Para las empresas que necesitan administrar datos y aplicaciones en más de un servidor, la infraestructura es primordial.
Para todas las empresas, una parte importante del flujo de trabajo consiste en monitorear los nodos de infraestructura, especialmente en ausencia de acceso directo para resolver problemas emergentes. Además, el uso intensivo de algunos recursos puede ser un indicador de fallas y sobrecargas de infraestructura. Sin embargo, el monitoreo puede usarse no solo para la prevención, sino también para evaluar las posibles consecuencias del uso de nuevo software en producción. Actualmente, existen varias soluciones listas para usar en el mercado para rastrear el consumo de recursos, pero, sin embargo, plantean dos problemas clave: el alto costo de instalación y configuración y los problemas de seguridad asociados con el software de terceros.
La primera cuestión es la cuestión del precio: el coste puede oscilar entre diez euros (tarifas al consumidor) y varios miles (tarifas corporativas) al mes, dependiendo del número de hosts a monitorizar. Por ejemplo, digamos que quiero monitorear tres nodos durante un año. A un precio de 10 euros al mes, gastaré 120 euros, mientras que una pequeña empresa tendrá que desembolsar de diez a veinte mil, lo que resultará una decisión económicamente insostenible y simplemente socavará todo el presupuesto.
El segundo problema es el software de terceros. Dado que para el análisis, los datos del usuario, ya sea un particular o una empresa, deben ser procesados por un tercero, surge la pregunta: ¿cómo el tercero recopila los datos y se los presenta al usuario? Por lo general, para esto, se instala una aplicación especial en el nodo, a través de la cual se realiza el monitoreo, pero muchas veces dichas aplicaciones tienen tiempo de quedar desactualizadas o resultar incompatibles con el sistema operativo del cliente. La experiencia de los investigadores en el campo de la seguridad de la información arroja luz sobre los problemas de trabajar con " software propietario ". ¿Confiaría en ese software? Yo no.
Tengo mis nodos tanto para Tor como para algunas criptomonedasasí que prefiero las alternativas de monitoreo gratuitas, de código abierto y fácilmente personalizables. En esta publicación, veremos tres de estas herramientas: Grafana, InfluxBD y CollectD.

Vigilancia
Para analizar con eficacia cada métrica de nuestra infraestructura, necesitamos una aplicación que pueda recoger estadísticas de los dispositivos que nos interesan. En este sentido, CollectD viene al rescate : este demonio agrupa y recopila ("recopila", por lo tanto, ese nombre) todos los parámetros que se pueden almacenar en el disco o transmitir a través de la red.
Luego, los datos se transferirán a la instancia de InfluxDB : esta es una base de datos de series de tiempo (TSBD) que asocia los datos con la hora (marca de tiempo codificada en UNIX) en la que el servidor los recibió. Por lo tanto, los datos enviados por CollectD llegarán como una secuencia de eventos.
Finalmente, usaremos Grafana: Este programa se conectará a InfluxDB y mostrará los datos en paneles coloridos y fáciles de usar. Gracias a todo tipo de gráficos e histogramas, podremos rastrear los datos de la CPU, RAM, etc. en tiempo real.

InfluxDB

Comencemos con InfluxDB, un TSBD gratuito para almacenar datos como una secuencia de eventos. Esta base de datos desarrollada por Go será el corazón de nuestro "sistema" de monitoreo.
Siempre que llegan datos, una etiqueta UNIX está vinculada a ellos de forma predeterminada . La flexibilidad de este enfoque libera al usuario de tener que almacenar la variable "tiempo", que de otro modo es bastante complicado. Imaginemos que tenemos varios dispositivos ubicados en diferentes continentes. ¿Cómo manejamos la variable "tiempo"? ¿Vamos a vincular todos los datos a la hora media de Greenwich?, ¿o le daremos a cada nodo su propia zona horaria? Si los datos se almacenan en diferentes zonas horarias, ¿cómo podemos mostrarlos correctamente en los gráficos? Como puede ver, los problemas surgen uno tras otro.
Dado que InfluxDB realiza un seguimiento del tiempo y etiqueta automáticamente cada llegada de datos, puede escribir datos sincrónicamente en una base de datos específica. Es por eso que InfluxDB a menudo se representa como una línea de tiempo: escribir datos no afecta el rendimiento de la base de datos (lo que a veces sucede con MySQL), ya que escribir es solo agregar un evento específico a la línea de tiempo. Por lo tanto, el nombre del programa proviene de la percepción del tiempo como una "corriente" interminable e ilimitada.
Instalacion y configuracion
Otra ventaja de InfluxDB es su facilidad de instalación y la extensa documentación proporcionada por la comunidad del proyecto, que lo respalda ampliamente . InfluxDB tiene dos tipos de interfaz: la línea de comandos (una herramienta útil para desarrolladores, pero mal preparada para trabajar con grandes cantidades de datos) y la API HTTP para la interacción directa con la base de datos.
Puede descargar InfluxDB no solo desde el sitio oficial, sino también a través del sistema de administración de paquetes (lo demostraremos a través de Debian). Además, se recomienda verificar los paquetes a través de GPG antes de instalar, por lo que a continuación importamos las claves del paquete InfluxDB:
root@node#~: curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
root@node#~: source /etc/os-release
root@node#~: echo "deb https://repos.influxdata.com/debian $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/influxdb.listFinalmente, actualizaremos e instalaremos InfluxDB:
root@node#~: apt-get update
root@node#~: apt-get install influxdbPara ejecutar usaremos
systemctl:
root@node#~: service start influxdb Para evitar que alguien con malas intenciones acceda a nosotros, crearemos un usuario llamado "administrador". Puede interactuar con la base de datos a través del lenguaje de consulta tipo SQL de InfluxDB " InfluxQL ". Para crear un nuevo usuario, ejecutaremos una solicitud
create user.
root@node#~: influx
Connected to http://localhost:8086
InfluxDB shell version: x.y.z
>
> CREATE USER admin WITH PASSWORD 'MYPASSISCOOL' WITH ALL PRIVILEGESEn la misma interfaz CLI, crearemos una base de datos "métricas", en la que almacenaremos nuestras métricas.
> CREATE DATABASE metricsA continuación, configuraremos InfluxBD (
/etc/influxdb/influxdb.conf) para abrir la interfaz en el puerto 24589 (UDP) con una conexión directa a la base de datos de "métricas" para admitir CollectD. También necesitaremos descargar el archivo types.dby colocarlo en la dirección /usr/share/collectd/(o en cualquier otra carpeta) para determinar correctamente los datos que transmite CollectD en su formato nativo .
root@node#~: nano /etc/influxdb/influxdb.conf
[Collectd]
enabled = true
bind-address = ":24589"
database = "metrics"
typesdb = "/usr/share/collectd/types.db"Puede leer más sobre CollectD en configuración en la documentación .
CollectD

CollectD en nuestra infraestructura de monitoreo actuará como un agregador de datos que simplifica la transferencia de datos a InfluxDB. Por definición, CollectD recopila métricas de CPU, RAM, discos duros, interfaces de red, procesos ... El potencial de este programa es ilimitado, especialmente si se tiene en cuenta la amplia gama de complementos ya disponibles , así como un conjunto planificado .
Como puede ver, instalar CollectD es simple:
root@node#~: apt-get install collectd collectd-utilsIlustremos cómo funciona CollectD con un ejemplo simplificado. Digamos que quiero saber la cantidad de procesos en mi nodo. Para comprobar esto, CollectD realizará una llamada a la API para averiguar el número de procesos por unidad de tiempo (5000 milisegundos por definición) y nada más. Tan pronto como el agregador reciba los datos, los transferirá a InfluxDB para su configuración a través de un módulo (denominado "Red"), que necesitaremos configurar.
Abra el archivo con nuestro editor
/etc/collectd.conf, desplácese hasta la sección Networky edítelo como se indica a continuación. Asegúrese de especificar la IP donde se encuentra la interfaz InfluxDB ( INFLUXDB_IP).
root@node#~: nano /etc/collectd.conf
...
<Plugin network>
<Server "INFLUXDB_IP" "24589">
</Server>
ReportStats true
</Plugin>
...
Sugiero cambiar el nombre de host en el archivo de configuración que se reenvía a InfluxDB (en nuestra infraestructura, esta es una base de datos "centralizada" ya que está ubicada en el mismo nodo). Así, no recibiremos datos innecesarios y desaparecerá el riesgo de que otros nodos sobrescriban los datos.

Grafana

Un gráfico vale mil imágenes
Considerando la cotización parafraseada, la observación de métricas de infraestructura en tiempo real a través de gráficos y tablas nos permite actuar de manera eficiente y oportuna. Usaremos Grafana para crear y personalizar el tablero de nuestros gráficos y tablas.
Grafana es una herramienta gratuita de métricas gráficas, compatible con una amplia gama de bases de datos (incluida InfluxDB), en la que el usuario puede crear alertas cuando un dato cumple una condición específica. Por ejemplo, si su CPU está en su punto máximo, puede recibir una alerta en Slack, Mattermost, correo electrónico, etc. Además, configuré mis alertas para monitorear activamente cada caso cuando alguien "ingresa" a mi infraestructura.
Grafana no requiere ninguna configuración especial: como mencionamos anteriormente, InfluxDB "escanea" la variable "tiempo". La integración en sí es muy simple: comenzaremos importando la clave pública para agregar el paquete desde el sitio web oficial de Grafana (depende de su sistema operativo):
root@node#~: wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
root@node#~: echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
root@node#~: apt-get update && apt-get install grafanaEntonces ejecutémoslo a través de systemctl:
root@node#~: systemctl start grafana-webAhora, cuando vayamos a la página localhost: 3000 en el navegador, deberíamos ver la interfaz de inicio de sesión de Grafana. Por definición, se puede pasar por el inicio de sesión de administrador y una contraseña de administrador (después de las primeras credenciales de acceso se recomienda cambiar).

