
Digo por experiencia personal lo que fue útil, dónde y cuándo. Encuesta y tesis, para que quedara claro qué y dónde profundizar, pero aquí tengo una experiencia personal exclusivamente subjetiva, tal vez todo sea completamente diferente contigo.
¿Por qué es importante conocer y poder manejar lenguajes de consulta? En esencia, la ciencia de datos tiene varias etapas de trabajo muy importantes, y la primera y más importante (sin ella, ¡nada funcionará, por supuesto!) Es la adquisición o recuperación de datos. La mayoría de las veces, los datos de alguna forma se encuentran en algún lugar y es necesario "obtenerlos" desde allí.
Los lenguajes de consulta solo te permiten extraer estos mismos datos. Y hoy les contaré sobre esos lenguajes de consulta que me resultaron útiles y les diré-mostraré dónde y cómo exactamente - por qué es necesario estudiar.
En total, habrá tres bloques principales de tipos de consultas a datos, que analizaremos en este artículo:
- Los lenguajes de consulta "estándar" son lo que normalmente entienden cuando se habla de un lenguaje de consulta como el álgebra relacional o SQL.
- Lenguajes de consulta de secuencias de comandos como pandas python tricks, numpy o shell scripting.
- Lenguajes de consulta para gráficos de conocimiento y bases de datos de gráficos.
Todo lo que está escrito aquí es solo una experiencia personal, que fue útil, con una descripción de situaciones y "por qué era necesario": todos pueden probar cómo situaciones similares pueden conocerte e intentar prepararse para ellas con anticipación, habiendo tratado estos idiomas antes para postularse (urgentemente) en un proyecto o incluso entrar en un proyecto donde se necesiten.
Idiomas de consulta "estándar"
Los lenguajes de consulta estándar son precisamente en el sentido en que solemos pensar en ellos cuando hablamos de consultas.
Álgebra relacional
¿Por qué se necesita hoy el álgebra relacional? Para tener una buena idea de por qué los lenguajes de consulta están organizados de cierta manera y para usarlos deliberadamente, es necesario comprender el núcleo subyacente.
¿Qué es el álgebra relacional?
La definición formal es la siguiente: el álgebra relacional es un sistema cerrado de operaciones sobre relaciones en un modelo de datos relacionales. Más humanamente, este es un sistema de operaciones sobre tablas, de modo que el resultado también es siempre una tabla.
Vea todas las operaciones relacionales en este artículo de Habr: aquí describimos por qué necesita saber y dónde resulta útil.
¿Para qué?
Empieza a comprender para qué se utilizan generalmente los lenguajes de consulta y qué operaciones están detrás de las expresiones de lenguajes de consulta específicos; a menudo, proporciona una comprensión más profunda de qué y cómo funciona en los lenguajes de consulta.
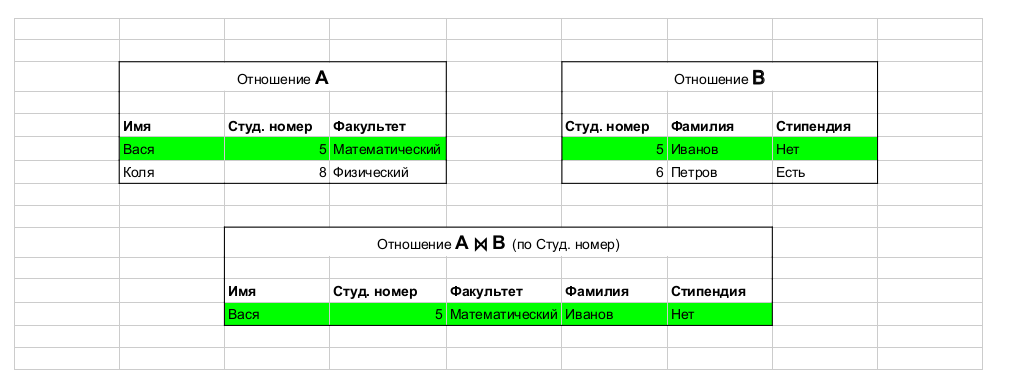
Tomado de este artículo. Ejemplo de operación: unión, que une tablas.
