
escalabilidad es un requisito clave para las aplicaciones en la nube. Con Kubernetes, escalar una aplicación es tan fácil como aumentar la cantidad de réplicas para una implementación adecuada, o
ReplicaSet, pero es un proceso manual.
Kubernetes permite que las aplicaciones se escalen automáticamente (es decir, pods en implementación o
ReplicaSet) de manera declarativa mediante la especificación del escalador automático de pods horizontal. El criterio predeterminado para el escalado automático son las métricas de utilización de la CPU (métricas de recursos), pero se pueden integrar métricas personalizadas y métricas proporcionadas externamente. Kubernetes aaS
equipo de Mail.rutradujo un artículo sobre cómo utilizar métricas externas para escalar automáticamente su aplicación de Kubernetes. Para mostrar cómo funciona todo, el autor utiliza métricas de solicitud de acceso HTTP, que se recopilan mediante Prometheus.
En lugar de escalar automáticamente los pods de forma horizontal, Kubernetes Event Driven Autoscaling (KEDA) es un operador de Kubernetes de código abierto. Se integra de forma nativa con el escalador automático de pod horizontal para proporcionar un ajuste de escala automático sin problemas (incluido desde / hacia cero) para cargas de trabajo basadas en eventos. El código está disponible en GitHub .
Resumen de funcionamiento del sistema
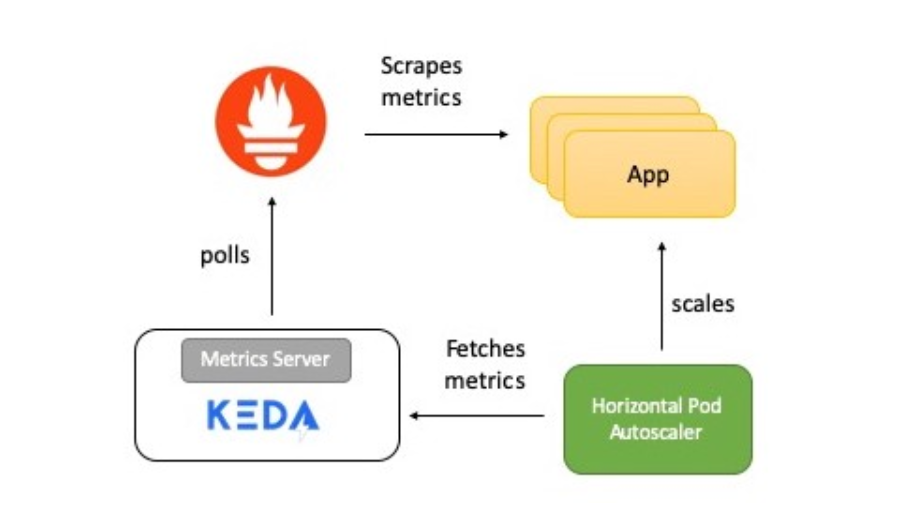
El diagrama muestra una breve descripción de cómo funciona todo:
- La aplicación proporciona métricas para el número de solicitudes HTTP en formato Prometheus.
- Prometheus está configurado para recopilar estas métricas.
- El escalador Prometheus en KEDA está configurado para escalar automáticamente la aplicación en función del número de solicitudes HTTP.
Ahora te contaré en detalle sobre cada elemento.
KEDA y Prometheus
Prometheus es un conjunto de herramientas de monitoreo y alerta de sistemas de código abierto, parte de Cloud Native Computing Foundation . Recopila métricas de diversas fuentes y las guarda como datos de series de tiempo. Para visualizar datos, puede utilizar Grafana u otras herramientas de visualización que funcionan con la API de Kubernetes.
KEDA es compatible con el concepto de escalador: actúa como un puente entre KEDA y el sistema externo. La implementación del escalador es específica para cada sistema de destino y extrae datos de él. KEDA luego los usa para controlar el autoescalado.
Los escaladores admiten múltiples fuentes de datos como Kafka, Redis, Prometheus. Es decir, KEDA se puede utilizar para escalar automáticamente las implementaciones de Kubernetes utilizando métricas de Prometheus como criterio.
