
Una de las tareas de un examen fonoscópico es establecer la autenticidad y autenticidad de una grabación de audio, en otras palabras, identificar signos de edición, distorsión y alteración de la grabación. Tuvimos la tarea de realizarlo para establecer la autenticidad de los registros, para determinar que no se ejerció ninguna influencia en los registros. Pero, ¿cómo analizar miles, e incluso cientos de miles de grabaciones de audio?
Los métodos de IA vienen a nuestro rescate, así como una utilidad para trabajar con audio, de la que hablamos en un artículo de la web de NewTechAudit " PROCESANDO AUDIO CON FFMPEG" .
¿Cómo aparecen los cambios en el audio? ¿Cómo se puede diferenciar un archivo modificado de un archivo intacto?
Existen varios de estos signos, y el más simple es identificar información sobre la edición de un archivo y analizar la fecha de su modificación. Estos métodos se implementan fácilmente mediante el propio sistema operativo, por lo que no nos detendremos en estos métodos. Pero los cambios pueden ser realizados por un usuario más calificado que puede ocultar o cambiar la información sobre la edición, en este caso, se utilizan métodos más complejos, por ejemplo:
- cambio de contornos;
- cambiar el perfil espectral del audio grabado;
- la aparición de pausas;
- y muchos otros.
Y todos estos métodos de sondeo complejos son realizados por expertos especialmente capacitados: fonoscopistas que utilizan software especializado como Praat, Speech Analyzer SIL, ELAN, la mayoría de los cuales son pagados y requieren calificaciones lo suficientemente altas para usar e interpretar los resultados.
Los expertos analizan el audio utilizando un perfil espectral, es decir, analizando sus coeficientes cepstrales. Usaremos la experiencia de expertos, y al mismo tiempo usaremos el código ya hecho, adaptándolo a nuestra tarea.
Entonces, hay muchos cambios que se pueden hacer, ¿cómo elegimos?
De los posibles tipos de cambios que se pueden realizar en los archivos de audio, nos interesa recortar una parte del audio, o recortar una parte y luego reemplazar la parte original con una parte de la misma duración, los llamados cambios de cortar / copiar. la edición de archivos en términos de reducción de ruido, cambio de frecuencia de tono y otros no conlleva el riesgo de ocultar información.
¿Y cómo identificaremos estos mismos cortes / copias? ¿Deberían compararse con algo?
Es muy simple: con la ayuda de la utilidad FFmpeg cortaremos una parte de una duración aleatoria del archivo y en un lugar aleatorio, después de lo cual compararemos los espectrogramas cepstrales pequeños del archivo original y el archivo "cortado".
Código para mostrarlos:
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
def make_spek(audio):
n_fft = 2048
y, sr = librosa.load(audio)
ft = np.abs(librosa.stft(y[:n_fft], hop_length = n_fft+1))
spec = np.abs(librosa.stft(y, hop_length=512))
spec = librosa.amplitude_to_db(spec, ref=np.max)
mel_spect = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=1024)
mel_spect = librosa.power_to_db(mel_spect, ref=np.max)
librosa.display.specshow(mel_spect, y_axis='mel', fmax=8000, x_axis='time');
plt.title('Mel Spectrogram');
plt.colorbar(format='%+2.0f dB');
plt.show();
make_spek('./audio/original.wav')# './audio/original.wav' Preparamos un conjunto de datos a partir de la fuente y cortamos archivos usando el comando de la utilidad FFmpeg:
ffmpeg -i oroginal.wav -ss STARTTIME -to ENDTIME -acodec copy cut.wav donde STARTTIME y ENDTIME son el principio y el final del fragmento cortado. Y usando el comando:
ffmpeg -iconcat:"part_0.wav|part_1.wav |part_2.wav" -codeccopyconcat.wavune la parte del archivo para insertar part_1.wav con las partes originales (para envolver los comandos de FFmpeg en python, consulta nuestro artículo sobre FFmpeg).