Materiales de estudio:
un buen curso introductorio de Stanford . En general, hay muchos materiales sobre álgebra relacional y teoría: Coursera, Udacity. También hay una gran cantidad de materiales en línea, incluidos buenos cursos académicos . Mi consejo personal es comprender muy bien el álgebra relacional: esta es la base.
SQL

Tomado de este artículo.
SQL es, de hecho, una implementación del álgebra relacional; con una advertencia importante, ¡SQL es declarativo! Es decir, al escribir una consulta en el lenguaje del álgebra relacional, en realidad dices cómo contar, pero con SQL especificas lo que quieres extraer, y luego el DBMS ya genera expresiones (efectivas) en el lenguaje del álgebra relacional (conocemos su equivalencia según el teorema de Codd ) ...
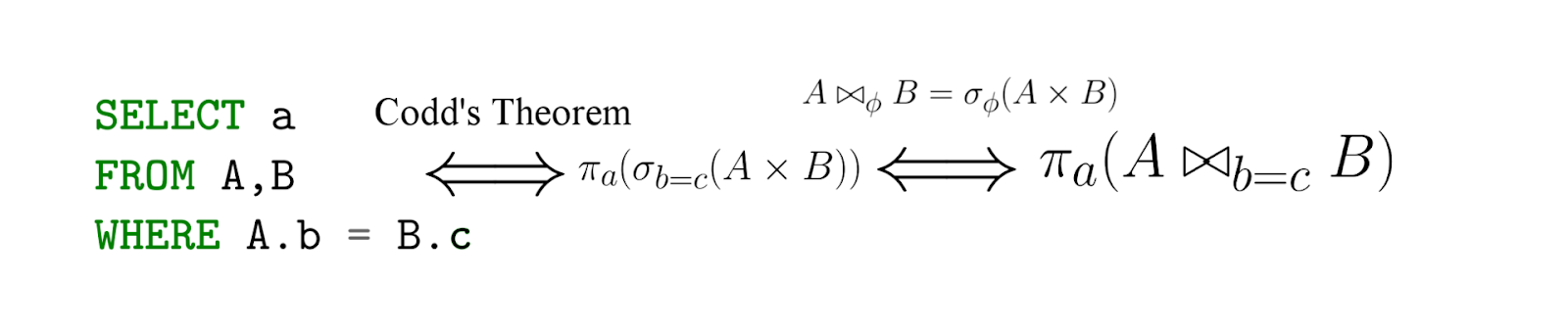
Tomado de este artículo.
¿Para qué?
DBMS relacionales: Oracle, Postgres, SQL Server, etc.están prácticamente por todas partes y existe una probabilidad increíblemente alta de que tenga que interactuar con ellos, lo que significa que tendrá que leer SQL (que es muy probable) o escribir en él ( tampoco es poco probable).
Qué leer y aprender
De los mismos enlaces anteriores (sobre álgebra relacional), hay una cantidad increíble de material, como este .
Por cierto, ¿qué es NoSQL?
"Vale la pena enfatizar una vez más que el término" NoSQL "tiene un origen completamente espontáneo y no tiene una definición universalmente reconocida o una institución científica detrás". El artículo correspondiente sobre Habré.
De hecho, la gente se dio cuenta de que no se necesita un modelo relacional completo para resolver muchos problemas, especialmente para aquellos en los que, por ejemplo, el rendimiento es fundamental y dominan ciertas consultas simples con agregación: es fundamental leer rápidamente las métricas y escribirlas en la base de datos, y la mayoría de las funciones son relacionales. resultó no solo innecesario, sino también dañino: ¿por qué normalizar algo si estropeará lo más importante para nosotros (para alguna tarea específica): el rendimiento?
Además, a menudo se necesitan esquemas flexibles en lugar de esquemas matemáticos fijos del modelo relacional clásico, y esto simplifica increíblemente el desarrollo de aplicaciones, cuando es fundamental implementar el sistema y comenzar a trabajar rápidamente, procesando los resultados, o el esquema y los tipos de datos almacenados no son tan importantes.
Por ejemplo, estamos creando un sistema experto y queremos almacenar información en un dominio determinado junto con algo de metainformación; es posible que no conozcamos todos los campos y es cursi almacenar JSON para cada registro; esto nos brinda un entorno muy flexible para expandir el modelo de datos y una iteración rápida, por lo tanto, en tal el caso de NoSQL sería incluso preferible y legible. Un ejemplo de una entrada (de uno de mis proyectos, donde NoSQL estaba justo donde se necesitaba).
{"en_wikipedia_url":"https://en.wikipedia.org/wiki/Johnny_Cash",
"ru_wikipedia_url":"https://ru.wikipedia.org/wiki/?curid=301643",
"ru_wiki_pagecount":149616,
"entity":[42775," ","ru"],
"en_wiki_pagecount":2338861}
Puede leer más sobre NoSQL aquí .
¿Qué estudiar?
Más bien, solo necesita ser bueno analizando su tarea, qué propiedades tiene y qué sistemas NoSQL están disponibles que se ajusten a esta descripción, y ya estudiar este sistema.
Lenguajes de consulta de secuencias de comandos
Al principio, parece, ¿qué tiene que ver Python con eso? Es un lenguaje de programación y no se trata de consultas en absoluto.

- Pandas es un cuchillo suizo directo de Data Science, en él se lleva a cabo una gran cantidad de transformación, agregación, etc. de datos.
- Numpy es computación vectorial, matrices y álgebra lineal.
- Scipy es una gran cantidad de matemáticas en este paquete, especialmente estadísticas.
- Laboratorio de Jupyter: muchos análisis de datos exploratorios se adaptan bien a las computadoras portátiles, es bueno poder hacerlo.
- Solicitudes - networking.
- Los pysparks son muy populares entre los ingenieros de datos, lo más probable es que necesites interactuar con esto o y chispas, simplemente por su popularidad.
- * El selenio es muy útil para recopilar datos de sitios y recursos, a veces simplemente no hay otra forma de obtener los datos.
Mi principal consejo: ¡aprende Python!
Pandas
Tomemos el siguiente código como ejemplo:
import pandas as pd
df = pd.read_csv(“data/dataset.csv”)
# Calculate and rename aggregations
all_together = (df[df[‘trip_type’] == “return”]
.groupby(['start_station_name','end_station_name'])\
.agg({'trip_duration_seconds': [np.size, np.mean, np.min, np.max]})\
.rename(columns={'size': 'num_trips',
'mean': 'avg_duration_seconds',
'amin': min_duration_seconds',
‘amax': 'max_duration_seconds'}))De hecho, podemos ver que el código encaja en el patrón SQL clásico.
SELECT start_station_name, end_station_name, count(trip_duration_seconds) as size, …..
FROM dataset
WHERE trip_type = ‘return’
GROUPBY start_station_name, end_station_namePero la parte importante es que este código es parte del script y de la canalización; de hecho, estamos incorporando solicitudes en la canalización de Python. En esta situación, el lenguaje de consulta nos llega de bibliotecas como Pandas o pySpark.
En general, en pySpark vemos un tipo similar de transformación de datos a través del lenguaje de consulta en el espíritu de:
df.filter(df.trip_type = “return”)\
.groupby(“day”)\
.agg({duration: 'mean'})\
.sort()Dónde y qué leer
No es un problema encontrar materiales para estudiar en Python en sí . Hay una gran cantidad de tutoriales sobre pandas , pySpark y cursos sobre Spark (así como sobre DS ) en la red . En general, los materiales aquí están magníficamente buscados en Google y si tuviera que elegir un paquete en el que concentrarme, sería pandas, por supuesto. También hay muchos materiales en el paquete DS + Python .
Shell como lenguaje de consulta
Muchos de los proyectos de análisis y procesamiento de datos con los que he trabajado son, de hecho, scripts de shell que llaman al código en Python, en Java y a los propios comandos de shell. Por lo tanto, en general, puede considerar las canalizaciones en bash / zsh / etc, como una solicitud de alto nivel (puede, por supuesto, insertar bucles allí, pero esto no es típico para el código DS en lenguajes shell), démos un ejemplo simple: necesitaba mapear el QID de la wikidata y un enlace completo a la wiki en ruso e inglés, para esto escribí una consulta simple de los comandos en el bash y para la salida escribí un script simple en Python, que armé así:
pv “data/latest-all.json.gz” |
unpigz -c |
jq --stream $JQ_QUERY |
python3 scripts/post_process.py "output.csv"
Dónde
JQ_QUERY = 'select((.[0][1] == "sitelinks" and (.[0][2]=="enwiki" or .[0][2] =="ruwiki") and .[0][3] =="title") or .[0][1] == "id")' Esta fue, de hecho, toda la tubería que creó el mapeo necesario, como vemos todo, funcionó en modo de flujo:
- pv filepath: proporciona una barra de progreso basada en el tamaño del archivo y pasa su contenido
- unpigz -c leyó parte del archivo y le dio a jq
- jq con la clave: el flujo produjo inmediatamente el resultado y lo pasó al postprocesador (como en el primer ejemplo) en Python
- internamente, el postprocesador es una máquina de estado simple que formatea la salida
En total, un pipeline complejo que trabaja en modo de flujo en big data (0,5 TB), sin recursos importantes y compuesto por un pipeline simple y un par de herramientas.
Otro consejo importante: sé bueno y eficiente en la terminal y escribe en bash / zsh / etc.¿Dónde es útil? Sí, casi en todas partes; nuevamente, hay MUCHOS materiales para estudiar en la red. En particular, este es mi artículo anterior.
Secuencias de comandos R
Una vez más, el lector puede exclamar: bueno, ¡este es un lenguaje de programación completo! Y por supuesto que tendrá razón. Sin embargo, normalmente tenía que tratar con R siempre en un contexto que, de hecho, era muy similar a un lenguaje de consulta.
R es un marco de computación estadística y un lenguaje de visualización y computación estática (de acuerdo con esto ).
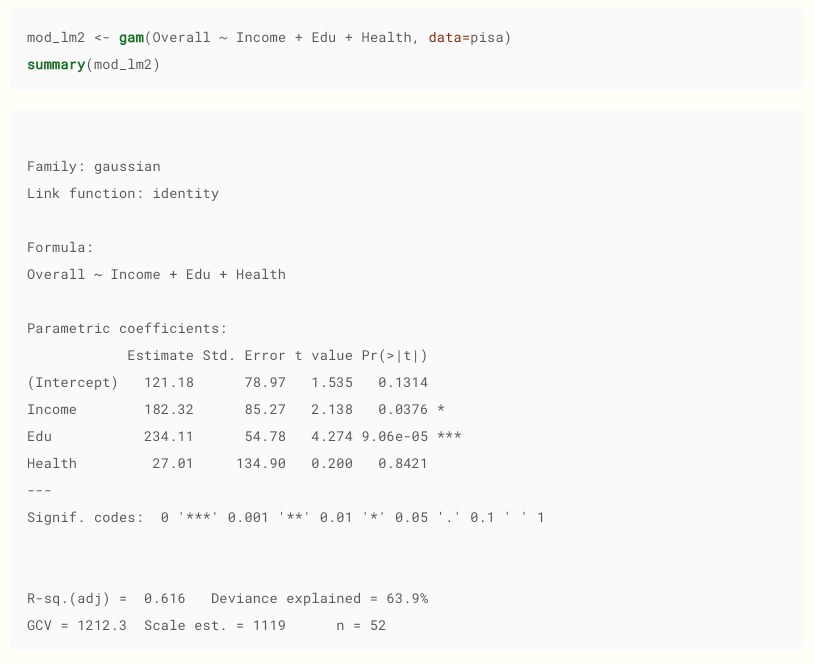
Tomado de aquí . Por cierto, recomiendo, buen material.
¿Por qué salir con un científico para conocer R? Al menos, porque hay una gran capa de personas que no son de TI que se dedican al análisis de datos en R. Me he reunido en los siguientes lugares:
- Sector farmacéutico.
- Biólogos.
- Sector financiero.
- Personas con una educación puramente matemática, que se ocupan de las estadísticas.
- Modelos de aprendizaje automático y estadísticos especializados (que a menudo solo se pueden encontrar en la versión ascendente como paquete R).
¿Por qué es en realidad un lenguaje de consulta? En la forma en que se encuentra a menudo, en realidad es una solicitud para crear un modelo, incluida la lectura de datos y la corrección de parámetros de consulta (modelo), así como la visualización de datos en paquetes como ggplot2; esta es también una forma de escribir consultas.
