soy el creador de Dependency Injector . Este es un marco de inyección de dependencia para Python.
Esta es la guía definitiva para crear aplicaciones con el inyector de dependencia. Los tutoriales anteriores cubren cómo construir una aplicación web con Flask , REST API con Aiohttp y monitorear un demonio con Asyncio usando la inyección de dependencia.
Hoy quiero mostrar cómo se puede crear una aplicación de consola (CLI).
Además, he preparado respuestas a preguntas frecuentes y publicaré su posdata.
El manual consta de las siguientes partes:
- ¿Qué vamos a construir?
- Preparando el medio ambiente
- Estructura del proyecto
- Instalación de dependencias
- Accesorios
- Envase
- Trabajando con csv
- Trabajando con sqlite
- Selector de proveedores
- Pruebas
- Conclusión
- PD: preguntas y respuestas
El proyecto completo se puede encontrar en Github .
Para empezar debes tener:
- Python 3.5+
- Ambiente virtual
Y es deseable tener una comprensión general del principio de inyección de dependencia.
¿Qué vamos a construir?
Crearemos una aplicación CLI (consola) que busca películas. Llamémoslo Movie Lister.
¿Cómo funciona Movie Lister?
- Tenemos una base de datos de películas
- Se conoce la siguiente información sobre cada película:
- Nombre
- Año de emisión
- Nombre del director
- La base de datos se distribuye en dos formatos:
- Archivo csv
- Base de datos sqlite
- La aplicación busca en la base de datos utilizando los siguientes criterios:
- Nombre del director
- Año de emisión
- Es posible que se agreguen otros formatos de base de datos en el futuro
Movie Lister es una aplicación de muestra utilizada en el artículo de Martin Fowler sobre inyección de dependencia e inversión de control.
Así es como se ve el diagrama de clases de la aplicación Movie Lister:
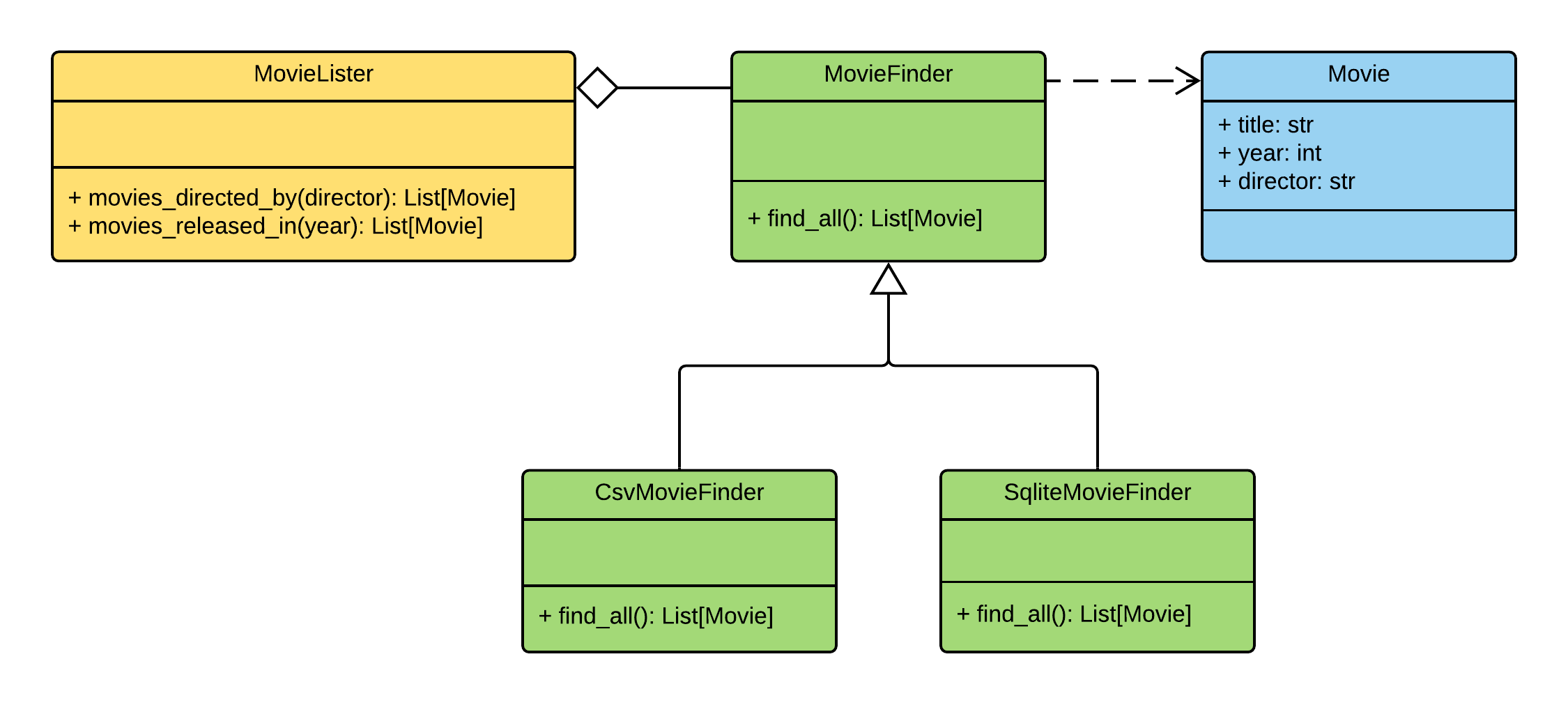
Las responsabilidades entre las clases se distribuyen de la siguiente manera:
MovieLister- responsable de la búsquedaMovieFinder- responsable de extraer datos de la base de datosMovie- clase de entidad "película"
Preparando el medio ambiente
Empecemos por preparar el medio ambiente.
En primer lugar, necesitamos crear una carpeta de proyecto y un entorno virtual:
mkdir movie-lister-tutorial
cd movie-lister-tutorial
python3 -m venv venv
Ahora activemos el entorno virtual:
. venv/bin/activate
El ambiente está listo. Ahora entremos en la estructura del proyecto.
Estructura del proyecto
En esta sección, organizaremos la estructura del proyecto.
Creemos la siguiente estructura en la carpeta actual. Deje todos los archivos vacíos por ahora.
Estructura inicial:
./
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ └── containers.py
├── venv/
├── config.yml
└── requirements.txt
Instalación de dependencias
Es hora de instalar las dependencias. Usaremos paquetes como este:
dependency-injector- marco de inyección de dependenciapyyaml- biblioteca para analizar archivos YAML, utilizada para leer la configuraciónpytest- marco de pruebapytest-cov- biblioteca auxiliar para medir la cobertura del código mediante pruebas
Agreguemos las siguientes líneas al archivo
requirements.txt:
dependency-injector
pyyaml
pytest
pytest-cov
Y ejecutar en la terminal:
pip install -r requirements.txt
La instalación de las dependencias está completa. Pasando a los accesorios.
Accesorios
En esta sección, agregaremos accesorios. Los datos de prueba se denominan accesorios.
Crearemos un script que creará bases de datos de prueba.
Agregue un directorio
data/a la raíz del proyecto y agregue un archivo dentro fixtures.py:
./
├── data/
│ └── fixtures.py
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ └── containers.py
├── venv/
├── config.yml
└── requirements.txt
A continuación, edite
fixtures.py:
"""Fixtures module."""
