int main()
{
int n = 500000000;
int *a = new int[n + 1];
for (int i = 0; i <= n; i++)
a[i] = i;
for (int i = 2; i * i <= n; i++)
{
if (a[i]) {
for (int j = i*i; j <= n; j += i) {
a[j] = 0;
}
}
}
delete[] a;
return 0;
}Esta es una aplicación sencilla específicamente para experimentos, busca números primos usando el tamiz de Eratosthenes . Ejecutemos la solución 20 veces y calculemos el tiempo de usuario de cada ejecución.
Descripción del banco de pruebas
i7-8750H @ 2,20
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
Dispersión del tiempo de ejecución antes de las optimizaciones:
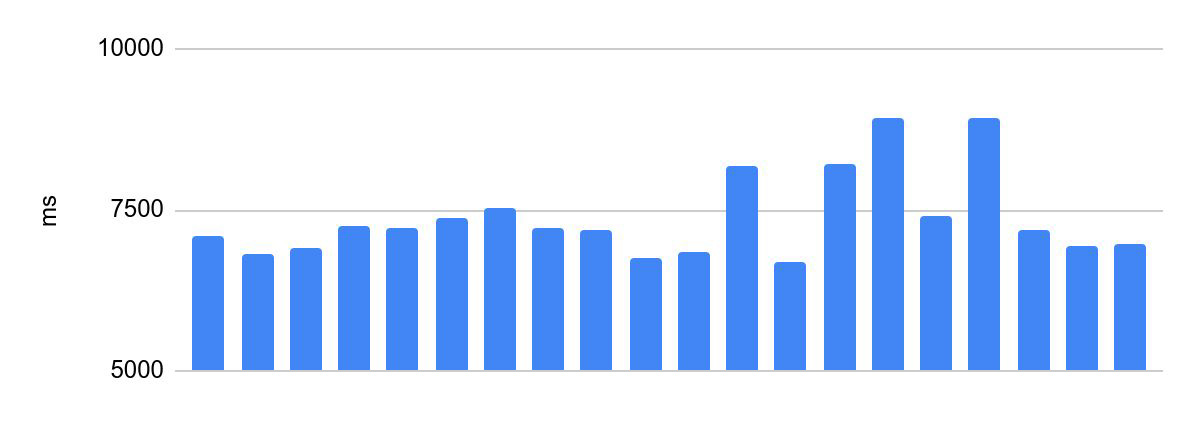
la diferencia entre la ejecución más rápida y la más lenta es de 2230 ms.
Esto es inaceptable para la programación de Olimpiadas. El tiempo de ejecución del código del participante es uno de los criterios para el éxito de su solución y una de las condiciones del concurso, de ello depende el reparto de premios. Por lo tanto, existe un requisito importante para tales sistemas: el mismo tiempo de verificación para el mismo código. En lo que sigue, llamaremos a esto la consistencia de la ejecución del código.
Intentemos alinear el tiempo de ejecución.
Aislamiento del núcleo
Empecemos por lo obvio. Los procesos compiten por los núcleos y, de alguna manera, es necesario aislar el núcleo para la ejecución de la solución. Además, con Hyper Threading habilitado, el sistema operativo define un núcleo de procesador físico como dos núcleos lógicos separados. Para un aislamiento de núcleo justo, necesitamos deshabilitar Hyper Threading. Esto se puede hacer en la configuración del BIOS.
El kernel de Linux listo para usar admite un indicador de inicio para aislar los kernels isolcpus. Agregue esta bandera a GRUB_CMDLINE_LINUX_DEFAULT en la configuración de grub: / etc / default / grub. Por ejemplo:
GRUB_CMDLINE_LINUX_DEFAULT="... isolcpus=0,1"
Ejecute update-grub y reinicie el sistema.
Todo se ve como se esperaba: el sistema no usa los dos primeros núcleos:

Comencemos con un kernel aislado. La configuración de CPU Affinity le permite vincular un proceso a un núcleo específico. Hay varias formas de hacer esto. Por ejemplo, ejecutemos la solución en un contenedor porto (el kernel se selecciona usando el argumento cpu_set):
portoctl exec test command='sudo stress.sh' cpu_set=0Offtop: utilizamos QEMU-KVM para ejecutar soluciones en producción. El contenedor de porto se utiliza a lo largo de este artículo para que sea más fácil de mostrar.
Lanzamiento con un kernel dedicado a la solución, sin cargar kernels vecinos:

la diferencia es de 375 ms. Mejoró, pero sigue siendo demasiado.
Rendimiento de Tyunim
Probemos nuestra prueba de esfuerzo. ¿Cúal? Nuestra tarea es cargar todos los núcleos con múltiples subprocesos. Esto se puede hacer de varias maneras:
- Escribe una aplicación sencilla que creará muchos hilos y empezará a contar algo en cada uno de ellos.
- :
cat /dev/zero | pbzip2 -c > /dev/null. pbzip2 — bzip2. - stress
stress --cpu 12.
Lanzamiento con un núcleo dedicado a la solución, con carga en núcleos vecinos:

