que ya estás adivinando.
La descomposición de datos, que es la base de la modularidad de las arquitecturas flexibles, conduce a un aumento en el número de tablas y, en consecuencia, a la sobrecarga de uniones al buscar. Para simplemente obtener todos los atributos de una dimensión, una selección es suficiente en el repositorio clásico y una arquitectura flexible requerirá una serie de uniones. Además, si para los informes todas estas uniones se pueden escribir por adelantado, los analistas que están acostumbrados a escribir SQL a mano sufrirán el doble.
Hay varios hechos que facilitan esta situación:
Cuando se trabaja con grandes dimensiones, casi nunca se utilizan todos sus atributos al mismo tiempo. Esto significa que puede haber menos uniones de las que parece cuando mira por primera vez el modelo. En Data Vault, también puede tener en cuenta la frecuencia de uso compartido esperada al distribuir atributos entre satélites. Al mismo tiempo, los propios Hubs o Anchors son necesarios principalmente para generar y mapear sustitutos en la etapa de carga y rara vez se utilizan en solicitudes (especialmente para Anchors).
Todas las uniones son por clave.Además, una forma más "concisa" de almacenar datos reduce la sobrecarga de escanear tablas cuando sea necesario (por ejemplo, al filtrar por valor de atributo). Esto puede llevar al hecho de que la obtención de una base de datos normalizada con un montón de combinaciones será incluso más rápida que la exploración de una dimensión pesada con muchas versiones por línea.
Por ejemplo, aquí en este artículo hay una prueba de desempeño comparativa detallada del Modelo Anchor con una selección de una tabla.
Depende mucho del motor. Muchas plataformas modernas tienen mecanismos internos de optimización de combinaciones. Por ejemplo, MS SQL y Oracle pueden "omitir" las uniones a las tablas si sus datos no se utilizan en ningún lugar excepto en otras uniones y no afectan la selección final (eliminación de tabla / unión), mientras que MPP VerticaLa experiencia de los compañeros de Avito , resultó ser un excelente motor para el modelo Anchor, teniendo en cuenta alguna optimización manual del plan de consultas. Por otro lado, mantener el modelo Anchor, por ejemplo, en Click House, que tiene un soporte de unión limitado, no parece una buena idea por ahora.
Además, existen técnicas especiales para ambas arquitecturas para facilitar el acceso a los datos (tanto desde la perspectiva del rendimiento de las consultas como para los usuarios finales). Por ejemplo, tablas de un momento en el tiempo en Data Vault o funciones de tablas especiales en el modelo de ancla.
Total
La esencia principal de las arquitecturas flexibles consideradas es la modularidad de su "diseño".
Es esta propiedad la que permite:
- , ETL, , . ( ) .
- ( ) 2-3 , ( ).
- , - .
- Debido a la descomposición en elementos estándar, los procesos ETL en tales sistemas parecen del mismo tipo, su escritura se presta a la algorítmica y, en última instancia, a la automatización .
El precio de esta flexibilidad es el rendimiento . Esto no significa que sea imposible lograr un rendimiento aceptable en tales modelos. La mayoría de las veces, solo necesita más esfuerzo y atención a los detalles para lograr las métricas que desea.
Aplicaciones
Tipos de entidad de Data Vault

Leer más sobre Data Vault:
el sitio de Dan Listadt
Todo sobre Data Vault en ruso
Acerca de Data Vault en Habré
Tipos de entidad del modelo de ancla

Más información sobre Anchor Model:
Sitio de los creadores de Anchor Model
Un artículo sobre la experiencia de implementar el Anchor Model en Avito
Una tabla resumen con las características comunes y diferencias de los enfoques considerados:
