1 ¿Qué es el manuscrito Voynich?
El manuscrito Voynich es un manuscrito misterioso (códice, manuscrito o simplemente un libro) en unas buenas 240 páginas que nos llegó, presumiblemente, del siglo XV. El manuscrito fue adquirido accidentalmente de un anticuario por el esposo del famoso escritor carbonario Ethel Voynich, Wilfred Voynich, en 1912 y pronto se convirtió en propiedad del público en general.
El idioma del manuscrito aún no se ha determinado. Varios investigadores del manuscrito sugieren que el texto del manuscrito está encriptado. Otros están seguros de que el manuscrito fue escrito en un idioma que no ha sobrevivido en los textos que conocemos hoy. Otros consideran que el manuscrito Voynich es una tontería (ver el himno moderno al absurdo Codex Seraphinianus ).
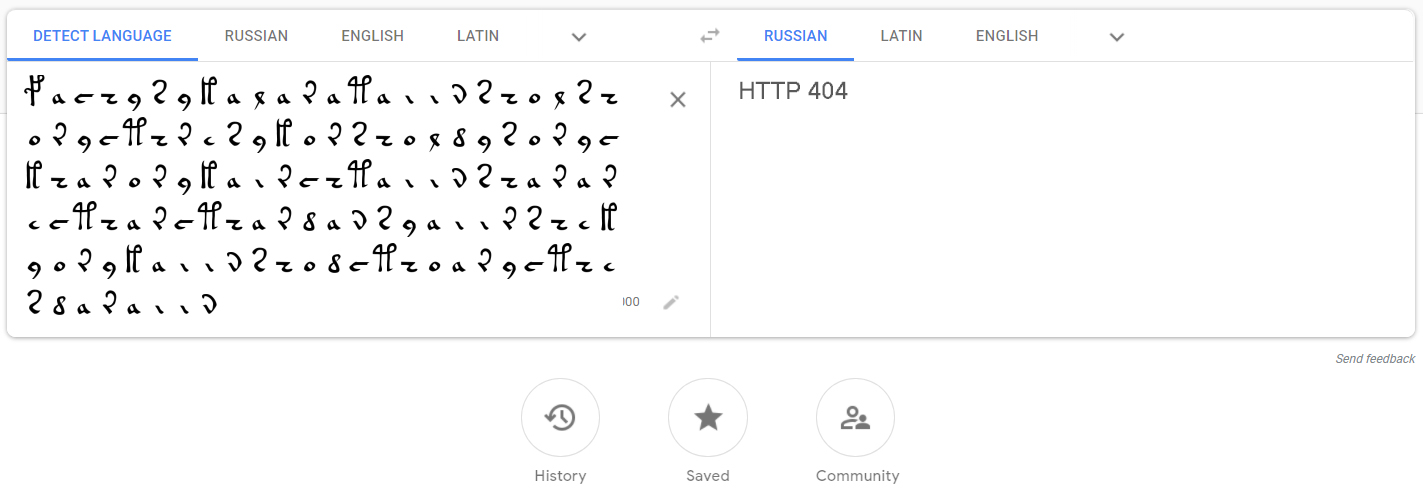
Como ejemplo, daré un fragmento escaneado de un sujeto con texto y ninfas:

2 ¿Por qué es tan interesante este extravagante manuscrito?
¿Quizás esto sea una falsificación tardía? Aparentemente no. A diferencia de la Sábana Santa de Turín, ni el análisis de radiocarbono ni otros intentos de disputar la antigüedad del pergamino han dado una respuesta inequívoca. Pero Voynich no podría haber previsto el análisis de isótopos a principios del siglo XX ...
Pero, ¿y si el manuscrito es un conjunto de cartas sin sentido de la pluma de un monje juguetón, un noble con una conciencia alterada? No, definitivamente no. Golpeando sin pensar las teclas, yo, por ejemplo, representaré el ruido blanco del teclado QWERTY modulado familiar de todos, como " asfds dsf”. Un examen grafológico muestra que el autor escribió con mano firme los símbolos del alfabeto que conocía bien. Además, las correlaciones de la distribución de letras y palabras en el texto del manuscrito corresponden al texto “vivo”. Por ejemplo, en un manuscrito, dividido condicionalmente en 6 secciones, hay palabras: "endémica", que a menudo se encuentran en una de las secciones, pero ausentes en otras.
