Vayamos en orden. E inmediatamente un pequeño descargo de responsabilidad: el artículo fue escrito en base a mi discurso en Ya Subbotnik Pro para desarrolladores front-end. Si está involucrado en el backend, entonces, quizás, no descubrirá nada nuevo por sí mismo. Aquí intentaré resumir mi experiencia de frontend en una gran empresa, explicar por qué y cómo usamos Node.js.
Definamos lo que consideraremos como frontend en este artículo. Dejemos de lado las disputas sobre las tareas y centrémonos en la esencia.
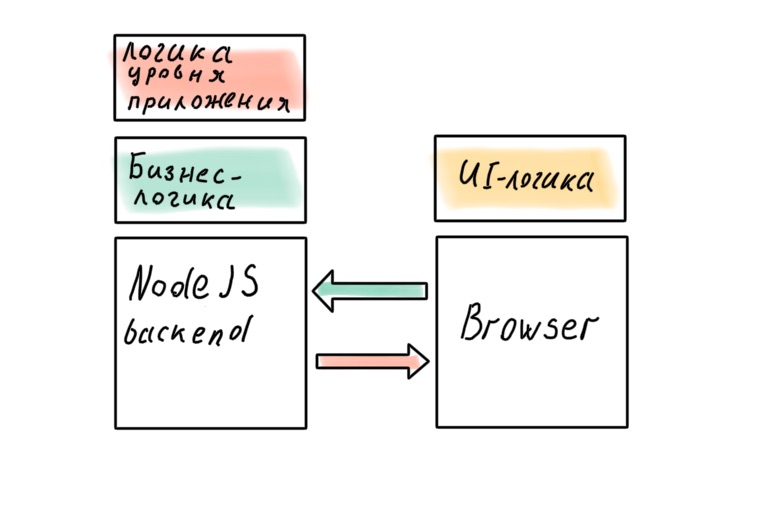
Frontend es la parte de la aplicación responsable de mostrar. Puede ser diferente: navegador, escritorio, móvil. Pero siempre hay una característica importante: la interfaz necesita datos. Sin un backend que proporcione estos datos, es inútil. Aquí hay un borde bastante claro. El backend sabe cómo ir a bases de datos, aplicar reglas de negocio a los datos recibidos y dar el resultado al frontend, que aceptará los datos, los modelará y le dará belleza al usuario.
Podemos decir que, conceptualmente, el frontend necesita el backend para recibir y guardar datos. Ejemplo: un sitio moderno típico con una arquitectura cliente-servidor. El cliente en el navegador (para llamarlo delgado, el idioma ya no cambiará) golpea el servidor donde se está ejecutando el backend. Y, por supuesto, hay excepciones en todas partes. Hay aplicaciones de navegador complejas que no necesitan un servidor (no consideraremos este caso), y es necesario ejecutar una interfaz en el servidor, lo que se llama Server Side Rendering o SSR. Empecemos por ello, porque este es el caso más simple y comprensible.
SSR
El mundo ideal para el backend se ve así: las solicitudes HTTP con datos llegan a la entrada de la aplicación, y en la salida tenemos una respuesta con nuevos datos en un formato conveniente. Por ejemplo JSON. Las API HTTP son fáciles de probar y comprenden cómo desarrollar. Sin embargo, la vida hace ajustes: a veces la API por sí sola no es suficiente.
El servidor debe responder con HTML listo para usar para enviarlo al rastreador del motor de búsqueda, generar una vista previa con metaetiquetas para insertarlas en la red social o, lo que es más importante, acelerar la respuesta en dispositivos débiles. Al igual que en la antigüedad cuando desarrollamos Web 2.0 en PHP.
Todo es familiar y se ha descrito durante mucho tiempo, pero el cliente ha cambiado: los motores de plantilla del lado del cliente imperativos han llegado a él. En la web moderna, JSX gobierna la pelota, cuyos pros y contras se pueden discutir durante mucho tiempo, pero una cosa no se puede negar: en la representación del servidor no se puede prescindir del código JavaScript.
Resulta que cuando necesita implementar SSR mediante el desarrollo de back-end:
- Las áreas de responsabilidad son mixtas. Los programadores backend están empezando a estar a cargo del renderizado.
- Los idiomas se mezclan. Los programadores de backend comienzan con JavaScript.
La salida es separar el SSR del backend. En el caso más simple, tomamos un tiempo de ejecución de JavaScript, le colocamos una solución autoescrita o un marco (Next, Nuxt, etc.) que funciona con el motor de plantillas de JavaScript que necesitamos y pasamos el tráfico a través de él. Un patrón familiar en el mundo moderno.
Así que ya hemos permitido que los desarrolladores de aplicaciones para el usuario accedan un poco al servidor. Pasemos a un tema más importante.
Recibiendo información
Una solución popular es crear API genéricas. Esta función la asume con mayor frecuencia API Gateway, que puede sondear una variedad de microservicios. Sin embargo, aquí también surgen problemas.
Primero, el problema de los equipos y las áreas de responsabilidad. Muchos equipos desarrollan una gran aplicación moderna. Cada equipo se centra en su dominio empresarial, tiene su propio microservicio (o incluso varios) en el backend y sus propias pantallas en el cliente. No entraremos en el problema de los microfrontes y la modularidad, este es un tema complejo separado. Suponga que las vistas del cliente están completamente separadas y son mini-SPA (aplicación de una sola página) dentro de un sitio grande.
Cada equipo tiene desarrolladores front-end y back-end. Todos están trabajando en su propia aplicación. API Gateway puede ser un obstáculo. ¿Quién es el responsable de esto? ¿Quién agregará nuevos puntos finales? ¿Un superequipo de API dedicado que siempre estará ocupado resolviendo problemas para todos los demás en el proyecto? ¿Cuál será el costo de un error? La caída de esta puerta de enlace acabará con todo el sistema.
En segundo lugar, el problema de los datos redundantes / insuficientes. Echemos un vistazo a lo que sucede cuando dos interfaces diferentes usan la misma API genérica.