Aplicación de prueba
La aplicación de prueba Golang proporciona acceso HTTP y tiene dos funciones importantes:
- Utiliza la biblioteca cliente de Prometheus Go para instrumentar la aplicación y proporcionar la métrica http_requests que contiene un contador de visitas. El punto final para el que están disponibles las métricas de Prometheus se encuentra mediante el URI
/metrics.
var httpRequestsCounter = promauto.NewCounter(prometheus.CounterOpts{ Name: "http_requests", Help: "number of http requests", }) - En respuesta a la solicitud, la
GETaplicación incrementa el valor key (access_count) en Redis. Esta es una manera fácil de hacer el trabajo como parte de un controlador HTTP y también verificar las métricas de Prometheus. El valor de la métrica debe ser el mismo que el valoraccess_counten Redis.
func main() { http.Handle("/metrics", promhttp.Handler()) http.HandleFunc("/test", func(w http.ResponseWriter, r *http.Request) { defer httpRequestsCounter.Inc() count, err := client.Incr(redisCounterName).Result() if err != nil { fmt.Println("Unable to increment redis counter", err) os.Exit(1) } resp := "Accessed on " + time.Now().String() + "\nAccess count " + strconv.Itoa(int(count)) w.Write([]byte(resp)) }) http.ListenAndServe(":8080", nil) }
La aplicación se implementa en Kubernetes a través de
Deployment. También se crea un servicio ClusterIPque permite al servidor de Prometheus recibir métricas de la aplicación.
Aquí está el manifiesto de implementación de la aplicación .
Servidor Prometheus
El manifiesto de implementación de Prometheus consta de:
ConfigMap- para transferir la configuración de Prometheus;Deployment- para implementar Prometheus en un clúster de Kubernetes;ClusterIP- servicio para acceder a UI Prometheus;ClusterRole,ClusterRoleBindingYServiceAccount- para la detección automática de los servicios en Kubernetes (Auto-descubrimiento).
Aquí está el manifiesto para ejecutar Prometheus .
KEDA Prometheus ScaledObject
El escalador actúa como un puente entre KEDA y el sistema externo del que se deben obtener las métricas.
ScaledObjectEs un recurso personalizado, debe implementarse para sincronizar la implementación con el origen del evento, en este caso Prometheus.
ScaledObjectcontiene información de escala de implementación, metadatos de origen de eventos (como secretos de conexión, nombre de cola), intervalo de sondeo, período de recuperación y otra información. Da como resultado el recurso de autoescalado apropiado (definición de HPA) para escalar la implementación.
Cuando
ScaledObjectse elimina un objeto, se borra su correspondiente definición de HPA.
Aquí está la definición
ScaledObjectde nuestro ejemplo, usa un escalador Prometheus:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: default
labels:
deploymentName: go-prom-app
spec:
scaleTargetRef:
deploymentName: go-prom-app
pollingInterval: 15
cooldownPeriod: 30
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: prometheus
metadata:
serverAddress:
http://prometheus-service.default.svc.cluster.local:9090
metricName: access_frequency
threshold: '3'
query: sum(rate(http_requests[2m]))
Considere los siguientes puntos:
- Señala
Deploymentcon un nombrego-prom-app. - Tipo de disparador -
Prometheus. La dirección del servidor de Prometheus se menciona junto con el nombre de la métrica, el umbral y la solicitud de PromQL que se utilizará. Solicitud PromQL -sum(rate(http_requests[2m])). - Según
pollingIntervalKEDA, solicita un objetivo de Prometheus cada quince segundos.minReplicaCountSe admite al menos un pod ( ) y el número máximo de pods no excedemaxReplicaCount(en este ejemplo, diez).
Se puede poner
minReplicaCounta cero. En este caso, KEDA activa una implementación de cero a uno y luego proporciona HPA para un mayor escalamiento automático. También es posible el orden inverso, es decir, escalar de uno a cero. En el ejemplo, no seleccionamos cero porque este es un servicio HTTP y no un sistema bajo demanda.
La magia dentro del autoescalado
El umbral se utiliza como disparador para escalar la implementación. En nuestro ejemplo, la consulta PromQL
sum(rate (http_requests [2m]))devuelve el valor agregado de la tasa de solicitudes HTTP (solicitudes por segundo), medido durante los últimos dos minutos.
Dado que el umbral es tres, habrá uno por debajo siempre que el valor sea
sum(rate (http_requests [2m]))inferior a tres. Si el valor aumenta, se agrega un valor inferior adicional cada vez que sum(rate (http_requests [2m]))aumenta en tres. Por ejemplo, si el valor es de 12 a 14, entonces el número de pods es cuatro.
¡Ahora intentemos configurar!
Preajuste
Todo lo que necesita es un clúster de Kubernetes y una utilidad personalizada
kubectl. Este ejemplo usa un clúster minikube, pero puede usar cualquier otro. Hay una guía para instalar el clúster .
Instale la última versión en Mac:
curl -Lo minikube
https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 \
&& chmod +x minikube
sudo mkdir -p /usr/local/bin/
sudo install minikube /usr/local/bin/
Instale kubectl para acceder a su clúster de Kubernetes.
Instale la última versión en Mac:
curl -LO
"https://storage.googleapis.com/kubernetes-release/release/$(curl -s
https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/darwin/amd64/kubectl"
chmod +x ./kubectl
sudo mv ./kubectl /usr/local/bin/kubectl
kubectl version
Instalación de KEDA
Puede implementar KEDA de varias formas, se enumeran en la documentación . Estoy usando YAML monolítico:
kubectl apply -f
https://raw.githubusercontent.com/kedacore/keda/master/deploy/KedaScaleController.yaml
KEDA y sus componentes se instalan en el espacio de nombres
keda. Comando para comprobar:
kubectl get pods -n keda
Espere, cuando bajo KEDA Operator comienza - va a
Running State. Y luego continúe.
Instalación de Redis con Helm
Si no tiene Helm instalado, use este tutorial . Comando para instalar en Mac:
brew install kubernetes-helm
helm init --history-max 200
helm initinicializa la CLI local y también se instala Tilleren el clúster de Kubernetes.
kubectl get pods -n kube-system | grep tiller
Espere a que el módulo Tiller entre en estado de funcionamiento.
Nota del traductor : el autor utiliza Helm @ 2, que requiere la instalación del componente del servidor Tiller. Helm @ 3 es relevante actualmente, no necesita una parte del servidor.
Después de instalar Helm, un comando es suficiente para iniciar Redis:
helm install --name redis-server --set cluster.enabled=false --set
usePassword=false stable/redis
Verifique que Redis se haya iniciado correctamente:
kubectl get pods/redis-server-master-0
Espere a que Redis entre en estado
Running.
Implementar la aplicación
Comando para el despliegue:
kubectl apply -f go-app.yaml
//output
deployment.apps/go-prom-app created
service/go-prom-app-service created
Comprueba que todo ha comenzado:
kubectl get pods -l=app=go-prom-app
Espere a que Redis cambie al estado
Running.
Implementación del servidor Prometheus
El manifiesto de Prometheus utiliza Kubernetes Service Discovery para Prometheus . Le permite descubrir dinámicamente pods de aplicaciones en función de una etiqueta de servicio.
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_run]
regex: go-prom-app-service
action: keep
Para implementación:
kubectl apply -f prometheus.yaml
//output
clusterrole.rbac.authorization.k8s.io/prometheus created
serviceaccount/default configured
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
configmap/prom-conf created
deployment.extensions/prometheus-deployment created
service/prometheus-service created
Comprueba que todo ha comenzado:
kubectl get pods -l=app=prometheus-server
Espere a que Prometheus entre en estado
Running.
Úselo
kubectl port-forwardpara acceder a la interfaz de usuario de Prometheus (o al servidor API) en http: // localhost: 9090 .
kubectl port-forward service/prometheus-service 9090
Implementar la configuración de ajuste de escala automático de KEDA
Comando para crear
ScaledObject:
kubectl apply -f keda-prometheus-scaledobject.yaml
Verifique los registros del operador KEDA:
KEDA_POD_NAME=$(kubectl get pods -n keda
-o=jsonpath='{.items[0].metadata.name}')
kubectl logs $KEDA_POD_NAME -n keda
El resultado se parece a esto:
time="2019-10-15T09:38:28Z" level=info msg="Watching ScaledObject:
default/prometheus-scaledobject"
time="2019-10-15T09:38:28Z" level=info msg="Created HPA with
namespace default and name keda-hpa-go-prom-app"
Verifique en aplicaciones. Una instancia debería estar ejecutándose porque
minReplicaCountes 1:
kubectl get pods -l=app=go-prom-app
Verifique que el recurso HPA se haya creado correctamente:
kubectl get hpa
Debería ver algo como:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-go-prom-app Deployment/go-prom-app 0/3 (avg) 1 10 1 45s
Chequeo de salud: acceso a la aplicación
Para acceder al punto final REST de nuestra aplicación, ejecute:
kubectl port-forward service/go-prom-app-service 8080
Ahora puede acceder a la aplicación Go utilizando la dirección http: // localhost: 8080 . Para hacer esto, ejecute el comando:
curl http://localhost:8080/test
El resultado se parece a esto:
Accessed on 2019-10-21 11:29:10.560385986 +0000 UTC
m=+406004.817901246
Access count 1
Compruebe Redis en este punto también. Verá que la clave
access_countaumenta a 1:
kubectl exec -it redis-server-master-0 -- redis-cli get access_count
//output
"1"
Asegúrese de que el valor de la métrica
http_requestssea el mismo:
curl http://localhost:8080/metrics | grep http_requests
//output
# HELP http_requests number of http requests
# TYPE http_requests counter
http_requests 1
Creación de carga
Usaremos hey , una utilidad para generar la carga:
curl -o hey https://storage.googleapis.com/hey-release/hey_darwin_amd64
&& chmod a+x hey
También puede descargar la utilidad para Linux o Windows .
Ejecutarlo:
./hey http://localhost:8080/test
De forma predeterminada, la utilidad envía 200 solicitudes. Puede verificar esto utilizando las métricas de Prometheus y Redis.
curl http://localhost:8080/metrics | grep http_requests
//output
# HELP http_requests number of http requests
# TYPE http_requests counter
http_requests 201
kubectl exec -it redis-server-master-0 -- redis-cli get access_count
//output
201
Confirme el valor de la métrica real (devuelto por la consulta PromQL):
curl -g
'http://localhost:9090/api/v1/query?query=sum(rate(http_requests[2m]))'
//output
{"status":"success","data":{"resultType":"vector","result":[{"metric":{},"value":[1571734214.228,"1.686057971014493"]}]}}
En este caso, el resultado real es igual
1,686057971014493y se muestra en el campo value. Esto no es suficiente para escalar, ya que el umbral que establecemos es 3.
¡Más carga!
En la nueva terminal, realice un seguimiento del número de pods de aplicaciones:
kubectl get pods -l=app=go-prom-app -w
Aumentemos la carga usando el comando:
./hey -n 2000 http://localhost:8080/test
Después de un tiempo, verá que HPA escala la implementación y lanza nuevos pods. Verifique la HPA para asegurarse de que:
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-go-prom-app Deployment/go-prom-app 1830m/3 (avg) 1 10 6 4m22s
Si la carga no es constante, la implementación se reducirá hasta el punto en que solo funcione un módulo. Si desea verificar la métrica real (devuelta por la consulta PromQL), use el comando:
curl -g
'http://localhost:9090/api/v1/query?query=sum(rate(http_requests[2m]))'
Limpieza
//Delete KEDA
kubectl delete namespace keda
//Delete the app, Prometheus server and KEDA scaled object
kubectl delete -f .
//Delete Redis
helm del --purge redis-server
Conclusión
KEDA le permite escalar automáticamente sus implementaciones de Kubernetes (a / desde cero) en función de los datos de métricas externas. Por ejemplo, según las métricas de Prometheus, la longitud de la cola en Redis, la latencia del consumidor en el tema Kafka.
KEDA se integra con una fuente externa y también proporciona métricas a través del servidor de métricas para el escalador automático horizontal de pod.
¡Buena suerte!
Qué más leer: