
El equipo de Mail.ru Cloud Solutions tradujo un ensayo resumido de Kevin Wu , que analiza lo que la industria farmacéutica y de la salud ya ha logrado utilizando inteligencia artificial y aprendizaje automático, y cuándo las nuevas tecnologías ayudarán a encontrar medicamentos. de todas las enfermedades.
Por qué puede parecer que no hay progreso
Algunas personas expresan su frustración con la vida algo como esto: "Si este es el futuro, ¿dónde está mi jetpack?" A primera vista, ese anhelo por un futuro retro parece extraño en una era de computación ubicua, células programables y una exploración espacial resurgente . Pero para algunos, este futurismo nostálgico se mantiene sorprendentemente bien. Se aferran a predicciones que parecen extrañas en retrospectiva, ignorando la sorprendente realidad que nadie podría haber predicho.
¿Quién hubiera pensado que gracias al aprendizaje profundo podríamos predecir las propiedades de fármacos que aún no existen? Esto es de gran importancia para la industria farmacéutica.
Con respecto a la inteligencia artificial, las quejas pueden sonar algo así: “Han pasado casi ocho años desde la invención de la red neuronal AlexNet [ aprox. traductor : en 2012, Aleksey Krizhevsky publicó el diseño de la red neuronal convolucional AlexNet, que ganó la competencia ImageNet por un amplio margen], bueno, ¿dónde está mi auto sin conductor? " De hecho, puede parecer que las expectativas de mediados de la década de 2010 no se han cumplido. Entre los pesimistas, las previsiones del próximo estancamiento en la investigación de la IA están ganando impulso .
El propósito de este ensayo es discutir el progreso significativo del aprendizaje automático en el desafío del descubrimiento de fármacos en el mundo real. Quiero recordarles otro viejo adagio, esta vez de los investigadores de IA. Para reformular un poco, suena así: "AI se llama AI hasta que funciona, entonces es solo software".
Lo que hasta hace unos años se consideraba investigación básica de vanguardia en aprendizaje automático ahora se conoce como "solo ciencia de datos " (o incluso análisis), y está revolucionando la industria farmacéutica. Existe una gran posibilidad de que el uso del aprendizaje profundo para descubrir drogas cambie dramáticamente nuestras vidas para mejor.
Visión por computadora y aprendizaje profundo en imágenes biomédicas
Tan pronto como los científicos tuvieron acceso a las computadoras y la oportunidad de cargar imágenes allí, inmediatamente intentaron procesarlas. Básicamente, estamos hablando de imágenes biomédicas: radiografías, ecografías y resultados de resonancia magnética. En los días de la buena inteligencia artificial, el procesamiento generalmente significaba inferir manualmente declaraciones lógicas basadas en atributos simples como contornos y brillo.
La década de 1980 vio un cambio hacia algoritmos de aprendizaje automático supervisados, pero aún confiaban en las etiquetas colocadas a mano. Los modelos simples de aprendizaje supervisado (como la regresión lineal o el ajuste polinomial) se entrenan en características extraídas por algoritmos como SIFT (Transformación de características invariantes de escala) y HOG (Histograma de gradientes dirigidos). No debería sorprendernos que los desarrollos que han llevado al uso práctico del aprendizaje profundo en la actualidad hayan comenzado hace décadas.
Las redes neuronales convolucionales se utilizaron por primera vez para el análisis de imágenes biomédicas en 1995, cuando Law y sus colegaspresentó un modelo para el reconocimiento de tumores cancerosos en los pulmones en fluorogramas. Su método era un poco diferente de lo que estamos acostumbrados hoy, la derivación del resultado tomó unos 15 segundos, pero el concepto fue esencialmente el mismo: el aprendizaje a través de la propagación hacia atrás hasta los núcleos convolucionales de la red neuronal. Su modelo incluía dos capas ocultas, mientras que las arquitecturas de redes profundas más populares de la actualidad suelen tener cien o más capas.
Avance rápido hasta 2012. Las redes neuronales convolucionales causaron sensación con la llegada del sistema AlexNet, que dio lugar a un salto en el rendimiento del ahora famoso conjunto de datos ImageNet. El éxito de AlexNet, una red con cinco capas convolucionales y tres capas estrechamente acopladas entrenadas en GPU de juegos, se ha vuelto tan famoso en el aprendizaje automático que la gente ahora está hablando "Moments of ImageNet ”en diferentes nichos de aprendizaje automático e IA.
Por ejemplo, "el procesamiento del lenguaje natural puede haber sobrevivido a su momento ImageNet con el desarrollo de grandes transformadores en 2018" o "el aprendizaje por refuerzo todavía está esperando su momento ImageNet".
Han pasado casi diez años desde AlexNet. Los modelos de visión por computadora y aprendizaje profundo están mejorando gradualmente. Las aplicaciones han ido más allá de la clasificación. Hoy han aprendido a segmentar imágenes, estimar la profundidad y reconstruir automáticamente escenas 3D a partir de múltiples imágenes 2D. Y esta no es una lista completa de sus capacidades.
El aprendizaje profundo para el análisis de imágenes biomédicas se ha convertido en un área de investigación candente. Un efecto secundario es un aumento inevitable del ruido. Publicado en 2019aproximadamente 17.000 artículos científicos sobre aprendizaje profundo . Por supuesto, no vale la pena leerlos todos. Es probable que muchos investigadores se ajusten demasiado a los modelos en sus modestos conjuntos de datos.
La mayoría de ellos no ha realizado ninguna contribución a la ciencia básica o al aprendizaje automático. La pasión por el aprendizaje profundo se ha apoderado de los investigadores académicos que anteriormente no habían mostrado interés en él, y por una buena razón. Puede hacer lo que hacen los algoritmos clásicos de visión por computadora (consulte el teorema de aproximación universal de Tsybenko y Hornik) y, a menudo, lo hace más rápido y mejor, lo que ahorra a los ingenieros el tedioso diseño manual de cada nueva aplicación.
Una rara oportunidad para luchar contra las enfermedades "desatendidas"
Esto nos lleva al tema del descubrimiento de fármacos en la actualidad, una industria que está experimentando una buena reestructuración. A las compañías farmacéuticas y sus contratistas les encanta reiterar los enormes costos de llevar un nuevo medicamento al mercado. Estos costos se deben en gran parte al hecho de que muchos medicamentos requieren mucho tiempo para estudiarlos y probarlos antes de consumirlos.
El costo de desarrollar un nuevo medicamento puede alcanzar los 2.500 millones de dólares o más . A veces, debido al alto costo y la rentabilidad relativamente baja, una serie de trabajos sobre ciertas clases de medicamentos quedan relegados a un segundo plano .
También está provocando un aumento en la incidencia de la categoría acertadamente denominada de "enfermedades desatendidas", que incluye un número desproporcionado de enfermedades tropicales.que afectan a las personas de los países más pobres y se consideran desventajosas para el tratamiento, y enfermedades raras con bajas tasas de incidencia. Relativamente pocas personas padecen cada uno de ellos, pero el número total de personas con todas las enfermedades raras es bastante grande. Se estima que unos 300 millones de personas. E incluso este número puede resultar subestimado debido a la sombría evaluación de los expertos: alrededor del 30% de los que padecen una enfermedad rara no viven hasta los cinco años.
" Cola larga»Las enfermedades raras tienen un potencial significativo para mejorar la vida de un gran número de personas, y aquí es donde el aprendizaje automático y los macrodatos vienen al rescate. El punto ciego de las enfermedades raras (huérfanas) que no tienen un tratamiento aprobado oficialmente abre una oportunidad para la innovación de pequeños equipos de biólogos y desarrolladores de aprendizaje automático.
Una de esas empresas emergentes en Salt Lake City, Utah, está tratando de hacer precisamente eso. Los fundadores de Recursion Pharmaceuticals ven la falta de medicamentos para enfermedades raras como una brecha en la industria farmacéutica. Reciben enormes cantidades de datos al analizar los resultados de microscopía y pruebas de laboratorio. Con la ayuda de las redes neuronales, es posible identificar las características de las enfermedades y buscar métodos de tratamiento.
A fines de 2019, la compañía había realizado miles de experimentos y recopilado más de 4 petabytes de información. Publicaron un pequeño subconjunto de estos datos (46 GB) para la competencia NeurIps 2019, puede descargarlo del sitio web de RxRx y jugar por su cuenta.
El flujo de trabajo descrito en este artículo se basa en gran medida en la información de los libros blancos [ pdf ] de Recursion Pharmaceuticals, pero este enfoque puede servir de inspiración para otras áreas.
Otras startups en el campo incluyen Bioage Labs (enfermedades del envejecimiento), Notable Labs (oncología) y TwoXAR.(diversas enfermedades para las que no existen opciones de tratamiento). Por lo general, las nuevas empresas jóvenes se dedican a técnicas innovadoras de procesamiento de datos y aplican una variedad de métodos de aprendizaje automático además o en lugar del aprendizaje profundo con visión por computadora.
