Al hacerlo, olvidan que los patrones son solo soluciones posibles. Los patrones, como cualquier principio, tienen límites de aplicabilidad y es importante comprenderlos. El camino al infierno está pavimentado con una adhesión ciega y religiosa incluso a las palabras autorizadas.
Y la presencia de los patrones necesarios en el marco no garantiza su correcta y consciente aplicación.

El brillo y la pobreza de Active Record
Veamos el patrón Active Record como un anti-patrón, que algunos lenguajes de programación y frameworks intentan evitar de todas las formas posibles.
La esencia de Active Record es simple: almacenamos lógica empresarial con lógica de almacenamiento de entidad. En otras palabras, para decirlo de manera muy simple, cada tabla en la base de datos corresponde a una clase de entidad junto con un comportamiento.
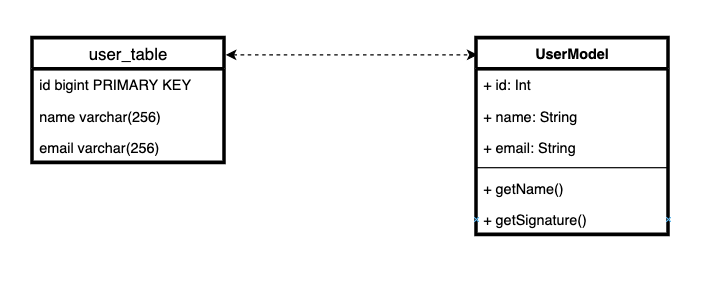
Existe una opinión bastante fuerte de que combinar la lógica empresarial con la lógica de almacenamiento en una clase es un patrón muy malo e inutilizable. Viola el principio de responsabilidad exclusiva. Y por esta razón, Django ORM es malo por diseño.
De hecho, puede que no sea muy bueno combinar lógica de almacenamiento y lógica de dominio en la misma clase.
Tomemos los modelos de usuario y perfil, por ejemplo. Este es un patrón bastante común. Hay una placa principal, y hay una adicional, que almacena datos no siempre obligatorios, pero a veces necesarios.

Resulta que la entidad del dominio "usuario" ahora está almacenada en dos tablas, y en el código tenemos dos clases. Y cada vez que realizamos algunas correcciones directamente
user.profile, debemos recordar que este es un modelo separado y que hicimos cambios en él. Y guárdalo por separado.
def create(self, validated_data):
# create user
user = User.objects.create(
url = validated_data['url'],
email = validated_data['email'],
# etc ...
)
profile_data = validated_data.pop('profile')
# create profile
profile = Profile.objects.create(
user = user
first_name = profile_data['first_name'],
last_name = profile_data['last_name'],
# etc...
)
return user
Para obtener una lista de usuarios, es imperativo pensar si se tomará un atributo de estos usuarios
profilepara seleccionar inmediatamente dos signos con una combinación y no obtenerlos SELECT N+1en un bucle.
user = User.objects.get(email='example@examplemail.com')
user.userprofile.company_name
user.userprofile.country
Las cosas empeoran aún más si, dentro de la arquitectura de microservicio, parte de los datos del usuario se almacena en otro servicio, por ejemplo, roles y derechos en LDAP.
Al mismo tiempo, por supuesto, realmente no quiero que los usuarios externos de la API se preocupen por esto de alguna manera. Hay un recurso REST
/users/{user_id}y me gustaría trabajar con él sin pensar en cómo se organiza el almacenamiento de datos en su interior. Si se almacenan en diferentes fuentes, será más difícil cambiar de usuario u obtener la lista de datos.
En general, ORM! = Modelo de dominio!

Y cuanto más difiere el mundo real de la suposición de que "una tabla en la base de datos, una entidad del dominio", más problemas con el patrón de registro activo.
Resulta que cada vez que escribe lógica empresarial, debe recordar cómo se almacena la esencia del dominio.
Los métodos ORM son el nivel más bajo de abstracción. No admiten ninguna limitación del área temática, lo que significa que dan la oportunidad de cometer errores. También ocultan al usuario qué consultas se realizan realmente en la base de datos, lo que conduce a consultas ineficientes y largas. El clásico, cuando las consultas se realizan en bucles, en lugar de una combinación o filtro.
