En nuestra empresa, estamos trabajando activamente en la abstracción automática de documentos, este artículo no incluyó todos los detalles y el código, pero describió los principales enfoques y resultados utilizando el ejemplo de un conjunto de datos neutral: 30.000 artículos de noticias de deportes de fútbol recopilados del portal de información Sport-Express.
Entonces, el resumen se puede definir como la creación automática de un resumen (título, resumen, anotación) del texto original. Hay 2 enfoques significativamente diferentes para este problema: extractivo y abstractivo.
Resumen extractivo
El enfoque extractivo consiste en extraer los bloques de información más "significativos" del texto fuente. Un bloque puede ser un solo párrafo, oraciones o palabras clave.

Los métodos de este enfoque se caracterizan por la presencia de una función de evaluación de la importancia del bloque de información. Al clasificar estos bloques en orden de importancia y elegir un número previamente especificado de ellos, formamos el resumen final del texto.
Pasemos a la descripción de algunos enfoques extractivos.
Suma extractiva basada en la aparición de palabras comunes
Este algoritmo es muy sencillo de comprender y de implementar. Aquí solo trabajamos con código fuente y, en general, no tenemos necesidad de entrenar ningún modelo de extracción. En mi caso, los bloques de información recuperados representarán determinadas frases de texto.
Entonces, en el primer paso, dividimos el texto de entrada en oraciones y dividimos cada oración en fichas (palabras separadas), llevamos a cabo la lematización para ellas (llevando la palabra a la forma "canónica"). Este paso es necesario para que el algoritmo combine palabras que tienen un significado idéntico, pero que difieren en la forma de las palabras.
Luego establecemos la función de similitud para cada par de oraciones. Se calculará como la relación entre el número de palabras comunes que se encuentran en ambas oraciones y su longitud total.... Como resultado, obtenemos los coeficientes de similitud para cada par de oraciones.
Habiendo eliminado previamente las oraciones que no tienen palabras comunes con otras, construimos un gráfico donde los vértices son las oraciones mismas, cuyos bordes muestran la presencia de palabras comunes en ellas.
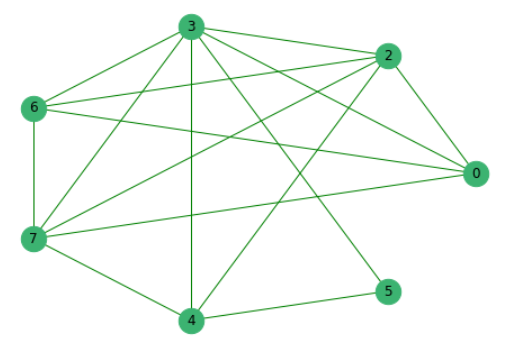
A continuación, clasificamos todas las propuestas según su importancia.

Al elegir varias oraciones con los coeficientes más altos y luego ordenarlas por el número de su aparición en el texto, obtenemos el resumen final.
Suma extractiva basada en representaciones de vectores entrenados
Los datos de noticias de texto completo recopilados previamente se utilizaron para construir el siguiente algoritmo.
Dividimos las palabras de todos los textos en fichas y las combinamos en una lista. En total, los textos contenían 2.270.778 palabras, de las cuales 114.247 eran únicas.
Usando el popular modelo Word2Vec, encontraremos su representación vectorial para cada palabra única. El modelo asigna vectores aleatorios a cada palabra y luego en cada paso del aprendizaje, “estudiando el contexto”, corrige sus valores. La dimensión del vector, que es capaz de "recordar" la característica de la palabra, puede establecer cualquiera. Según el volumen del conjunto de datos disponible, tomaremos vectores que constan de 100 números. También observo que Word2Vec es un modelo reentrable, que le permite enviar nuevos datos a la entrada y, en base a ellos, corregir las representaciones vectoriales existentes de palabras.
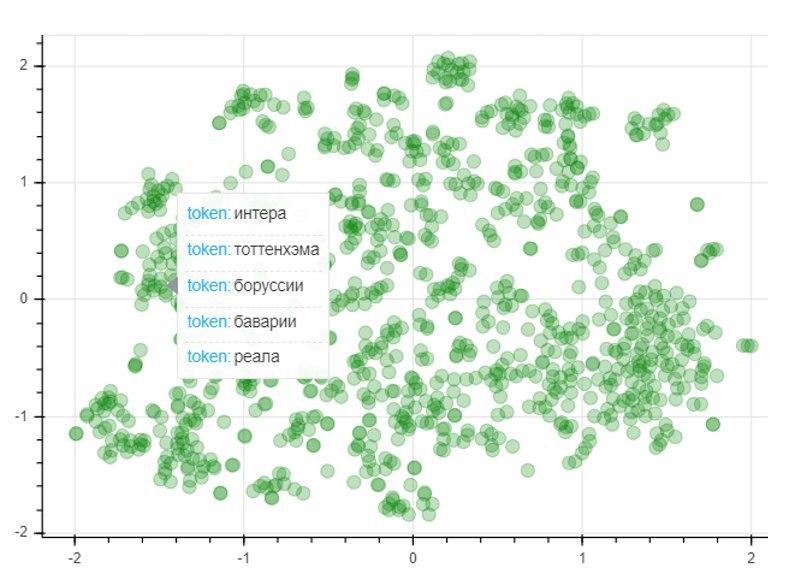
Para evaluar la calidad del modelo, utilizamos el método de reducción de dimensionalidad T-SNE, que construye iterativamente un mapeo vectorial para 1000 palabras más utilizadas en un espacio bidimensional. El gráfico resultante representa la ubicación de los puntos, cada uno de los cuales corresponde a una determinada palabra de tal manera que palabras similares en significado se ubican cerca unas de otras, y diferentes por el contrario. Entonces, en el lado izquierdo del gráfico están los nombres de los clubes de fútbol, y los puntos en la esquina inferior izquierda representan los nombres y apellidos de los jugadores y entrenadores de fútbol:
Después de obtener las representaciones vectoriales entrenadas de palabras, puede proceder al algoritmo en sí. Como en el caso anterior, en la entrada tenemos un texto que descomponemos en oraciones. Al tokenizar cada oración, componimos representaciones vectoriales para ellas. Para hacer esto, tomamos la razón de la suma de vectores para cada palabra en la oración a la longitud de la oración misma. Los vectores de palabras previamente entrenados nos ayudan aquí. Si no hay ninguna palabra en el diccionario, se agrega un vector cero al vector de oración actual. Así, neutralizamos la influencia de la aparición de una nueva palabra que no está en el diccionario sobre el vector general de la oración.
A continuación, redactamos una matriz de similitud de oraciones que utiliza la fórmula de similitud de coseno para cada par de oraciones.
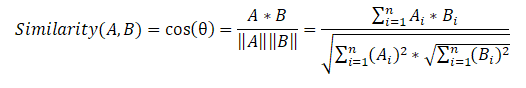
En la última etapa, con base en la matriz de similitud, también creamos un gráfico y realizamos una clasificación de oraciones por importancia. Como en el algoritmo anterior, obtenemos una lista de oraciones ordenadas por su importancia en el texto.

Al final, describiré esquemáticamente y una vez más describiré las etapas principales de la implementación del algoritmo (para el primer algoritmo extractivo, la secuencia de acciones es exactamente la misma, excepto que no necesitamos encontrar representaciones vectoriales de palabras, y la función de similitud para cada par de oraciones se calcula en función de la apariencia de comunes palabras):

- Dividir el texto de entrada en oraciones separadas y procesarlas.
- Busque una representación vectorial para cada oración.
- Calcular y almacenar similitudes entre vectores de oraciones en una matriz.
- Transformación de la matriz resultante en un gráfico con enunciados en forma de vértices y estimaciones de similitud en forma de aristas para calcular el rango de enunciados.
- Selección de propuestas con mayor puntuación para el currículum final.
Comparación de algoritmos extractivos
Usando el microframework Flask (una herramienta para crear aplicaciones web minimalistas ), se desarrolló un servicio web de prueba para comparar visualmente la salida de modelos extractivos usando el ejemplo de una variedad de textos de noticias fuente. Analicé el resumen generado por ambos modelos (recuperando las 2 frases más significativas) para 100 artículos de noticias deportivas diferentes.

Con base en los resultados de comparar los resultados de determinar las ofertas más relevantes de ambos modelos, puedo ofrecer las siguientes recomendaciones para usar los algoritmos:
- . , . , .
- . , , , . , , , .
Resumen abstractivo
El enfoque abstractivo se diferencia significativamente de su antecesor y consiste en generar un resumen con la generación de un nuevo texto, resumiendo de manera significativa el documento primario.
La idea principal de este enfoque es que el modelo puede generar un resumen completamente único, que puede contener palabras que no están en el texto original. La inferencia modelo es un recuento del texto, que está más cerca de la compilación manual de un resumen del texto por personas.
Fase de aprendizaje
No me detendré en la fundamentación matemática del algoritmo, todos los modelos que conozco se basan en la arquitectura "codificador-decodificador", que a su vez se construye utilizando capas LSTM recurrentes (puede leer sobre el principio de su trabajo aquí ). Describiré brevemente los pasos para decodificar la secuencia de prueba.
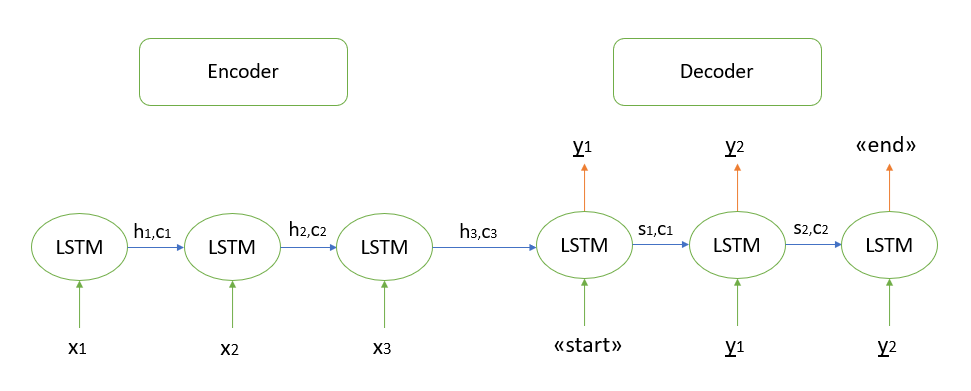
- Codificamos toda la secuencia de entrada e inicializamos el decodificador con los estados internos del codificador
- Pasa el token de "inicio" como entrada al decodificador
- Iniciamos el decodificador con los estados internos del codificador por un paso de tiempo, como resultado obtenemos la probabilidad de la siguiente palabra (palabra con la máxima probabilidad)
- Pase la palabra seleccionada como entrada al decodificador en el siguiente paso de tiempo y actualice los estados internos
- Repita los pasos 3 y 4 hasta que generemos el token "final".
Puede encontrar más detalles sobre la arquitectura "codificador-decodificador" aquí .
Implementando resumen abstractivo
Para construir un modelo abstractivo más complejo para extraer contenido resumido, se requieren tanto los textos completos de noticias como sus titulares. El titular de la noticia actuará como resumen, ya que el modelo “no recuerda bien” secuencias de texto largas.
Al limpiar los datos, utilizamos la traducción en minúsculas y descartamos los caracteres que no están en ruso. La lematización de palabras, la eliminación de preposiciones, partículas y otras partes del discurso no informativas tendrán un impacto negativo en el resultado final del modelo, ya que se perderá la relación entre las palabras de una oración.
A continuación, dividimos los textos y sus títulos en muestras de entrenamiento y prueba en una proporción de 9 a 1, después de lo cual los transformamos en vectores (aleatoriamente).
En el siguiente paso, creamos el propio modelo, que leerá los vectores de palabras que se le transmiten y realizará su procesamiento utilizando 3 capas recurrentes del codificador LSTM y 1 capa del decodificador.
Después de inicializar el modelo, lo entrenamos usando una función de pérdida de entropía cruzada que muestra la discrepancia entre el título objetivo real y el predicho por nuestro modelo.

Finalmente, generamos el resultado del modelo para el conjunto de entrenamiento. Como puede ver en los ejemplos, los textos fuente y los resúmenes contienen inexactitudes debido al descarte de palabras raras antes de construir el modelo (lo descartamos para “simplificar el aprendizaje”).

Los resultados del modelo en esta etapa dejan mucho que desear. El modelo "recuerda con éxito" algunos de los nombres de los clubes y los nombres de los jugadores, pero prácticamente no captó el contexto en sí.
A pesar del enfoque más moderno para reanudar la extracción, este algoritmo sigue siendo muy inferior a los modelos extractivos creados anteriormente. Sin embargo, para mejorar la calidad del modelo, es posible entrenar el modelo en un conjunto de datos más grande, pero, en mi opinión, para obtener un resultado de modelo realmente bueno, es necesario cambiar o, posiblemente, cambiar completamente la arquitectura de las redes neuronales utilizadas.
Entonces, ¿qué enfoque es mejor?
Resumiendo este artículo, enumeraré los principales pros y contras de los enfoques revisados para extraer un resumen:
1. Enfoque extractivo:
Ventajas:
- La esencia del algoritmo es intuitiva
- Relativa facilidad de implementación
Desventajas:
- En muchos casos, la calidad del contenido puede ser peor que el contenido escrito a mano por humanos
2. Enfoque abstracto:
ventajas:
- Un algoritmo bien implementado es capaz de producir un resultado más cercano a la escritura manual de un currículum.
Desventajas:
- Dificultades para percibir las principales ideas teóricas del algoritmo.
- Grandes costos laborales en la implementación del algoritmo
No hay una respuesta definitiva a la pregunta de qué enfoque formará mejor el currículum vitae final. Todo depende de la tarea y los objetivos específicos del usuario. Por ejemplo, es muy probable que un algoritmo extractivo sea más adecuado para generar el contenido de documentos de varias páginas, donde la extracción de oraciones relevantes puede transmitir correctamente la idea de un texto grande.
En mi opinión, el futuro pertenece a los algoritmos abstractos. A pesar de que en este momento están poco desarrollados y con un cierto nivel de calidad de salida, solo se pueden usar para generar pequeños resúmenes (1-2 oraciones), vale la pena esperar un gran avance en los métodos de redes neuronales. En el futuro, serán capaces de formar contenido para cualquier tamaño de texto y, lo más importante, el contenido en sí será lo más parecido posible a la elaboración manual de un currículum por un experto en un campo en particular.
Veklenko Vlad, analista de sistemas,
Codex Consortium