
Introducción
Hay muchos concursos en aprendizaje automático, así como las plataformas en las que se realizan, para todos los gustos. Pero no tan a menudo el tema del concurso es el lenguaje humano y su procesamiento, incluso con menos frecuencia una competencia de este tipo se asocia con el idioma ruso. Recientemente participé en un concurso de traducción automática chino-ruso en la plataforma ML Boot Camp de Mail.ru. No teniendo mucha experiencia en programación competitiva, y habiendo pasado, gracias a la cuarentena, todas las vacaciones de mayo en casa, logré tomar el primer lugar. Intentaré hablar de esto, así como de los idiomas y la sustitución de una tarea por otra en el artículo.
Capítulo 1. Nunca hables chino
Los autores de esta competencia propusieron crear un sistema de traducción automática de propósito general, ya que la traducción incluso de grandes empresas en un par chino-ruso está significativamente por detrás de los pares más populares. Pero dado que la validación tuvo lugar en noticias y ficción, quedó claro que era necesario aprender del corpus de noticias y libros. La métrica para evaluar las transferencias fue la BLEU estándar . Esta métrica compara la traducción humana con la traducción automática y, en términos generales, en función del número de coincidencias encontradas, estima la similitud de los textos en una escala de 100 puntos. El idioma ruso es rico en su morfología, por lo tanto, esta métrica siempre es notablemente más baja cuando se traduce a él que a idiomas con menos formas de formación de palabras (por ejemplo, lenguas romances: francés, italiano, etc.).
Cualquiera que se ocupe del aprendizaje automático sabe que se trata principalmente de datos y su limpieza. Comencemos a buscar corpus y, en paralelo, entenderemos los límites de la traducción automática. Entonces, con una capa blanca ...
Capítulo 2. Pon Tiy Pi Lat
En una capa blanca con un forro ensangrentado, un paso de caballería arrastrando los pies, nos subimos a un motor de búsqueda detrás de un cuerpo paralelo ruso-chino. Como entenderemos más adelante, lo que hemos encontrado no es suficiente, pero por ahora echemos un vistazo a nuestros primeros hallazgos (recopilé los conjuntos de datos que encontré, los limpié y los puse en el dominio público [1] ):
OPUS es un corpus bastante grande y lingüísticamente diverso, veamos ejemplos de él:
"Lo que ella y yo hemos experimentado es incluso más inusual que lo que tú has experimentado ..."
我 与 她 的 经历 比 你 的 经历 离奇 多 了
"Te lo contaré".
我 给 你 讲讲 这段 经历 ...
" El pequeño pueblo donde nací ... "
我 出生 那座 小镇 ...
Como sugiere el nombre, en su mayoría son subtítulos para películas y series de televisión. Los subtítulos TED pertenecen al mismo tipo , que, después del análisis y la limpieza, también se convierten en un corpus completamente paralelo:
Así resultó nuestro experimento histórico de castigo:WikiMatrix son textos alineados con LASER de páginas de Internet (el llamado rastreo común ) en varios idiomas, pero para nuestra tarea hay pocos y se ven extraños:
这 就是 关于 我们 印象 中 的 惩戒 措施 的 不为人知 的 一面 los
jóvenes temen que en cualquier momento puedan ser detenidos, registrados, detenidos.
年轻人 总是 担心 随时 会 被 截停、 搜身 和 逮捕
Y no solo en la calle, sino también en sus propias casas,
无论 是 在 街上 还是 在家
Zbranki (ucranianoDespués de la primera etapa de recuperación de datos, surge una pregunta con nuestro modelo. ¿Cuáles son las herramientas y cómo abordar la tarea?
但 被 其 否认。 ¡
Pero será mejor que ayunes, si lo supieras!
斋戒 对于 你们 更好 , 如果 你们 知道。
Rechazó esta afirmación
后来 这个 推论 被 否认
Hay un curso de PNL que me gustó mucho de MIPT en Stepic [2] , que es especialmente útil cuando estás en línea, donde los sistemas de traducción automática también se entienden en los seminarios y los escribes tú mismo. Recuerdo la alegría de que la red, escrita desde cero, después de estudiar en Colab, produjera una traducción adecuada al ruso en respuesta al texto alemán. Construimos nuestros modelos sobre la arquitectura de transformadores con un mecanismo de atención, que en un momento se convirtió en una idea revolucionaria [3] .
Naturalmente, el primer pensamiento fue "simplemente proporcione al modelo diferentes datos de entrada" y gane. Pero, como cualquier alumno chino sabe, no hay espacios en la escritura china y nuestro modelo acepta conjuntos de tokens como entrada, que son palabras en él. Las bibliotecas como jieba pueden descomponer el texto chino en palabras con cierta precisión. Al incorporar la tokenización de palabras en el modelo y ejecutarlo en los cuerpos encontrados, obtuve un BLEU de aproximadamente 0.5 (y la escala es de 100 puntos).
Capítulo 3. Traducción automática y exposición
Se propuso una línea de base oficial (solución de ejemplo simple pero funcional) para la competencia, que se basó en OpenMNT . Es una herramienta de aprendizaje de traducción de código abierto con muchos hiperparámetros para torcer. En este paso, entrenemos e inferenciamos el modelo a través de él. Entrenaremos en la plataforma kaggle, ya que brinda 40 horas de entrenamiento GPU gratis [4] .
Cabe señalar que en este momento había tan pocos participantes en la competencia que, habiendo ingresado, uno podía ingresar de inmediato entre los cinco primeros, y había razones para eso. El formato de la solución era un contenedor docker, en el que se montaban carpetas durante el proceso de inferencia, y el modelo tenía que leer de uno y poner la respuesta en otro. Como la línea de base oficial no comenzó (yo personalmente no la ensamblé de inmediato) y no tenía pesos, decidí recopilar la mía propia y ponerla en el dominio público [5]. Después de eso, los participantes comenzaron a postularse con una solicitud para ensamblar correctamente una solución y, en general, ayudar con la ventana acoplable. Moraleja, los contenedores son el estándar en el desarrollo actual, utilícelos, orquesta y simplifique su vida (no todos están de acuerdo con la última afirmación).
Agreguemos ahora un par más a los cuerpos encontrados en el paso anterior:
- Corpus paralelo de las Naciones Unidas (más de 3 millones de filas)
- UM-Corpus: A Large English-Chinese Parallel Corpus (News subcorpora) (450K líneas)
El primero es un enorme corpus de documentos legales de reuniones de la ONU. Está disponible, por cierto, en todos los idiomas oficiales de esta organización y está alineado según las propuestas. El segundo es aún más interesante, ya que es directamente un corpus de noticias con una peculiaridad: es chino-inglés. Este hecho no nos molesta, porque la traducción automática moderna del inglés al ruso es de muy alta calidad y se utilizan Amazon Translate, Google Translate, Bing y Yandex. Para completar, mostraremos ejemplos de lo que sucedió.
Documentos de la ONU
.
它是一个低成本平台运转寿命较长且能在今后进一步发展。
.
报告特别详细描述了由参加者自己拟订的若干与该地区有关并涉及整个地区的项目计划。
UM-Corpus
Facebook cerró el trato para comprar Little Eye Labs a principios de enero.
1 月初 脸 书 完成 了 对 Little Eye Labs 的 收购 ,
Cuatro ingenieros en Bangalore lanzaron Little Eye Labs hace aproximadamente un año y medio.
一年 半 以前 四位 工程师 在 班加罗尔 创办 了 La
empresa crea herramientas de software para aplicaciones móviles, trato costará entre $ 10 y $ 15 millones.
该 公司 开发 移动 应用 软件 工具 , 这次 交易 价值 1000 到 1500 万 美元 ,
Entonces, nuestros nuevos ingredientes: OpenNMT + carcasas de alta calidad + BPE (puede leer sobre la tokenización de BPE aquí ). Entrenamos, montamos en un contenedor y después de depurar / limpiar y trucos estándar, obtenemos BLEU 6.0 (la escala sigue siendo de 100 puntos).
Capítulo 4. Los manuscritos paralelos no se queman
Hasta este momento, hemos ido mejorando nuestro modelo paso a paso, y la mayor ganancia ha venido del uso del corpus de noticias, uno de los dominios de validación. Además de las noticias, sería bueno tener un cuerpo de literatura. Después de haber pasado una buena cantidad de tiempo, quedó claro que las traducciones automáticas de libros chinos sin un sistema popular no pueden proporcionar: Nastasia se convierte en algo como Nostosi Filipauny y Rogozhin : Rogo Wren . Los nombres de los personajes suelen representar un porcentaje bastante grande de todo el trabajo y, a menudo, estos nombres son raros, por lo tanto, si el modelo nunca los ha visto, lo más probable es que no pueda traducirlos correctamente. Debemos aprender de los libros.
