Para comprender cómo surgieron los índices de árbol B, imaginemos un mundo sin ellos y tratemos de resolver un problema típico. A lo largo del camino, discutiremos los problemas que enfrentaremos y las formas de resolverlos.

Introducción
En el mundo de las bases de datos, existen dos formas más habituales de almacenar información:
- Basado en estructuras basadas en Log.
- Basado en páginas.
La ventaja del primer método es que le permite leer y guardar datos fácil y rápidamente. La nueva información solo se puede escribir al final del archivo (grabación secuencial), lo que garantiza una alta velocidad de grabación. Este método es utilizado por bases como Leveldb, Rocksdb, Cassandra.
El segundo método (basado en páginas) divide los datos en fragmentos de tamaño fijo y los guarda en el disco. Estas partes se denominan "páginas" o "bloques". Contienen registros (filas, tuplas) de tablas.
Este método de almacenamiento de datos es utilizado por MySQL, PostgreSQL, Oracle y otros. Y dado que estamos hablando de índices en MySQL, este es el enfoque que consideraremos.
Almacenamiento de datos en MySQL
Entonces, todos los datos en MySQL se guardan en el disco como páginas. El tamaño de la página está regulado por la configuración de la base de datos y es de 16 KB por defecto.
Cada página contiene 38 bytes de encabezados y un final de 8 bytes (como se muestra en la figura). Y el espacio asignado para el almacenamiento de datos no está completamente lleno, porque MySQL deja un espacio vacío en cada página para cambios futuros.
Más adelante en los cálculos, descuidaremos la información del servicio, asumiendo que los 16 KB de la página están llenos con nuestros datos. No profundizaremos en la organización de las páginas de InnoDB, este es un tema para un artículo separado. Puedes leer más sobre esto aquí .

Como acordamos anteriormente que los índices aún no existen, por ejemplo, crearemos una tabla simple sin índices (de hecho, MySQL seguirá creando un índice, pero no lo tendremos en cuenta en los cálculos):
CREATE TABLE `product` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` CHAR(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`category_id` INT NOT NULL,
`price` INT NOT NULL,
) ENGINE=InnoDB;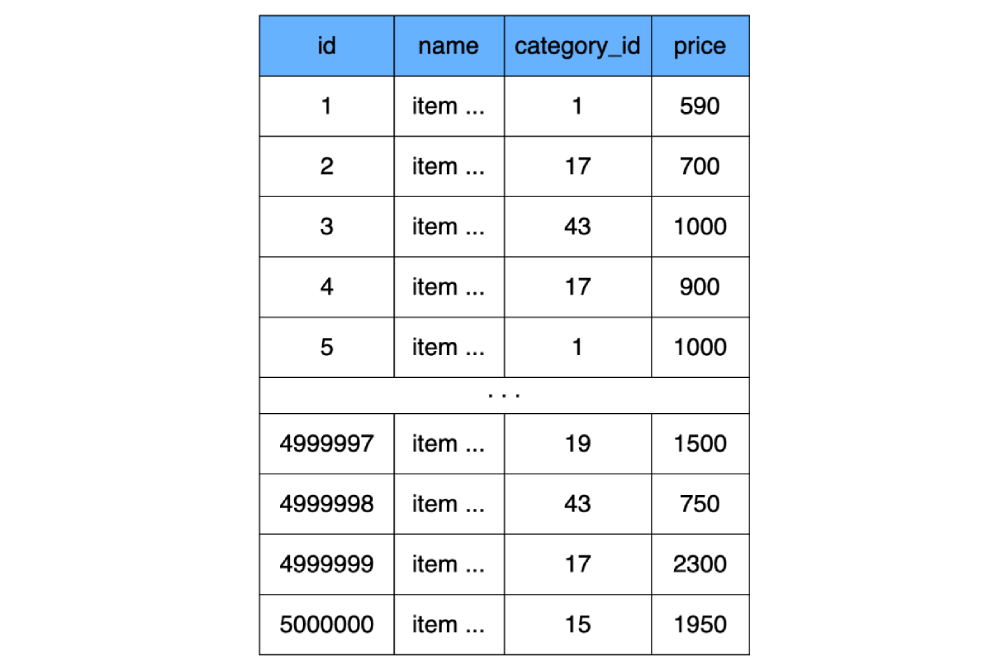
y ejecutar la siguiente solicitud:
SELECT * FROM product WHERE price = 1950;MySQL abrirá el archivo donde se almacenan los datos de la tabla
producty comenzará a iterar sobre todos los registros (filas) en busca de los requeridos, comparando el campo pricede cada fila encontrada con el valor en la consulta. Para mayor claridad, considero específicamente la opción con un escaneo completo del archivo, por lo que los casos en que MySQL recibe datos del caché no son adecuados para nosotros.
¿Qué problemas podemos enfrentar con esto?
HDD
Como tenemos todo almacenado en un disco duro, echemos un vistazo a su dispositivo. El disco duro lee y escribe datos en sectores (bloques). El tamaño de dicho sector puede ser de 512 bytes a 8 KB (según el disco). Se pueden combinar varios sectores consecutivos en grupos.
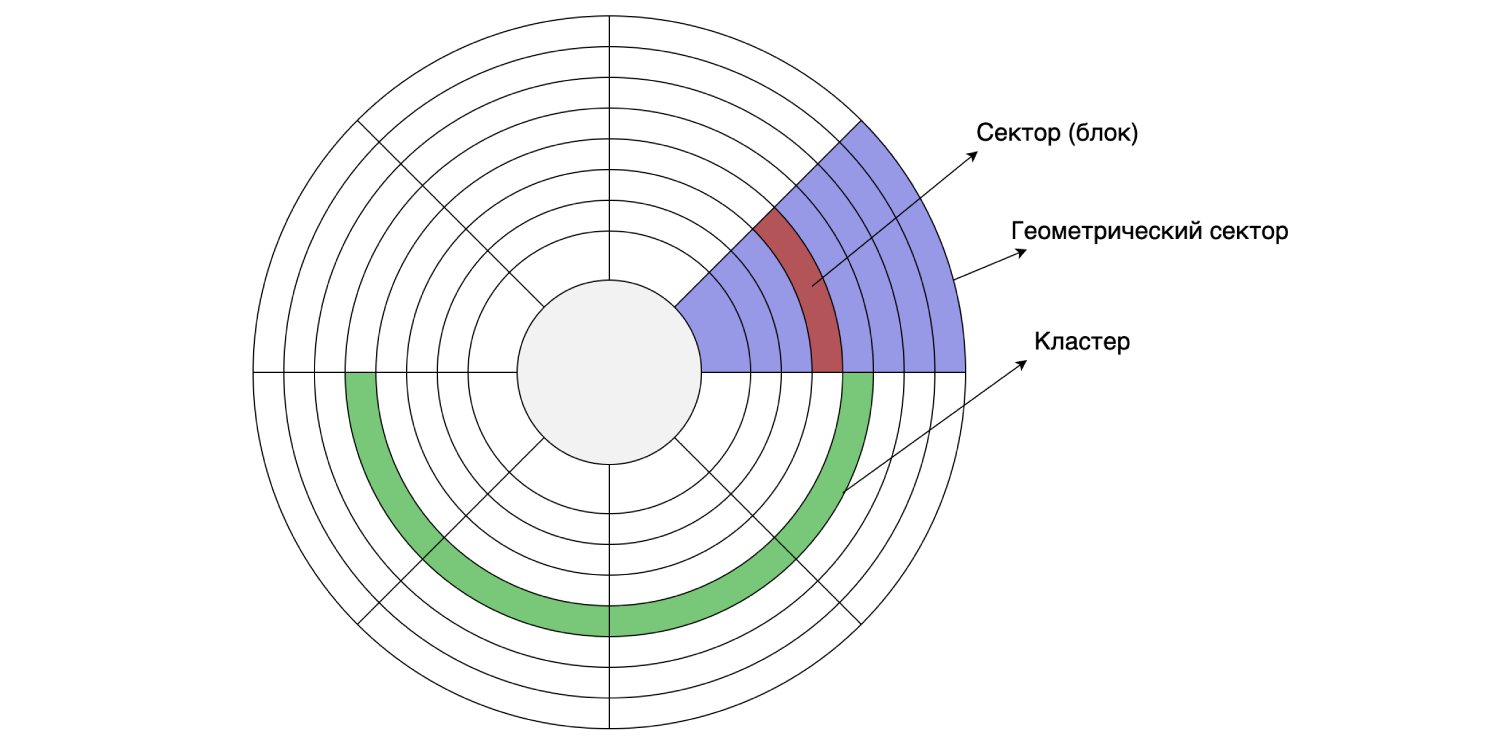
El tamaño del clúster se puede configurar al formatear / particionar el disco, es decir, se hace mediante programación. Suponga que el tamaño del sector del disco es de 4 KB y el sistema de archivos está particionado con un tamaño de clúster de 16 KB: un clúster consta de cuatro sectores. Como recordamos, MySQL almacena de forma predeterminada los datos en el disco en páginas de 16 KB, por lo que una página cabe en un clúster de disco.