La diferencia es de 1354 ms: un segundo más que sin carga. Obviamente, la carga afectó el tiempo de ejecución, a pesar de que estábamos ejecutando en un kernel aislado. Se puede observar que en un momento determinado disminuyó el tiempo de ejecución. A primera vista, esto es contrario a la intuición: al aumentar la carga, el rendimiento también aumenta.
En producción, este comportamiento (cuando el tiempo de ejecución comienza a flotar bajo carga) puede ser muy doloroso de disparar. ¿Cuál es la carga en este caso? Un flujo de decisiones de los participantes, con mayor frecuencia en las principales competiciones y olimpiadas.
La razón es que Intel Turbo Boost se activa bajo carga, una tecnología para aumentar la frecuencia. Desactívala. Para mi stand también apagué SpeedStep... Para un procesador AMD, Turbo Core Cool'n'Quiet tendría que estar apagado. Todo lo anterior se hace en la BIOS, la idea principal es deshabilitar lo que controla automáticamente la frecuencia del procesador.
Ejecución en un núcleo aislado con Turbo Boost desactivado y carga en núcleos vecinos: se

ve bien, pero la diferencia sigue siendo de 252 ms. Y eso sigue siendo demasiado.
Offtop: observe cómo el tiempo de ejecución promedio se redujo en aproximadamente un 25%. En la vida cotidiana, las tecnologías para discapacitados son buenas.
Nos deshicimos de la competencia por los núcleos, estabilizamos la frecuencia del núcleo, ahora nada los afecta. Entonces, ¿de dónde viene la diferencia?
NUMA
Acceso a memoria no uniforme, o arquitectura de memoria no uniforme, "una arquitectura con memoria desigual". En los sistemas NUMA (es decir, convencionalmente, en cualquier computadora multiprocesador moderna), cada procesador tiene memoria local, que se considera parte del total. Cada procesador puede acceder tanto a su memoria local como a la memoria local de otros procesadores (memoria remota). La irregularidad es que el acceso a la memoria local es notablemente más rápido.
El tiempo de actuación "camina" precisamente por tal desnivel. Arreglemoslo vinculando nuestra ejecución a un nodo numa específico. Para hacer esto, agregue numa node a la configuración del contenedor porto:
portoctl exec test command='stress.sh' cpu_set="node 0" cpu_set=0Ejecución en un núcleo aislado con Turbo Boost desactivado, configuración NUMA y carga en núcleos vecinos:
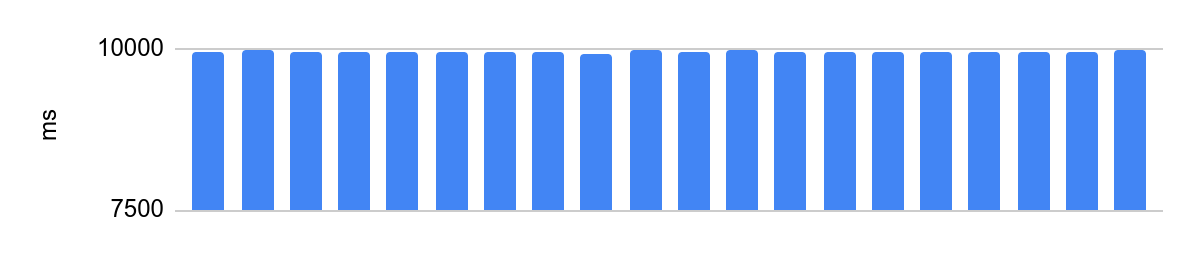
la diferencia es de 48 ms y el tiempo medio de ejecución después de que desactivamos las optimizaciones del procesador es de 10 segundos. 48 ms a 10 s equivalen a un error de 0,5%, muy bien.
Spoiler importante
Un poco más sobre isolcpus
El indicador isolcpus tiene un problema: algunos subprocesos del sistema aún pueden programar en un kernel aislado.
Por lo tanto, en producción usamos un kernel parcheado con funcionalidad extendida de esta bandera. Por lo tanto, seleccionamos el kernel, teniendo en cuenta la bandera, cuando los hilos están programando.
, 3.18. kthread_run, . CPU, isolcpus.
— slave_cpus , .
— slave_cpus , .
Planes para el futuro
Pools
Si una máquina decisiva es más poderosa que la otra, entonces ninguna cantidad de trucos de aislamiento del núcleo ayudarán; como resultado, aún obtendremos una gran diferencia en el tiempo de ejecución. Por lo tanto, debe pensar en entornos heterogéneos. Hasta ahora, simplemente no admitíamos la heterogeneidad: toda la flota de máquinas decisorias está equipada con el mismo hardware. Pero en un futuro cercano, comenzaremos a dividir hardware diferente en grupos homogéneos, y cada competencia se llevará a cabo dentro del mismo grupo con el mismo hardware.
Moviéndose a la nube
Un nuevo desafío para el sistema será la necesidad de lanzarse en Yandex.Cloud. Según los estándares actuales, los servidores de hierro no son confiables, es necesario un movimiento, pero es importante mantener la coherencia en la ejecución de los paquetes. Aquí todavía se están investigando las posibilidades técnicas. Existe la idea de que, en casos extremos, las máquinas en la nube pueden ejecutar soluciones que no requieren un tiempo de ejecución estricto. Por lo tanto, reduciremos la carga en las máquinas de hierro y solo se ocuparán de soluciones que solo requieran consistencia. Hay otra opción: primero verifique el paquete en la nube y, si no cumplió con el límite de tiempo, vuelva a verificarlo en hardware real.
Recopilación de estadísticas
Incluso después de todos los ajustes, los procesadores inevitablemente se ralentizarán. Para reducir el efecto negativo, ejecutaremos las soluciones en paralelo, compararemos los resultados y, si difieren, lanzaremos una nueva comprobación. Además, si una de las máquinas decisivas se degrada constantemente, es una excusa para ponerla fuera de servicio y ocuparse de los motivos.
conclusiones
El concurso tiene una peculiaridad: puede parecer que todo se reduce a simplemente ejecutar el código y obtener el resultado. En este artículo, he revelado solo un pequeño aspecto de este proceso. Hay algo como esto en cada capa del servicio.