import csv
import sqlite3
import pathlib
SAMPLE_DATA = [
('The Hunger Games: Mockingjay - Part 2', 2015, 'Francis Lawrence'),
('Rogue One: A Star Wars Story', 2016, 'Gareth Edwards'),
('The Jungle Book', 2016, 'Jon Favreau'),
]
FILE = pathlib.Path(__file__)
DIR = FILE.parent
CSV_FILE = DIR / 'movies.csv'
SQLITE_FILE = DIR / 'movies.db'
def create_csv(movies_data, path):
with open(path, 'w') as opened_file:
writer = csv.writer(opened_file)
for row in movies_data:
writer.writerow(row)
def create_sqlite(movies_data, path):
with sqlite3.connect(path) as db:
db.execute(
'CREATE TABLE IF NOT EXISTS movies '
'(title text, year int, director text)'
)
db.execute('DELETE FROM movies')
db.executemany('INSERT INTO movies VALUES (?,?,?)', movies_data)
def main():
create_csv(SAMPLE_DATA, CSV_FILE)
create_sqlite(SAMPLE_DATA, SQLITE_FILE)
print('OK')
if __name__ == '__main__':
main()
Ahora ejecutemos en la terminal:
python data/fixtures.py
La secuencia de comandos debería salir
OKcon éxito.
Verificamos que los archivos
movies.csvy movies.dbaparecieron en el directorio data/:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ └── containers.py
├── venv/
├── config.yml
└── requirements.txt
Se crean los accesorios. Continuemos.
Envase
En esta sección, agregaremos la parte principal de nuestra aplicación: el contenedor.
El contenedor le permite describir la estructura de la aplicación en un estilo declarativo. Contendrá todos los componentes de la aplicación y sus dependencias. Todas las dependencias se especificarán explícitamente. Los proveedores se utilizan para agregar componentes de la aplicación al contenedor. Los proveedores controlan la vida útil de los componentes. Al crear un proveedor, no se crea ningún componente. Le decimos al proveedor cómo crear el objeto, y lo creará tan pronto como sea necesario. Si la dependencia de un proveedor es otro proveedor, entonces se llamará y así sucesivamente a lo largo de la cadena de dependencias.
Editemos
containers.py:
"""Containers module."""
from dependency_injector import containers
class ApplicationContainer(containers.DeclarativeContainer):
...
El contenedor todavía está vacío. Agregaremos proveedores en las siguientes secciones.
Agreguemos otra función
main(). Su responsabilidad es ejecutar la aplicación. Por ahora, solo creará un contenedor.
Editemos
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
if __name__ == '__main__':
main()
El contenedor es el primer objeto de la aplicación. Se usa para obtener todos los demás objetos.
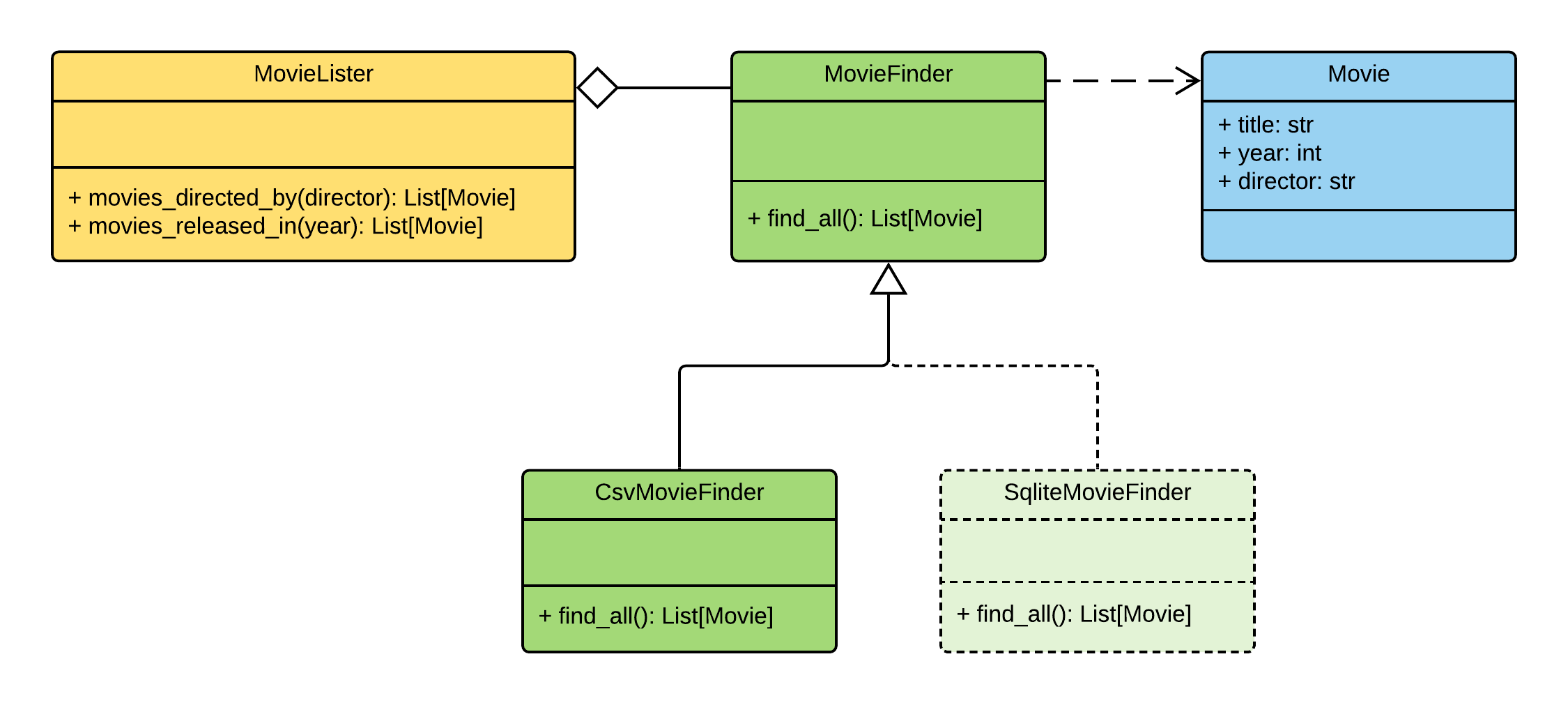
Trabajando con csv
Ahora agreguemos todo lo que necesitamos para trabajar con archivos csv.
Nosotros necesitamos:
- La esencia
Movie - Clase base
MovieFinder - Su implementación
CsvMovieFinder - Clase
MovieLister
Después de agregar cada componente, lo agregaremos al contenedor.
Cree un archivo
entities.pyen un paquete movies:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ └── entities.py
├── venv/
├── config.yml
└── requirements.txt
y agregue las siguientes líneas dentro:
"""Movie entities module."""
class Movie:
def __init__(self, title: str, year: int, director: str):
self.title = str(title)
self.year = int(year)
self.director = str(director)
def __repr__(self):
return '{0}(title={1}, year={2}, director={3})'.format(
self.__class__.__name__,
repr(self.title),
repr(self.year),
repr(self.director),
)
Ahora necesitamos agregar una fábrica
Movieal contenedor. Para ello necesitamos un módulo providersde dependency_injector.
Editemos
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import entities
class ApplicationContainer(containers.DeclarativeContainer):
movie = providers.Factory(entities.Movie)
No olvide eliminar la elipsis ( ...). El contenedor ya tiene proveedores y ya no es necesario.
Pasemos a la creación
finders.
Cree un archivo
finders.pyen un paquete movies:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ ├── entities.py
│ └── finders.py
├── venv/
├── config.yml
└── requirements.txt
y agregue las siguientes líneas dentro:
"""Movie finders module."""
import csv
from typing import Callable, List
from .entities import Movie
class MovieFinder:
def __init__(self, movie_factory: Callable[..., Movie]) -> None:
self._movie_factory = movie_factory
def find_all(self) -> List[Movie]:
raise NotImplementedError()
class CsvMovieFinder(MovieFinder):
def __init__(
self,
movie_factory: Callable[..., Movie],
path: str,
delimiter: str,
) -> None:
self._csv_file_path = path
self._delimiter = delimiter
super().__init__(movie_factory)
def find_all(self) -> List[Movie]:
with open(self._csv_file_path) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=self._delimiter)
return [self._movie_factory(*row) for row in csv_reader]
Ahora agreguemos
CsvMovieFinderal contenedor.
Editemos
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
Tienes
CsvMovieFinderuna dependencia de la fábrica Movie. CsvMovieFindernecesita una fábrica, ya que creará objetos a Moviemedida que lee datos de un archivo. Para pasar de fábrica usamos el atributo .provider. Esto se denomina delegación de proveedores. Si especificamos una fábrica moviecomo dependencia, se llamará cuando se csv_findercree CsvMovieFindery se pasará un objeto como una inyección Movie. El .providerpropio proveedor pasará el uso del atributo como una inyección.
También
csv_finderdepende de varias opciones de configuración. Hemos agregado un proveedor onfigurationpara pasar estas dependencias.
Usamos los parámetros de configuración antes de establecer sus valores. Este es el principio por el que trabaja el proveedorConfiguration.
Primero usamos, luego establecemos los valores.
Ahora agreguemos los valores de configuración.
Editemos
config.yml:
finder:
csv:
path: "data/movies.csv"
delimiter: ","
Los valores se establecen en el archivo de configuración. Actualicemos la función
main()para indicar su ubicación.
Editemos
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
container.config.from_yaml('config.yml')
if __name__ == '__main__':
main()
Vamos a
listers.
Cree un archivo
listers.pyen un paquete movies:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ ├── entities.py
│ ├── finders.py
│ └── listers.py
├── venv/
├── config.yml
└── requirements.txt
y agregue las siguientes líneas dentro:
"""Movie listers module."""
from .finders import MovieFinder
class MovieLister:
def __init__(self, movie_finder: MovieFinder):
self._movie_finder = movie_finder
def movies_directed_by(self, director):
return [
movie for movie in self._movie_finder.find_all()
if movie.director == director
]
def movies_released_in(self, year):
return [
movie for movie in self._movie_finder.find_all()
if movie.year == year
]
Actualizamos
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=csv_finder,
)
Todos los componentes se crean y se agregan al contenedor.
Finalmente, actualizamos la función
main().
Editemos
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
container.config.from_yaml('config.yml')
lister = container.lister()
print(
'Francis Lawrence movies:',
lister.movies_directed_by('Francis Lawrence'),
)
print(
'2016 movies:',
lister.movies_released_in(2016),
)
if __name__ == '__main__':
main()
Todo está listo. Ahora iniciemos la aplicación.
Ejecutemos en la terminal:
python -m movies
Ya verás:
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')]
2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
Nuestra aplicación funciona con una base de datos de películas en formato
csv. También necesitamos agregar soporte de formato sqlite. Nos ocuparemos de esto en la siguiente sección.
Trabajando con sqlite
En esta sección, agregaremos otro tipo
MovieFinder- SqliteMovieFinder.
Editemos
finders.py:
"""Movie finders module."""
import csv
import sqlite3
from typing import Callable, List
from .entities import Movie
class MovieFinder:
def __init__(self, movie_factory: Callable[..., Movie]) -> None:
self._movie_factory = movie_factory
def find_all(self) -> List[Movie]:
raise NotImplementedError()
class CsvMovieFinder(MovieFinder):
def __init__(
self,
movie_factory: Callable[..., Movie],
path: str,
delimiter: str,
) -> None:
self._csv_file_path = path
self._delimiter = delimiter
super().__init__(movie_factory)
def find_all(self) -> List[Movie]:
with open(self._csv_file_path) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=self._delimiter)
return [self._movie_factory(*row) for row in csv_reader]
class SqliteMovieFinder(MovieFinder):
def __init__(
self,
movie_factory: Callable[..., Movie],
path: str,
) -> None:
self._database = sqlite3.connect(path)
super().__init__(movie_factory)
def find_all(self) -> List[Movie]:
with self._database as db:
rows = db.execute('SELECT title, year, director FROM movies')
return [self._movie_factory(*row) for row in rows]
Agregue el proveedor
sqlite_finderal contenedor y especifíquelo como una dependencia para el proveedor lister.
Editemos
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
sqlite_finder = providers.Singleton(
finders.SqliteMovieFinder,
movie_factory=movie.provider,
path=config.finder.sqlite.path,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=sqlite_finder,
)
El proveedor
sqlite_finderdepende de las opciones de configuración que aún no hemos definido. Actualicemos el archivo de configuración:
Editar
config.yml:
finder:
csv:
path: "data/movies.csv"
delimiter: ","
sqlite:
path: "data/movies.db"
Hecho. Vamos a revisar.
Ejecutamos en la terminal:
python -m movies
Ya verás:
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')]
2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
Nuestra aplicación admite ambos formatos de base de datos:
csvy sqlite. Cada vez que necesitamos cambiar el formato, tenemos que cambiar el código en el contenedor. Mejoraremos esto en la siguiente sección.
Selector de proveedores
En esta sección, flexibilizaremos nuestra aplicación.
Ya no necesitará realizar cambios en el código para cambiar entre formatos
csvy sqlite. Implementaremos un cambio basado en una variable de entorno MOVIE_FINDER_TYPE:
- Cuando una
MOVIE_FINDER_TYPE=csvaplicación usacsv. - Cuando una
MOVIE_FINDER_TYPE=sqliteaplicación usasqlite.
El proveedor nos ayudará con esto
Selector. Elige un proveedor en función de la opción de configuración ( documentación ).
Editemos
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
sqlite_finder = providers.Singleton(
finders.SqliteMovieFinder,
movie_factory=movie.provider,
path=config.finder.sqlite.path,
)
finder = providers.Selector(
config.finder.type,
csv=csv_finder,
sqlite=sqlite_finder,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=finder,
)
Creamos un proveedor
findery lo especificamos como una dependencia para el proveedor lister. El proveedor finderelige entre proveedores csv_findery sqlite_finderen tiempo de ejecución. La elección depende del valor del interruptor.
El conmutador es la opción de configuración
config.finder.type. Cuando su valor es csvutilizado por el proveedor de la clave csv. Lo mismo para sqlite.
Ahora necesitamos leer el valor
config.finder.typede la variable de entorno MOVIE_FINDER_TYPE.
Editemos
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
container.config.from_yaml('config.yml')
container.config.finder.type.from_env('MOVIE_FINDER_TYPE')
lister = container.lister()
print(
'Francis Lawrence movies:',
lister.movies_directed_by('Francis Lawrence'),
)
print(
'2016 movies:',
lister.movies_released_in(2016),
)
if __name__ == '__main__':
main()
Hecho.
Ejecute los siguientes comandos en la terminal:
MOVIE_FINDER_TYPE=csv python -m movies
MOVIE_FINDER_TYPE=sqlite python -m movies
La salida de cada comando se verá así:
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')]
2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
En esta sección, nos familiarizamos con el proveedor
Selector. Con este proveedor, puede hacer que su aplicación sea más flexible. El valor del conmutador se puede establecer desde cualquier fuente: archivo de configuración, diccionario, otro proveedor.
Sugerencia:
anular un valor de configuración de un proveedor diferente le permite implementar la sobrecarga de configuración en su aplicación sin un reinicio en caliente.
Para hacer esto, necesita usar la delegación de proveedores y.override().
En la siguiente sección, agregaremos algunas pruebas.
Pruebas
Finalmente, agreguemos algunas pruebas.
Cree un archivo
tests.pyen un paquete movies:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ ├── entities.py
│ ├── finders.py
│ ├── listers.py
│ └── tests.py
├── venv/
├── config.yml
└── requirements.txt
y agregue las siguientes líneas:
"""Tests module."""
from unittest import mock
import pytest
from .containers import ApplicationContainer
@pytest.fixture
def container():
container = ApplicationContainer()
container.config.from_dict({
'finder': {
'type': 'csv',
'csv': {
'path': '/fake-movies.csv',
'delimiter': ',',
},
'sqlite': {
'path': '/fake-movies.db',
},
},
})
return container
def test_movies_directed_by(container):
finder_mock = mock.Mock()
finder_mock.find_all.return_value = [
container.movie('The 33', 2015, 'Patricia Riggen'),
container.movie('The Jungle Book', 2016, 'Jon Favreau'),
]
with container.finder.override(finder_mock):
lister = container.lister()
movies = lister.movies_directed_by('Jon Favreau')
assert len(movies) == 1
assert movies[0].title == 'The Jungle Book'
def test_movies_released_in(container):
finder_mock = mock.Mock()
finder_mock.find_all.return_value = [
container.movie('The 33', 2015, 'Patricia Riggen'),
container.movie('The Jungle Book', 2016, 'Jon Favreau'),
]
with container.finder.override(finder_mock):
lister = container.lister()
movies = lister.movies_released_in(2015)
assert len(movies) == 1
assert movies[0].title == 'The 33'
Ahora comencemos a probar y verificar la cobertura:
pytest movies/tests.py --cov=movies
Ya verás:
platform darwin -- Python 3.8.3, pytest-5.4.3, py-1.9.0, pluggy-0.13.1
plugins: cov-2.10.0
collected 2 items
movies/tests.py .. [100%]
---------- coverage: platform darwin, python 3.8.3-final-0 -----------
Name Stmts Miss Cover
------------------------------------------
movies/__init__.py 0 0 100%
movies/__main__.py 10 10 0%
movies/containers.py 9 0 100%
movies/entities.py 7 1 86%
movies/finders.py 26 13 50%
movies/listers.py 8 0 100%
movies/tests.py 24 0 100%
------------------------------------------
TOTAL 84 24 71%
Usamos el método del.override()proveedorfinder. El proveedor es anulado por simulacro. Al comunicarse con el proveedor,finderahora se devolverá el simulacro primordial.
El trabajo está hecho. Ahora resumamos.
Conclusión
Creamos una aplicación CLI utilizando el principio de inyección de dependencia. Usamos Dependency Injector como un marco de inyección de dependencias.
La ventaja que obtiene con Dependency Injector es el contenedor.
El contenedor comienza a dar sus frutos cuando necesita comprender o cambiar la estructura de su aplicación. Con un contenedor, esto es fácil porque todos los componentes de la aplicación y sus dependencias se definen explícitamente en un solo lugar:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
sqlite_finder = providers.Singleton(
finders.SqliteMovieFinder,
movie_factory=movie.provider,
path=config.finder.sqlite.path,
)
finder = providers.Selector(
config.finder.type,
csv=csv_finder,
sqlite=sqlite_finder,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=finder,
)
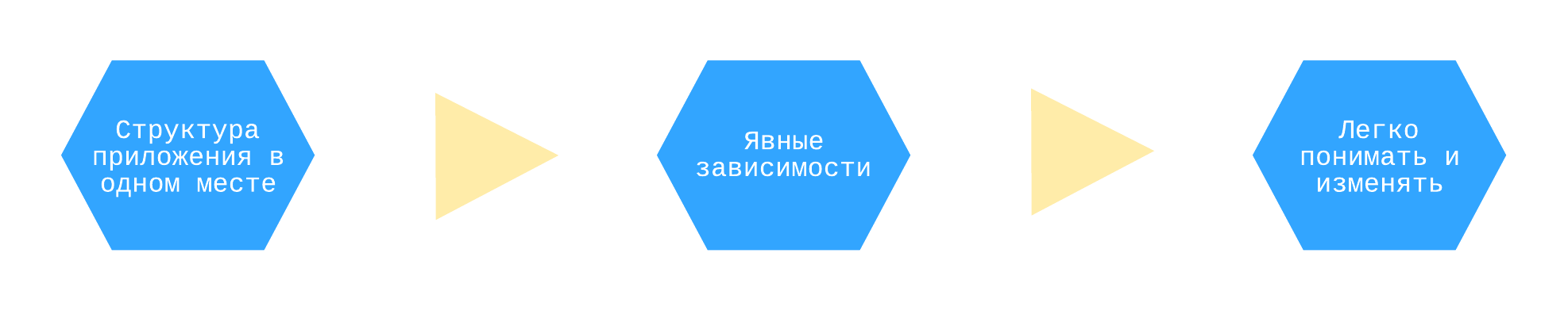
Un contenedor como mapa de su aplicación. Siempre sabes qué depende de qué.
PD: preguntas y respuestas
En los comentarios al tutorial anterior, se hicieron preguntas interesantes: "¿por qué es necesario?", "¿Por qué necesitamos un marco?", "¿Cómo ayuda el marco en la implementación?"
He preparado respuestas:
¿Qué es la inyección de dependencia?
- es el principio que reduce el acoplamiento y aumenta la cohesión
¿Por qué debería usar la inyección de dependencia?
- su código se vuelve más flexible, comprensible y mejor comprobable
- tiene menos problemas cuando necesita entender cómo funciona o cambiarlo
¿Cómo empiezo a aplicar la inyección de dependencia?
- comienzas a escribir código siguiendo el principio de inyección de dependencia
- registra todos los componentes y sus dependencias en el contenedor
- cuando necesita un componente, lo obtiene del contenedor
¿Por qué necesito un marco para esto?
- necesitas un marco para no crear el tuyo propio. El código de creación del objeto estará duplicado y será difícil de cambiar. Para evitar esto, necesita un recipiente.
- el marco te da un contenedor y proveedores
- los proveedores controlan la vida útil de los objetos. Necesitará fábricas, singletons y objetos de configuración
- el contenedor sirve como una colección de proveedores
¿Qué precio estoy pagando?
- necesita especificar explícitamente las dependencias en el contenedor
- este es un trabajo adicional
- comenzará a pagar dividendos cuando el proyecto comience a crecer
- o 2 semanas después de su finalización (cuando olvidas qué decisiones tomaste y cuál es la estructura del proyecto)
Concepto de inyector de dependencia
Además, describiré el concepto de Dependency Injector como marco.
Dependency Injector se basa en dos principios:
- Explícito es mejor que implícito (PEP20).
- No hagas magia con tu código.
¿En qué se diferencia Dependency Injector de otros marcos?
- Sin vinculación automática. El marco no vincula automáticamente las dependencias. No se utiliza introspección, vinculación por nombres y / o tipos de argumentos. Porque "explícito es mejor que implícito (PEP20)".
- No contamina el código de su aplicación. Su aplicación desconoce y es independiente de Dependency Injector. Sin
@injectdecoradores, anotaciones, parches u otros trucos de magia.
Dependency Injector ofrece un contrato simple:
- Le muestras al marco cómo recolectar objetos.
- El marco los recopila
La fuerza del inyector de dependencia radica en su simplicidad y sencillez. Es una herramienta simple para implementar un principio poderoso.
¿Que sigue?
Si está interesado, pero duda, mi recomendación es la siguiente:
pruebe este enfoque durante 2 meses. No es intuitivo. Se necesita tiempo para acostumbrarse y sentirse. Los beneficios se vuelven tangibles cuando el proyecto crece a más de 30 componentes en un contenedor. Si no le gusta, no pierda mucho. Si te gusta, obtén una ventaja significativa.
- Obtenga más información sobre el inyector de dependencia en GitHub
- Consulte la documentación en Leer los documentos
Me complacería recibir comentarios y responder preguntas en los comentarios.