Aquí están los archivos originales del espectrograma de tiza de los cuales se cortaron del audio de 0.2-2.5 segundos, y el espectrograma de tiza de los archivos que se cortaron del audio de 0.2-2.5 segundos, y luego se insertaron en los fragmentos de audio de una duración similar de este archivo de audio:
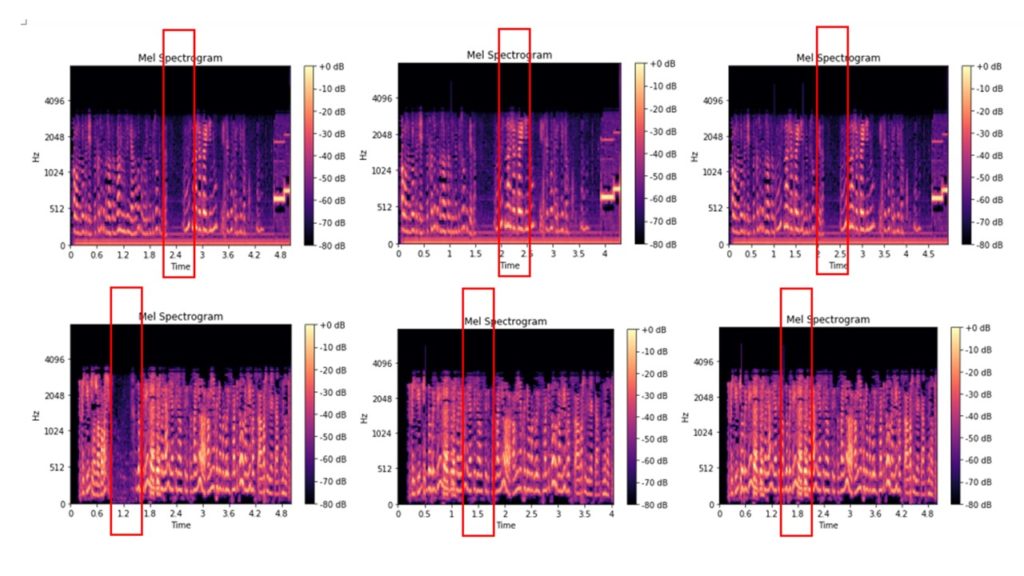
Algunos las imágenes se distinguen incluso visualmente, otras se ven casi iguales. Distribuimos las imágenes resultantes en carpetas y las usamos como datos de entrada para entrenar el modelo para la clasificación de imágenes. Estructura de carpetas:
model.py #
/input/train/original/ #
/input/train/cut_copy/ # Para nosotros, no importa si el archivo de audio modificado se complementó o acortó: dividimos todos los resultados en buenos, es decir, archivos sin cambios y malos. Por tanto, resolvemos el problema clásico de la clasificación binaria. Clasificaremos usando redes neuronales, tomaremos el código para trabajar con una red neuronal ya hecho a partir de ejemplos de trabajo con el paquete Keras.
#
from keras.models import Sequential
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
#
classifier = Sequential()
classifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(32, (3, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Flatten())
classifier.add(Dense(units = 128, activation = 'relu'))
classifier.add(Dense(units = 1, activation = 'sigmoid'))
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
#
from keras.preprocessing.image import ImageDataGenerator as img
train_datagen = img(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = img(rescale = 1./255)
training_set = train_datagen.flow_from_directory('input/train',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
test_set = test_datagen.flow_from_directory('input/test',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
classifier.fit_generator(
training_set,
steps_per_epoch = 8000,
epochs = 25,
validation_data = test_set,
validation_steps = 2000)Además, una vez que el modelo ha entrenado, llevamos a cabo la clasificación con su ayuda.
import numpy as np
from keras.preprocessing import image
test_image = image.load_img('dataset/prediction/original_or_corrupt.jpg', target_size = (64, 64))
test_image = image.img_to_array(test_image)
test_image = np.expand_dims(test_image, axis = 0)
result = classifier.predict(test_image)
training_set.class_indices
ifresult[0][0] == 1:
prediction = 'original'
else:
prediction = 'corrupt'En la salida, obtenemos la clasificación del archivo de audio: 'original' / 'corrupto', es decir, el archivo sin cambios y los archivos en los que se realizaron los cambios.
Demostramos una vez más que las cosas complejas se pueden hacer de manera simple: no utilizamos el mecanismo más difícil de los métodos de inteligencia artificial, soluciones listas para usar y verificamos el audio para ver si hay cambios. Bueno, éramos los expertos del detective.