Este no es un análisis sistemático o una tabla. Una mirada individual, también desde el punto de vista de un geofísico. Pero siempre tengo curiosidad por leer Gartner MQ, formulan algunos puntos a la perfección. Así que aquí están las cosas a las que presté atención en términos técnicos, de mercado y filosóficos.
Esto no es para personas que están profundamente en ML, sino para personas que están interesadas en lo que generalmente sucede en el mercado.
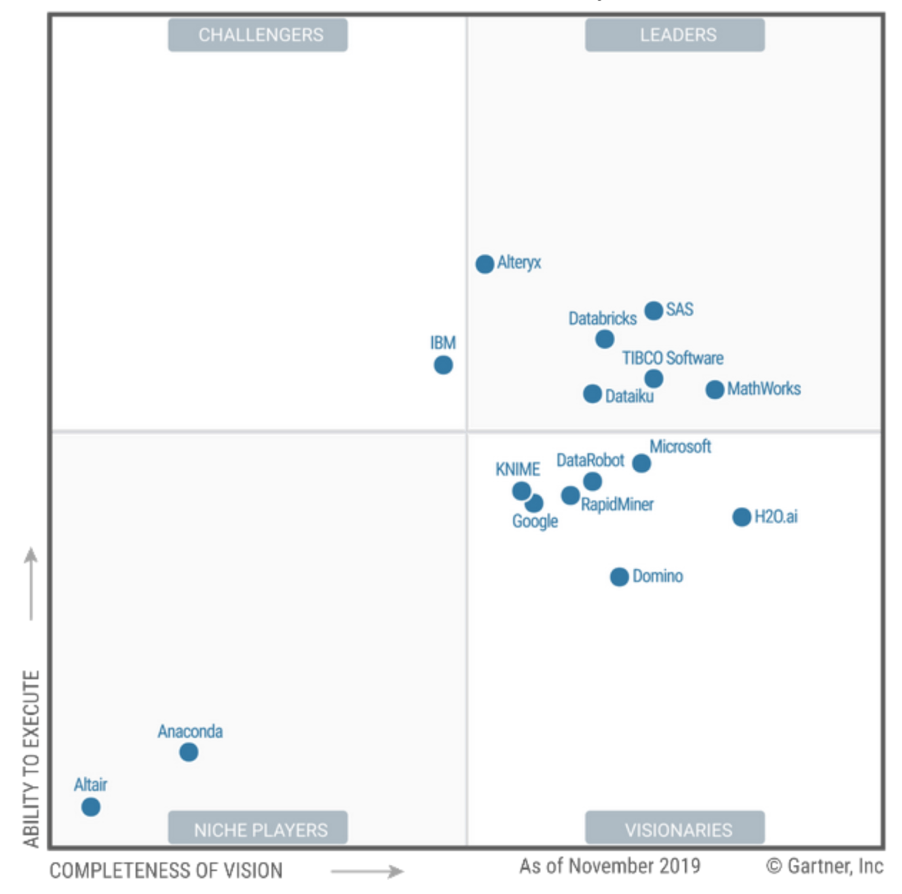
El mercado de DSML en sí mismo se anida lógicamente entre los servicios de desarrollo de BI y Cloud AI.
Primeras citas y términos que me gustaron:
- “Un líder puede no ser la mejor opción” : el líder del mercado no es necesariamente lo que necesita. ¡Muy urgente! Como consecuencia de la falta de un cliente funcional, siempre buscan la "mejor" solución, no la "adecuada".
- La operacionalización del modelo se abrevia como MOP. ¡Y los pugs son difíciles para todos! - (El tema pug genial hace que el modelo funcione).
- El entorno portátil es un concepto importante en el que se combinan código, comentarios, datos y resultados. Esto es muy claro, prometedor y puede reducir significativamente la cantidad de código de IU.
- «Rooted in OpenSource» — – .
- «Citizen Data Scientists» — , , , . .
- «Democratise» — “ ”. «democratise the data» «free the data», . «Democratise» — long tail . — !
- «Exploratory Data Analysis – EDA» — . . . , . ,
- "Reproducibilidad" - máxima conservación de todos los parámetros del entorno, entradas y salidas, para que pueda repetir el experimento una vez realizado. ¡El término más importante para un entorno de prueba experimental!
Entonces:
Alteryx
La interfaz genial es solo un juguete. La escalabilidad, por supuesto, es un poco ajustada. En consecuencia, la comunidad ciudadana de ingenieros en torno a lo mismo con tsatski para jugar. Analytics tiene su propio todo en una botella. Me recordó a la Coscad espectral de correlación Análisis de Datos de baño que fue programado en los años 90.
Anaconda
Una comunidad alrededor de expertos en Python y R. El código abierto es grande, respectivamente. Resultó que mis colegas están usando constantemente. No lo sabía.
DataBricks
Consiste en tres proyectos de código abierto: los desarrolladores de Spark han recaudado una gran cantidad de dinero desde 2013. Tengo que leer la wiki:
“En septiembre de 2013, Databricks anunció que había recaudado 13,9 millones de dólares de Andreessen Horowitz. La compañía recaudó $ 33 millones adicionales en 2014, $ 60 millones en 2016, $ 140 millones en 2017, $ 250 millones en 2019 (febrero) y $ 400 millones en 2019 (octubre) ”!!!Algunas grandes personas que Spark cortó. No es familiar, lo siento!
Y los proyectos son:
- Delta Lake - ACID on Spark fue lanzado recientemente (lo que soñamos con Elasticsearch) - lo convierte en una base de datos: un esquema rígido, ACID, auditoría, versiones ...
- ML Flow : seguimiento, empaquetado, administración y almacenamiento de modelos.
- Koalas - Pandas DataFrame API en Spark - Pandas - API de Python para trabajar con tablas y datos en general.
Puedes ver sobre Spark, que de repente no sabe o ha olvidado: enlace . Vidosiki buscó ejemplos de pájaros carpinteros consultores un poco aburridos pero detallados: DataBricks para Data Science ( enlace ) y para Data Engineering ( enlace ).
En resumen, Databricks saca Spark. Quien quiera usar Spark normalmente en la nube toma DataBricks sin dudarlo, como se pretendía :) Spark es el principal diferenciador aquí.
Descubrí que Spark Streaming no es un microbatching o en tiempo real falso. Y si necesita tiempo real real, es en Apache STORM. Aún así, todo el mundo dice y escribe que Spark es más genial que MapReduce. El lema es este.
DATAIKU
Genial cosa de principio a fin. Hay mucha publicidad. ¿No entiendes en qué se diferencia de Alteryx?
DataRobot
Paxata para preparar datos es genial es una empresa separada que fue comprada por Data Robots en diciembre de 2019. Recaudó 20 MUSD y vendió. Todo en 7 años.
Preparando datos en Paxata, no en Excel - ver aquí: enlace .
Hay falsificaciones automáticas y propuestas de unión entre dos conjuntos de datos. Una gran cosa: para ordenar los datos, incluso más énfasis en la información de texto ( enlace ).
El Catálogo de datos es un gran catálogo de conjuntos de datos "en vivo" que nadie necesita.
También es interesante cómo se forman los directorios en Paxata ( enlace ).
«According to analyst firm Ovum, the software is made possible through advances in predictive analytics, machine learning and the NoSQL data caching methodology.[15] The software uses semantic algorithms to understand the meaning of a data table's columns and pattern recognition algorithms to find potential duplicates in a data-set.[15][7] It also uses indexing, text pattern recognition and other technologies traditionally found in social media and search software.»
El producto principal de Data Robot está aquí . ¡Su lema es de modelo a aplicación corporativa! Consultoría descubierta para la industria petrolera en relación con la crisis, pero muy banal y poco interesante: enlace . Vi sus videos en Mops o MLops ( enlace ). Este es un Frankenstein compuesto por 6-7 adquisiciones de varios productos.
Por supuesto, queda claro que un gran equipo de científicos de datos debe tener ese entorno para trabajar con modelos, de lo contrario producirán muchos de ellos y nunca implementarán nada. Y en nuestra realidad upstream de petróleo y gas, ¡un modelo podría crearse con éxito y esto ya es un gran progreso!
El proceso en sí recuerda mucho al trabajo de diseño de sistemas en geología-geofísica, por ejemplo, Petrel... Todos y cada uno hacen y modifican modelos. Recopile datos en el modelo. Luego hicieron un modelo de referencia y lo pusieron en producción. Hay muchas similitudes entre, digamos, un modelo geológico y un modelo ML.
dominó
Énfasis en plataforma abierta y colaboración. Los usuarios comerciales pueden ingresar de forma gratuita. Su Data Lab se parece mucho a un Sharepoint. (Y desde el nombre da con fuerza IBM). Todos los experimentos están vinculados al conjunto de datos original. Qué familiar es :) Como en nuestra práctica, algunos datos se arrastraron al modelo, luego se limpiaron y se pusieron en orden en el modelo, y todo esto ya vive allí en el modelo y no se pueden encontrar los extremos en los datos iniciales.
Domino tiene una virtualización de infraestructura genial. Recogí la máquina cuántos núcleos por segundo y fui a contar. Cómo se hizo no está del todo claro de inmediato. Docker en todas partes. ¡Mucha libertad! Se pueden conectar todos los espacios de trabajo de las últimas versiones. Ejecución de experimentos en paralelo. Seguimiento y selección de exitosos.
Lo mismo que DataRobot: los resultados se publican para los usuarios comerciales en forma de aplicaciones. Para los “interesados” especialmente dotados. Y también se supervisa el uso real de los modelos. ¡Todo para los Pugs!
No entendí completamente cómo los modelos complejos entran en producción. Se proporciona alguna API para alimentarlos con datos y obtener resultados.
H2O
Driveless AI es un sistema muy compacto y sencillo para el aprendizaje automático supervisado. Todo en una caja. No está claro sobre el backend de inmediato.
El modelo se empaqueta automáticamente en un servidor REST o una aplicación Java. Esta es una gran idea. Se ha hecho mucho por la interpretabilidad y la explicabilidad. Interpretación y explicación de los resultados del trabajo del modelo (¿Qué, en su esencia, no debe explicarse, de lo contrario una persona puede calcular lo mismo?).
Por primera vez, se analiza en detalle un estudio de caso sobre datos no estructurados y PNL . Cuadro arquitectónico de alta calidad. En general, me gustaron las imágenes.
Existe un gran marco H2O de código abierto que no está del todo claro (¿un conjunto de algoritmos / bibliotecas?). Portátil visual propio sin programación como Jupiter ( enlace). También leí sobre Pojo y Mojo: modelos H2O envueltos en la realidad. El primero está en la frente, el segundo es con optimización. H20 son los únicos (!) A quienes Gartner ha escrito sobre análisis de texto y PNL en sus puntos fuertes, así como en sus esfuerzos de explicabilidad. ¡Es muy importante!
Ibid: Alto rendimiento, optimización y estándar de la industria para la integración de hierro y la nube.
Y es lógico en su debilidad: Driverles AI es débil y estrecha en comparación con su propio código abierto. ¡La preparación de datos es escasa en comparación con el mismo Paxata! E ignore los datos industriales: flujo, gráfico, geo. Bueno, no todo puede estar bien.
KNIME
Me gustaron 6 casos de negocios muy específicos muy interesantes en la página de inicio. Fuerte código abierto.
Gartner ha bajado de líderes a visionarios. Ganar poco dinero es una buena señal para los usuarios, dado que Leader no siempre es la mejor opción.
La palabra clave es como en H2O: aumentada significa ayudar a los científicos de datos ciudadanos pobres. ¡Esta es la primera vez que alguien ha sido regañado por su desempeño en una revisión! ¿Interesante? Es decir, ¿hay tanta potencia informática que el rendimiento no puede ser un problema sistémico en absoluto? Gartner tiene un artículo separado sobre esta palabra "aumentada" , al que no pude acceder.
¡Y KNIME parece ser el primer no estadounidense en la revisión! (Y a nuestros diseñadores les gustó mucho su página de destino. Gente extraña.
MathWorks
¡MatLab es un viejo amigo honorario conocido por todos! Cajas de herramientas para todos los ámbitos de la vida y situaciones. Algo muy diferente. De hecho, ¡muchas, muchas, muchas matemáticas para todas las ocasiones en general!
Producto complementario de Simulink para el diseño de sistemas. Cavé en las cajas de herramientas de Digital gemelos - No entiendo nada al respecto, pero una mucho se ha escrito aquí. Para la industria petrolera . En general, este es un producto fundamentalmente diferente de las profundidades de las matemáticas y la ingeniería. Para seleccionar kits de herramientas de matemáticas específicos. Según Gartner, todos tienen problemas como ingenieros inteligentes, sin colaboración, cada uno hurga en su propio modelo, sin democracia, sin explotabilidad.
RapidMiner
Me he encontrado y escuchado mucho antes (junto con Matlab) en el contexto de un buen código abierto. Enterrado un poco en TurboPrep como de costumbre. Estoy interesado en cómo obtener datos limpios a partir de datos sucios.
Nuevamente, puede ver que las personas son buenas en los materiales de marketing de 2018 y que hablan inglés terriblemente en la demostración de funciones.
Y gente de Dortmund desde 2001 con un fuerte pasado alemán)

No entendí en el sitio qué está exactamente disponible en el código abierto; es necesario profundizar más. Buenos videos sobre implementación y conceptos de AutoML.
Tampoco hay nada especial en el backend de RapidMiner Server. Probablemente será compacto y funcionará bien en las instalaciones fuera de la caja. Se empaqueta en Docker. Entorno compartido solo en el servidor RapidMiner. Y luego está Radoop, datos de hadup, contando rimas de Spark en el flujo de trabajo de Studio.
Los empujó hacia abajo como lo esperaban los vendedores jóvenes y calientes "vendedores de palos rayados". Sin embargo, Gartner predice el éxito futuro en el espacio empresarial. Puedes recaudar dinero allí. Los alemanes saben lo santo y santo :) ¡¡¡No menciones SAP !!!
¡Hacen mucho por los ciudadanos! Pero en la página se puede ver cómo Gartner dice que tienen dificultades con la innovación en ventas y que no luchan por la amplitud de la cobertura, sino por la rentabilidad. SAS y Tibco
siguieron siendo los proveedores de BI típicos para mí ... Y ambos están en la cima, lo que confirma mi creencia de que la ciencia de datos normal crece lógicamente a partir de BI, y no a partir de nubes e infraestructuras de Hadoop. De negocios, es decir, no de TI. Como en Gazpromneft, por ejemplo: link , un entorno DSML maduro surge de una sólida práctica de BI. Pero tal vez tenga una mancha y un sesgo en MDM y otras cosas, quién sabe.
SAS
No hay mucho que decir. Solo cosas obvias.
TIBCO
La estrategia se lee en la lista de compras en una página Wiki de una página. Si, larga historia, pero 28 !!! Charles. Soborné a BI Spotfire (2007) en mi juventud tecno. Y también informes de Jaspersoft (2014), luego hasta tres proveedores de análisis predictivo Insightful (S-plus) (2008), Statistica (2017) y Alpine Data (2017), procesamiento de eventos y sistema de transmisión por secuencias Streambase (2013), MDM Orchestra Networks (2018) ) y la plataforma en memoria Snappy Data (2019).
¡Hola Frankie!
