Google: Google: el 90% de nuestros ingenieros usan un programa que usted escribió (Homebrew), pero usted no se puede invertir un árbol binario en un tablero, así que adiós.
Aunque nunca tuve la necesidad de invertir un árbol binario, encontré ejemplos de uso real de estructuras de datos y algoritmos en mi trabajo diario cuando trabajaba en Skype / Microsoft, Skyscanner y Uber . Esto incluyó la codificación y la toma de decisiones basadas en los detalles de las estructuras de datos y los algoritmos. Pero yo, en su mayor parte, utilicé el conocimiento relevante para comprender cómo se crearon ciertos sistemas y por qué se crearon de esa manera. El conocimiento de los conceptos relevantes facilita la comprensión de la arquitectura y la implementación de los sistemas en los que se utilizan estos conceptos.

En este artículo, he incluido historias sobre situaciones en las que se han utilizado estructuras de datos como árboles y gráficos, así como varios algoritmos, en proyectos reales. Aquí espero mostrar al lector que un conocimiento básico de estructuras de datos y algoritmos no es una teoría inútil necesaria solo para entrevistas, sino algo que es muy probable que sea realmente necesario para alguien que trabaja en empresas de tecnología innovadora de rápido crecimiento.
Aquí hablaremos de una cantidad muy pequeña de algoritmos, pero en lo que respecta a las estructuras de datos, puedo señalar que abordaré casi todos ellos aquí. No debería sorprender a nadie que no sea un fanático del tipo de preguntas de entrevista que enfatizan demasiado los algoritmos que están fuera de contacto con la práctica y se dirigen a estructuras de datos exóticas como árboles rojo-negro o árboles AVL. Nunca he hecho tales preguntas en entrevistas y no las haré. Al final de este artículo, compartiré mis pensamientos sobre tales entrevistas. Pero a pesar de lo anterior, el conocimiento de las estructuras de datos subyacentes es de inmenso valor. Este conocimiento le permite seleccionar exactamente lo que se necesita para resolver ciertos problemas prácticos.
Pasemos ahora a ejemplos de uso de estructuras de datos y algoritmos en la vida real.
Árboles y cruce de árboles: marcos de Skype, Uber y UI
Cuando estábamos desarrollando Skype para Xbox One, el código tenía que escribirse para un sistema operativo Xbox puro que no tenía las bibliotecas que necesitábamos. Desarrollamos una de las primeras aplicaciones completas para esta plataforma. Necesitábamos un sistema de navegación de aplicaciones que pudiera operarse usando la pantalla táctil y dando comandos de voz a la aplicación.
Hemos creado un marco de navegación básico basado en WinJS. Para hacer esto, necesitábamos mantener un gráfico tipo DOM, que era necesario para organizar la observación de los elementos con los que el usuario podía interactuar. Para encontrar dichos elementos, realizamos un recorrido DOM, que se redujo al recorrido del árbol, es decir, la estructura existente de los elementos DOM. Este es un ejemplo clásico de BFS o DFS (búsqueda en amplitud o búsqueda en profundidad: búsqueda en amplitud o búsqueda en profundidad).
Si está haciendo desarrollo web, esto significa que ya está trabajando con una estructura de árbol, es decir, el DOM. Todos los nodos DOM pueden tener nodos secundarios. El navegador muestra nodos en la pantalla después de atravesar el árbol DOM. Si necesita encontrar un elemento específico, puede utilizar los métodos DOM integrados para resolver este problema. Por ejemplo, el método getElementById. Una alternativa es desarrollar su propia solución BFS o DFS para atravesar los nodos y encontrar lo que necesita. Por ejemplo, aquí se hace algo similar .
Muchos marcos que representan elementos de la interfaz de usuario utilizan estructuras de árbol en su profundidad. Entonces, React admite DOM virtual y usa un algoritmo de reconciliación inteligente(comparaciones). Esto le permite lograr un alto rendimiento debido al hecho de que solo se vuelven a renderizar las partes cambiadas de la interfaz. Puede encontrar una visualización de este proceso aquí.
En arquitectura móvil Uber, RIB, también se utilizan árboles. Esto hace que esta arquitectura sea similar a la mayoría de los otros marcos de interfaz de usuario que muestran estructuras jerárquicas de elementos. La arquitectura de RIB mantiene un árbol RIB para fines de gestión de estado. Adjuntar RIB y separarlos controla su renderizado. Mientras trabajamos con RIB, a veces hicimos un bosquejo, tratando de entender si los RIB encajan en la jerarquía existente, y discutimos si los RIB en cuestión deberían tener elementos visibles. Es decir, hablaron sobre si esta estructura participará en la formación de la presentación visual de la interfaz, o se utilizará solo para la gestión estatal.

Transiciones de estado al usar RIB. Puede encontrar más detalles sobre los RIB aquí.Si
alguna vez necesita renderizar elementos jerárquicos, tenga en cuenta que las estructuras de árbol se utilizan normalmente para esto, atravesándolas y renderizando los elementos visitados. Me he encontrado con muchas herramientas internas que adoptan este enfoque. Un ejemplo de una herramienta de este tipo es el renderizador de RIB creado por el equipo de Plataforma Móvil en Uber. Aquí hay un informe sobre este tema.
Gráficos ponderados y buscador de ruta más corta: Skyscanner
Skyscanner es un proyecto que tiene como objetivo encontrar las mejores ofertas en boletos aéreos. La búsqueda de tales propuestas se realiza visualizando y analizando todas las rutas existentes en el mundo y combinándolas. La esencia de esta tarea está más relacionada con la recopilación automática de datos por parte de un robot de búsqueda, y no con el almacenamiento en caché de todos estos datos, ya que las aerolíneas calculan de forma independiente el tiempo de espera para el próximo vuelo. Pero la posibilidad de planificar un viaje para visitar varias ciudades se reduce a la tarea de encontrar el camino más corto.
La planificación de viajes en varias ciudades fue una de las posibilidades que Skyscanner tardó en implementar. Al mismo tiempo, las dificultades se relacionan principalmente con el propio sistema que se está desarrollando. Las mejores ofertas de este tipo se encuentran utilizando algoritmos de ruta más corta como Dijkstra o A *. Las rutas de vuelo se presentan en forma de gráfico dirigido. A cada uno de sus bordes se le asigna un peso en forma de precio de entrada. Al buscar la mejor ruta, la búsqueda de la ruta más barata entre dos ciudades se realiza mediante la implementación del algoritmo A * modificado . Si está interesado en el tema de seleccionar boletos de avión y encontrar las rutas más cortas, aquí hay un buen artículo sobre el uso de BFS para resolver tales problemas.
Sin embargo, en el caso de Skyscanner, qué algoritmo se utilizó para resolver el problema no fue particularmente importante. Almacenar en caché, usar robots de búsqueda, organizar el trabajo con varios sitios, todo esto fue mucho más difícil que elegir un algoritmo. Pero al mismo tiempo, surgen diferentes variantes del problema de encontrar el camino más corto en muchas empresas de planificación de viajes diferentes y optimizar el costo de dichos viajes. Como era de esperar, este tema también ha sido objeto de charlas entre bastidores en Skyscanner.
Tipo: Skype (o algo así)
Rara vez tuve una razón para implementar algoritmos de clasificación yo mismo o para estudiar profundamente las complejidades de su estructura. A pesar de esto, fue interesante comprender cómo funcionan estos algoritmos, desde la clasificación de burbujas, la clasificación por inserción, la clasificación por fusión y la clasificación por selección, hasta el algoritmo más complejo: clasificación rápida. Descubrí que rara vez es necesario implementar dichos algoritmos, especialmente si no necesita escribir una función de clasificación que sea parte de una biblioteca.
En Skype, sin embargo, tuve que recurrir al uso práctico de mis conocimientos de algoritmos de clasificación. Uno de nuestros programadores decidió implementar la clasificación por inserciones para mostrar contactos. En 2013, cuando Skype estaba en línea, los contactos se descargaban en lotes. Me llevó algún tiempo descargarlos todos. Como resultado, ese programador pensó que sería mejor crear una lista de contactos ordenados por nombre usando el orden de inserción. Hablamos mucho de este algoritmo, pensando en por qué no usar algo que ya se ha implementado. Como resultado, nos tomó más tiempo probar adecuadamente nuestra implementación del algoritmo y verificar su rendimiento. Personalmente, no veía mucho sentido en crear mi propia implementación de este algoritmo. Pero entonces el proyecto estaba en tal etapadonde teníamos tiempo para esas cosas.
Por supuesto, hay situaciones reales en las que la clasificación eficiente juega un papel muy importante en un proyecto. Y si el desarrollador puede de forma independiente, según las características de los datos, elegir el algoritmo más adecuado, esto puede dar un aumento notable en el rendimiento de la solución. La ordenación por inserción puede ser muy útil cuando trabaja con grandes conjuntos de datos transmitidos en algún lugar en tiempo real y visualiza inmediatamente estos datos. Merge Sort puede funcionar bien para enfoques de dividir y conquistar cuando se trata de grandes cantidades de datos almacenados en diferentes nodos. Nunca he trabajado con tales sistemas, así que por ahora sigo considerando la clasificación de algoritmos como algo que tiene un uso limitado en el trabajo diario. Es verdad,no se trata de la importancia de comprender cómo funcionan los diferentes algoritmos de clasificación.
Tablas hash y hash: en todas partes
La estructura de datos que utilizo habitualmente es una tabla hash. Esto también incluye funciones hash. Esta es una herramienta muy útil que se puede usar para resolver una variedad de tareas, desde contar el número de ciertas entidades, detectar duplicados, almacenar en caché, hasta escenarios como la fragmentación utilizada en sistemas distribuidos . Las tablas hash son, después de las matrices, la estructura de datos más común en programación. Lo he usado en innumerables situaciones. Está presente en casi todos los lenguajes de programación y, si es necesario, puede implementarlo usted mismo.
Pilas y colas: de vez en cuando
Una pila es una estructura de datos familiar para cualquiera que tenga código depurado escrito en un lenguaje que admita seguimientos de pila. Si hablamos de la pila como una estructura de datos, entonces, en el curso del trabajo, encontré varios problemas para cuya solución se necesitaba. Pero debe tenerse en cuenta que llegué a conocer las pilas correctamente mientras depuraba y perfilaba el rendimiento del código. Las pilas también son una opción natural para que la estructura de datos utilice al realizar DFS.
Rara vez tuve que recurrir al uso de colas, pero las encontré con bastante frecuencia en las bases de código de varios proyectos. Digamos que se colocó algo en la cola y se recuperó algo de ella. Por lo general, las colas se utilizan para implementar el recorrido del árbol en amplitud, y son ideales para esta tarea. Las colas también se pueden utilizar en muchas otras situaciones. Un día me encontré con un código de programación de trabajos en el que encontré un ejemplo de un uso decente de la cola de prioridad implementada por el módulo heapq Python , cuando los trabajos más cortos se ejecutaron primero.
Algoritmos criptográficos: Uber
Los datos importantes que los usuarios ingresan en aplicaciones móviles o aplicaciones web deben estar encriptados antes de transmitirse a través de la red. Y los descifran solo donde se necesitan. Para organizar tal esquema de trabajo, la implementación de algoritmos criptográficos debe estar presente en las partes cliente y servidor de las aplicaciones.
Comprender los algoritmos criptográficos es muy interesante. Al mismo tiempo, no debe ofrecer sus propios algoritmos para resolver ciertos problemas. Esta es una de las peores ideas que puede pensar un programador. En su lugar, toma un estándar existente y bien documentado y utiliza las primitivas integradas de los respectivos marcos. Por lo general, AES actúa como el estándar elegido al implementar soluciones criptográficas.... Es lo suficientemente seguro como para usarlo para cifrar información clasificada en los Estados Unidos . No se conocen ataques operativos al protocolo. AES-192 y AES-256 suelen ser bastante fiables para la mayoría de las tareas prácticas.
Cuando llegué a Uber, el sistema de encriptación móvil y el sistema de encriptación para la aplicación web ya estaban implementados, se basaban en los mecanismos anteriores, por lo que tuve una excusa para estudiar los detalles sobre AES (Advanced Encryption Standard), sobre HMAC (Hashed Message Authentication Codes) , sobre el algoritmo RSA y otras cosas similares. También fue interesante comprender cómo se prueba la fuerza criptográfica de la secuencia de acciones utilizadas en el cifrado. Por ejemplo, si hablamos de encriptación autenticada con datos adjuntos, resulta que al analizar los modos encriptar y MAC, MAC-luego-encriptar y encriptar-luego-MAC, es posible probar la fuerza criptográfica de solo uno de ellos , aunque esto no significa que el resto no es criptográficamente seguro.
Casi nunca necesitará implementar primitivas criptográficas usted mismo, a menos que esté implementando un marco criptográfico completamente nuevo. Pero es posible que se enfrente a la necesidad de tomar decisiones sobre qué primitivas utilizar y cómo combinarlas. También es posible que necesite conocimientos en el campo de los algoritmos criptográficos para comprender por qué un determinado sistema utiliza un determinado enfoque para el cifrado de datos.
Árboles de decisión: Uber
Mientras trabajábamos en uno de los proyectos, tuvimos que implementar una lógica empresarial compleja en una aplicación móvil. Es decir, en base a media docena de reglas, tenía que mostrarse una de varias pantallas. Estas reglas eran muy complejas porque los resultados de la secuencia de prueba y la preferencia del usuario debían tenerse en cuenta.
El programador que comenzó a resolver este problema primero intentó expresar todas estas reglas en forma de declaraciones if-else. Esto resultó en un código extremadamente confuso. Como resultado, se decidió utilizar el árbol de decisiones. Con su ayuda, fue fácil realizar todos los controles necesarios. Fue relativamente fácil de implementar. Además, si es necesario, se podría cambiar sin mucho problema. Necesitábamos crear nuestra propia implementación del árbol de decisiones, de modo que las condiciones se verifiquen en sus bordes. Esto es todo lo que necesitamos de este árbol. Si bien podríamos haber ahorrado el tiempo invertido en implementar el árbol adoptando un enfoque diferente, el equipo decidió que el árbol en particular sería más fácil de mantener y se puso a trabajar. Este árbol se ve así:los bordes simbolizan los resultados de verificar las condiciones (estos son resultados binarios, o los resultados representados por rangos de valores), y los nodos de hoja del árbol describen las pantallas a las que necesita navegar.
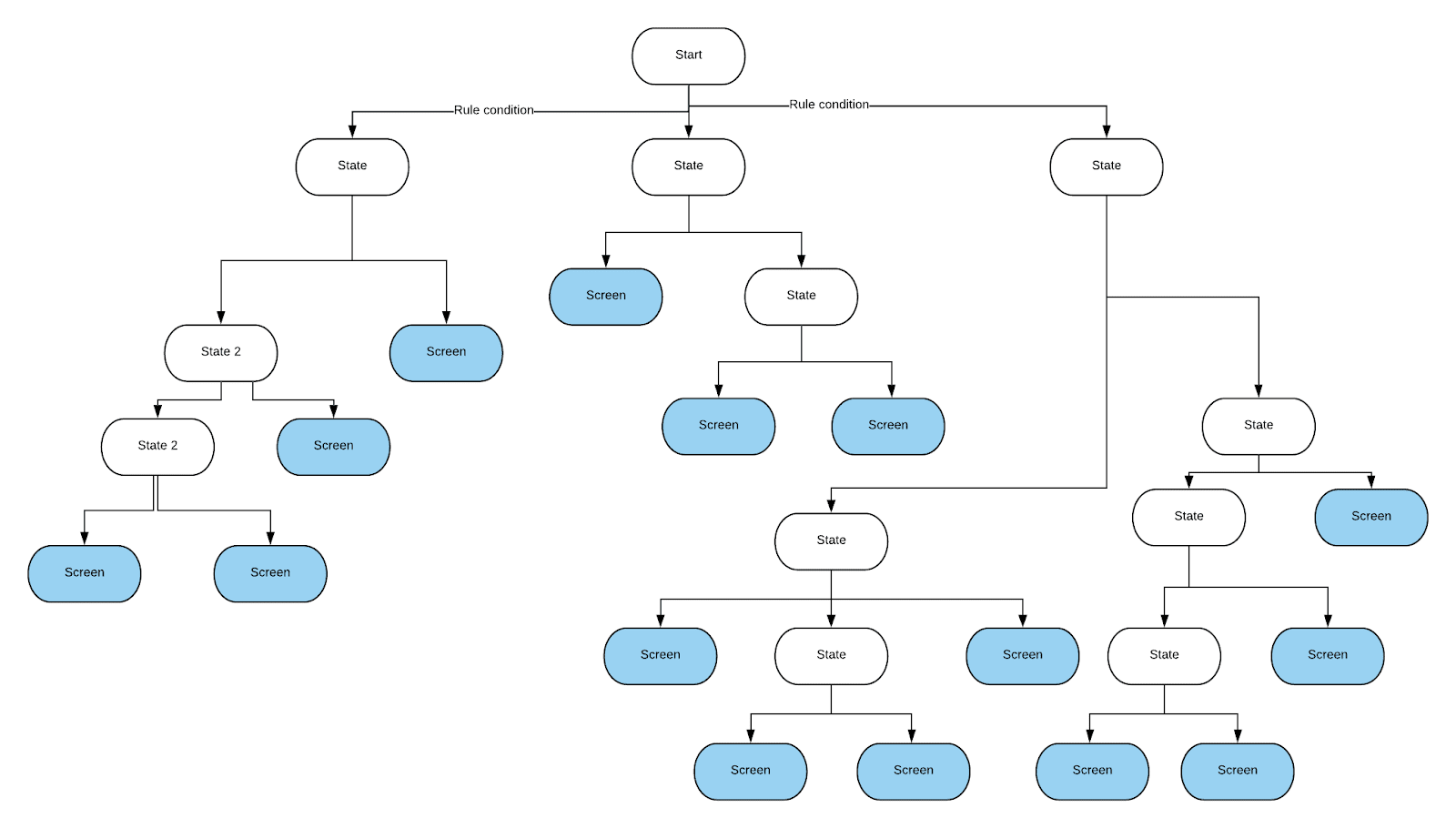
, , .
El sistema de compilación de la aplicación móvil de Uber, llamado SubmitQueue, también usó un árbol de decisiones, pero se generó dinámicamente. El equipo de Developer Experience tuvo que abordar el difícil problema de realizar una combinación diaria de cientos de ramas de origen con la rama de destino. Al mismo tiempo, cada montaje tardó unos 30 minutos en completarse. Esto incluyó la compilación, ejecución de pruebas de integración y unidad, y pruebas de interfaz. La puesta en paralelo de ensamblajes no era una solución suficientemente buena, ya que a menudo había cambios superpuestos en diferentes ensamblajes, lo que provocaba conflictos de fusión. En la práctica, esto significaba que a veces los programadores tenían que esperar de 2 a 3 horas, recurrir a la reorganización y reiniciar el proceso de fusión nuevamente, esperando que esta vez no enfrentaran un conflicto.
El equipo de Developer Experience adoptó un enfoque innovador para predecir los conflictos de fusión y los ensamblajes de cola en consecuencia. Esto se hizo utilizando un árbol de decisión binario especial (árbol de especulación).

SubmitQueue utiliza un árbol de decisión binario con bordes anotados con probabilidades predichas. Este enfoque le permite determinar qué conjuntos de ensamblajes se pueden ejecutar en paralelo. Esto se hace para acortar el tiempo entre la recepción y la ejecución de tareas y para aumentar el rendimiento del sistema. En este caso, solo el código completamente probado y viable debe ingresar a la rama
maestra.El equipo de Experiencia de Desarrollador que creó este sistema ha escrito material excelente alrespecto. Pero aqui- otro artículo sobre el mismo tema, bien ilustrado. El resultado de la introducción de este sistema fue la creación de un sistema de montaje de proyectos mucho más rápido que antes. Nos permitió optimizar el tiempo de construcción de los proyectos y ayudó a facilitar la vida de cientos de programadores móviles.
Cuadrículas hexagonales, índices jerárquicos: Uber
Este es el último proyecto del que quiero hablar aquí. Se basó completamente en una estructura de datos en particular. Al hacerlo, aprendí sobre esta estructura de datos. Estamos hablando de una cuadrícula hexagonal con índices jerárquicos.
Uno de los problemas más desafiantes e interesantes de Uber fue la optimización del costo de viaje y la distribución de pedidos entre socios. Las tarifas de los viajes pueden cambiar dinámicamente, los conductores están en constante movimiento. Los ingenieros de Uber crearon el sistema de red H3. Está diseñado para visualizar y analizar datos en ciudades a diferentes escalas. La estructura de datos que se utiliza para resolver los problemas anteriores es una cuadrícula hexagonal con índices jerárquicos. Se utilizan un par de herramientas internas especializadas para visualizar los datos.

División del mapa en celdas hexagonales
Esta estructura de datos tiene su propio sistema de indexación, recorrido, sus propias definiciones de áreas individuales de la cuadrícula, sus propias funciones. Una descripción detallada de todo esto se puede encontrar en la documentación de la API correspondiente. Lea más sobre H3 aquí . Aquí está el código fuente. Aquí puede encontrar una historia sobre cómo y por qué se creó este sistema.
La experiencia con este sistema me permitió tener una idea del hecho de que crear sus propias estructuras de datos especializadas puede tener sentido al resolver problemas muy específicos. Hay muy pocos problemas en cuya solución se puede aplicar una cuadrícula hexagonal, si no se tiene en cuenta la división en fragmentos de mapa con una comparación con cada fragmento de datos resultante de diferentes niveles. Pero, como en otros casos, si está familiarizado con otras estructuras de datos, será mucho más fácil de entender. Y para una persona que se ha ocupado de una cuadrícula hexagonal, será más fácil crear una nueva estructura de datos diseñada para resolver problemas similares a los que se resuelven utilizando dicha cuadrícula.
Estructuras de datos y algoritmos en entrevistas
Arriba, hablé sobre las estructuras de datos y los algoritmos que encontré mientras trabajaba en varias empresas durante mucho tiempo. Propongo ahora volver a ese tweet de Max Howell, que mencioné al principio del artículo. Allí, Max se quejó de que en una entrevista con Google le pidieron que invirtiera un árbol binario en un tablero. No lo hizo. Le mostraron la puerta. En esta situación, estoy del lado de Max.
Creo que saber cómo funcionan los algoritmos populares, o cómo funcionan las estructuras de datos exóticas, no es el tipo de conocimiento que necesita para trabajar para una empresa de tecnología. Necesita saber qué es un algoritmo, necesita poder idear de forma independiente algoritmos simples, por ejemplo, trabajando en el principio "codicioso". También debe tener conocimiento de las estructuras de datos más comunes, como tablas hash, colas y pilas. Pero algo bastante específico, como el algoritmo de Dijkstra o A *, o algo aún más complejo, no es algo que deba aprenderse de memoria. Si realmente necesita estos algoritmos, puede encontrar fácilmente materiales de referencia sobre ellos. Por ejemplo, si hablamos de algoritmos que no están relacionados con los algoritmos de ordenación, generalmente trato de entenderlos en términos generales y comprender su esencia.Lo mismo ocurre con estructuras de datos exóticas como árboles rojo-negro y árboles AVL. Nunca he tenido la necesidad de usarlos. Y si los necesitaba, siempre podía refrescar mis conocimientos sobre ellos recurriendo a las publicaciones adecuadas. Al entrevistar, como dije, nunca hago tales preguntas y no planeo hacerlas.
Estoy a favor de los problemas prácticos relacionados con la programación, a los que se puede aplicar una variedad de enfoques: desde métodos de "fuerza bruta" y variantes de algoritmos "codiciosos" hasta ideas algorítmicas más avanzadas. Por ejemplo, creo que está perfectamente bien tener una tarea de alineación de texto como esta . Por ejemplo, tuve que resolver este problema al crear un componente para renderizar texto en Windows Phone. Puede resolver este problema simplemente usando una matriz y algunas declaraciones if-else, sin recurrir a estructuras de datos complicadas.
De hecho, muchos equipos y empresas exageran la importancia de los problemas algorítmicos. Entiendo el atractivo de las preguntas del algoritmo. Le permiten evaluar al solicitante en poco tiempo, las preguntas son fáciles de rehacer, lo que significa que si las preguntas que se le hicieron a alguien se hacen públicas, no causará ningún problema especial. Las preguntas de algoritmo son buenas para organizar ensayos para un gran número de solicitantes. Por ejemplo, puede crear un grupo de más de cien preguntas y distribuirlas al azar entre los solicitantes. Las preguntas sobre programación dinámica y estructuras de datos exóticas son cada vez más comunes. Especialmente en Silicon Valley. Estas preguntas pueden ayudar a las empresas a contratar programadores sólidos. Pero estas mismas preguntas pueden cerrar el camino en la empresa a aquellas personas que han tenido éxito en los negocios,donde no se necesita un conocimiento profundo de algoritmos.
Si eres de una empresa que solo contrata personas que tienen un conocimiento profundo de algoritmos complejos casi desde el nacimiento, te sugiero que pienses detenidamente si estas son las personas que necesitas. Por ejemplo, contraté grandes equipos en Skyscanner (Londres) y Uber (Ámsterdam) sin hacer preguntas complicadas sobre algoritmos. Me he limitado a las estructuras de datos más comunes y a probar las capacidades de los entrevistados relacionadas con la resolución de problemas. Es decir, necesitaban conocer las estructuras de datos comunes y poder idear algoritmos simples para resolver los problemas que enfrentan. Las estructuras de datos y los algoritmos son solo herramientas.
En pocas palabras: las estructuras de datos y los algoritmos son herramientas
Si trabaja para una empresa de tecnología dinámica e innovadora, probablemente encontrará implementaciones de una amplia variedad de estructuras de datos y algoritmos en el código de los productos de esta empresa. Si está desarrollando algo completamente nuevo, a menudo debe buscar estructuras de datos que faciliten la resolución de los problemas que enfrenta. En situaciones como esta, necesita un conocimiento general de algoritmos y estructuras de datos y sus pros y contras para tomar la decisión correcta.
Las estructuras de datos y los algoritmos son herramientas que debe utilizar con confianza al escribir programas. Al conocer estas herramientas, verá mucho de lo que ya sabe en las bases de código en las que se utilizan. Además, dicho conocimiento te permitirá resolver problemas complejos con mucha más confianza. Conocerá las limitaciones teóricas de los algoritmos y cómo se pueden optimizar. Esto lo ayudará en última instancia a llegar a una solución que, con todas las compensaciones necesarias, resulte ser lo mejor posible.
Si desea comprender mejor las estructuras de datos y los algoritmos, aquí hay algunos consejos y recursos:
- -, , , , , , . , , . , . — , .
- « ». , , , . — , , . , , , .
- Aquí hay un par de libros más: “ Algoritmos. Guía de desarrollo "y" Algoritmos en Java, 4ª edición ". Los usé para refrescar mis conocimientos universitarios sobre algoritmos. Es cierto que no los he leído hasta el final. Me parecieron más bien secos e inaplicables a mi trabajo diario.
¿Qué estructuras de datos y algoritmos ha encontrado en la práctica?
