Atributos con metainformación
Título (atributo de título)
El título describe brevemente la esencia de la regla. Este campo de texto tiene hasta 256 caracteres. Aquí debe dar la descripción más breve y amplia. Siga estas pautas:
- No uses construcciones como "Detecta ..." como encabezado. Y sin esto, está claro que la regla detecta algo.
- Utilice títulos amplios que no superen los 50 caracteres.
- Escriba las explicaciones y los comentarios importantes en el campo de descripción (lo consideraremos más adelante).
Descripción detallada y explicaciones adicionales de la regla (atributo de descripción)
Si el título contiene una breve descripción de la regla para una comprensión general de su propósito, entonces en el campo de descripción puede especificar todos los matices y características que el autor pone en esta regla. También describe brevemente el ataque que se propone detectar utilizando esta regla. La longitud máxima de este campo es de 65 535 caracteres.
Identificador único de la regla e identificadores de reglas relacionadas (id, relativo)
Dado que los valores específicos de los atributos de título y descripción pueden ser arbitrarios, incluido el mismo para dos reglas diferentes (nunca haga esto), no son adecuados para identificar de forma única una regla. Se necesita un identificador único más formal. El identificador universalmente único (UUID) se utiliza en la gran mayoría de productos para resolver este problema. Los autores de Sigma aconsejan a los desarrolladores de reglas que sigan el mismo camino, sin embargo, cualquier esquema de generación de identificadores puede usarse para reglas privadas. En el repositorio público, el UUID mencionado anteriormente se selecciona como el esquema para crear identificadores. Seguimos el mismo enfoque en la regla de ejemplo en la primera parte del artículo. Si desea publicar su regla en el futuro o enviar una solicitud para agregarla al repositorio oficial,le recomendamos que siga el mismo esquema para crear un identificador de regla.
El identificador único se puede generar de diferentes formas, en Windows la forma más sencilla es ejecutar el siguiente código de PowerShell:
PS C:\> "id: $(New-Guid)"
id: b2ddd389-f676-4ac4-845a-e00781a48e5fEn un sistema operativo basado en el kernel de Linux, puede utilizar la utilidad uuidgen:
$ echo “id: `uuidgen`”
id: b2ddd389-f676-4ac4-845a-e00781a48e5fCuando se realizan cambios importantes en una regla, se debe cambiar su identificador. Situaciones en las que crear un nuevo identificador:
- cambiando la lógica de la regla;
- herencia de una regla de una existente conservando la original (también es cierto para la situación de mejora de la regla);
- fusionar reglas.
Para los casos de herencia y fusión de reglas, existe un identificador especial relacionado con cuatro posibles valores del tipo (el atributo de tipo).
Consideremos situaciones hipotéticas en las que podría resultar útil utilizar el identificador relacionado. Para mayor claridad, en lugar de identificadores largos en el formato UUID, simplemente escribiremos X, Y, Z.
En el primer caso, la nueva regla (id: X) se deriva de la existente (id: Y). Esto puede suceder si hemos mejorado la lógica de trabajo en una nueva regla, pero por alguna razón queremos mantener la regla anterior. Por lo tanto, nuestra regla tiene una regla principal que se guarda y se puede usar en el futuro:

El segundo caso es similar al primero excepto por un hecho: la antigua regla no se conserva. Es decir, reescribimos radicalmente la regla, y era necesario asignar un nuevo identificador, y el antiguo queda obsoleto (obsoleto) y ya no se utilizará más. Entonces, teníamos una regla (id: Y) que reescribimos y decidimos que ya no la necesitamos. La nueva regla recibió un identificador (id: X). En la regla Sigma, una situación similar se verá así:

En el tercer caso, considere una situación en la que apareció una nueva regla como resultado de la fusión de dos o más reglas existentes. La nueva regla (id: X) es el resultado de fusionar dos reglas (id: Y, Z). Es importante tener en cuenta que las dos reglas principales que participaron en la fusión se conservan y se pueden utilizar más. En una regla Sigma, una situación similar podría verse así:

aunque el orden de las reglas no se define durante la fusión, en los comentarios las hemos numerado para mayor claridad.
El cuarto tipo es renombrar. Como sugiere el nombre, este tipo de asociación entre identificadores se aplica cuando se cambia el nombre de una regla antigua. De hecho, este tipo no se utiliza en la práctica. Como ejemplo de uso, los autores citan un caso de cambio del esquema para la creación de identificadores (recuerde que UUID no es el único esquema de nomenclatura posible).
Estado de regla lista (atributo de estado)
Según la especificación, una regla puede estar en uno de tres estados:
- estable : la regla se puede utilizar en una infraestructura real para detectar ataques, no se requiere modificación;
- prueba : la regla es casi estable, pero se requiere un pequeño ajuste;
- experimental : una regla de este tipo puede generar una gran cantidad de falsos positivos, pero al mismo tiempo revela eventos interesantes.
Por lo general, antes de ejecutar una regla en una infraestructura real, la regla tiene el estado experimental, ya que aún no se sabe exactamente con qué frecuencia generará errores. Además, después de varios meses de pruebas, si la regla está bien escrita y no genera errores (o los hay insignificantes), se transfiere a la categoría estable. De lo contrario, se realizan correcciones y se comprueban nuevamente. No hay reglas con el estado de la prueba en el repositorio oficial de Sigma.
La licencia bajo la cual se distribuye la regla (el atributo de licencia)
La licencia bajo la cual se distribuye la regla. Este campo proviene del mundo del software libre. Rara vez se especifica, pero si se especifica, debe cumplir con la especificación SPDX ID.
Creadores de reglas (atributo de autor)
Este campo enumera todos los autores de la regla. Se considera una buena forma indicar no solo a la persona que escribió la regla en sí, sino también al autor de la idea original de detección.
Vínculos a estudios que ayudaron a desarrollar la regla (atributo de referencias)
Al escribir las reglas de Sigma, es habitual incluir enlaces a artículos originales, tweets e investigaciones que ayudaron o inspiraron la creación de la regla. Además de expresar respeto por el trabajo de otra persona, estos enlaces ayudan a comprender cómo funciona la regla.
Campos de eventos útiles para que los análisis muestren cuándo se activa una regla (atributo de campos)
Dado que el autor de la regla tiene un conocimiento profundo del algoritmo de ataque y los eventos que se generan durante su ejecución, puede seleccionar una lista de campos de eventos que ayudarán al operador del SOC u otro empleado del equipo de seguridad de la información a comprender el incidente.
Casos de falsos positivos de la regla (atributo de falsos positivos)
El campo de falsos positivos es bastante inusual para las reglas de detección. No afecta el curso de la validación de eventos de ninguna manera, pero hace dos cosas útiles:
- Ayude al usuario a determinar si una regla determinada es un error.
- Recuerde al desarrollador de la regla una vez más que su regla puede activarse falsamente. Tales pensamientos pueden ayudar a un desarrollador a escribir una regla más precisa.
Varias etiquetas y etiquetas (atributo de etiquetas)
Normalmente, este campo se utiliza para las etiquetas MITRE ATT & CK y CAR. Recomendamos encarecidamente que clasifique su regla de inmediato, ya que dicho marcado le permite integrar las reglas Sigma con otros proyectos de seguridad de la información. Sin embargo, el formato no limita a los autores de las reglas solo a dichas etiquetas, puede poner cualquiera.
Colecciones de reglas
Según el estándar YAML, un archivo (en su flujo de terminología) puede contener varios documentos YAML. Esto se logra gracias a la etiqueta de documento YAML - tres guiones ("---"). Para el formato Sigma, estos documentos pueden ser reglas Sigma independientes o documentos de acción.
En el primer caso, todo es simple: un archivo contiene reglas Sigma completas que separados entre sí por una etiqueta de documento YAML (ejemplo rules / proxy / proxy_ursnif_malware.yml ) El
segundo caso es más complicado: un documento YAML se trata como un documento de acción si el atributo de acción de nivel superior tiene uno de los siguientes tres valores:
- global — , YAML- . action- . : , Sigma- ;
- reset — , action-;
- repeat — repeat .
Nota : el atributo de acción puede aparecer en cualquier lugar de la regla.
El caso de uso más común para una colección de reglas es definir múltiples reglas Sigma para eventos similares, como Windows Security EventID 4688 y Sysmon EventID 1. Ambos eventos aparecen como resultado de la creación del proceso, simplemente tienen diferentes fuentes. La colección de reglas Sigma para un escenario determinado puede contener tres documentos de acción:
- Un documento de acción global que define campos de metadatos e indicadores de detección comunes.
