
Grandes problemas de textura
La idea de renderizar texturas gigantes no es nueva en sí misma. Parecería que lo que podría ser más fácil: cargar una gran textura de un millón de megapíxeles y dibujar un objeto con ella. Pero, como siempre, hay matices:
- Las API de gráficos limitan el tamaño máximo de una textura en ancho y alto. Puede depender tanto del hardware como de los controladores. El tamaño máximo para hoy es 32768x32768 píxeles.
- Incluso si llegamos a estos límites, la textura RGBA de 32768x32768 ocupará 4 gigabytes de memoria de video. La memoria de video es rápida, se encuentra en un bus ancho, pero es relativamente cara. Por lo tanto, suele ser menor que la memoria del sistema y mucho menor que la memoria del disco.
1. Representación moderna de texturas grandes
Dado que la imagen no encaja en los límites, naturalmente se sugiere una solución: simplemente divídala en pedazos (mosaicos):

todavía se utilizan varias variaciones de este enfoque para la geometría analítica. Este no es un enfoque universal; requiere cálculos no triviales en la CPU. Cada mosaico se dibuja como un objeto separado, lo que agrega sobrecarga y excluye la posibilidad de aplicar un filtrado de textura bilineal (habrá una línea visible entre los límites del mosaico). Sin embargo, las matrices de texturas pueden evitar la limitación del tamaño de la textura. Sí, esta textura todavía tiene un ancho y una altura limitados, pero han aparecido capas adicionales. El número de capas también es limitado, pero puede contar con 2048, aunque la especificación del volcán solo promete 256. En una tarjeta de video 1060 GTX, puede crear una textura que contenga 32768 * 32768 * 2048 píxeles. Simplemente no será posible crearlo, porque toma 8 terabytes y no hay tanta memoria de video. Si le aplica el bloque de compresión de hardware BC1 , dicha textura ocuparía "sólo" 1 terabyte. Todavía no cabe en una tarjeta de video, pero te diré qué hacer con él.
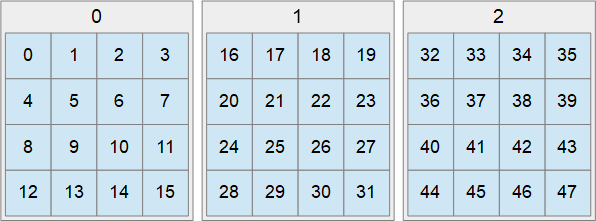
Entonces, todavía cortamos la imagen original en pedazos. Pero ahora no será una textura separada para cada mosaico, sino solo una pieza dentro de una enorme matriz de texturas que contiene todos los mosaicos. Cada fragmento tiene su propio índice, todos los fragmentos se organizan secuencialmente. Primero por columnas, luego por filas, luego por capas:
Una pequeña digresión sobre las fuentes de la textura de prueba.
Por ejemplo, tomé una imagen de la tierra desde aquí . Aumenté su tamaño original 43200x2160 a 65536x32768. Esto, por supuesto, no agregó detalles, pero obtuve la imagen que necesitaba, que no cabe en una capa de textura. Luego lo reduje recursivamente a la mitad con filtrado bilineal, hasta que obtuve un mosaico de 512 por 256 píxeles. Luego batí las capas resultantes en mosaicos de 512x256. Los comprimí BC1 y los escribí secuencialmente en un archivo. Algo como esto:
Como resultado, obtuvimos un archivo de 1,431,633,920 bytes, que consta de 21845 mosaicos. El tamaño de 512 por 256 no es aleatorio. Una imagen comprimida de 512 por 256 BC1 tiene exactamente 65536 bytes, que es el tamaño de bloque de la imagen dispersa, el héroe de este artículo. El tamaño del mosaico no es importante para el renderizado.
Descripción de la técnica para pintar grandes texturas.
Así que hemos cargado una matriz de texturas en la que los mosaicos son columnas / líneas / capas secuenciales.
Entonces, el sombreador que dibuja esta misma textura puede verse así:
layout(set=0, binding=0) uniform sampler2DArray u_Texture;
layout(location = 0) in vec2 v_uv;
layout(location = 0) out vec4 out_Color;
int lodBase[8] = { 0, 1, 5, 21, 85, 341, 1365, 5461};
int tilesInWidth = 32768 / 512;
int tilesInHeight = 32768 / 256;
int tilesInLayer = tilesInWidth * tilesInHeight;
void main() {
float lod = log2(1.0f / (512.0f * dFdx(v_uv.x)));
int iLod = int(clamp(floor(lod),0,7));
int cellsSize = int(pow(2,iLod));
int tX = int(v_uv.x * cellsSize); //column index in current level of detail
int tY = int(v_uv.y * cellsSize); //row index in current level of detail
int tileID = lodBase[iLod] + tX + tY * cellsSize; //global tile index
int layer = tileID / tilesInLayer;
int row = (tileID % tilesInLayer) / tilesInWidth;
int column = (tileID % tilesInWidth);
vec2 inTileUV = fract(v_uv * cellsSize);
vec2 duv = (inTileUV + vec2(column,row)) / vec2(tilesInWidth,tilesInHeight);
out_Color = texelFetch(u_Texture,ivec3(duv * textureSize(u_Texture,0).xy,layer),0);
}
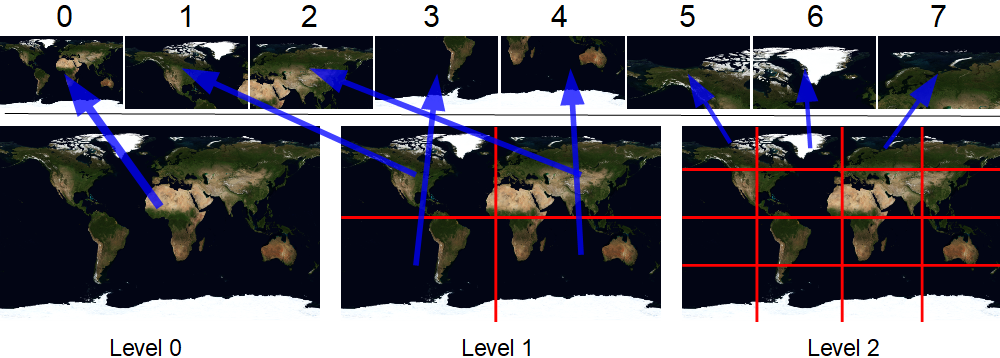
Echemos un vistazo a este sombreador. En primer lugar, debemos determinar qué nivel de detalle elegir. La maravillosa función dFdx nos ayudará con esto . Para simplificar mucho, devuelve el valor por el cual el atributo pasado es mayor en el píxel vecino. En la demostración, dibujo un rectángulo plano con coordenadas de textura en el rango 0..1. Cuando este rectángulo tiene X píxeles de ancho, dFdx (v_uv.x) devolverá 1 / X. Por lo tanto, el mosaico del primer nivel caerá píxel a píxel con dFdx == 1/512. El segundo en 1/1024, el tercero en 1/2048, etc. El nivel de detalle en sí se puede calcular de la siguiente manera: log2 (1.0f / (512.0f * dFdx (v_uv.x))). Recortemos la parte fraccionaria. Luego contamos cuántos mosaicos hay de ancho / alto en el nivel.
Consideremos el cálculo del resto usando un ejemplo:

aquí lod = 2, u = 0.65, v = 0.37
ya que lod es igual a dos, entonces cellsSize es igual a cuatro. La imagen muestra que este nivel consta de 16 mosaicos (4 filas 4 columnas), todo está correcto.
tX = int (0.65 * 4) = int (2.6) = 2
tY = int (0.37 * 4) = int (1.48) = 1
es decir dentro del nivel, este mosaico está en la tercera columna y en la segunda fila (indexando desde cero).
También necesitamos las coordenadas locales del fragmento (flechas amarillas en la imagen). Se pueden calcular fácilmente simplemente multiplicando las coordenadas de la textura original por el número de celdas en una fila / columna y tomando la parte fraccionaria. En los cálculos anteriores, ya están allí: 0,6 y 0,48.
Ahora necesitamos un índice global para este mosaico. Para esto utilizo la matriz precalculada lodBase. En él, por índice, se almacenan los valores de cuántos mosaicos había en todos los niveles anteriores (más pequeños). Agréguele el índice local del mosaico dentro del nivel. Por ejemplo, resulta lodBase [2] + 1 * 4 + 2 = 5 + 4 + 2 = 11. Lo cual también es correcto.
Conociendo el índice global, ahora necesitamos encontrar las coordenadas del mosaico en nuestra matriz de texturas. Para hacer esto, necesitamos saber cuántos mosaicos hemos encajado en ancho y alto. Su producto es cuántos mosaicos caben en la capa. En este ejemplo, cosí estas constantes directamente en el código de sombreado, por simplicidad. A continuación, obtenemos las coordenadas de textura y leemos el texto de ellas. Tenga en cuenta que sampler2DArray se utiliza como muestreador . Por lo tanto texelFetch pasamos un vector de tres componentes, en la tercera coordenada: el número de capa.
Texturas no cargadas completamente (imágenes de residencia parcial)
Como escribí anteriormente, las texturas enormes consumen mucha memoria de video. Además, se utiliza una cantidad muy pequeña de píxeles de esta textura. La solución al problema: las texturas de residencia parcial aparecieron en 2011. Su esencia es en resumen: ¡el mosaico puede no estar físicamente en la memoria! Al mismo tiempo, la especificación garantiza que la aplicación no se bloquee y todas las implementaciones conocidas garantizan que se devuelvan ceros. Además, la especificación garantiza que si se admite la extensión, se admite el tamaño de bloque garantizado en bytes: 64 kibytes. Las resoluciones de los bloques de construcción en la textura están vinculadas a este tamaño:
| TAMAÑO DE TEXEL (bits) | Forma de bloque (2D) | Forma de bloque (3D) |
|---|---|---|
| ? 4 bits? | ? 512 × 256 × 1 | no apoyo |
| 8 bits | 256 × 256 × 1 | 64 × 32 × 32 |
| 16 bits | 256 × 128 × 1 | 32 × 32 × 32 |
| 32 bits | 128 × 128 × 1 | 32 × 32 × 16 |
| 64 bits | 128 × 64 × 1 | 32 × 16 × 16 |
| 128 bits | 64 × 64 × 1 | 16 × 16 × 16 |
De hecho, no hay nada en la especificación sobre los texels de 4 bits, pero siempre podemos averiguar sobre ellos usando vkGetPhysicalDeviceSparseImageFormatProperties .
VkSparseImageFormatProperties sparseProps;
ermy::u32 propsNum = 1;
vkGetPhysicalDeviceSparseImageFormatProperties(hphysicalDevice, VK_FORMAT_BC1_RGB_SRGB_BLOCK, VkImageType::VK_IMAGE_TYPE_2D,
VkSampleCountFlagBits::VK_SAMPLE_COUNT_1_BIT, VkImageUsageFlagBits::VK_IMAGE_USAGE_SAMPLED_BIT | VkImageUsageFlagBits::VK_IMAGE_USAGE_TRANSFER_DST_BIT
, VkImageTiling::VK_IMAGE_TILING_OPTIMAL, &propsNum, &sparseProps);
int pageWidth = sparseProps.imageGranularity.width;
int pageHeight = sparseProps.imageGranularity.height;
La creación de una textura tan escasa es diferente a la habitual.
En primer lugar, en VkImageCreateInfo en las banderas se deben especificar VK_IMAGE_CREATE_SPARSE_BINDING_BIT y VK_IMAGE_CREATE_SPARSE_RESIDENCY_BIT En
segundo lugar, no es necesario vincular a través de la memoria vkBindImageMemory . Debe
averiguar qué tipos de memoria se pueden usar a través de vkGetImageMemoryRequirements . También le dirá cuánta memoria se necesita para cargar la textura completa, pero no necesitamos esta figura.
En su lugar, debemos decidir a nivel de la aplicación cuántos mosaicos pueden ser visibles simultáneamente.
Después de cargar algunos mosaicos, otros se descargarán, ya que ya no son necesarios. En la demostración, solo apunté con el dedo al cielo y asigné memoria para mil veinticuatro mosaicos. Suena un desperdicio, pero solo son 50 megabytes frente a 1.4GB de una textura completamente cargada. También necesita asignar memoria en el host, para la puesta en escena: un búfer.
const int sparseBlockSize = 65536;
int numHotPages = 512; //
VkMemoryRequirements memReqsOpaque;
vkGetImageMemoryRequirements(device, mySparseImage, &memReqsOpaque); // memoryTypeBits. -
VkMemoryRequirements image_memory_requirements;
image_memory_requirements.alignment = sparseBlockSize ; //
image_memory_requirements.size = sparseBlockSize * numHotPages;
image_memory_requirements.memoryTypeBits = memReqsOpaque.memoryTypeBits;
De esta forma tendremos una textura enorme en la que solo se cargan algunas partes. Se verá algo como esto:

Gestión de azulejos
En lo que sigue, usaré el término mosaico para denotar una pieza de textura (cuadrados verde oscuro y gris en la figura) y el término página para denotar una pieza en un bloque grande preasignado en la memoria de video (rectángulos verde claro y azul claro en la figura).
Después de crear una VkImage tan escasa , se puede usar a través de VkImageView en el sombreador. Por supuesto, esto será inútil: el muestreo devolverá ceros, no hay datos, pero a diferencia de la VkImage habitual , nada caerá y las capas de depuración no jurarán. Los datos de esta textura no solo deberán cargarse, sino también descargarse, ya que ahorramos memoria de video.
El enfoque OpenGL, que prevé la asignación de memoria por parte del controlador para cada bloque, no me parece correcto. Sí, tal vez se use allí algún asignador inteligente y rápido, porque el tamaño del bloque es fijo. Esto se insinúa por el hecho de que se utiliza un enfoque similar en el ejemplo de texturas de residencia dispersa en un volcán. Pero en cualquier caso, seleccione un gran bloque lineal de páginas y, en el lado de la aplicación, vincule estas páginas a mosaicos de textura específicos y llénelos con datos definitivamente no será más lento.
Por lo tanto, la interfaz de nuestra textura dispersa incluirá métodos como:
void CommitTile(int tileID, void* dataPtr); // 64
void FreeTile(int tileID);
void Flush();
El último método es necesario para agrupar el relleno / lanzamiento de baldosas. Actualizar los mosaicos uno por uno es bastante costoso, solo una vez por cuadro. Clasifiquémoslos en orden.
//void CommitTile(int tileID, void* dataPtr)
int freePageID = _getFreePageID();
if (freePageID != -1)
{
tilesByPageIndex[freePageID] = tileID;
tilesByTileID[tileID] = freePageID;
memcpy(stagingPtr + freePageID * pageDataSize, tileData, pageDataSize);
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = optimalTilingMem;
mbind.memoryOffset = freePageID * pageDataSize;
mbind.flags = 0;
memoryBinds.push_back(mbind);
VkBufferImageCopy copyRegion;
copyRegion.bufferImageHeight = pageHeight;
copyRegion.bufferRowLength = pageWidth;
copyRegion.bufferOffset = mbind.memoryOffset;
copyRegion.imageExtent.depth = 1;
copyRegion.imageExtent.width = pageWidth;
copyRegion.imageExtent.height = pageHeight;
copyRegion.imageOffset.x = mbind.offset.x;
copyRegion.imageOffset.y = mbind.offset.y;
copyRegion.imageOffset.z = 0;
copyRegion.imageSubresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
copyRegion.imageSubresource.baseArrayLayer = layer;
copyRegion.imageSubresource.layerCount = 1;
copyRegion.imageSubresource.mipLevel = 0;
copyRegions.push_back(copyRegion);
return true;
}
return false;
Primero, necesitamos encontrar un bloque libre. Simplemente reviso la matriz de estas mismas páginas y busco la primera, que contiene el número de código auxiliar -1. Este será el índice de la página gratuita. Copio datos del disco al búfer de ensayo usando memcpy. La fuente es un archivo mapeado en memoria con un desplazamiento para un mosaico específico. Además, por el ID del mosaico, considero su posición (x, y, capa) en la matriz de textura.
A continuación, comienza lo más interesante: completar la estructura VkSparseImageMemoryBind . Es ella quien une la memoria de video al mosaico. Sus campos importantes son:
memoria . Este es un objeto VkDeviceMemory . Preasignó memoria para todas las páginas.
memoryOffset . Este es el desplazamiento en bytes a la página que necesitamos.
A continuación, necesitaremos copiar datos del búfer de ensayo en esta memoria recién vinculada. Esto se hace usando vkCmdCopyBufferToImage .
Como copiaremos muchas secciones a la vez, en este lugar solo llenaremos la estructura, con una descripción de dónde y dónde copiaremos. Lo importante aquí es bufferOffset que indica el desplazamiento que ya está en el búfer de transición . En este caso, coincide con el offset en la memoria de video, pero las estrategias pueden ser diferentes. Por ejemplo, divida las baldosas en caliente, tibio y frío. Los calientes están en la memoria de video, los calientes están en la RAM y los fríos están en el disco. Entonces, el búfer de etapas puede ser más grande y el desplazamiento será diferente.
//void FreeTile(int tileID)
if (tilesByTileID.count(tileID) > 0)
{
i16 hotPageID = tilesByTileID[tileID];
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.memory = optimalTilingMem;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = VK_NULL_HANDLE;
mbind.memoryOffset = 0;
mbind.flags = 0;
memoryBinds.push_back(mbind);
tilesByPageIndex[hotPageID] = -1;
tilesByTileID.erase(tileID);
return true;
}
return false;
Aquí es donde desacoplamos la memoria del mosaico. Para hacer esto, asigne la memoria VK_NULL_HANDLE .