¿Y qué más, además de la construcción de consultas (la capacidad de generar consultas), nos brinda ORM? No importa. ¿Capacidad para pasar a una nueva base de datos? ¿Y quién en su sano juicio y firme memoria se mudó a una nueva base de datos y ORM lo ayudó en esto? Si lo percibe no como un intento de mapear el modelo de dominio (!) En la base de datos, sino como una biblioteca simple que le permite hacer consultas a la base de datos de una manera conveniente, entonces todo encaja.
Y aunque se utilizan en los nombres de las clases
Modely en los nombres de los archivos models, no se convierten en modelos. No te engañes. Es solo una descripción de las etiquetas. No ayudarán a encapsular nada.
Pero si todo está tan mal, ¿qué hacer? Los patrones de arquitecturas en capas vienen al rescate.
¡La arquitectura en capas contraataca!
La idea de las arquitecturas en capas es simple: separamos la lógica empresarial, la lógica de almacenamiento y la lógica de uso.
Parece perfectamente lógico separar el almacenamiento del cambio de estado. Aquellos. Cree una capa separada que pueda recibir y guardar datos del almacenamiento "abstracto".
Dejamos toda la lógica de almacenamiento, por ejemplo, en la clase de almacenamiento
Repository. Y los controladores (o capa de servicio) solo lo usan para obtener y guardar entidades. Entonces podemos cambiar la lógica de almacenar y recibir como queramos, ¡y este será un lugar! Y cuando escribimos el código del cliente, podemos estar seguros de que no nos hemos olvidado un lugar más en el que necesitamos guardar o desde el que debemos tomarlo, y no repetimos el mismo código un montón de veces.
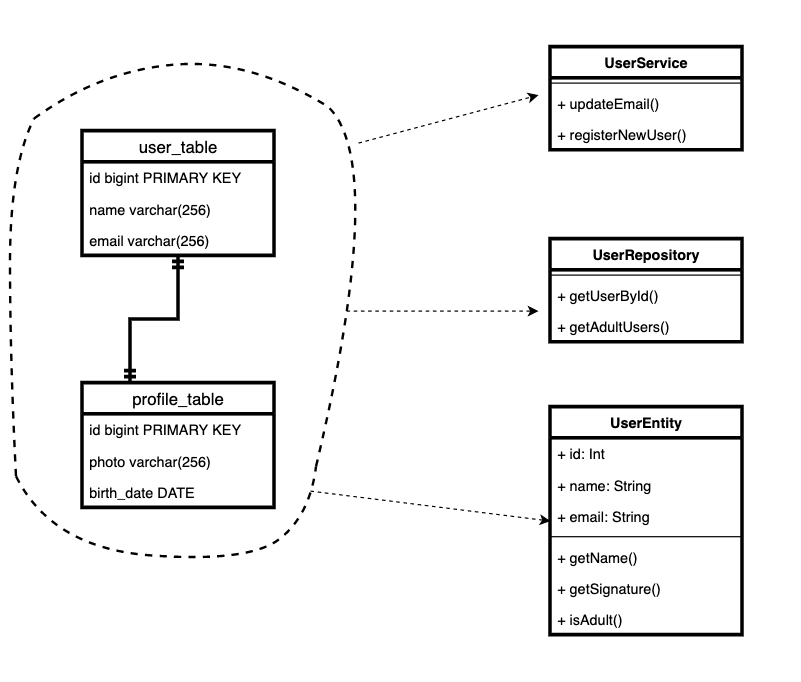
No nos importa si la entidad consta de registros en diferentes tablas o microservicios. O si las entidades con diferente comportamiento según el tipo se almacenan en una tabla.
Pero esta división de responsabilidades no es gratuita . Debe entenderse que se crean capas adicionales de abstracción para evitar cambios de código "incorrectos". Obviamente,
Repositoryesconde el hecho de que el objeto está almacenado en la base de datos SQL, por lo que debemos intentar que el SQLismo no se salga de los límites Repository. Y todas las solicitudes, incluso las más simples y obvias, deberán arrastrarse a través de la capa de almacenamiento.
Por ejemplo, si es necesario obtener una oficina por nombre y departamento, deberá escribir lo siguiente:
#
interface OfficeRepository: CrudRepository<OfficeEntity, Long> {
@Query("select o from OfficeEntity o " +
"where o.number = :office and o.branch.number = :branch")
fun getOffice(@Param("branch") branch: String,
@Param("office") office: String): OfficeEntity?
...
Y en el caso de Active Record, todo es mucho más sencillo:
Office.objects.get(name=’Name’, branch=’Branch’)
No es tan simple incluso si la entidad comercial está realmente almacenada de una manera no trivial (en varias tablas, en diferentes servicios, etc.). Para implementar esto bien (y correctamente), para lo que se creó este patrón, la mayoría de las veces debe usar patrones como agregados, Unidad de trabajo y Mapeadores de datos.
Es difícil seleccionar correctamente un agregado, observar correctamente todas las restricciones que se le imponen y realizar correctamente el mapeo de datos. Y solo un desarrollador muy bueno puede hacer frente a esta tarea. El que, en el caso de Active Record, podía hacer todo "bien".
¿Qué pasa con los desarrolladores habituales? Aquellos que conocen todos los patrones y están firmemente convencidos de que si usan una arquitectura en capas, su código automáticamente se vuelve fácil de mantener y bueno, no como Active Record. Y crean repositorios CRUD para cada tabla. Y funcionan en el concepto de
una placa, un repositorio, una entidad.
No:
un repositorio, un objeto de dominio.

También creen ciegamente que si se usa una palabra en una claseEntity, refleja el modelo de dominio. Como una palabraModelen Active Record.
El resultado es una capa de almacenamiento más compleja y menos flexible que tiene todas las propiedades negativas de los mapeadores de registros activos y repositorios / datos.
Pero la arquitectura en capas no termina ahí. La capa de servicio también suele distinguirse.
La implementación correcta de dicha capa de servicio también es una tarea difícil. Y, por ejemplo, los desarrolladores sin experiencia crean una capa de servicio, que es un servicio: proxy para repositorios u ORM (DAO). Aquellos. Los servicios están escritos para que en realidad no encapsulen la lógica empresarial:
#
@Service
class AccountServiceImpl(val accountDaoService: AccountDaoService) : AccountService {
override fun saveAccount(account: Account) =
accountDaoService.saveAccount(convertClass(account, AccountEntity::class.java))
override fun deleteAccount(id: Long) =
accountDaoService.deleteAccount(id)
Y existe una combinación de desventajas tanto en la capa de registro como en la de servicio.
Como resultado, en los frameworks Java en capas y en el código escrito por amantes de los patrones jóvenes e inexpertos, el número de abstracciones por unidad de lógica empresarial comienza a superar todos los límites razonables.
Hay capas, pero todas son triviales y son solo capas para llamar a la siguiente capa.
La presencia de patrones OOP en el framework no garantiza su correcta y adecuada aplicación.
No hay bala de plata
Está bastante claro que no existe una fórmula mágica. Las soluciones complejas son para problemas complejos y las soluciones simples son para problemas simples.
Y no hay patrones buenos ni malos. En una situación, Active Record es bueno, en otras, arquitectura en capas. Y sí, para la gran mayoría de aplicaciones pequeñas y medianas, Active Record funciona razonablemente bien. Y para la gran mayoría de aplicaciones pequeñas y medianas, la arquitectura en capas (a lo Spring) funciona peor. Y exactamente lo contrario para los servicios web y las aplicaciones complejas ricas en lógica.
Cuanto más simple sea la aplicación o el servicio, menos capas de abstracción necesitará.
Dentro de los microservicios, donde no hay mucha lógica empresarial, a menudo no tiene sentido utilizar arquitecturas en capas. Los scripts transaccionales ordinarios (scripts en el controlador) pueden ser perfectamente adecuados para la tarea en cuestión.
En realidad, un buen desarrollador se diferencia de uno malo en que no solo conoce los patrones, sino que también entiende cuándo aplicarlos.