Aquí reemplazamos la tarea de traducción con la tarea de alineación del texto. Debo decir de inmediato que esta parte me gustó más, porque a mí mismo me gusta estudiar idiomas y textos paralelos de libros e historias, en mi opinión, esta es una de las formas más productivas de aprender. Hubo varias ideas para la alineación, la más productiva resultó ser traducir oraciones en espacio vectorial y calcular la distancia coseno entre candidatos para una coincidencia. Traducir algo en vectores se llama incrustación, en este caso es una incrustación de oraciones . Hay varias bibliotecas buenas para este propósito [6] . Al visualizar el resultado, se puede ver que el texto chino se desliza un poco debido a que las oraciones complejas en ruso a menudo se traducen como dos o tres en chino.
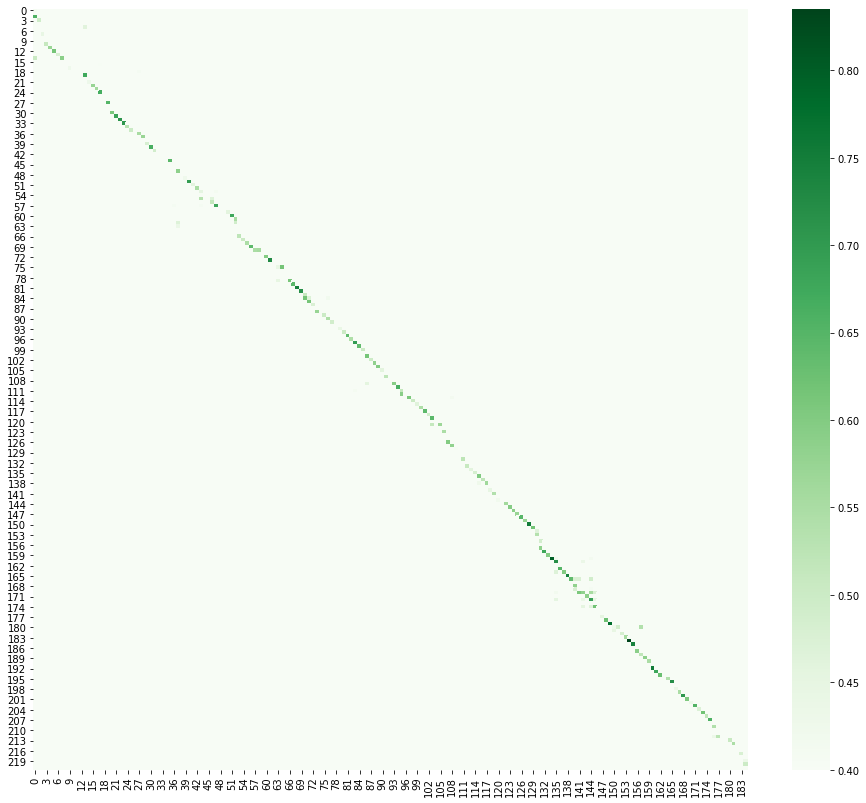
Habiendo encontrado todo lo que es posible en Internet, y nivelando los libros nosotros mismos, los agregamos a nuestro corpus.
Llevaba un traje gris caro y extranjero, en los zapatos del color del traje.
他 的 穿 一身 昂贵 灰色 西装, 脚上 外国 皮鞋 的 也 与 颜色 西装 十分 协调.
Gray lo lleva famoso en la oreja, bajo el brazo, llevando un bastón con un negro una perilla en
forma de caniche .
Parece tener más de cuarenta años.
看 模样 年纪 在 四十 开外。
Después de la capacitación sobre el nuevo edificio, BLEU creció a 20 en un conjunto de datos públicos y a 19,7 en uno privado. También jugó un papel en el hecho de que los trabajos de validación obviamente entraron en el entrenamiento. En realidad, esto nunca debe hacerse, se llama fuga y la métrica deja de ser indicativa.
Conclusión
La traducción automática ha recorrido un largo camino desde la heurística y los métodos estadísticos hasta las redes neuronales y los transformadores. Me alegro de haber podido encontrar el tiempo para familiarizarme con este tema, definitivamente merece mucha atención por parte de la comunidad. ¡Me gustaría agradecer a los autores del concurso y otros participantes por la interesante comunicación y las nuevas ideas!
[1] Corpus paralelo ruso-chino
[2] Curso de procesamiento del lenguaje natural de MIPT
[3] Artículo innovador La atención es todo lo que necesita
[4] Computadora portátil con un ejemplo de aprendizaje en kaggle
[5] Línea de base de Docker pública
[6] Biblioteca para oraciones multilingües incrustaciones