Ejemplo de consultas para renderizar
ggplot(data = beav,
aes(x = id, y = temp,
group = activ, color = activ)) +
geom_line() +
geom_point() +
scale_color_manual(values = c("red", "blue"))En general, muchas ideas de R han migrado a paquetes de Python como pandas, numpy o scipy, como dataframes y vectorización de datos; por lo tanto, en general, muchas cosas en R le resultarán familiares y convenientes.
Hay muchas fuentes para estudiar, por ejemplo, esta .
Gráfico de conocimiento
Aquí tengo una experiencia un poco inusual, porque todavía tengo que trabajar con bastante frecuencia con gráficos de conocimiento y lenguajes de consulta para gráficos. Por lo tanto, repasemos brevemente los conceptos básicos, ya que esta parte es un poco más exótica.
En las bases de datos relacionales clásicas tenemos un esquema fijo - aquí el esquema es flexible, cada predicado es en realidad una "columna" y aún más.
Imagina que modelarías a una persona y te gustaría describir cosas clave, por ejemplo, tomemos a una persona específica de Douglas Adams, tomemos esta descripción como base.
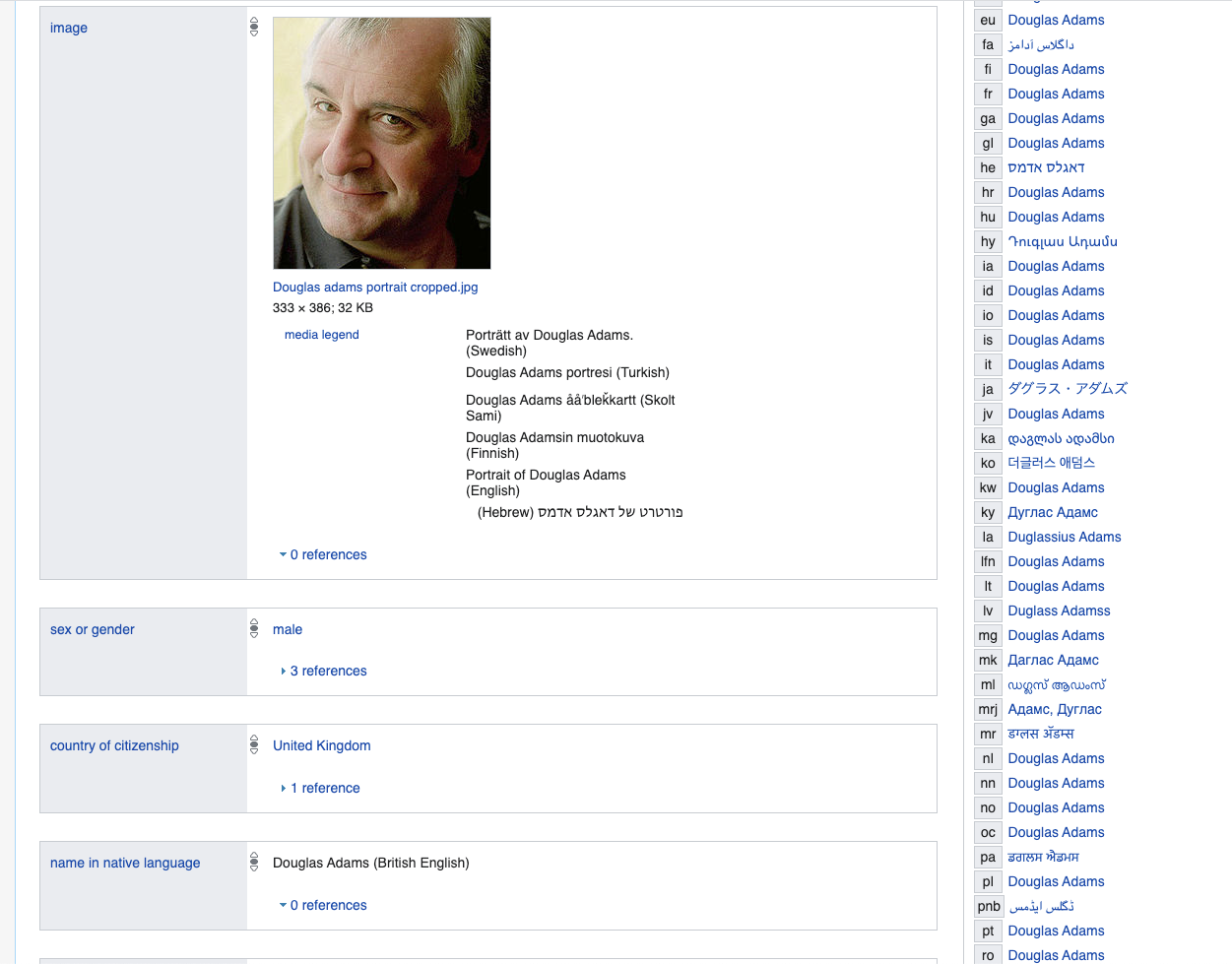
www.wikidata.org/wiki/Q42
Si estuviéramos usando una base de datos relacional, tendríamos que crear una o varias tablas enormes con una gran cantidad de columnas, la mayoría de las cuales serían NULL o se llenarían con algún valor False predeterminado, por ejemplo, poco probable muchos de nosotros tenemos una entrada en la biblioteca nacional coreana; por supuesto, podríamos ponerlas en tablas separadas, pero eso sería en última instancia un intento de modelar la lógica flexible con predicados usando una relacional fija.
Por lo tanto, imagine que todos los datos se almacenan como un gráfico o como expresiones lógicas binarias y unarias.
¿Dónde puedes encontrarte con esto? Primero, trabajar con datos wiki y con cualquier base de datos de gráficos o datos conectados.
Los siguientes son los principales lenguajes de consulta que he usado y con los que he trabajado.
SPARQL
Wiki:
SPARQL ( . SPARQL Protocol and RDF Query Language) — , RDF, . SPARQL W3C .
Pero en realidad es un lenguaje de consultas a predicados lógicos unarios y binarios. Solo está indicando condicionalmente lo que está fijo en una expresión booleana y lo que no (muy simplista).
La base RDF (Resource Description Framework) en sí, sobre la cual se ejecutan las consultas SPARQL, es un triplete
object, predicate, subject, y la consulta selecciona los tripletes necesarios de acuerdo con las restricciones especificadas en el espíritu de: encuentre una X tal que p_55 (X, q_33) sea verdadero, donde, por supuesto, p_55 es lo que -esa relación con ID 55, y q_33 es un objeto con ID 33 (esa es toda la historia, de nuevo omitiendo todo tipo de detalles).
Ejemplo de presentación de datos:
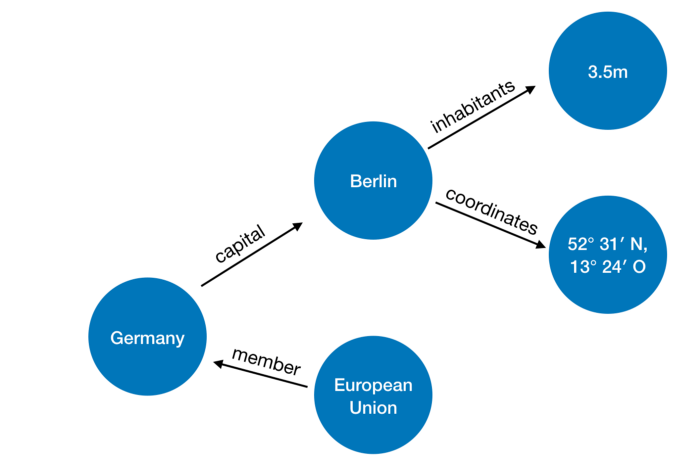
Las imágenes y un ejemplo con países son de aquí .
Ejemplo de consulta básica

De hecho, queremos encontrar el valor de la variable? País, de modo que para el predicado
member_of, es cierto que member_of (? País, q458) y q458 es el ID de la Unión Europea.
Un ejemplo de una consulta SPARQL real dentro del motor de Python:
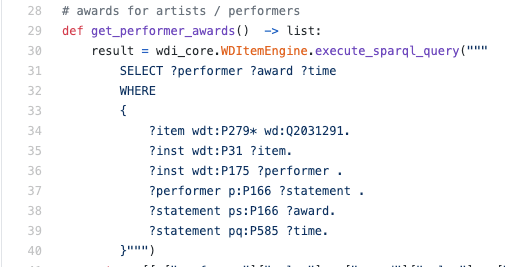
Como regla general, tenía que leer SPARQL, no escribir; en tal situación, lo más probable es que sea una habilidad útil comprender el idioma al menos en un nivel básico para comprender exactamente cómo se recuperan los datos.
Hay mucho material de estudio en línea, como este y este . Yo mismo suelo buscar en Google construcciones y ejemplos específicos, y hasta ahora tengo suficientes.
Lenguajes de consulta lógica
Puedes leer más sobre el tema en mi artículo aquí . Aquí, discutiremos brevemente por qué los lenguajes lógicos son adecuados para escribir consultas. De hecho, RDF es solo una colección de declaraciones lógicas de la forma p (X) y h (X, Y), y una consulta lógica se ve así:
output(X) :- country(X), member_of(X,“EU”).
Aquí estamos hablando de crear una nueva salida de predicado / 1 (/ 1 significa unario), cuando siempre que sea cierto para X ese país (X), es decir, X es el país y también miembro_de (X, “UE”).
Es decir, tenemos tanto los datos como las reglas en este caso generalmente se presentan de la misma manera, lo que hace muy fácil y bueno modelar tareas.
¿Dónde te conociste en la industria?: todo un gran proyecto con una empresa que escribe consultas en ese lenguaje, así como sobre el proyecto actual en el núcleo del sistema; parecería algo bastante exótico, pero a veces ocurre.
Un ejemplo de un fragmento de código en lenguaje lógico que procesa wikidata:
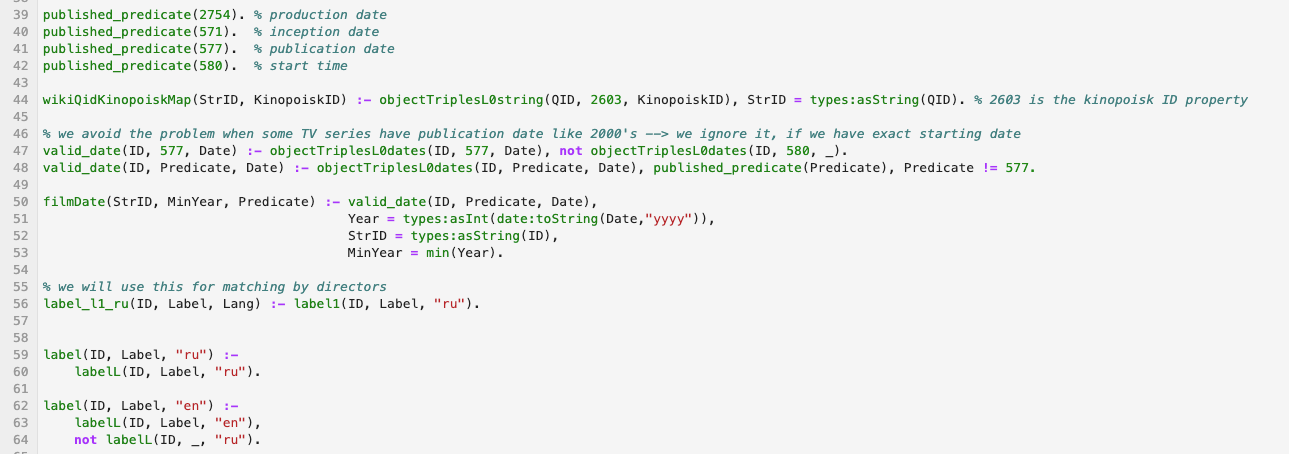
Materiales: Daré aquí un par de enlaces al lenguaje de programación lógico moderno Programación de conjuntos de respuestas; recomiendo estudiarlo:
- http://peace.eas.asu.edu/aaai12tutorial/asp-tutorial-aaai.pdf
- http://ceur-ws.org/Vol-1145/tutorial1.pdf
- https://www.youtube.com/watch?v=gVQ0bP8zyHw
- https://www.youtube.com/watch?v=kdcd7Je2glc
- https://potassco.org/book/
- http://potassco.sourceforge.net/teaching.html
- https://www.cs.uni-potsdam.de/~torsten/Potassco/Tutorials/fmcad12.pdf