//void Flush();
cbuff = hostDevice->CreateOneTimeSubmitCommandBuffer();
VkImageSubresourceRange imageSubresourceRange;
imageSubresourceRange.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
imageSubresourceRange.baseMipLevel = 0;
imageSubresourceRange.levelCount = 1;
imageSubresourceRange.baseArrayLayer = 0;
imageSubresourceRange.layerCount = numLayers;
VkImageMemoryBarrier bSamplerToTransfer;
bSamplerToTransfer.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bSamplerToTransfer.pNext = nullptr;
bSamplerToTransfer.srcAccessMask = 0;
bSamplerToTransfer.dstAccessMask = VK_ACCESS_TRANSFER_WRITE_BIT;
bSamplerToTransfer.oldLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bSamplerToTransfer.newLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bSamplerToTransfer.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.image = opaqueImage;
bSamplerToTransfer.subresourceRange = imageSubresourceRange;
VkSparseImageMemoryBindInfo imgBindInfo;
imgBindInfo.image = opaqueImage;
imgBindInfo.bindCount = memoryBinds.size();
imgBindInfo.pBinds = memoryBinds.data();
VkBindSparseInfo sparseInfo;
sparseInfo.sType = VK_STRUCTURE_TYPE_BIND_SPARSE_INFO;
sparseInfo.pNext = nullptr;
sparseInfo.waitSemaphoreCount = 0;
sparseInfo.pWaitSemaphores = nullptr;
sparseInfo.bufferBindCount = 0;
sparseInfo.pBufferBinds = nullptr;
sparseInfo.imageOpaqueBindCount = 0;
sparseInfo.pImageOpaqueBinds = nullptr;
sparseInfo.imageBindCount = 1;
sparseInfo.pImageBinds = &imgBindInfo;
sparseInfo.signalSemaphoreCount = 0;
sparseInfo.pSignalSemaphores = nullptr;
VkImageMemoryBarrier bTransferToSampler;
bTransferToSampler.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bTransferToSampler.pNext = nullptr;
bTransferToSampler.srcAccessMask = 0;
bTransferToSampler.dstAccessMask = VK_ACCESS_SHADER_READ_BIT;
bTransferToSampler.oldLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bTransferToSampler.newLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bTransferToSampler.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.image = opaqueImage;
bTransferToSampler.subresourceRange = imageSubresourceRange;
vkQueueBindSparse(graphicsQueue, 1, &sparseInfo, fence);
vkWaitForFences(device, 1, &fence, true, UINT64_MAX);
vkResetFences(device, 1, &fence);
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, VK_PIPELINE_STAGE_TRANSFER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bSamplerToTransfer);
if (copyRegions.size() > 0)
{
vkCmdCopyBufferToImage(cbuff, stagingBuffer, opaqueImage, VkImageLayout::VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL, copyRegions.size(), copyRegions.data());
}
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TRANSFER_BIT, VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bTransferToSampler);
hostDevice->ExecuteCommandBuffer(cbuff);
copyRegions.clear();
memoryBinds.clear();
El trabajo principal tiene lugar en este método. En el momento de su llamada, ya tenemos dos matrices con VkSparseImageMemoryBind y VkBufferImageCopy. Completamos las estructuras para llamar a vkQueueBindSparse y lo llamamos. Esta no es una función de bloqueo (como casi todas las funciones en Vulkan), por lo que tendremos que esperar explícitamente a que se ejecute. Para ello se le pasa el último parámetro VkFence , cuya ejecución esperaremos. De hecho, en mi caso, la espera de esta fenza no afectó de ninguna manera el rendimiento del programa. Pero, en teoría, aquí se necesita.
Una vez que hayamos adjuntado memoria a los mosaicos, debemos completar los dibujos en ellos. Esto se hace con la función vkCmdCopyBufferToImage .
Puede completar los datos en la textura con diseñoVK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL y obténgalos en un sombreador con diseño VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL . Por tanto, necesitamos dos barreras. Tenga en cuenta que en VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL traducimos estrictamente de VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL , no de VK_IMAGE_LAYOUT_UNDEFINED . Dado que estamos llenando solo una parte de la textura, es importante que no perdamos las partes que se rellenaron antes.
Aquí hay un video de cómo funciona. Una textura. Un objeto. Decenas de miles de mosaicos.
Lo que queda detrás de escena es cómo determinar en la aplicación cómo averiguar realmente qué mosaico es el momento de cargar y cuál descargar. En la sección que describe los beneficios del nuevo enfoque, uno de los puntos fue que puede usar geometría compleja. En la misma prueba, yo mismo utilizo la proyección ortográfica y el rectángulo más simples. Y cuento la identificación de los mosaicos analíticamente. Antideportivo.
De hecho, los identificadores de mosaicos visibles se cuentan dos veces. Analíticamente en la CPU y honestamente en el sombreador de fragmentos. Al parecer, ¿por qué no recogerlos del sombreador de fragmentos? Pero no es tan simple. Este será el segundo artículo.