Calculemos cuánto espacio ocupará nuestra placa de producto, asumiendo que almacena 500.000 artículos. Tenemos tres campos de cuatro bytes
id, pricey category_id. Acordemos que el campo de nombre para todos los registros se llena hasta el final (los 100 caracteres) y cada carácter ocupa 3 bytes. (3 * 4) + (100 * 3) = 312 bytes - esto es cuánto pesa una fila de nuestra tabla, y multiplicando esto por 500,000 filas obtenemos el peso de la tabla de product156 megabytes.
Por lo tanto, para almacenar esta etiqueta, se requieren 9750 clústeres en el disco duro (9750 páginas de 16 KB).
Al guardar en el disco, se toman grupos libres, lo que lleva a "manchar" los grupos de una placa (archivo) en todo el disco (esto se denomina fragmentación). La lectura de dichos bloques de memoria ubicados aleatoriamente en el disco se denomina lectura aleatoria. Esta lectura es más lenta porque debe mover el cabezal del disco duro muchas veces. Para leer el archivo completo, tenemos que saltar por todo el disco para obtener los clústeres necesarios.
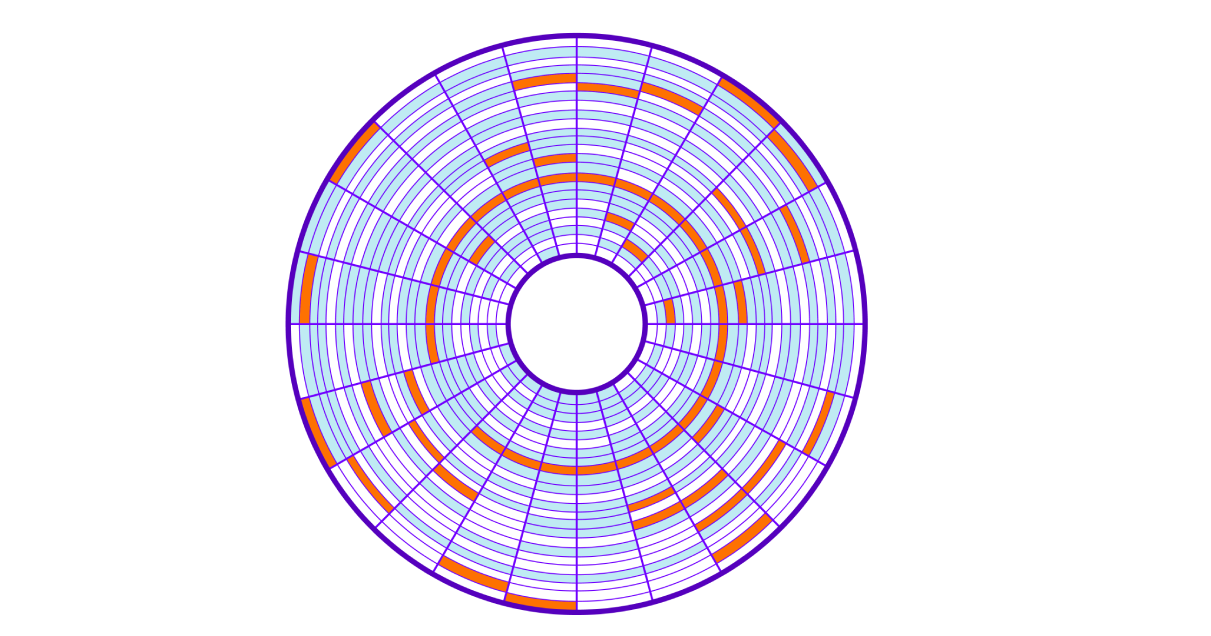
Volvamos a nuestra consulta SQL. Para encontrar todas las filas, el servidor tendrá que leer todos los clústeres 9750 dispersos por el disco y llevará mucho tiempo mover el cabezal de lectura del disco. Cuantos más clústeres usemos nuestros datos, más lento se buscará. Y además, nuestra operación obstruirá el sistema de E / S del sistema operativo.
Al final, obtenemos una velocidad de lectura baja; "Suspender" el sistema operativo, obstruyendo el sistema de E / S; y haga muchas comparaciones, verificando las condiciones de consulta para cada fila.
Mi propia bicicleta
¿Cómo podemos resolver este problema por nuestra cuenta?
Necesitamos descubrir cómo mejorar las búsquedas de tablas
product. Creemos otra tabla en la que solo almacenaremos el campo pricey el enlace al registro (área en disco) en nuestra tabla product. Tomemos como regla de inmediato que al agregar datos a una nueva tabla, almacenaremos los precios en forma ordenada.
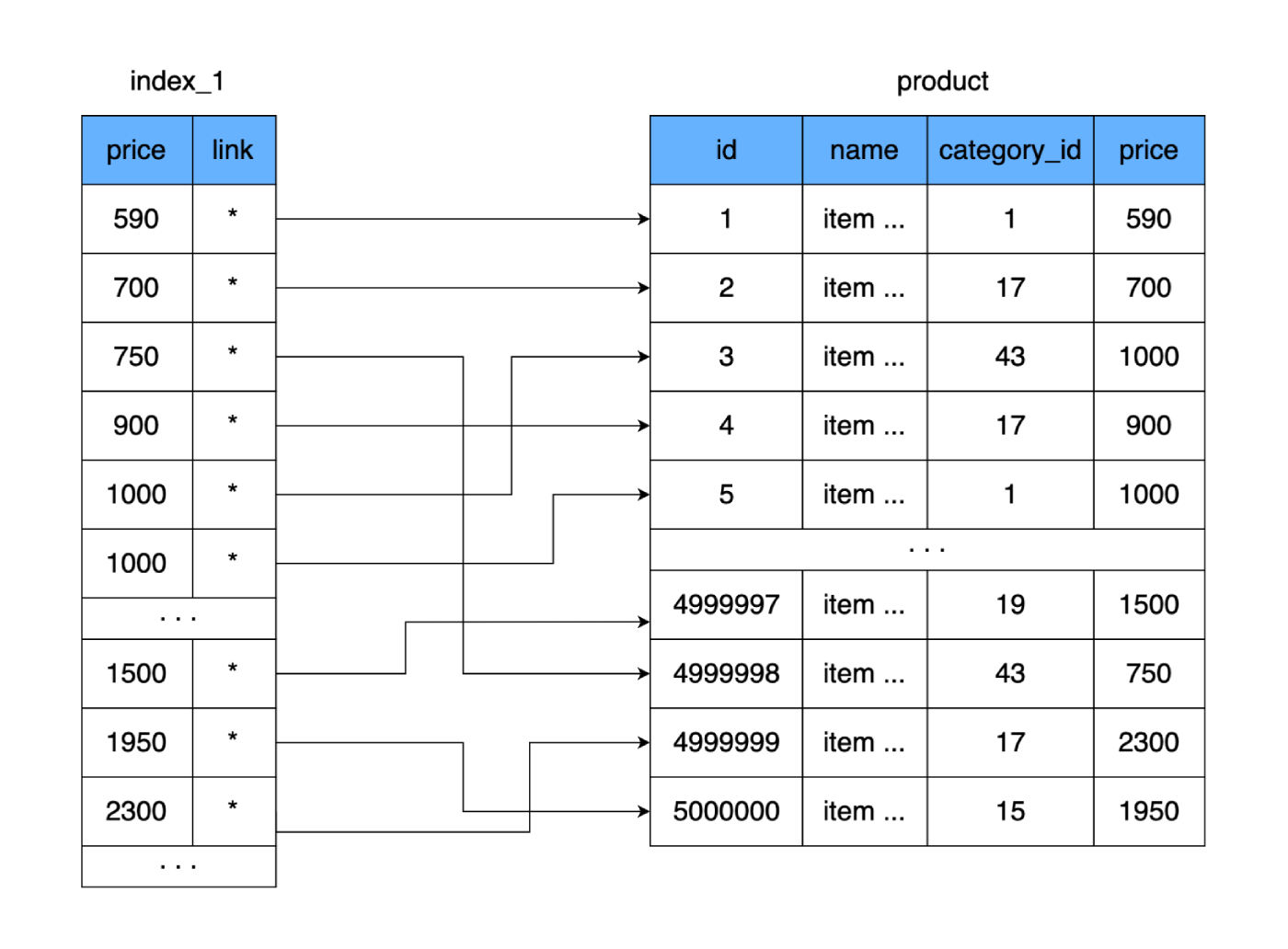
¿Qué nos aporta? La nueva tabla, como la principal, se almacena en el disco página por página (en bloques). Contiene el precio y un enlace a la tabla principal. Calculemos cuánto espacio ocupará una mesa de este tipo. El precio ocupa 4 bytes y la referencia a la tabla principal (dirección) también es de 4 bytes. Para 500.000 filas, nuestra nueva tabla solo pesará 4 MB. De esa manera, cabrán muchas más filas de la nueva tabla en una página de datos y se necesitarán menos páginas para almacenar todos nuestros precios.
Si una tabla completa requiere 9,750 clústeres de disco duro (en el peor de los casos, 9,750 saltos de disco duro), entonces la nueva tabla solo se ajusta a 250 clústeres. Debido a esto, la cantidad de clústeres usados en el disco se reducirá en gran medida y, por lo tanto, el tiempo dedicado a la lectura aleatoria. Incluso si leemos toda nuestra nueva tabla y comparamos los valores para encontrar el precio correcto, en el peor de los casos, se necesitarán 250 saltos en los grupos de la nueva tabla. Y después de encontrar la dirección requerida, leeremos otro clúster donde se encuentran los datos completos. Resultado: 251 lecturas frente a las 9750 originales. La diferencia es significativa.
Además, para buscar una tabla de este tipo, puede utilizar, por ejemplo, el algoritmo de búsqueda binaria (ya que la lista está ordenada). Esto ahorrará aún más en el número de lecturas y operaciones de comparación.
Llamemos índice a nuestra segunda tabla.
¡Hurra! ¡Hemos creado nuestro propio índice de
Pero detente: a medida que la tabla crece, el índice también se hará cada vez más grande y, finalmente, volveremos al problema original. La búsqueda volverá a tardar mucho.
Otro índice
¿Y si crea otro índice sobre el existente?
Solo que esta vez no escribiremos todos los valores de campo
price, sino que asociaremos un valor con toda la página (bloque) del índice. Es decir, aparecerá un nivel adicional de índice, que apuntará al conjunto de datos del índice anterior (la página del disco donde se almacenan los datos del primer índice).
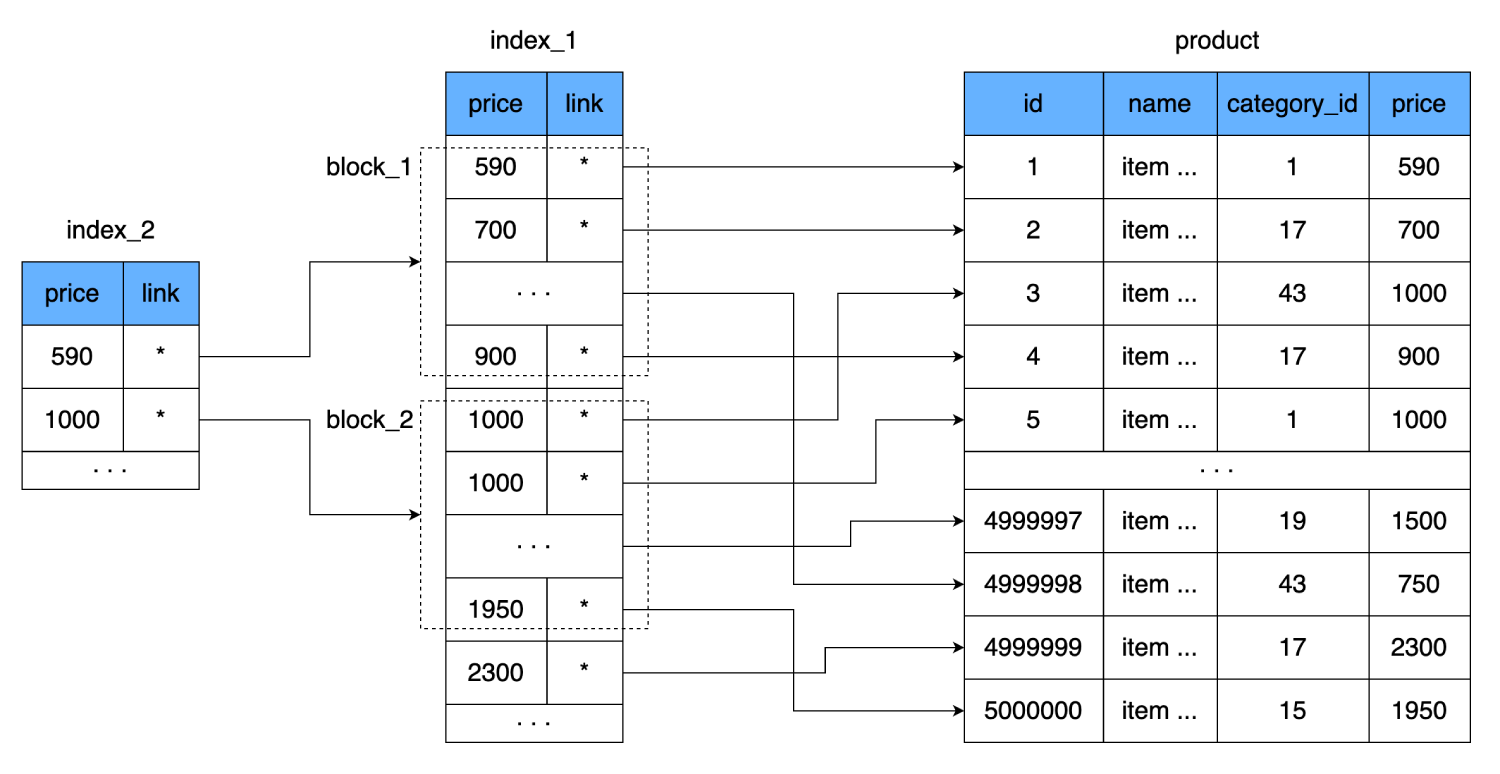
Esto reducirá aún más el número de lecturas. Una línea de nuestro índice ocupa 8 bytes, es decir, podemos colocar 2000 líneas de este tipo en una página de 16 kilobytes. El nuevo índice contendrá un enlace al bloque de 2000 líneas del primer índice y el precio a partir del cual comienza este bloque. Una de esas líneas también ocupa 8 bytes, pero su número se reduce drásticamente: en lugar de 500.000, solo 250. Incluso caben en un grupo de disco duro. Por lo tanto, para encontrar el precio deseado, podremos determinar exactamente en qué bloque de 2000 líneas se encuentra. Y en el peor de los casos, para encontrar el mismo registro, nosotros:
- Hagamos una lectura del nuevo índice.
- Después de recorrer 250 líneas, encontramos un enlace al bloque de datos del segundo índice.
- Consideramos un grupo, que contiene 2000 filas con precios y enlaces a la tabla principal.
- Una vez comprobadas estas 2000 líneas, encontraremos la necesaria y saltaremos una vez más por el disco para leer el último bloque de datos.
Obtendremos un total de 3 saltos de grupo.
Pero tarde o temprano este nivel también se llenará con una gran cantidad de datos. Por tanto, tendremos que repetir todo lo que hemos hecho, añadiendo un nuevo nivel una y otra vez. Es decir, necesitamos una estructura de datos de este tipo para almacenar el índice, que agregará nuevos niveles a medida que el tamaño del índice crezca y equilibre de forma independiente los datos entre ellos.
Si le damos la vuelta a las tablas para que el último índice esté arriba y la tabla principal con datos esté abajo, obtenemos una estructura muy similar a un árbol.
La estructura de datos del árbol B funciona con un principio similar, por lo que se eligió para estos fines.
Árboles B en breve
Los índices más comunes utilizados en MySQL son índices ordenados de árbol B (árbol de búsqueda equilibrado) .
La idea general de un árbol B es similar a nuestras tablas de índice. Los valores se almacenan en orden y todas las hojas del árbol están a la misma distancia de la raíz.
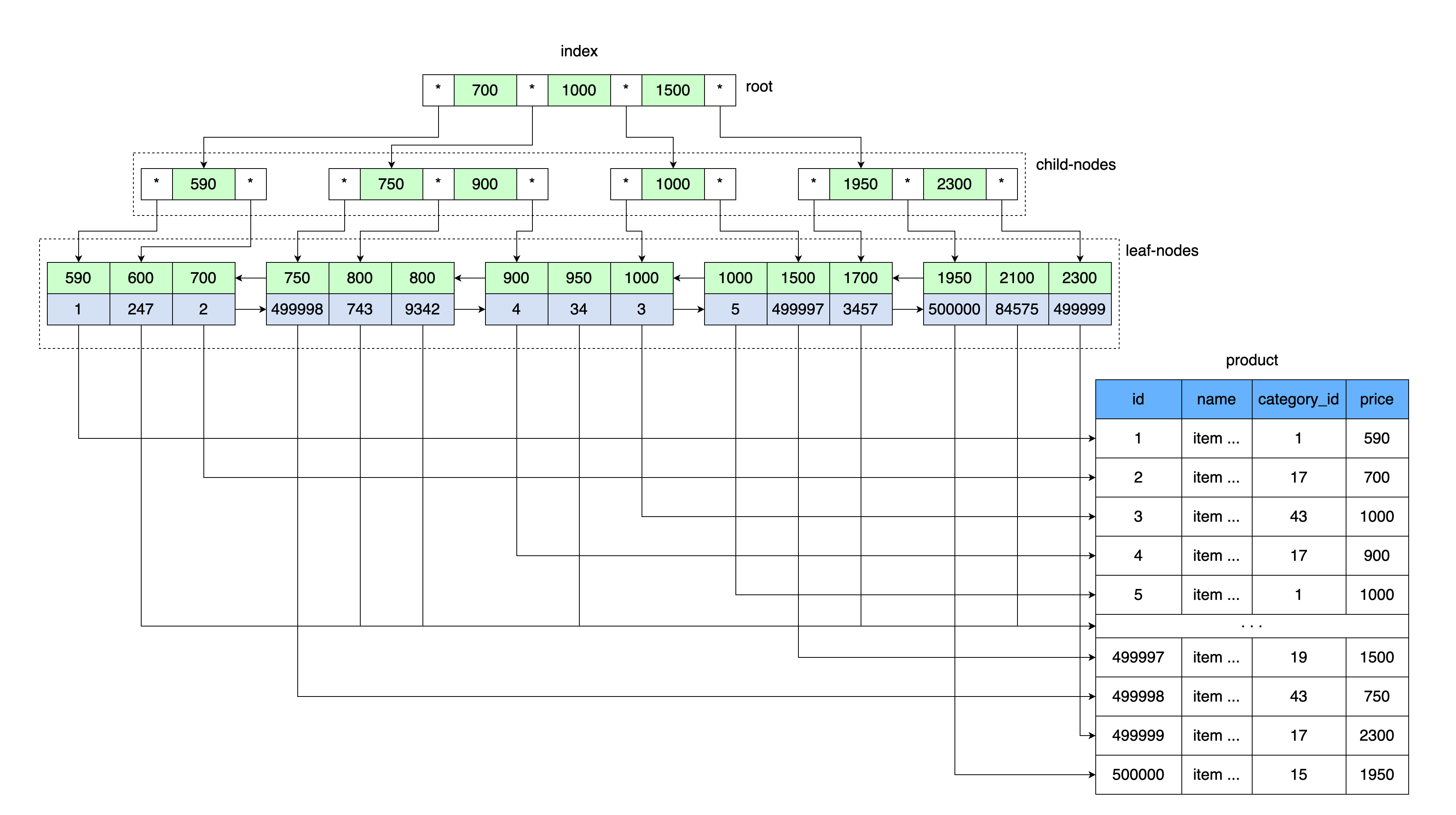
Así como nuestra tabla con un índice almacena un valor de precio y un enlace a un bloque de datos que contiene un rango de valores con este precio, la raíz del árbol B almacena un valor de precio y un enlace a un área de memoria en el disco.
Primero, se lee la página que contiene la raíz del árbol B. Además, después de ingresar el rango de claves, hay un puntero al nodo secundario deseado. Se lee la página del nodo hijo, desde donde se toma el enlace a la hoja de datos del valor clave, y se lee la página con los datos desde este enlace.
Árbol B en InnoDB
Más específicamente, InnoDB usa una estructura de datos de árbol B +.
Cada vez que crea una tabla, crea automáticamente un árbol B +, porque MySQL almacena dicho índice para las claves primaria y secundaria.
Las claves secundarias almacenan además los valores de la clave principal (clúster) como referencia a la fila de datos. En consecuencia, la clave secundaria crece según el tamaño del valor de la clave principal.
Además, los árboles B + utilizan enlaces adicionales entre los nodos secundarios, lo que aumenta la velocidad de búsqueda en un rango de valores. Lea más sobre la estructura de los índices de árbol b + en InnoDB aquí .
Resumiendo
El índice de árbol b proporciona una gran ventaja al buscar datos en un rango de valores debido a una reducción múltiple en la cantidad de información leída desde el disco. Participa no solo durante la búsqueda por condición, sino también durante las clasificaciones, uniones, agrupaciones. Lea cómo MySQL usa índices aquí .
La mayoría de las consultas a la base de datos son solo consultas para encontrar información por valor o por un rango de valores. Por lo tanto, en MySQL, el índice más utilizado es un índice de árbol b.
Además, el índice de árbol b ayuda con la recuperación de datos. Dado que la clave principal (índice agrupado) y el valor de la columna en la que se construye el índice no agrupado (clave secundaria) se almacenan en las hojas del índice, ya no se puede acceder a estos datos desde la tabla principal ni tomarlos del índice. A esto se le llama índice de cobertura. Puede encontrar más información sobre índices agrupados y no agrupados en este artículo .
Los índices, como las tablas, también se almacenan en el disco y ocupan espacio. Cada vez que se agrega información a la tabla, el índice debe mantenerse actualizado para monitorear la exactitud de todos los enlaces entre nodos. Esto crea una sobrecarga en la escritura de información, que es la principal desventaja de los índices b-tree. Sacrificamos la velocidad de escritura para aumentar la velocidad de lectura.
- MySQL . 3-
: ,
: 2018 - blog.jcole.us/innodb
- dev.mysql.com/doc/refman/8.0/en/innodb-storage-engine.html