- Regla que define el origen del registro de eventos de seguridad de Windows y el evento EventID = 4688.
- Una regla que define el origen del registro de eventos de Windows Sysmon y el evento EventID = 1.
Una solución alternativa podría ser:
- Un documento de acción global que define campos de metadatos comunes.
- Windows Security Event Log ( EventID=4688) .
- Action- repeat, logsource EventID , . 2.
action-
En esta sección, detallaremos exactamente cómo Sigma genera reglas de resumen basadas en los valores del atributo de acción. Los documentos YAML que contienen un atributo de acción con el valor global se consideran documentos globales dentro de este archivo y sus campos se agregarán a todos los demás documentos.
Nota : si el documento actual contiene el atributo de acción con el valor de restablecimiento, los campos del documento global no se agregarán.
La lógica para trabajar con documentos globales es la siguiente: tan pronto como el analizador encuentra un documento global (un documento que contiene un atributo de acción con el valor global), agrega sus campos a un búfer especial y pasa al siguiente documento. Llamemos a este búfer especial GLOBALYAML, será de ayuda en el futuro referirse a él en los diagramas.
Importante: Dado que los límites del documento están definidos por la marca “---”, es importante colocar estas marcas correctamente en el archivo.
En el siguiente ejemplo, el primer documento YAML contiene un atributo de acción con el valor global. Los límites de este documento se extienden hasta la primera marca de documento. Por lo tanto, todo el primer documento se escribe en el búfer global. Los campos de este búfer se agregan luego a cada documento posterior. Como resultado, obtenemos dos reglas en la salida. Esquema 1. Procesamiento de una regla simple con la definición correcta de las etiquetas del documento YAML Pero si elimina u olvida la primera etiqueta, todos los campos del DOCUMENTO YAML 2 se incluirán en el documento global. Como resultado, obtenemos solo una regla con un conjunto incorrecto de identificadores de búsqueda en la salida. Por lo tanto, es muy importante etiquetar correctamente los documentos YAML en tales reglas compuestas.
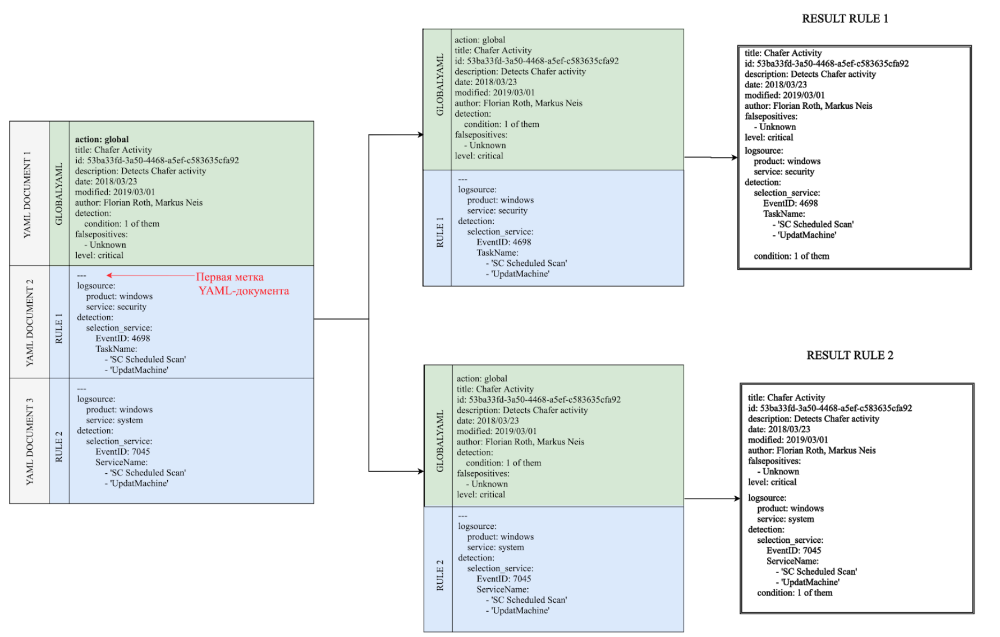

Esquema 2. Procesamiento de la regla anterior: si olvida poner la primera etiqueta del documento YAML
Debe tenerse en cuenta que el documento global no necesariamente viene al principio. Si observa los dos esquemas anteriores, entonces no siempre es YAML DOCUMENT 1. Además, no tiene por qué estar en singular. El siguiente diagrama ilustra esto claramente. Esquema 3. Procesamiento de una regla que contiene varias opciones para configurar un documento YAML global Por lo tanto, hemos considerado los problemas relacionados con la ubicación correcta de las etiquetas del documento YAML. También vimos que puede configurar el documento YAML global de diferentes formas usando el atributo action con el valor global. A continuación, veamos el esquema para transformar una regla utilizando los dos valores restantes del atributo de acción: restablecer y repetir.