Estas dos interfaces son muy diferentes. Necesitan diferentes conjuntos de datos, tienen diferentes ciclos de lanzamiento. La variabilidad de versiones del frontend móvil es máxima, por lo que nos vemos obligados a diseñar la API con la máxima compatibilidad con versiones anteriores. La variabilidad del cliente web es baja, de hecho solo necesitamos admitir una versión anterior para reducir la cantidad de errores en el momento del lanzamiento. Pero incluso si la API "genérica" solo sirve a clientes web, todavía nos enfrentamos al problema de datos redundantes o insuficientes.
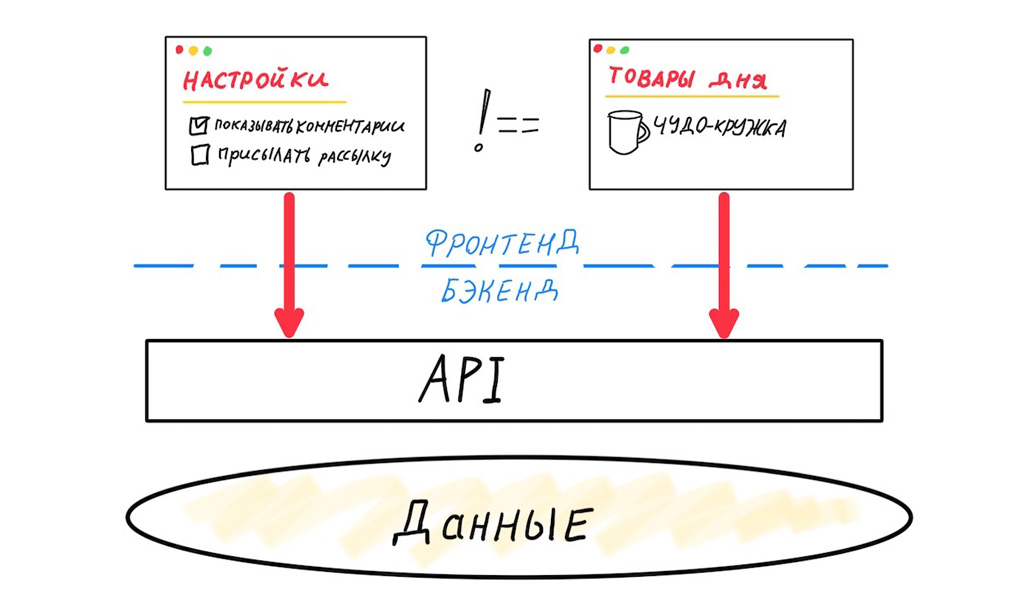
Cada mapeo requiere un conjunto de datos separado, que se puede recuperar con una consulta óptima.
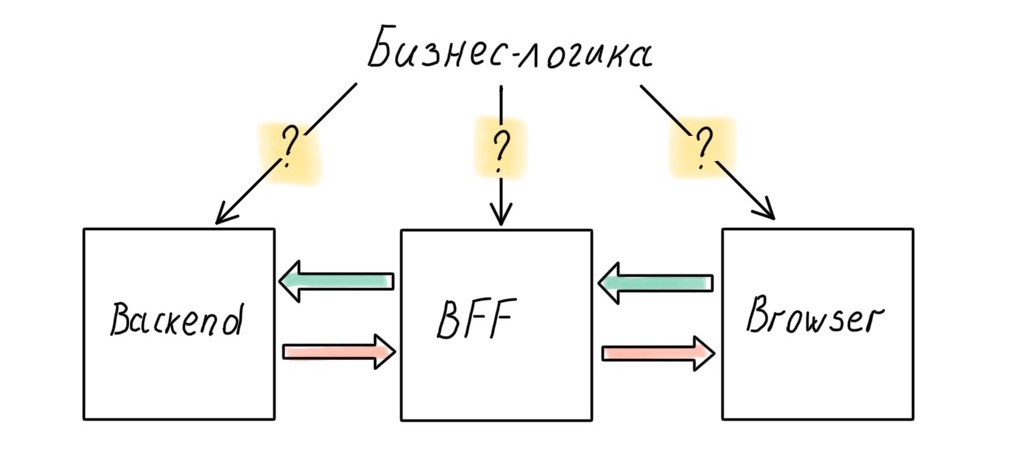
En este caso, una API universal no nos funcionará, tendremos que separar las interfaces. Esto significa que necesita su propia API Gateway para cadaInterfaz. La palabra "cada uno" aquí denota un mapeo único que opera en su propio conjunto de datos.

Podemos confiar la creación de dicha API a un desarrollador de backend que tendrá que trabajar con el frontend e implementar sus deseos o, lo que es mucho más interesante y en muchos sentidos más efectivo, entregar la implementación de la API al equipo de frontend. Esto eliminará el dolor de cabeza debido a la implementación de SSR: ya no es necesario instalar una capa que golpee la API, todo se integrará en una aplicación de servidor. Además, al controlar el SSR, podemos poner todos los datos primarios necesarios en la página en el momento de la renderización, sin realizar solicitudes adicionales al servidor.
Esta arquitectura se llama Backend For Frontend o BFF. La idea es simple: aparece una nueva aplicación en el servidor que escucha las solicitudes de los clientes, sondea los backends y devuelve la respuesta óptima. Y, por supuesto, esta aplicación está controlada por el desarrollador front-end.

¿Más de un servidor en el backend? ¡No es un problema!

Independientemente del protocolo de comunicación que prefiera el desarrollo de backend, podemos utilizar cualquier forma conveniente de comunicarnos con el cliente web. REST, RPC, GraphQL: nosotros mismos lo elegimos.
Pero, ¿no es GraphQL en sí mismo la solución al problema de obtener datos en una sola consulta? ¿Quizás no necesita vallar ningún servicio intermedio?
Desafortunadamente, el trabajo eficiente con GraphQL es imposible sin una cooperación cercana con los desarrolladores de backend que asumen la tarea de desarrollar consultas de bases de datos eficientes. Al elegir una solución de este tipo, volveremos a perder el control sobre los datos y volveremos al punto de partida.

Es posible, por supuesto, pero no interesante (para una interfaz)
Bueno, implementemos BFF. Por supuesto, en Node.js. ¿Por qué? Necesitamos un solo idioma en el cliente y el servidor para reutilizar la experiencia de los desarrolladores front-end y JavaScript para trabajar con plantillas. ¿Qué pasa con otros entornos de ejecución?

GraalVM y otras soluciones exóticas tienen un rendimiento inferior al V8 y son demasiado específicas. Deno sigue siendo un experimento y no se utiliza en producción.
Y un momento. Node.js es una solución sorprendentemente buena para implementar API Gateway. La arquitectura de nodo permite un intérprete de JavaScript de un solo subproceso combinado con libuv, una biblioteca de E / S asíncrona que a su vez utiliza un grupo de subprocesos.
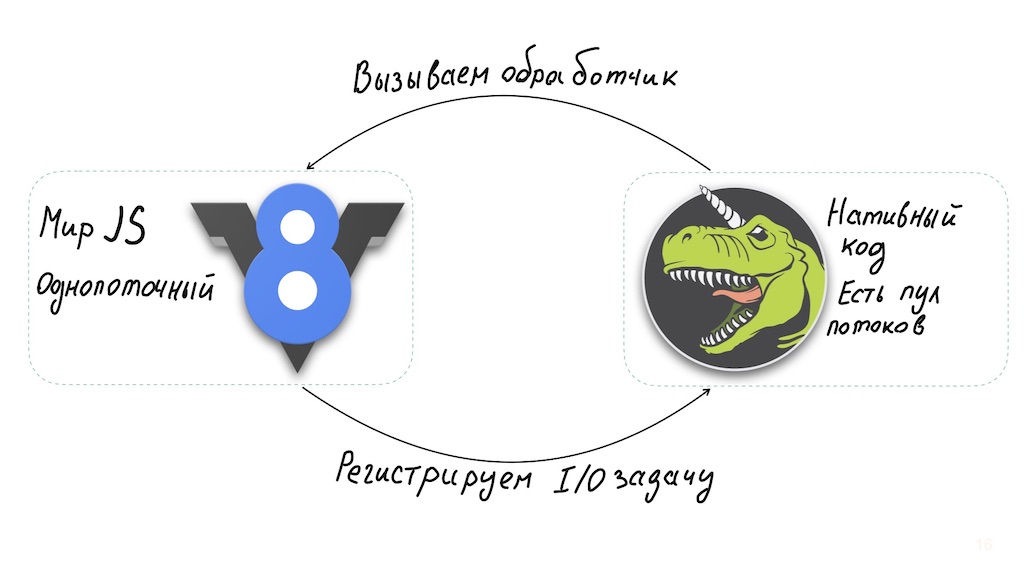
Los cálculos largos en el lado de JavaScript afectan el rendimiento del sistema. Puede solucionar esto: ejecútelos en trabajadores separados o llévelos al nivel de módulos binarios nativos.
Pero en el caso básico, Node.js no es adecuado para operaciones con uso intensivo de CPU y, al mismo tiempo, funciona muy bien con E / S asíncronas, proporcionando un alto rendimiento. Es decir, obtenemos un sistema que siempre puede responder rápidamente al usuario, independientementesobre qué tan ocupado está el backend. Puede manejar esta situación notificando instantáneamente al usuario que espere el final de la operación.
Dónde almacenar la lógica empresarial
Nuestro sistema ahora tiene tres partes grandes: backend, frontend y BFF en el medio. Surge una pregunta razonable (para un arquitecto): ¿dónde guardar la lógica empresarial?

Por supuesto, un arquitecto no quiere difundir las reglas comerciales en todas las capas del sistema; debe haber una sola fuente de verdad. Y esa fuente es el backend. ¿Dónde más almacenar las políticas de alto nivel, si no en la parte del sistema más cercana a los datos?

Pero en realidad, esto no siempre funciona. Por ejemplo, surge un problema comercial que se puede implementar de manera rápida y eficiente a nivel de BFF. El diseño perfecto del sistema es genial, pero el tiempo es dinero. A veces hay que sacrificar la limpieza de la arquitectura y las capas comienzan a gotear.
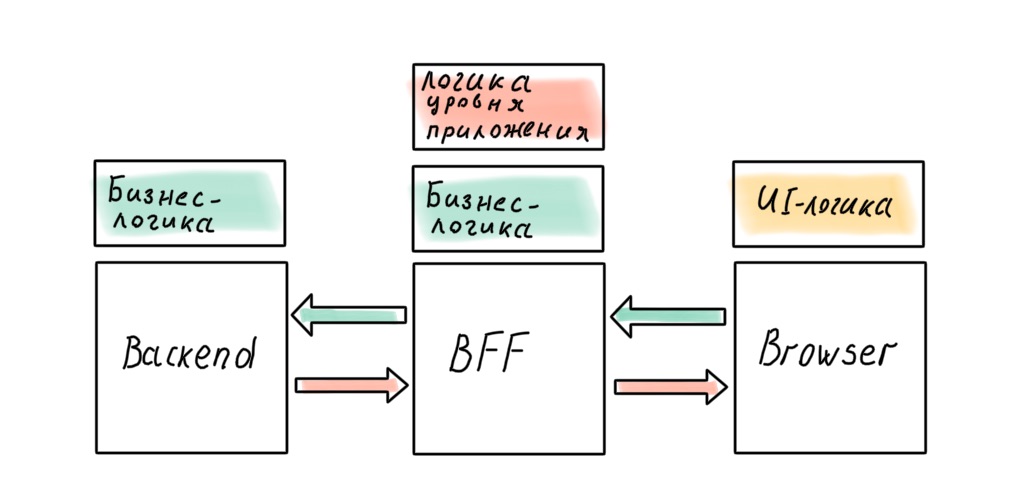
¿Podemos obtener la arquitectura perfecta abandonando el BFF en favor de un backend de Node.js "completo"? Parece que en este caso no habrá fugas.
No es un hecho. Habrá reglas comerciales que, si se transfieren al servidor, afectarán la capacidad de respuesta de la interfaz. Puede resistir esto hasta el final, pero lo más probable es que no pueda evitarlo por completo. La lógica a nivel de aplicación también penetrará en el cliente: en el SPA moderno, se difunde entre el cliente y el servidor, incluso en el caso de que haya un BFF.

No importa cuánto lo intentemos, la lógica empresarial se infiltrará en API Gateway en Node.js. Arreglemos esta conclusión y pasemos a la implementación más deliciosa.
Gran bola de barro
La solución más popular para las aplicaciones Node.js en los últimos años es Express. Probado, pero de muy bajo nivel y no ofrece buenos enfoques arquitectónicos. El patrón principal es el middleware. Una aplicación típica en el Express como un gran trozo de barro (no es sobrenombre y antipatrón ).
const express = require('express');
const app = express();
const {createReadStream} = require('fs');
const path = require('path');
const Joi = require('joi');
app.use(express.json());
const schema = {id: Joi.number().required() };
app.get('/example/:id', (req, res) => {
const result = Joi.validate(req.params, schema);
if (result.error) {
res.status(400).send(result.error.toString()).end();
return;
}
const stream = createReadStream( path.join('..', path.sep, `example${req.params.id}.js`));
stream
.on('open', () => {stream.pipe(res)})
.on('error', (error) => {res.end(error.toString())})
});Todas las capas están mezcladas, en un archivo hay un controlador, donde todo está ahí: lógica de infraestructura, validación, lógica de negocios. Es doloroso trabajar con esto, no quiero mantener ese código. ¿Podemos escribir código de nivel empresarial en Node.js?

Esto requiere una base de código que sea fácil de mantener y desarrollar. En otras palabras, necesitas arquitectura.
Arquitectura de la aplicación Node.js (finalmente)
"El objetivo de la arquitectura de software es reducir el esfuerzo humano involucrado en la construcción y mantenimiento de un sistema".
Robert "Tío Bob" Martin
La arquitectura consta de dos cosas importantes: las capas y las conexiones entre ellas. Debemos dividir nuestra aplicación en capas, evitar fugas de una a otra, organizar adecuadamente la jerarquía de capas y las conexiones entre ellas.
Capas
¿Cómo divido mi aplicación en capas? Existe un enfoque clásico de tres niveles: datos, lógica, presentación.
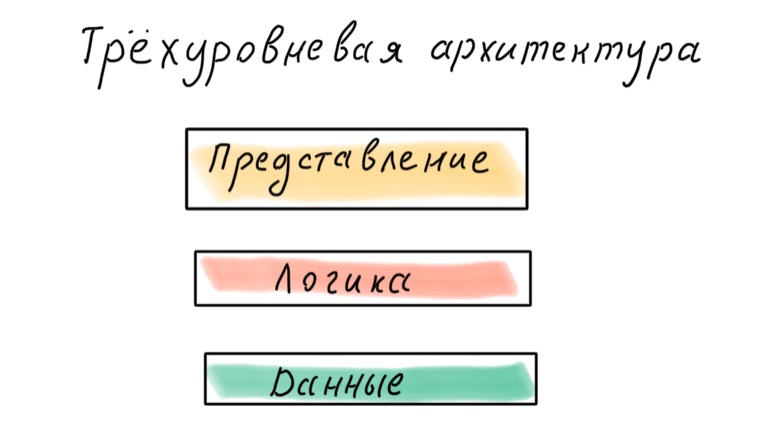
Este enfoque ahora se considera obsoleto. El problema es que los datos son la base, lo que significa que la aplicación se diseña en función de cómo se presenten los datos en la base de datos y no de en qué procesos de negocio participan.
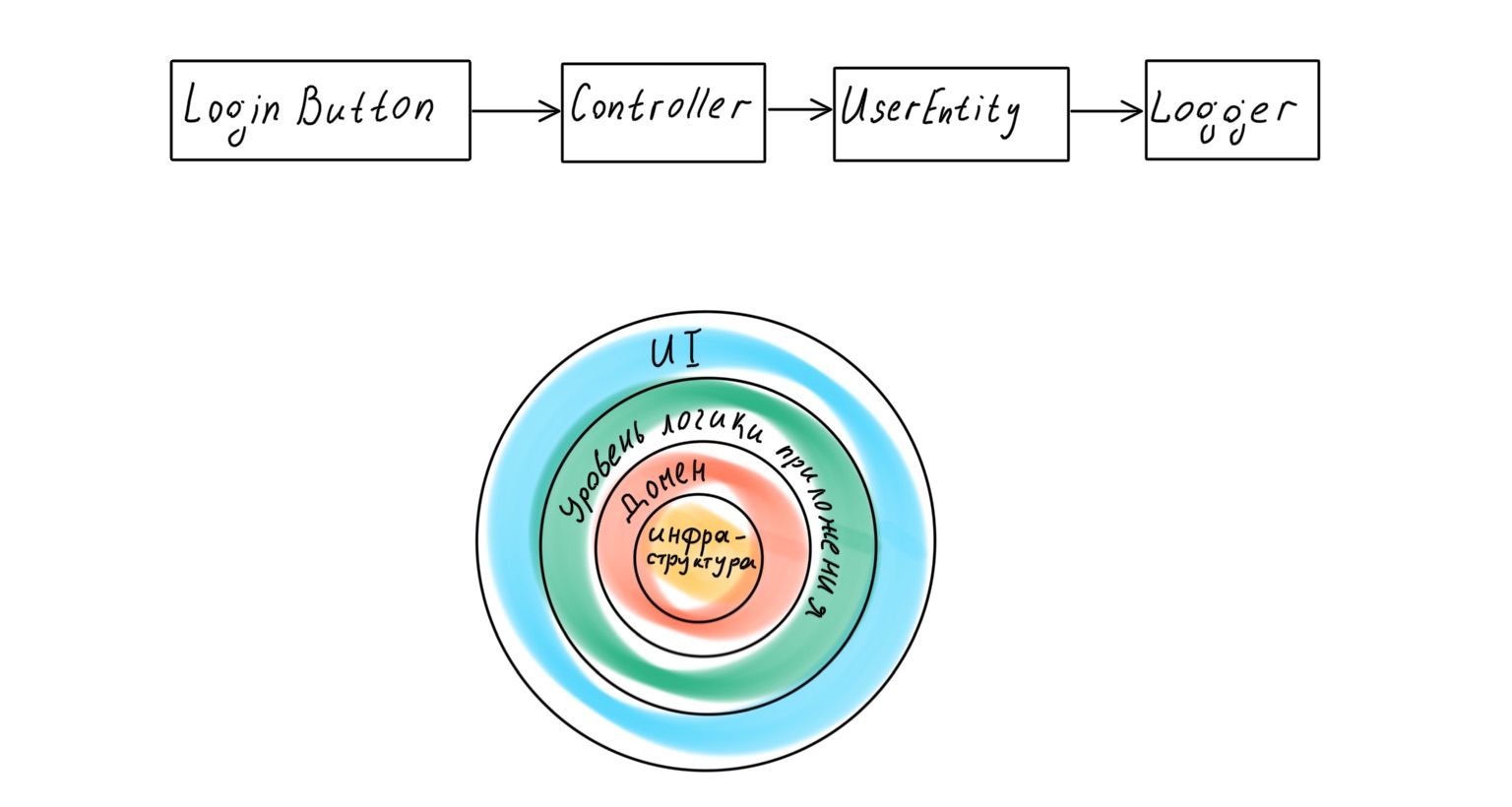
Un enfoque más moderno supone que la aplicación tiene una capa de dominio dedicada que funciona con la lógica empresarial y es una representación de los procesos empresariales reales en código. Sin embargo, si pasamos al trabajo clásico de Eric Evans Domain-Driven Design , encontraremos allí el siguiente esquema de capas de aplicación:

¿Qué pasa aquí? Parecería que la base de una aplicación diseñada por DDD debería ser un dominio: políticas de alto nivel, la lógica más importante y valiosa. Pero debajo de esta capa se encuentra toda la infraestructura: capa de acceso a datos (DAL), registro, monitoreo, etc. Es decir, políticas de un nivel mucho más bajo y de menor importancia.
La infraestructura está en el centro de la aplicación y un reemplazo banal del registrador puede llevar a una reorganización de toda la lógica empresarial.
Si volvemos a mirar a Robert Martin, nos encontramos con que en el libro Clean Architecture postula una jerarquía de capas diferente en la aplicación, con el dominio en el centro.
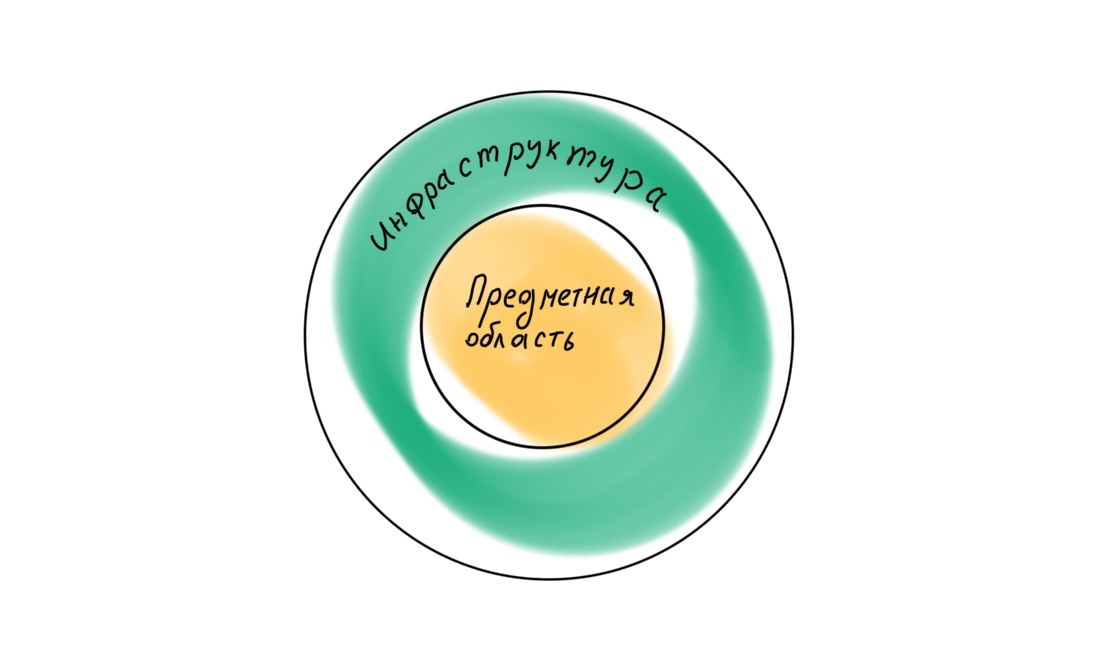
En consecuencia, las cuatro capas deben organizarse de manera diferente:
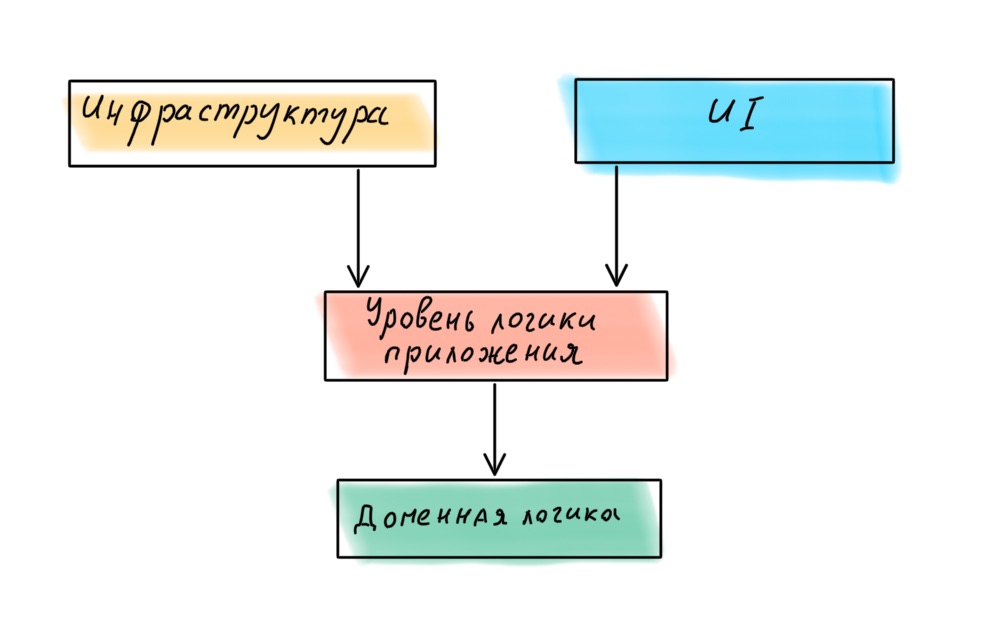
hemos seleccionado las capas y definido su jerarquía. Ahora pasemos a las conexiones.
Conexiones
Volvamos al ejemplo con la llamada lógica de usuario. ¿Cómo deshacerse de la dependencia directa de la infraestructura para garantizar la jerarquía de capas correcta? Existe una forma sencilla y conocida de revertir las dependencias: las interfaces.

Ahora la UserEntity de alto nivel no depende del Logger de bajo nivel. Por el contrario, dicta el contrato que se debe implementar para incluir el Logger en el sistema. Reemplazar el registrador en este caso se reduce a conectar una nueva implementación que observe el mismo contrato. Una pregunta importante es cómo conectarlo.
import {Logger} from ‘../core/logger’;
class UserEntity {
private _logger: Logger;
constructor() {
this._logger = new Logger();
}
...
}
...
const UserEntity = new UserEntity();Las capas están conectadas rígidamente. Existe un vínculo con la estructura y la implementación del archivo. Necesitamos Inversión de dependencias, lo que haremos usando Inyección de dependencias.
export class UserEntity {
constructor(private _logger: ILogger) { }
...
}
...
const logger = new Logger();
const UserEntity = new UserEntity(logger);Ahora el "dominio" UserEntity no sabe nada más sobre la implementación del registrador. Proporciona un contrato y espera que la implementación se ajuste a ese contrato.
Por supuesto, generar instancias de entidades de infraestructura manualmente no es lo más agradable. Necesitamos un archivo raíz en el que prepararemos todo, tendremos que arrastrar de alguna manera la instancia creada del registrador por toda la aplicación (es ventajoso tener uno, no crear muchos). Fatigoso. Y aquí es donde entran en juego los contenedores de IoC y pueden hacerse cargo de este trabajo de bollerplate.
¿Cómo sería el uso de un contenedor? Por ejemplo, así:
export class UserEntity {
constructor(@Inject(LOGGER) private readonly _logger: ILogger){ }
}¿Que está pasando aqui? Usamos la magia de los decoradores y escribimos la instrucción: “Al crear una instancia de UserEntity, inyecte en su campo privado _logger una instancia de la entidad que se encuentra en el contenedor de IoC bajo el token LOGGER. Se espera que se ajuste a la interfaz ILogger ". Y luego, el contenedor de IoC hará todo por sí mismo.
Hemos seleccionado las capas, decidido cómo las desataremos. Es hora de elegir un marco.
Marcos y arquitectura
La pregunta es simple: al dejar Express por un marco moderno, ¿obtendremos una buena arquitectura? Echemos un vistazo a Nest:
- escrito en TypeScript,
- construido sobre Express / Fastify, hay compatibilidad a nivel de middleware,
- declara la modularidad de la lógica,
- proporciona un contenedor de IoC.
¡Parece tener todo lo que necesitamos aquí! También dejaron el concepto de aplicación como cadena de middleware. Pero, ¿qué pasa con la buena arquitectura?
Inyección de dependencia en Nest
Intentemos seguir las instrucciones . Dado que en Nest el término Entidad generalmente se aplica a ORM, cambie el nombre de UserEntity a UserService. El registrador es proporcionado por el marco, por lo que inyectaremos el FooService abstracto en su lugar.
import {FooService} from ‘../services/foo.service’;
@Injectable()
export class UserService {
constructor(
private readonly _fooService: FooService
){ }
}Y ... ¡parece que dimos un paso atrás! Hay una inyección, pero no hay inversión, la dependencia está
dirigida a la implementación, no a la abstracción.
Intentemos arreglarlo. Opción número uno:
@Injectable()
export class UserService {
constructor(
private _fooService: AbstractFooService
){ } }Describimos y exportamos este servicio abstracto en algún lugar cercano:
export {AbstractFooService};FooService ahora usa AbstractFooService. Como tal, lo registramos manualmente en el IoC.
{ provide: AbstractFooService, useClass: FooService }Segunda opción. Probemos el enfoque descrito anteriormente con interfaces. Dado que no hay interfaces en JavaScript, no será posible extraer la entidad requerida de IoC en tiempo de ejecución mediante la reflexión. Tenemos que indicar explícitamente lo que necesitamos. Usaremos el decorador @ Inject para esto.
@Injectable()
export class UserService {
constructor(
@Inject(FOO_SERVICE) private readonly _fooService: IFooService
){ } }Y registrarse por token:
{ provide: FOO_SERVICE, useClass: FooService }¡Hemos ganado el marco! ¿Pero a qué precio? Hemos desactivado bastante azúcar. Esto es sospechoso y sugiere que no debería agrupar toda la aplicación en un marco. Si aún no te he convencido, hay otros problemas.
Excepciones
Nest se ilumina con excepciones. Además, sugiere usar el lanzamiento de excepciones para describir la lógica del comportamiento de la aplicación.
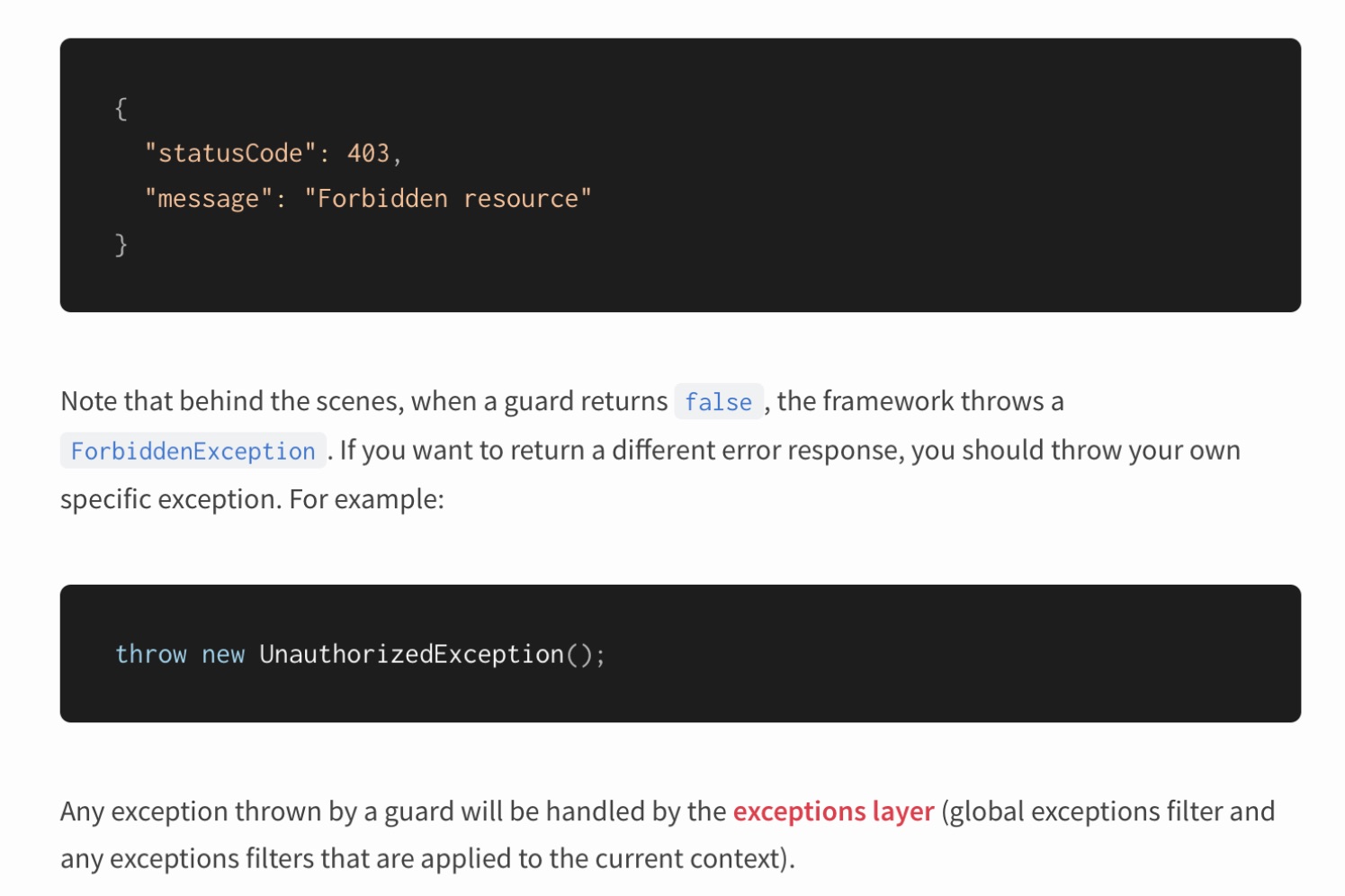
¿Está todo bien aquí en términos de arquitectura? Volvamos a las luminarias nuevamente:
"Si el error es el comportamiento esperado, entonces no debería usar excepciones".Las excepciones sugieren una situación excepcional. Al escribir lógica empresarial, debemos evitar lanzar excepciones. Aunque solo sea por la razón de que ni JavaScript ni TypeScript garantizan que se manejará la excepción. Además, ofusca el flujo de ejecución, comenzamos a programar en el estilo GOTO, lo que significa que mientras examina el comportamiento del código, el lector tendrá que saltar por todo el programa.
Martin Fowler

Existe una regla general simple para ayudarlo a comprender si el uso de excepciones es legal:
"¿Funcionará el código si elimino todos los controladores de excepciones?" Si la respuesta es no, entonces quizás se utilicen excepciones en circunstancias no excepcionales ".¿Es posible evitar esto en la lógica empresarial? ¡Si! Es necesario minimizar las excepciones de lanzamiento, y para devolver convenientemente el resultado de operaciones complejas, use la mónada Either , que proporciona un contenedor en un estado de éxito o error (un concepto muy cercano a Promise).
El programador pragmático
const successResult = Result.ok(false);
const failResult = Result.fail(new ConnectionError())Desafortunadamente, dentro de las entidades proporcionadas por Nest, a menudo no podemos actuar de otra manera: tenemos que lanzar excepciones. Así es como funciona el marco y esta es una característica muy desagradable. Y nuevamente surge la pregunta: ¿tal vez no debería actualizar la aplicación con un marco? ¿Quizás será posible separar el marco y la lógica empresarial en diferentes capas arquitectónicas?
Vamos a revisar.
Anidar entidades y capas arquitectónicas
La cruda verdad de la vida: todo lo que escribimos con Nest se puede apilar en una sola capa. Esta es la capa de aplicación.
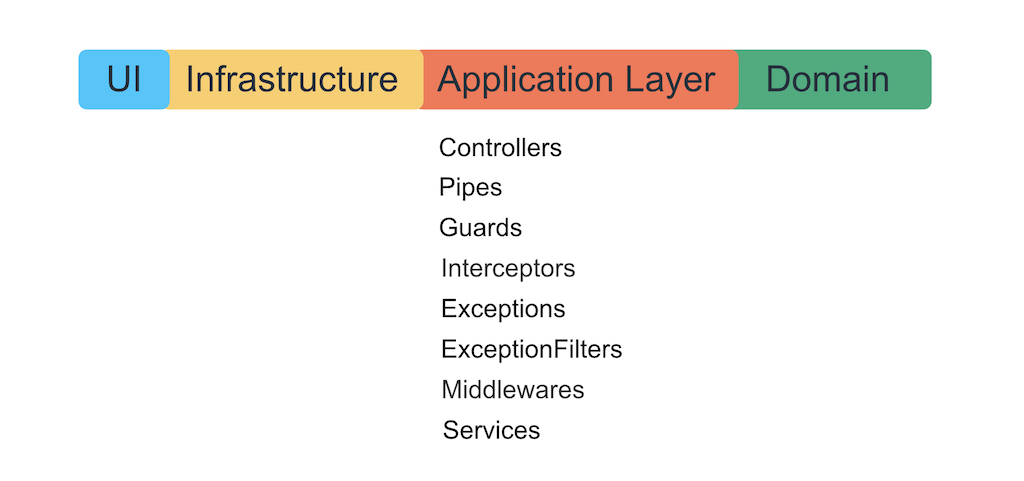
No queremos dejar que el marco se adentre más en la lógica empresarial, para que no se convierta en ella con sus excepciones, decoradores y contenedor de IoC. Los autores del marco mostrarán lo bueno que es escribir lógica empresarial utilizando su azúcar, pero su tarea es atarte a ellos para siempre. Recuerde que un marco es solo una forma de organizar convenientemente la lógica a nivel de la aplicación, conectar la infraestructura y la interfaz de usuario.

"Un marco es un detalle".
Robert "Tío Bob" Martin
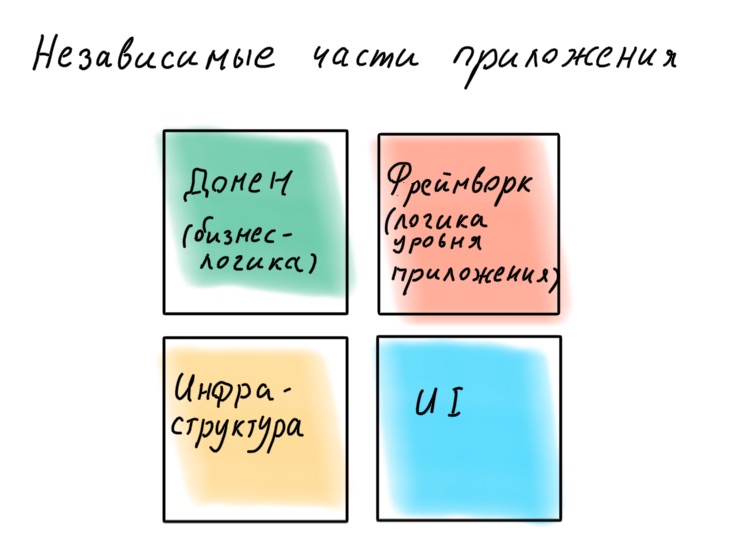
Es mejor diseñar una aplicación como un constructor en el que sea fácil reemplazar componentes. Un ejemplo de tal implementación es la arquitectura hexagonal (arquitectura de puerto y adaptador ). La idea es interesante: el núcleo del dominio con toda la lógica empresarial proporciona puertos para comunicarse con el mundo exterior. Todo lo que se necesita se conecta externamente a través de adaptadores.
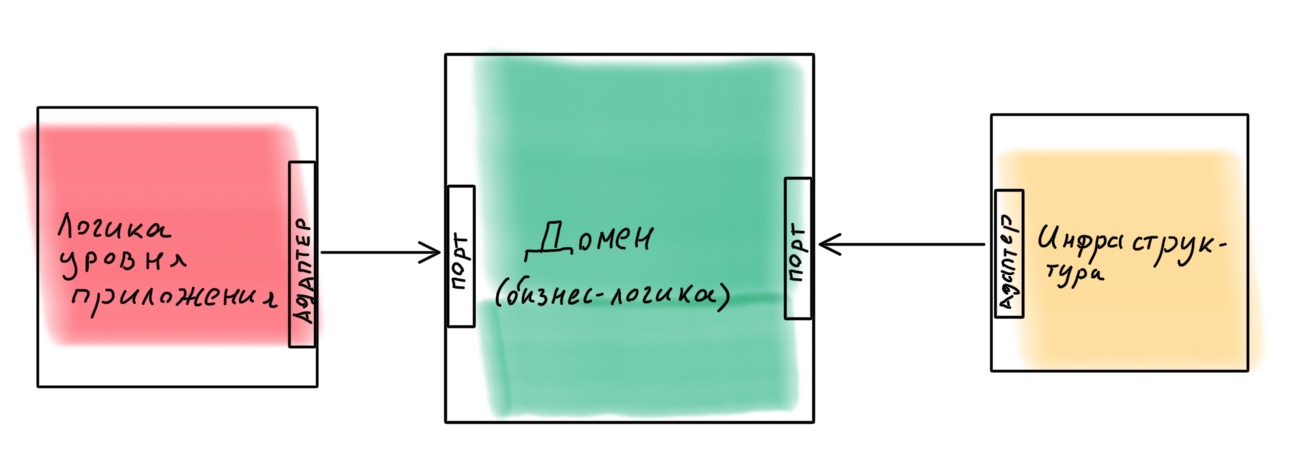
¿Es realista implementar una arquitectura de este tipo en Node.js usando Nest como marco? Bastante. Hice una lección con un ejemplo, si está interesado, puede encontrarlo aquí .
Resumamos
- Node.js es bueno para los mejores amigos. Puedes vivir con ella.
- No hay soluciones listas para usar.
- Los marcos no son importantes.
- Si su arquitectura se vuelve demasiado compleja, si se encuentra escribiendo, es posible que haya elegido la herramienta incorrecta.
Recomiendo estos libros:
- Robert Martin, "Arquitectura limpia",
- Vaughn Vernon, Domain-Driven Design Distilled,
- Khalil Stemmler, khalilstemmler.com,
- Martin Fowler, martinfowler.com/architecture.