A continuación, describiré el proceso de análisis de imágenes y cómo el aprendizaje profundo encaja en el flujo de trabajo de descubrimiento de fármacos para enfermedades raras. Examinaremos un proceso de alto nivel que es aplicable a una variedad de otras áreas del descubrimiento de fármacos.
Por ejemplo, se puede usar fácilmente para detectar medicamentos contra el cáncer por su efecto sobre la morfología de las células tumorales. Quizás incluso para analizar la respuesta de células de pacientes específicos a diferentes opciones de fármacos. Este enfoque utiliza conceptos del análisis de componentes principales no lineales ., hash semántico [ pdf ] y buena clasificación de imágenes de redes neuronales convolucionales.
Clasificación en ruido morfológico
La biología es un desastre. Por lo tanto, la microscopía multiparamétrica de alto rendimiento es una fuente de frustración constante para los biólogos celulares. Las imágenes resultantes difieren mucho de un experimento a otro. Las fluctuaciones de temperatura, el tiempo de exposición, la cantidad de reactivos, entre otros, provocan cambios que no están relacionados con el fenotipo estudiado o la acción del fármaco y, por tanto, errores en los resultados obtenidos.
¿Quizás el control climático en un laboratorio funciona de manera diferente en verano e invierno? ¿Quizás alguien almorzó junto a los portaobjetos antes de insertarlos en el microscopio? ¿Quizás haya cambiado el proveedor de uno de los ingredientes del medio de cultivo? ¿O el proveedor ha cambiado de proveedor? Una gran cantidad de variables afectan el resultado de un experimento. El seguimiento y el resaltado del ruido no intencional es uno de los principales desafíos en el descubrimiento de fármacos basado en datos.
Las imágenes microscópicas pueden ser muy diferentes en los mismos experimentos. El brillo de la imagen, la forma de las células, la forma de los orgánulos y muchas otras características cambian debido a los correspondientes efectos fisiológicos o errores aleatorios.
Entonces, las imágenes en la figura siguiente se obtienen del mismoun conjunto de micrografías de células cancerosas metastásicas disponibles públicamente compiladas por Scott Wilkinson y Adam Marcus. Las variaciones en la saturación y la morfología deberían reflejar la incertidumbre de los datos experimentales. Se crean introduciendo distorsiones en el procesamiento. Es una especie de análogo del aumento, que los investigadores utilizan para regularizar redes neuronales profundas en problemas de clasificación. Por lo tanto, no debería sorprendernos que la capacidad de generalizar grandes modelos a grandes conjuntos de datos sea una opción lógica para buscar características fisiológicamente significativas en un mar de ruido.
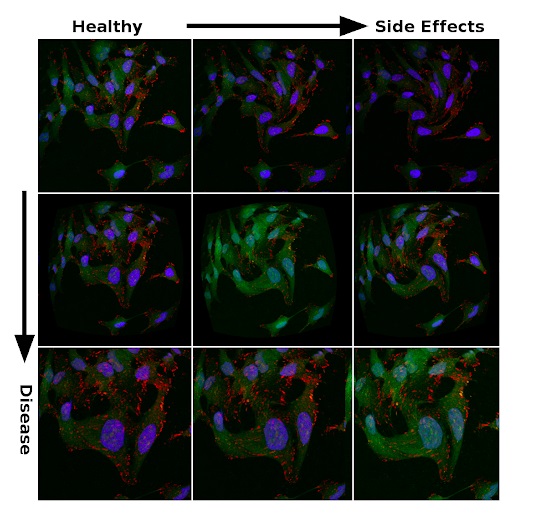
Signos de efectividad del tratamiento y efectos secundarios entre datos ruidosos
La principal causa de las enfermedades raras suele ser una mutación genética. Para construir modelos para encontrar una cura para estas enfermedades, es necesario comprender los efectos de una amplia gama de mutaciones y su relación con diferentes fenotipos. Para comparar de manera eficaz los posibles tratamientos para una enfermedad rara específica, las redes neuronales se entrenan en función de miles de mutaciones diferentes.
Estas mutaciones se pueden imitar suprimiendo la expresión génica utilizando pequeños ARN interferentes.(ARNip). Es un poco como si los bebés te agarrasen los tobillos: incluso si puedes correr rápido, tu velocidad bajará drásticamente con tu sobrina o sobrino colgando de cada pierna. El ARNip funciona de manera similar: una pequeña secuencia de ARN interferentes se adhiere a las partes correspondientes del ARN mensajero de genes específicos, impidiendo su expresión completa.
Al aprender de miles de mutaciones en lugar de un modelo celular singular de una enfermedad específica, la red neuronal aprende a codificar fenotipos en un espacio oculto multidimensional. El código resultante permite evaluar los fármacos por su capacidad para acercar el fenotipo de la enfermedad a un fenotipo sano, cada uno de los cuales está representado por un conjunto multidimensional de coordenadas. Asimismo, los efectos secundarios de los medicamentos pueden incluirse en la representación codificada del fenotipo, y los medicamentos se evalúan no solo para la desaparición de los síntomas de la enfermedad, sino también para minimizar los efectos secundarios dañinos.

El diagrama muestra el efecto del tratamiento en el modelo celular de la enfermedad (representado por un punto rojo). El tratamiento es el movimiento del fenotipo codificado más cerca del fenotipo sano (punto azul). Esta es una representación 3D simplificada de la codificación fenotípica en un espacio oculto multidimensional.Los
modelos de aprendizaje profundo utilizados para este flujo de trabajo son muy similares a otros problemas de clasificación con un conjunto de datos grande, aunque si está acostumbrado a trabajar con un número pequeño de categorías, como en conjuntos de datos CIFAR-10 y CIFAR-100, no se acostumbrará inmediatamente a las miles de marcas de clasificación diferentes.
Además, este método de descubrimiento de fármacos basado en imágenes funciona bien con la misma arquitectura DenseNet o ResNet con cientos de capas, lo que proporciona un rendimiento óptimo en conjuntos de datos como ImageNet.
Los valores de activación de la capa codificados en un espacio multidimensional reflejan el fenotipo, la patogenia de la enfermedad, las relaciones entre los tratamientos, los efectos secundarios y otras dolencias. Por tanto, todos estos factores pueden analizarse por desplazamiento en el espacio codificado. Este código fenotípico puede someterse a una regularización especial (por ejemplo, minimizando la covarianza entre diferentes activaciones de capas) para reducir las correlaciones de codificación o para otros fines.
La siguiente figura muestra un modelo simplificado. Las flechas negras representan las operaciones de convolución + agrupación. Las líneas azules representan conexiones estrechas. Por simplicidad, se ha reducido el número de capas y no se muestran las conexiones residuales.
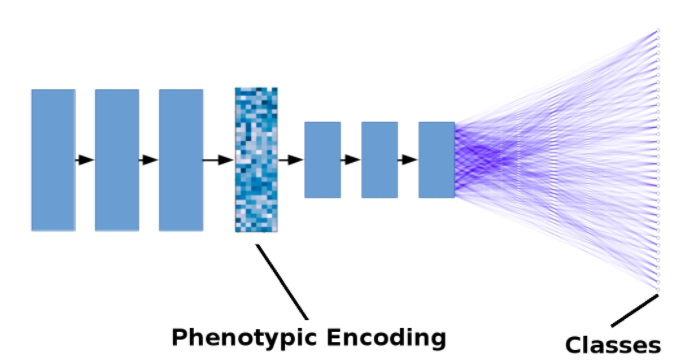
Ilustración simplificada de un modelo de aprendizaje profundo para el descubrimiento de fármacos
El futuro del aprendizaje profundo en el descubrimiento de fármacos y la industria farmacéutica
El alto costo de llevar nuevos medicamentos al mercado ha llevado a las compañías farmacéuticas a optar a menudo por los éxitos del mercado en lugar de investigar medicamentos para enfermedades graves. Los equipos de análisis de datos más pequeños en las nuevas empresas están mejor equipados para innovar en esta área, mientras que las enfermedades desatendidas y raras brindan una oportunidad para ingresar al mercado y demostrar el valor del aprendizaje automático.
Se ha demostrado la eficacia de este enfoque. Estamos viendo un progreso de investigación significativo y varios medicamentos ya se encuentran en la primera fase de ensayos clínicos. Por ejemplo, equipos de unos pocos cientos de científicos e ingenieros de empresas como Recursion Pharmaceuticals logran esto. Hay otras empresas emergentes cercanas: TwoXAR tiene varios candidatos a fármacos que se someten a ensayos preclínicos en otras categorías de enfermedades.
Se puede esperar que el enfoque de aprendizaje profundo y visión por computadora para el desarrollo de medicamentos tenga un impacto significativo en las grandes compañías farmacéuticas y en la atención médica en general. Pronto veremos cómo esto afectará el desarrollo de nuevos tratamientos para enfermedades comunes (incluidas las enfermedades cardíacas y la diabetes), así como las dolencias raras que han permanecido fuera de la vista hasta el día de hoy.
Qué más leer sobre el tema: