Introducción
¡Hola, Habr!
A muchas personas les gustó la parte anterior, así que volví a recoger la mitad de la documentación de boost y encontré algo sobre lo que escribir. Es muy extraño que no haya tanta emoción en boost.compute como en boost.asio. Después de todo, es suficiente que esta biblioteca sea multiplataforma, también proporciona una interfaz conveniente (dentro del marco de c ++) para interactuar con la computación paralela en la GPU y la CPU.
Todas las partes
- Parte 1
- Parte 2
Contenido
- Operaciones asincrónicas
- Funciones personalizadas
- Comparación de la velocidad de diferentes dispositivos en diferentes modos.
- Conclusión
Operaciones asincrónicas
¿Parecería mucho más rápido? Una forma de acelerar su trabajo con contenedores en el espacio de nombres informático es utilizar funciones asincrónicas. Boost.compute nos proporciona varias herramientas. De estas, la clase compute :: future para controlar el uso de funciones y las funciones copy_async (), fill_async () para copiar o llenar la matriz. Por supuesto, también existen herramientas para trabajar con eventos, pero no es necesario considerarlas. El siguiente será un ejemplo del uso de todo lo anterior:
auto device = compute::system::default_device();
auto context = compute::context::context(device);
auto queue = compute::command_queue(context, device);
std::vector<int> vec_std = {1, 2, 3};
compute::vector<int> vec_compute(vec_std.size(), context);
compute::vector<int> for_filling(10, context);
int num_for_fill = 255;
compute::future<void> filling = compute::fill_async(for_filling.begin(),
for_filling.end(), num_for_fill, queue); //
compute::future<void> copying = compute::copy_async(vec_std.begin(),
vec_std.end(), vec_compute.begin(), queue); //
filling.wait();
copying.wait();
No hay nada especial que explicar aquí. Las primeras tres líneas son la inicialización estándar de las clases requeridas, luego dos vectores para copiar, un vector para llenar, cuya variable llenará el vector anterior y directamente las funciones para llenar y copiar, respectivamente. Luego esperamos su ejecución.
Para aquellos que trabajaron con std :: future de STL, todo es absolutamente igual aquí, solo que en un espacio de nombres diferente y no hay un análogo de std :: async ().
Funciones personalizadas para cálculos
En la parte anterior, dije que explicaré cómo usar mis propios métodos para procesar un conjunto de datos. Conté 3 formas de hacer esto: use una macro, use make_function_from_source <> () y use un marco especial para expresiones lambda.
Comenzaré con la primera opción: una macro. Primero adjuntaré un código de muestra y luego explicaré cómo funciona.
BOOST_COMPUTE_FUNCTION(float,
add,
(float x, float y),
{ return x + y; });
El primer argumento es el tipo de valor de retorno, luego el nombre de la función, sus argumentos y el cuerpo de la función. Además, bajo el nombre add, esta función se puede usar, por ejemplo, en la función compute :: transform (). El uso de esta macro es muy similar a una expresión lambda regular, pero he comprobado que no funcionarán.
El segundo y probablemente el más difícil método es muy similar al primero. Miré el código de la macro anterior y resultó que usa el segundo método.
compute::function<float(float)> add = compute::make_function_from_source<float(float)>
("add", "float add(float x, float y) { return x + y; }");
Aquí todo es más obvio de lo que podría parecer a primera vista, la función make_function_from_source () usa solo dos argumentos, uno de los cuales es el nombre de la función y el segundo es su implementación. Después de declarar una función, se puede usar de la misma manera que después de una implementación de macro.
Bueno, la última opción es un marco de expresión lambda. Ejemplo de uso:
compute::transform(com_vec.begin(),
com_vec.end(),
com_vec.begin(),
compute::_1 * 2,
queue);
Como cuarto argumento, indicamos que queremos multiplicar cada elemento del primer vector por 2, todo es bastante simple y se hace en su lugar.
Las expresiones booleanas se pueden especificar de la misma forma. Por ejemplo, en el método compute :: count_if ():
std::vector<int> source_std = { 1, 2, 3 };
compute::vector<int> source_compute(source_std.begin() ,source_std.end(), queue);
auto counter = compute::count_if(source_compute.begin(),
source_compute.end(),
compute::lambda::_1 % 2 == 0,
queue);
Por lo tanto, hemos contado todos los números pares en la matriz, el contador será igual a uno.
Comparación de la velocidad de diferentes dispositivos en diferentes modos.
Bueno, lo último sobre lo que me gustaría escribir en este artículo es una comparación de la velocidad de procesamiento en diferentes dispositivos y en diferentes modos (solo para la CPU). esta comparación demostrará cuándo tiene sentido usar GPU para computación y computación paralela en general.
Lo probaré así: usando compute para todos los dispositivos, llame a la función compute :: sort () para ordenar una matriz de 100 millones de valores flotantes. Para probar el modo de un solo subproceso, llame a std :: sort en una matriz del mismo tamaño. Para cada dispositivo, anotaré el tiempo en milisegundos usando la biblioteca estándar del cronógrafo y enviaré todo a la consola.
El resultado es el siguiente:

Ahora haré lo mismo solo para mil valores. Esta vez el tiempo será en microsegundos.

Esta vez, el procesador en modo de subproceso único se adelantó a todos. De esto concluimos que vale la pena realizar este tipo de operación solo cuando se trata de datos realmente grandes.
Me gustaría hacer algunas pruebas más, así que hagamos una prueba para calcular el coseno, la raíz cuadrada y el cuadrado.
Al calcular el coseno, la diferencia es muy grande (la GPU funciona 60 veces más rápido que la CPU en un hilo).
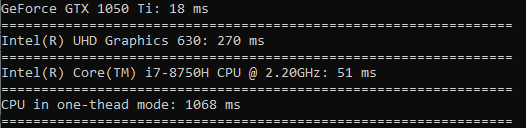
La raíz cuadrada se calcula casi a la misma velocidad que la clasificación.
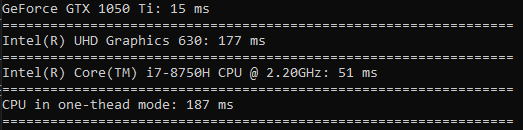
El tiempo empleado en cuadrar es una diferencia incluso menor que en ordenar (la GPU es solo 3,5 veces más rápida).

Conclusión
Entonces, después de leer este artículo, aprendió a usar funciones asincrónicas para copiar matrices y llenarlas. Aprendimos de qué manera puede usar sus propias funciones para realizar cálculos sobre datos. Y también vio claramente cuándo vale la pena usar una GPU o CPU para computación paralela, y cuándo puede arreglárselas con un hilo.
Me encantaría recibir comentarios positivos, ¡gracias por tu tiempo!
¡Buena suerte a todos!