Esquema 4. Procesamiento de una regla que contiene los atributos de acción con los valores de reinicio y repetición
¿Qué más hay que decir sobre el proyecto Sigma?
Sigma no es solo un conjunto de reglas formateadas que cubrimos en esta serie.
En nuestras publicaciones, nos enfocamos en describir el formato y la sintaxis de las reglas. Pero las reglas son solo la mitad del proyecto, la segunda son los backends utilizados por el convertidor sigmac. Convencionalmente, estos convertidores se pueden considerar como "adaptadores" con una entrada universal y una salida específica. Es la presencia de tales "adaptadores" lo que hace que el formato de descripción universal sea tan útil. En esta situación, no importa cuál de los sistemas compatibles utilice, Sigma le permite describir la idea y el algoritmo de detección, mientras que uno u otro backend para el convertidor sigmac es responsable de la sintaxis específica del sistema de destino y el mapeo de campos.
Sin embargo, no asuma que al descargar las reglas y convertirlas en la sintaxis del sistema de destino requerido, resolverá todos los problemas asociados con llenar su sistema con experiencia. Discutiremos brevemente por qué Sigma no es una solución lista para usar en este momento y por qué es necesario comprender la sintaxis de las reglas.
Desafíos actuales de Sigma
Sigma es un proyecto en desarrollo activo y, como cualquier proyecto en crecimiento, Sigma tiene sus propios desafíos. Personalmente, los percibo como puntos de desarrollo y áreas de crecimiento. Bueno, dado que este es un proyecto de código abierto, unir fuerzas puede hacer una contribución significativa al desarrollo de ciertas partes del proyecto. Enumeraré lo que en este momento me refiero a las principales llamadas del framework:
- . .
- , Windows- (. ). , .
- Wiki , . .
- experimental — , .
- .
- , .
Por mi propia experiencia, diré que cuando me familiaricé con el proyecto Sigma y participé en OSCD, el primer elemento de la lista resultó ser el más significativo. Resultó que las diferencias entre la sintaxis en MaxPatrol SIEM y en Sigma no terminan solo con la semántica de palabras clave y el diseño de reglas de correlación. Algunas de nuestras ideas no se pueden describir en términos de sintaxis Sigma, ya que en esta etapa no hay posibilidad de correlación de eventos. El mecanismo de correlación le permite buscar valores comunes de campos de eventos y relacionar dichos eventos entre sí. Esto es útil cuando queremos establecer con precisión la relación entre eventos. Por ejemplo, para rastrear eventos dentro de una sesión de usuario. Para hacer esto, necesita vincular eventos por el valor del campo LogonID o su equivalente.
Cabe señalar que las detecciones puntuales o las detecciones basadas en eventos no directamente relacionados se describen con mucho éxito utilizando Sigma.
Una forma de ayudar a abordar estos y otros problemas es participar activamente en uno de los Sprints de OSCD. Y como hay muchas tareas, todo el mundo puede encontrar algo que le interese.
Próximamente nuevo sprint, únete a nosotros
Expresamos nuestro agradecimiento a los organizadores del primer sprint por la conducción de alta calidad del evento y la actitud atenta hacia los participantes. ¿Cuáles son las únicas postales personalizadas que se rellenan a mano y se envían a cada participante? Por nuestra parte, planeamos seguir participando en nuevos sprints y hacer una contribución factible al repositorio Sigma.
Después de leer nuestra serie de artículos y familiarizarse con el formato de las reglas, podrá aplicar su experiencia en beneficio de toda la comunidad de seguridad de la información.
Asegúrate de unirte al segundo sprint. Participe individualmente y forme equipos, ¡hagamos el mundo más seguro juntos!
Contactos de la iniciativa OSCD:
Autor : Anton Kutepov, especialista del departamento de servicios expertos y desarrollo de Tecnologías Positivas (PT Expert Security Center)