Pero, ¿qué pasa si el manuscrito es un cifrado complejo y los intentos de descifrarlo no tienen sentido teóricamente? Si asumimos con fe la venerable edad del texto, la versión encriptada es extremadamente improbable. La Edad Media solo podría haber ofrecido un cifrado de sustitución, que Edgar Allan Poe rompió con tanta facilidad y elegancia . Nuevamente, la correlación de letras y palabras del texto no es típica de la gran mayoría de cifrados.
A pesar de los colosales éxitos en la traducción de escrituras antiguas, incluso con el uso de recursos informáticos modernos, el manuscrito Voynich todavía desafía a los lingüistas profesionales experimentados o a los jóvenes científicos de datos ambiciosos.
3 Pero, ¿y si conocemos el idioma del manuscrito?
... pero la ortografía es diferente? ¿Quién, por ejemplo, reconoce el latín en este texto ?

Y aquí hay otro ejemplo: la transliteración de un texto en inglés al griego:
in one of the many little suburbs which cling to the outskirts of london
ιν ονε οφ θε μανυ λιττλε συμπυρμπσ whιχ cλιγγ το θε ουτσκιρτσ οφ λονδονBiblioteca transliterada de Python . NB: esto ya no es un cifrado de sustitución: algunas combinaciones de varias letras se transmiten en una letra y viceversa.
Intentaré identificar (clasificar) el idioma del manuscrito, o encontrar el pariente más cercano a él de los idiomas conocidos, resaltando los rasgos característicos y entrenando el modelo en ellos:
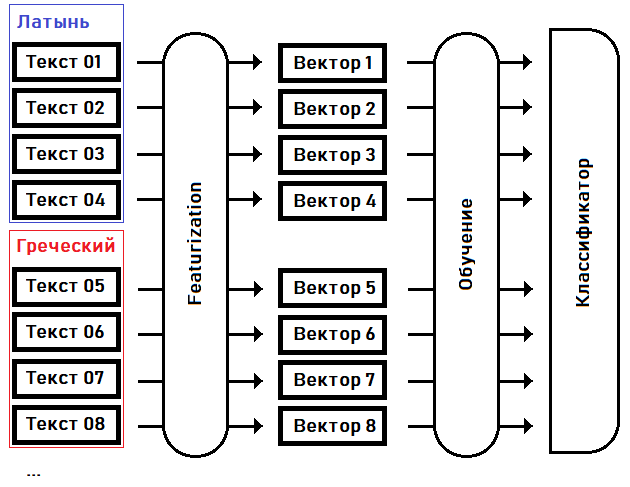
En la primera etapa - caracterización- convertimos textos en vectores de características: matrices de números reales de tamaño fijo, donde cada dimensión del vector es responsable de su propia característica especial (característica) del texto fuente. Por ejemplo, pongamos de acuerdo en la decimoquinta dimensión del vector para mantener la frecuencia de uso de la palabra más común en el texto, en la decimosexta dimensión - la segunda palabra más popular ... en la enésima dimensión - la longitud máxima de una secuencia de la misma palabra repetida, etc.
En el segundo paso, la formación , seleccionamos los coeficientes del clasificador en función del conocimiento previo del idioma de cada uno de los textos.
Una vez que el clasificador está entrenado, podemos usar este modelo para determinar el idioma del texto que no se incluyó en la muestra de entrenamiento. Por ejemplo, para el texto del manuscrito Voynich.
4 La imagen es tan simple: ¿cuál es el truco?
La parte complicada es cómo convertir exactamente un archivo de texto en un vector. Separando el trigo de la paja y dejando solo aquellas características que son propias del idioma en su conjunto, y no cada texto específico.
Si, para simplificar, convierte los textos de origen en codificación (es decir, números) y "alimenta" estos datos como están a uno de los muchos modelos de redes neuronales, el resultado probablemente no nos complacerá. Lo más probable es que un modelo entrenado con tales datos esté vinculado al alfabeto y es sobre la base de símbolos que, en primer lugar, intentará determinar el idioma de un texto desconocido.
