Entonces, hay dos tipos de bots web: legítimos y maliciosos. Los legítimos incluyen motores de búsqueda, lectores de RSS. Ejemplos de bots web maliciosos son los escáneres de vulnerabilidades, los raspadores, los spammers, los bots de ataque DDoS y los troyanos de fraude con tarjetas de pago. Una vez que se ha identificado el tipo de bot web, se le pueden aplicar varias políticas. Si el bot es legítimo, puede reducir la prioridad de sus solicitudes al servidor o reducir el nivel de acceso a ciertos recursos. Si un bot se identifica como malicioso, puede bloquearlo o enviarlo a la zona de pruebas para un análisis más detallado. Detectar, analizar y clasificar los bots web es importante porque pueden causar daños, por ejemplo, filtrar datos críticos para la empresa. Y también reducirá la carga en el servidor y reducirá el llamado ruido en el tráfico, porque hasta el 66% del tráfico de bots web es exactamentetráfico malicioso .
Enfoques existentes
Existen diferentes técnicas para detectar bots web en el tráfico de la red, que van desde limitar la frecuencia de las solicitudes a un host, poner en una lista negra las direcciones IP, analizar el valor del encabezado HTTP User-Agent, tomar las huellas digitales de un dispositivo y terminar con la implementación de CAPTCHA y el análisis del comportamiento de la actividad de la red utilizando aprendizaje automático.
Pero recopilar información sobre la reputación de un sitio y mantener actualizadas las listas negras utilizando diversas bases de conocimientos e inteligencia de amenazas es un proceso costoso y laborioso, y cuando se utilizan servidores proxy, no es recomendable.
El análisis del campo User-Agent en una primera aproximación puede parecer útil, pero nada impide que el web bot o el usuario cambie los valores de este campo por uno válido, disfrazándose de usuario habitual y utilizando un User-Agent válido para el navegador, o como un bot legítimo. Llamemos a esos imitadores de webbots. El uso de huellas dactilares de varios dispositivos (rastrear el movimiento del mouse o verificar la capacidad del cliente para representar una página HTML) nos permite resaltar los bots web más difíciles de detectar que imitan el comportamiento humano, por ejemplo, solicitando páginas adicionales (archivos de estilo, iconos, etc.), analizando JavaScript. Este enfoque se basa en la inyección de código del lado del cliente, que a menudo es inaceptable, ya que un error al insertar un script adicional puede romper la aplicación web.
Cabe señalar que los web bots también se pueden detectar online: la sesión se evaluará en tiempo real. Una descripción de esta formulación del problema se puede encontrar en Cabri et al. [1], así como en los trabajos de Zi Chu [2]. Otro enfoque es analizar solo después de que finaliza la sesión. La más interesante, obviamente, es la primera opción, que permite tomar decisiones más rápido.
El enfoque propuesto
Usamos técnicas de aprendizaje automático y la pila de tecnología ELK (Elasticsearch Logstash Kibana) para identificar y clasificar los bots web. Los objetos de investigación fueron sesiones HTTP. La sesión es una secuencia de solicitudes de un nodo (valor único de la dirección IP y el campo Usuario-Agente en la solicitud HTTP) en un intervalo de tiempo fijo. Derek y Gohale utilizan un intervalo de 30 minutos para definir los límites de la sesión [3]. Iliu et al. Argumentan que este enfoque no garantiza la singularidad real de la sesión, pero sigue siendo aceptable. Debido al hecho de que el campo User-Agent se puede cambiar, pueden aparecer más sesiones de las que realmente hay. Por lo tanto, Nikiforakis y sus coautores proponen un ajuste más preciso en función de si se admite ActiveX, si Flash está habilitado, resolución de pantalla, versión del sistema operativo.
Consideraremos un error aceptable en la formación de una sesión separada si el campo Usuario-Agente cambia dinámicamente. Y para identificar las sesiones de bot, crearemos un modelo de clasificación binaria claro y usaremos:
- actividad de red automática generada por un bot web (bot de etiquetas);
- actividad de red generada por humanos (etiqueta humana).
Para clasificar los bots web por tipo de actividad, creemos un modelo de clases múltiples a partir de la tabla siguiente.
| Nombre | Descripción | Etiqueta | Ejemplos de |
|---|---|---|---|
| Rastreadores | Bots
web que
recopilan páginas web |
tractor | SemrushBot,
360Spider, Heritrix |
| Redes sociales | Bots web de varias
redes sociales |
red social | LinkedInBot,
bot de
WhatsApp, bot de Facebook |
| Lectores de rss | -,
RSS |
rss | Feedfetcher,
Feed Reader, SimplePie |
| -
|
search_engines | Googlebot, BingBot,
YandexBot |
|
| -,
|
libs_tools | Curl, Wget,
python-requests, scrapy |
|
| - | bots | ||
| ,
User-Agent |
unknown |
También resolveremos el problema del entrenamiento online del modelo.
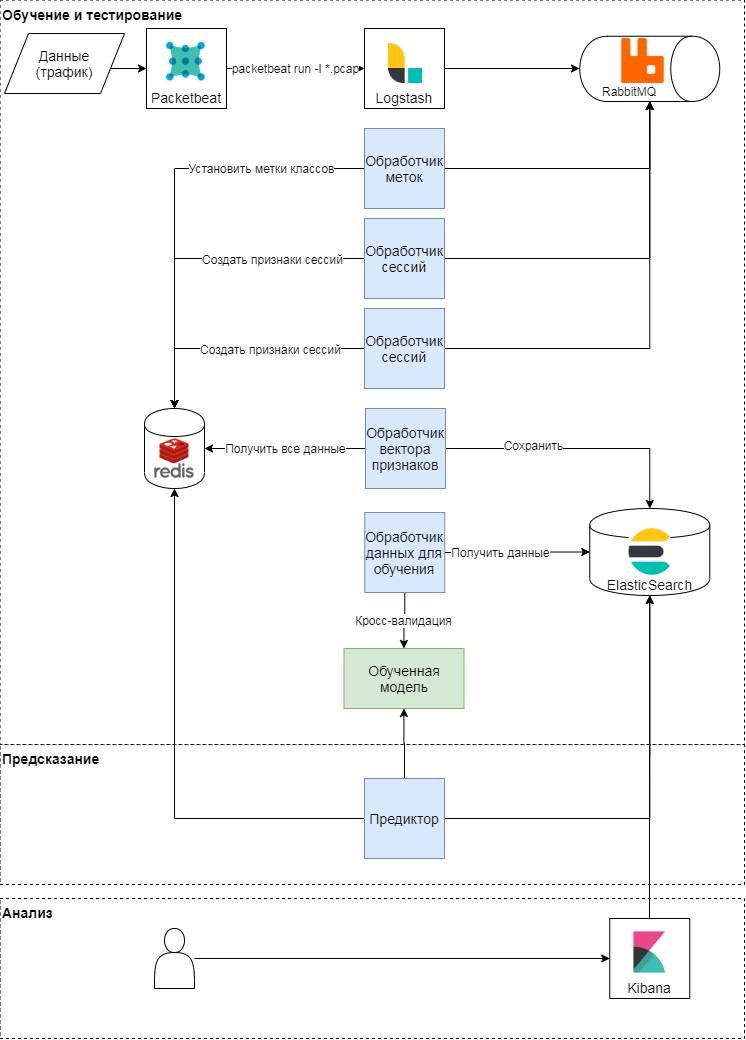
Esquema conceptual del enfoque propuesto
Este enfoque tiene tres etapas: entrenamiento y prueba, predicción, análisis de resultados. Consideremos los dos primeros con más detalle. Conceptualmente, el enfoque sigue el patrón clásico de aprendizaje y aplicación de modelos de aprendizaje automático. Primero, se determinan las métricas de calidad y los atributos para la clasificación. Después de eso, se forma un vector de características y se llevan a cabo una serie de experimentos (varias verificaciones cruzadas) para validar el modelo y seleccionar hiperparámetros. En la última etapa, se selecciona el mejor modelo y se verifica la calidad del modelo en una muestra diferida.
Entrenamiento y prueba de modelos
El módulo packetbeat se utiliza para analizar el tráfico. Las solicitudes HTTP sin procesar se envían a logstash, donde las tareas se generan utilizando un script Ruby en términos de apio. Cada uno de ellos opera con un identificador de sesión, tiempo de solicitud, cuerpo de solicitud y encabezados. Identificador de sesión (clave): el valor de la función hash de la concatenación de la dirección IP y el agente de usuario. En esta etapa, se crean dos tipos de tareas:
- sobre la formación de un vector de características para la sesión,
- etiquetando la clase según el texto de la solicitud y el agente de usuario.
Estas tareas se envían a una cola donde los manejadores de mensajes las ejecutan. Por lo tanto, el manejador de etiquetado realiza la tarea de etiquetar la clase usando el juicio de expertos y datos abiertos del servicio de navegador basado en el Usuario-Agente usado; el resultado se escribe en el almacenamiento de clave-valor. El procesador de sesión genera un vector de características (consulte la tabla a continuación) y escribe el resultado para cada clave en el almacenamiento de clave-valor y también establece la duración de la clave (TTL).
| Firmar | Descripción |
|---|---|
| len | Número de solicitudes por sesión |
| len_pages | Número de solicitudes por sesión en páginas
(URI termina en .htm, .html, .php, .asp, .aspx, .jsp) |
| len_static_request | Número de solicitudes por sesión en
páginas estáticas |
| len_sec | Tiempo de sesión en segundos |
| len_unique_uri | Número de solicitudes por sesión que
contienen un URI único |
| headers_cnt | Número de encabezados por sesión |
| has_cookie | ¿Hay un encabezado de cookie? |
| has_referer | ¿Hay un encabezado Referer? |
| mean_time_page | Tiempo medio por página por sesión |
| mean_time_request | Tiempo promedio por solicitud por sesión |
| mean_headers | Número promedio de encabezados por sesión |
Así es como se forma la matriz de características y se establece la etiqueta de clase de destino para cada sesión. A partir de esta matriz, se produce un entrenamiento periódico de modelos y la posterior selección de hiperparámetros. Para el entrenamiento, usamos: regresión logística, máquina de vectores de soporte, árboles de decisión, aumento de gradiente sobre árboles de decisión, algoritmo de bosque aleatorio. Los resultados más relevantes se obtuvieron mediante el algoritmo de bosque aleatorio.
Predicción
Durante el análisis del tráfico, se actualiza el vector de atributos de sesión en el almacenamiento de valores-clave: cuando aparece una nueva solicitud en la sesión, se recalculan los atributos que la describen. Por ejemplo, el signo del número promedio de encabezados en una sesión (mean_headers) se calcula cada vez que se agrega una nueva solicitud a la sesión. El Predictor envía el vector de características de sesión al modelo y escribe la respuesta del modelo en Elasticsearch para su análisis.
Experimentar
Probamos nuestra solución en el tráfico del portal SecurityLab.ru . Volumen de datos: más de 15 GB, más de 130 horas. El número de sesiones es más de 10,000. Debido al hecho de que el modelo propuesto usa características estadísticas, las sesiones que contenían menos de 10 solicitudes no estuvieron involucradas en la capacitación y las pruebas. Usamos las métricas de calidad clásicas como métricas de calidad: precisión, integridad y medida F para cada clase.
Prueba del modelo de detección de bots web
Construiremos y evaluaremos un modelo de clasificación binaria, es decir, detectaremos bots, y luego los clasificaremos por el tipo de actividad. Con base en los resultados de una validación cruzada estratificada de cinco veces (esto es exactamente lo que se requiere para los datos en consideración, ya que existe un fuerte desequilibrio de clases), podemos decir que el modelo construido es bastante bueno (precisión e integridad - más del 98%) es capaz de separar las clases de usuarios humanos y bots.
| Precisión media | Plenitud media | Medida F media | |
|---|---|---|---|
| larva del moscardón | 0,86 | 0,90 | 0,88 |
| humano | 0,98 | 0,97 | 0,97 |
Los resultados de probar el modelo en una muestra diferida se presentan en la siguiente tabla.
| Exactitud | Lo completo | Medida F | Numero de
ejemplos |
|
|---|---|---|---|---|
| larva del moscardón | 0,88 | 0,90 | 0,89 | 1816 |
| humano | 0,98 | 0,98 | 0,98 | 9071 |
Los valores de las métricas de calidad en el muestreo diferido coinciden aproximadamente con los valores de las métricas de calidad durante la validación del modelo, lo que significa que el modelo sobre estos datos puede generalizar el conocimiento adquirido durante el entrenamiento.
Consideremos los errores del primer tipo. Si estos datos están marcados de manera experta, entonces la matriz de errores cambiará significativamente. Esto significa que se cometieron algunos errores al marcar los datos para el modelo, pero el modelo aún pudo reconocer tales sesiones correctamente.
| Exactitud | Lo completo | Medida F | Numero de
ejemplos |
|
|---|---|---|---|---|
| larva del moscardón | 0,93 | 0,92 | 0,93 | 2446 |
| humano | 0,98 | 0,98 | 0,98 | 8441 |
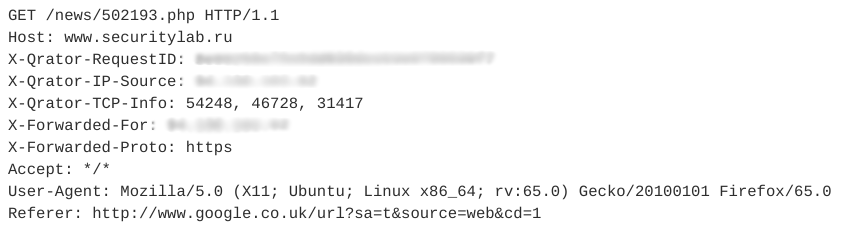
Veamos un ejemplo de imitadores de sesiones. Contiene 12 consultas similares. Una de las solicitudes se muestra en la siguiente figura.
Todas las solicitudes posteriores de esta sesión tienen la misma estructura y solo difieren en el URI.
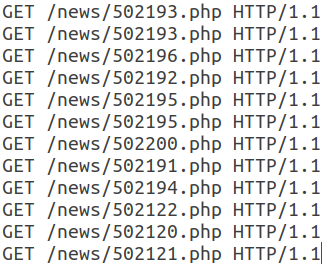
Tenga en cuenta que este webbot usa un User-Agent válido, agrega un campo Referer, que generalmente se usa de manera no automática, y la cantidad de encabezados en una sesión es pequeña. Además, las características temporales de las solicitudes - tiempo de sesión, tiempo medio por solicitud - nos permiten decir que esta actividad es automática y pertenece a la clase de lectores RSS. En este caso, el propio bot se disfraza de usuario normal.
Prueba del modelo de clasificación de bots web
Para clasificar los bots web por tipo de actividad, usaremos los mismos datos y el mismo algoritmo que en el experimento anterior. Los resultados de probar el modelo en una muestra diferida se presentan en la siguiente tabla.
| Exactitud | Lo completo | Medida F | Numero de
ejemplos |
|
|---|---|---|---|---|
| larva del moscardón | 0,82 | 0,81 | 0,82 | 194 |
| tractor | 0,87 | 0,72 | 0,79 | sesenta y cinco |
| libs_tools | 0,27 | 0,17 | 0,21 | Dieciocho |
| rss | 0,95 | 0,97 | 0,96 | 1823 |
| los motores de búsqueda | 0,84 | 0,76 | 0,80 | 228 |
| red social | 0,80 | 0,79 | 0,84 | 73 |
| desconocido | 0,65 | 0,62 | 0,64 | 45 |
La calidad de la categoría libs_tools es baja, pero el volumen insuficiente de ejemplos para evaluación no nos permite hablar sobre la exactitud de los resultados. Debería llevarse a cabo una segunda serie de experimentos para clasificar los bots web en más datos. Podemos decir con confianza que el modelo actual con una precisión e integridad bastante altas es capaz de separar las clases de lectores RSS, motores de búsqueda y bots en general.
Según estos experimentos con los datos considerados, más del 22% de las sesiones (con un volumen total de más de 15 GB) se crean automáticamente, y entre ellas el 87% están relacionadas con la actividad de bots generales, bots desconocidos, lectores RSS, bots web que utilizan diversas bibliotecas y utilidades. ... Por lo tanto, si filtra el tráfico de red de los bots web por el tipo de actividad, el enfoque propuesto reducirá la carga sobre los recursos del servidor utilizados en al menos un 9-10%.
Probar el modelo de clasificación de bots web en línea
La esencia de este experimento es la siguiente: en tiempo real, después de analizar el tráfico, se identifican las características y se forman vectores de características para cada sesión. Periódicamente, cada sesión se envía al modelo para la predicción, cuyos resultados se guardan.
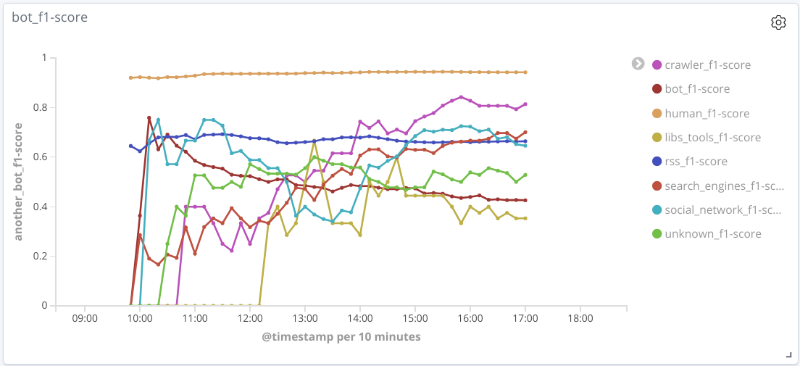
Medida F del modelo a lo largo del tiempo para cada clase Los
gráficos siguientes ilustran el cambio en el valor de las métricas de calidad a lo largo del tiempo para las clases más interesantes. El tamaño de los puntos en ellos está relacionado con el número de sesiones de la muestra en un momento determinado.

Precisión, integridad, medida F para la clase de motores de búsqueda

Precisión, integridad, medida F para la clase de herramientas libs
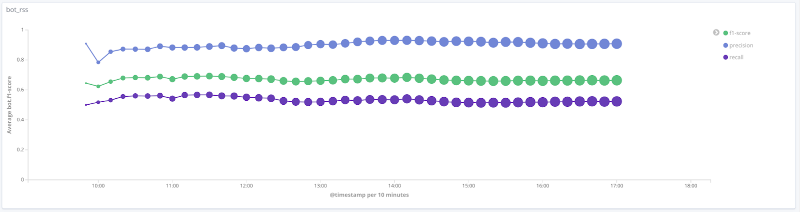
Precisión, integridad, medida F para la clase rss

Precisión, integridad, medida F para la clase de orugas

Precisión, integridad, medida F para clase humana
Para una serie de clases (humano, rss, motores de búsqueda) de los datos en consideración, la calidad del modelo es aceptable (la precisión y la completitud son más del 80%). Para la clase de rastreador, con un aumento en el número de sesiones y un cambio cualitativo en el vector de características para esta muestra, la calidad del rendimiento del modelo aumenta: la completitud aumentó del 33% al 80%. Es imposible sacar conclusiones razonables para la clase libs_tools, ya que el número de ejemplos para esta clase es pequeño (menos de 50); por lo tanto, no se pueden confirmar los resultados negativos (mala calidad).
Principales resultados y desarrollo posterior
Hemos descrito un enfoque para detectar y clasificar bots web mediante algoritmos de aprendizaje automático y funciones estadísticas. Con respecto a los datos en consideración, la precisión e integridad promedio de la solución propuesta para la clasificación binaria es más del 95%, lo que indica que el enfoque es prometedor. Para ciertas clases de bots web, la precisión e integridad promedio es de aproximadamente el 80%.
La validación de los modelos construidos requiere una valoración real de la sesión. Como se mostró anteriormente, el rendimiento del modelo mejora significativamente cuando está disponible el marcado correcto para la clase de destino. Desafortunadamente, ahora es difícil construir automáticamente dicho marcado y debe recurrir a expertos, lo que complica la construcción de modelos de aprendizaje automático, pero le permite encontrar patrones ocultos en los datos.
Para un mayor desarrollo del problema de clasificación y detección de web bots, es recomendable:
- asignar clases adicionales de bots y reentrenar, probar el modelo;
- agregue señales adicionales para clasificar los bots web. Por ejemplo, agregar un atributo de robots.txt, que es binario y es responsable de la presencia o ausencia de acceso a una página de robots.txt, le permite aumentar el puntaje F promedio para una clase de bots web en un 3% sin empeorar otras métricas de calidad para otras clases;
- hacer un marcado más correcto para la clase de destino, teniendo en cuenta las metafunciones adicionales y el juicio de expertos.
Autor : Nikolay Lyfenko, Especialista Líder, Grupo de Tecnologías Avanzadas, Tecnologías Positivas
Fuentes
[1] Cabri A. et al. Online Web Bot Detection Using a Sequential Classification Approach. 2018 IEEE 20th International Conference on High Performance Computing and Communications.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.