Vayamos a la sección de Fuentes y agreguemos nuestra base de datos de Influx allí:


Ahora vemos un pequeño rectángulo verde debajo de la etiqueta Nuevo Tablero. Pase el cursor sobre él y seleccione Agregar panel y luego Gráfico:

ahora puede ver un gráfico con datos de prueba. Haga clic en el título de este diagrama y haga clic en Editar. Con Grafana, puede crear consultas inteligentes: no necesita conocer todos los campos de la base de datos, Grafana se los ofrecerá a partir de una lista de parámetros adecuados para el análisis.
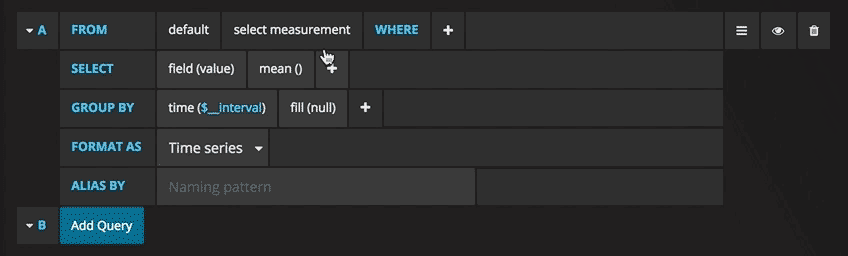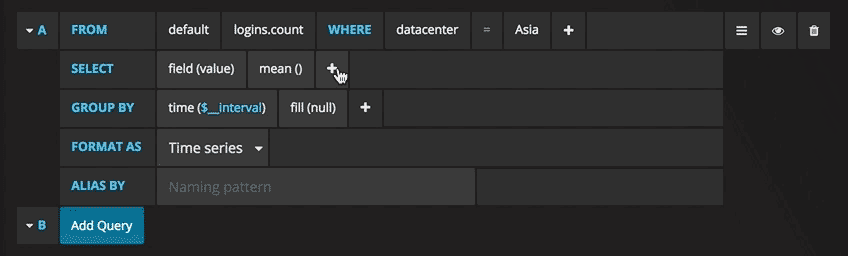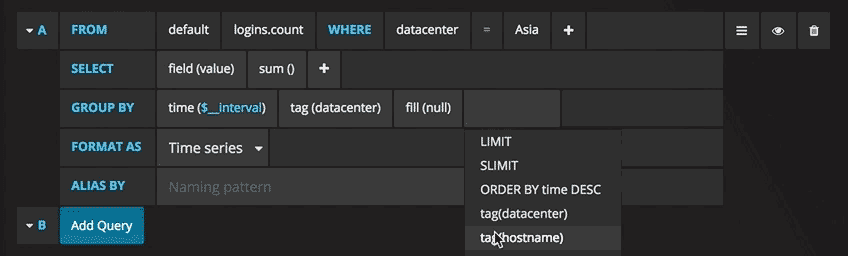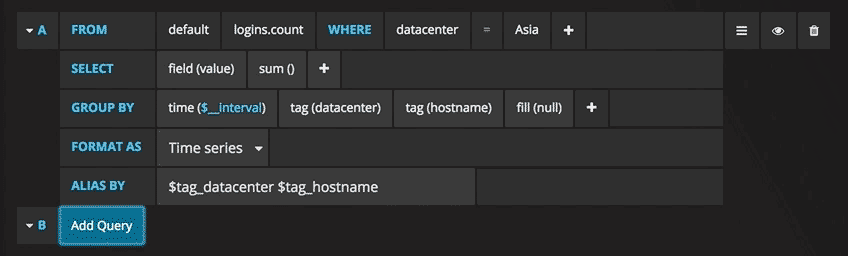
Escribir consultas nunca ha sido tan fácil: simplemente seleccione la métrica que le interesa y haga clic en Actualizar. También recomiendo dividir las métricas por host para que sea más fácil aislar los problemas. Si está interesado en otras ideas de paneles de control, puede visitar el sitio de Grafana para obtener todo tipo de ejemplos para inspirarse.
Notamos que Grafana es una herramienta muy extensible y nos permite comparar datos que son muy diferentes entre sí. No hay una sola métrica que no se pueda obtener, por lo que solo tu ingenio te limita. ¡Realice un seguimiento de sus dispositivos y obtenga la descripción general más completa de su infraestructura en tiempo real!