Pero el alfabeto del manuscrito "no tiene análogos". Además, no podemos confiar plenamente en patrones en la distribución de letras. Teóricamente, también es posible transferir la fonética de un idioma por las reglas de otro (el idioma es élfico y las runas son Mordor).
El astuto escriba no usó signos de puntuación ni números como los conocemos. El texto completo se puede considerar como un flujo de palabras dividido en párrafos. Ni siquiera hay certeza sobre dónde termina una oración y comienza otra.
Esto significa que subiremos a un nivel superior en relación con las letras y nos apoyaremos en las palabras. Compilaremos un diccionario basado en el texto del manuscrito y trazaremos los patrones ya a nivel de palabra.
5 Texto original del manuscrito
Por supuesto, no es necesario que codifique los intrincados caracteres del manuscrito de Voynich en sus equivalentes Unicode y viceversa; este trabajo ya se ha realizado para nosotros, por ejemplo, aquí . Con las opciones predeterminadas, obtengo el siguiente equivalente a la primera línea del manuscrito:
fachys.ykal.ar.ataiin.shol.shory.cth!res.y.kor.sholdy!-Los puntos y los signos de exclamación (así como una serie de otros símbolos del alfabeto EVA ) son solo separadores, que para nuestros propósitos pueden reemplazarse con espacios. Los signos de interrogación y los asteriscos son palabras / letras no reconocidas.
Para verificación, sustituyamos el texto aquí y obtengamos un fragmento del manuscrito:
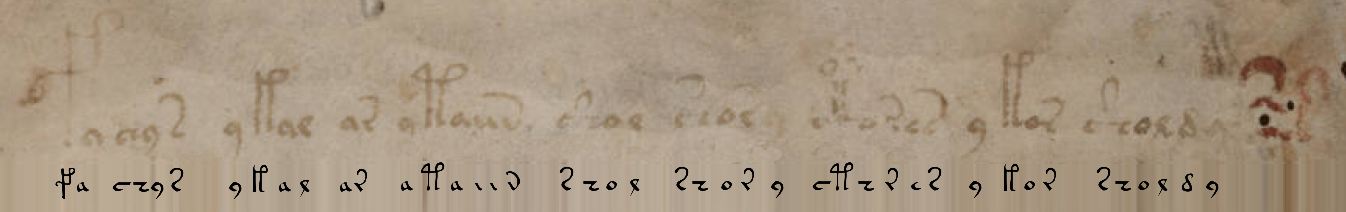
6 Programa - clasificador de texto (Python)
Aquí hay un enlace al repositorio de código con las sugerencias mínimas README que necesita para probar el código en acción.
Recopilé más de 20 textos en latín, ruso, inglés, polaco y griego, tratando de mantener el volumen de cada texto en ± 35,000 palabras (el volumen del manuscrito Voynich).
Intenté seleccionar citas cercanas en los textos, en una ortografía; por ejemplo, en los textos en ruso evité la letra Ѣ, y las variantes de escribir letras griegas con diferentes diacríticos llevaron a un denominador común. También eliminé números, especiales de los textos. caracteres, espacios extra, letras convertidas a un caso.
El siguiente paso es crear un "diccionario" que contenga información como:
- frecuencia de uso de cada palabra en el texto (textos),
- La "raíz" de una palabra, o más bien, una parte común e inmutable de un conjunto de palabras,
- "prefijos" y "finales" comunes - o más bien, el principio y el final de las palabras, junto con la "raíz" que constituye las palabras reales,
- secuencias comunes de 2 y 3 palabras idénticas y la frecuencia de su aparición.
Tomé la "raíz" de la palabra entre comillas: un algoritmo simple (y a veces yo mismo) no es capaz de determinar, por ejemplo, ¿cuál es la raíz de la palabra soporte? ¿Al convertirme en ka? ¿Bajo la tasa ?
En términos generales, este vocabulario son datos a medio preparar para construir un vector de características. ¿Por qué seleccioné esta etapa: compilar y almacenar en caché diccionarios para textos individuales y para un conjunto de textos para cada uno de los idiomas? El hecho es que la creación de un diccionario de este tipo lleva mucho tiempo, aproximadamente medio minuto para cada archivo de texto. Y ya tengo más de 120 archivos de texto.
7 Caracterización
La obtención de un vector de características es solo una etapa preliminar para una mayor magia del clasificador. Como un fanático de la programación orientada a objetos, por supuesto, creé una clase BaseFeaturizer abstracta para la lógica ascendente, para no violar el principio de inversión de dependencia . Esta clase lega a los descendientes poder transformar uno o varios archivos de texto a la vez en vectores numéricos.
Además, la clase heredera debe dar un nombre a cada característica individual (coordenada i del vector de característica). Esto será útil si decidimos visualizar la lógica de la máquina de la clasificación. Por ejemplo, la dimensión 0 del vector se marcará como CRw1: autocorrelación de la frecuencia del uso de palabras tomadas del texto en la posición adyacente (con un retraso de 1).
De la clase BaseFeaturizer, heredé la claseWordMorphFeaturizer , cuya lógica se basa en la frecuencia del uso de palabras a lo largo del texto y dentro de una ventana deslizante de 12 palabras.
Un aspecto importante es que el código de un sucesor específico de BaseFeaturizer, además de los textos en sí, también necesita diccionarios preparados en base a ellos (la clase CorpusFeatures ), que probablemente ya estén almacenados en caché en disco en el momento del inicio del entrenamiento y prueba del modelo.
8 Clasificación
La siguiente clase abstracta es BaseClassifier . Este objeto se puede entrenar y luego clasificar los textos por sus vectores de características.
Para la implementación (la clase RandomForestLangClassifier ) elegí el algoritmo Random Forest Classifier de la biblioteca sklearn . ¿Por qué este clasificador en particular?
- El clasificador de bosque aleatorio me convenía con sus parámetros predeterminados,
- no requiere la normalización de los datos de entrada,
- ofrece una visualización sencilla e intuitiva del algoritmo de toma de decisiones.
Dado que, en mi opinión, Random Forest Classifier hizo frente a su tarea, no he escrito ninguna otra implementación.
9 Entrenamiento y pruebas
El 80% de los archivos, grandes fragmentos de las obras de Byron, Aksakov, Apuleius, Pausanias y otros autores, cuyos textos pude encontrar en formato txt, fueron seleccionados al azar para entrenar al clasificador. El 20% restante (28 archivos) se determina para pruebas fuera de muestra.
Si bien probé el clasificador en ~ 30 textos en inglés y 20 en ruso, el clasificador arrojó un gran porcentaje de errores: en casi la mitad de los casos, el idioma del texto se determinó incorrectamente. Pero cuando comencé ~ 120 archivos de texto en 5 idiomas (ruso, inglés, latín, griego antiguo y polaco), el clasificador dejó de cometer errores y comenzó a reconocer correctamente el idioma de 27 a 28 archivos de 28 casos de prueba.
Luego compliqué un poco el problema: transcribí la novela irlandesa del siglo XIX "Rachel Gray" al griego y la entregué a un clasificador capacitado. El idioma del texto en transliteración fue nuevamente definido correctamente.
10 El algoritmo de clasificación es claro
Así es como se ve uno de los 100 árboles en el Clasificador de bosque aleatorio entrenado (para que la imagen sea más legible, corté 3 nodos del subárbol derecho):
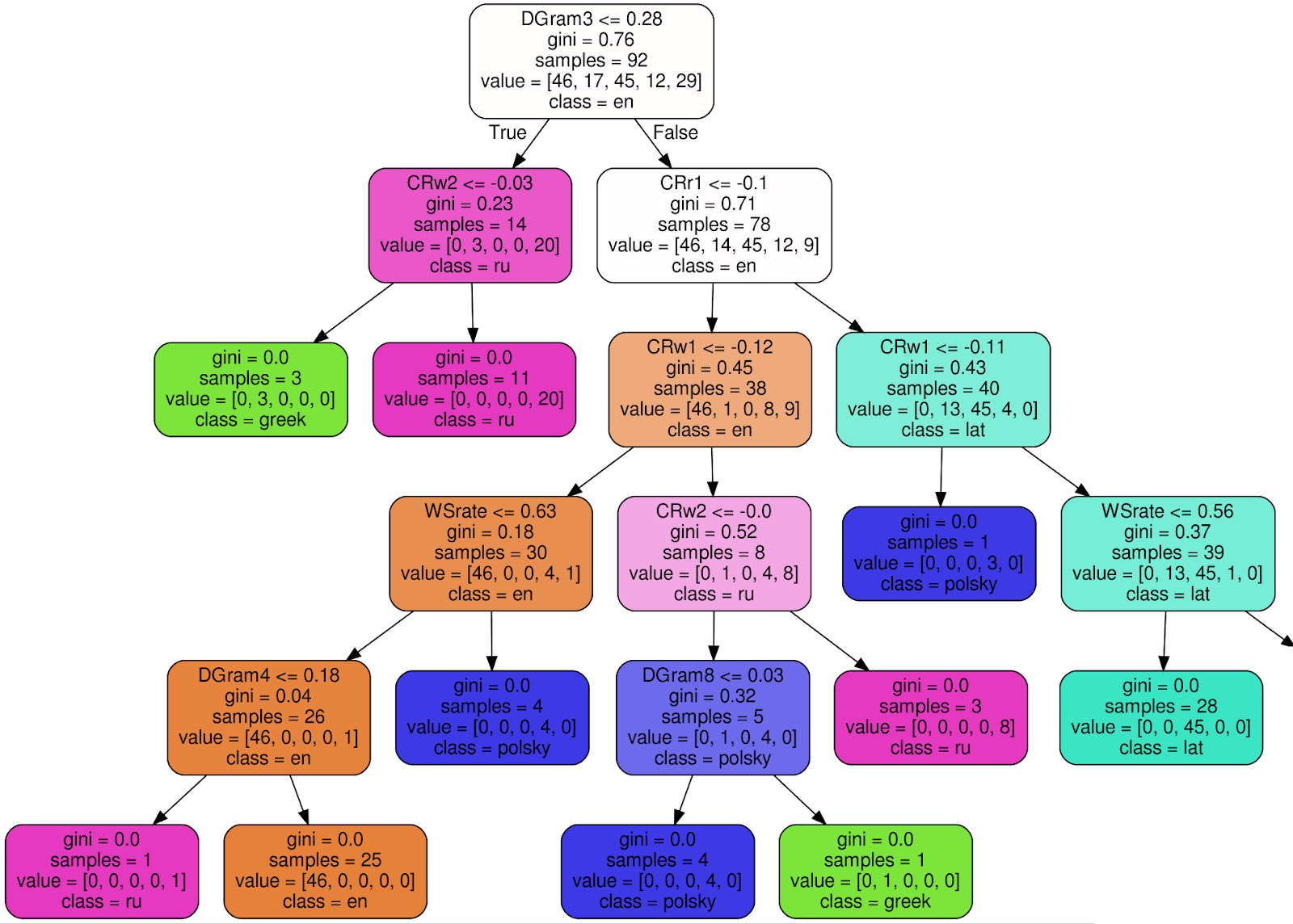
Usando el nodo raíz como ejemplo , explicaré el significado de cada firma:
- DGram3 <= 0,28 - criterio de clasificación. En este caso, DGram3 es una dimensión específica de un vector de características nombrado por la clase WordMorphFeaturizer, es decir, la frecuencia de la tercera palabra más común en una ventana deslizante de 12 palabras,
- gini = 0.76 — , Gini impurity, , , . , , - . . , gini, , 0 ( ),
- samples = 92 — , ,
- value = [46, 17, 45, 12, 29] — , (46 , 17 , 45 ..),
- class = en ( ) — .
Si se cumple el criterio (DGram3 <= 0.28 para el nodo raíz), vaya al subárbol izquierdo, de lo contrario, a la derecha. En cada hoja, todos los textos deben asignarse a una clase (idioma) y el criterio de incertidumbre de Gini ≡ 0. La
decisión final la toma un conjunto de 100 árboles similares construidos durante el entrenamiento del clasificador.
11 ¿Y cómo definió el programa el idioma del manuscrito?
Latín , estimación de probabilidad 0,59. Y, por supuesto, esta aún no es la solución al problema del siglo.
Una correspondencia uno a uno entre los diccionarios del manuscrito y el idioma latino es difícil, si no imposible. Por ejemplo, aquí hay diez de las palabras utilizadas con más frecuencia: manuscritos de Voynich, latín,

griego antiguo y ruso: el
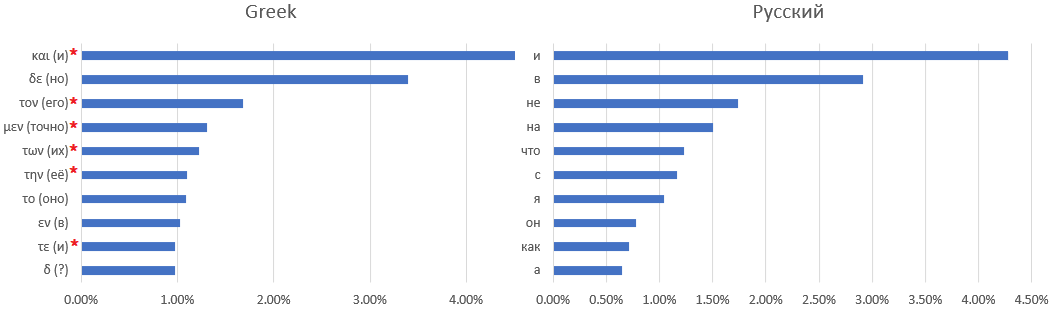
asterisco marca palabras que son difíciles de encontrar un equivalente ruso, por ejemplo, artículos o preposiciones que cambian de significado según el contexto.
Una coincidencia obvia como
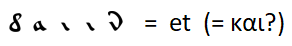
con la extensión de las reglas para reemplazar letras con otras palabras de uso frecuente, no pude encontrar. Solo puede hacer suposiciones, por ejemplo, la palabra más común es la conjunción "y", como en todos los demás idiomas considerados, excepto el inglés, en el que la conjunción "y" fue empujada al segundo lugar por el artículo definido "el".
¿Que sigue?
Primero, vale la pena intentar complementar la muestra de idiomas con textos en francés moderno, español, ..., idiomas del Medio Oriente, si es posible: inglés antiguo, idiomas franceses (antes del siglo XV) y otros. Incluso si ninguno de estos idiomas es el idioma del manuscrito, la precisión de la definición de idiomas conocidos seguirá aumentando, y probablemente se seleccionará un equivalente más cercano al idioma del manuscrito.
Un desafío más creativo es tratar de definir una parte del discurso para cada palabra. Para varios idiomas (por supuesto, en primer lugar, inglés), los tokenizadores de PoS (parte del habla) como parte de los paquetes disponibles para descargar funcionan bien con esta tarea. Pero, ¿cómo determinar los roles de las palabras en un idioma desconocido?
Problemas similares fueron resueltos por el lingüista soviético B.V. Sukhotin, por ejemplo, describió los algoritmos:
- separación de caracteres de un alfabeto desconocido en vocales y consonantes; desafortunadamente, no es 100% confiable, especialmente para idiomas con fonética no trivial, como el francés,
- selección de morfemas en el texto sin espacios.
Para la tokenización de PoS, podemos comenzar con la frecuencia del uso de palabras, la aparición en combinaciones de 2/3 palabras, la distribución de palabras en secciones del texto: las uniones y partículas deben distribuirse de manera más uniforme que los sustantivos.
Literatura
No dejaré aquí enlaces a libros y tutoriales sobre PNL, eso es suficiente en la red. En cambio, enumeraré obras de arte que se convirtieron en un gran hallazgo para mí cuando era niño, donde los héroes tuvieron que trabajar duro para desentrañar los textos cifrados:
- E. A. Poe: The Golden Beetle es un clásico atemporal
- V. Babenko: "Meeting" es una famosa historia de detectives retorcida y algo visionaria de finales de los 80,
- K. Kirita: “Caballeros de la calle Chereshnevaya, o el castillo de la niña de blanco” es una novela adolescente fascinante, escrita sin descuento para la edad del lector.