- Dispositivos integrados e IoT.
- Análisis de los datos.
- Transfiriendo datos de un sistema a otro.
- Archivo de datos y (o) empaquetado de datos en contenedores.
- Almacenamiento de datos en una base de datos externa o temporal.
- Un sustituto de una base de datos corporativa utilizada con fines de demostración o prueba.
- Formación, dominio por parte de principiantes de técnicas prácticas de trabajo con una base de datos.
- Creación de prototipos e investigación de extensiones experimentales del lenguaje SQL.
Puede encontrar otras razones para usar esta base de datos en la documentación de SQLite . Este artículo trata sobre el uso de SQLite en el desarrollo de Python. Por eso, es especialmente importante para nosotros que este DBMS, representado por el módulo , esté incluido en la biblioteca estándar del idioma. Es decir, resulta que para trabajar con SQLite desde código Python, no necesitas instalar ningún software cliente-servidor, no necesitas soportar el funcionamiento de algún servicio encargado de trabajar con el DBMS. Todo lo que necesita hacer es importar el módulo y empezar a utilizarlo en el programa, habiendo recibido el sistema de gestión de bases de datos relacionales a su disposición.
sqlite3sqlite3
Importación de módulos
Arriba dije que SQLite es un DBMS integrado en Python. Esto significa que para empezar a trabajar con él, basta con importar el módulo correspondiente sin antes instalarlo con un comando como
pip install. El comando de importación de SQLite se ve así:
import sqlite3 as sl
Creando una conexión a la base de datos
Para establecer una conexión a una base de datos SQLite, no necesita preocuparse por instalar controladores, preparar cadenas de conexión y otras cosas similares. Es muy sencillo y rápido crear una base de datos y poner a tu disposición un objeto de conexión a ella:
con = sl.connect('my-test.db')
Al ejecutar esta línea de código, crearemos una base de datos y nos conectaremos a ella. El punto aquí es que la base de datos a la que nos estamos conectando aún no existe, por lo que el sistema crea automáticamente una nueva base de datos vacía. Si la base de datos ya ha sido creada (suponga que esto es
my-test.dbdel ejemplo anterior), para conectarse a ella, solo necesita usar exactamente el mismo código.

Archivo de base de datos recién creado
Creando una mesa
Ahora creemos una tabla en nuestra nueva base de datos:
with con:
con.execute("""
CREATE TABLE USER (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
name TEXT,
age INTEGER
);
""")
Esto describe cómo agregar una tabla
USERcon tres columnas a la base de datos . Como puede ver, SQLite es un sistema de administración de bases de datos muy simple, pero tiene todas las capacidades básicas que esperaría de un sistema de administración de bases de datos relacional convencional. Estamos hablando de soporte para tipos de datos, incluidos: tipos que permiten un valor null, soporte para clave primaria y autoincremento.
Si este código funciona como se esperaba (el comando anterior, sin embargo, no devuelve nada), tendremos una tabla a nuestra disposición, lista para seguir trabajando con ella.
Insertar registros en una tabla
Insertemos algunos registros en la tabla
USERque acabamos de crear. Esto, entre otras cosas, nos dará una prueba de que la tabla fue realmente creada por el comando anterior.
Imaginemos que necesitamos agregar varios registros a la tabla con un comando. Es muy fácil hacer esto en SQLite:
sql = 'INSERT INTO USER (id, name, age) values(?, ?, ?)'
data = [
(1, 'Alice', 21),
(2, 'Bob', 22),
(3, 'Chris', 23)
]
Aquí necesitamos definir una expresión SQL con signos de interrogación (
?) como marcadores de posición. Dado que tenemos un objeto de conexión de base de datos a nuestra disposición, después de haber preparado la expresión y los datos, podemos insertar registros en la tabla:
with con:
con.executemany(sql, data)
Después de ejecutar este código, no se reciben mensajes de error, lo que significa que los datos se han agregado correctamente a la tabla.
Ejecución de consultas de base de datos
Ahora es el momento de averiguar si los comandos que acabamos de ejecutar han funcionado correctamente. Ejecutemos una consulta a la base de datos e intentemos obtener
USERalgunos datos de la tabla . Por ejemplo, obtenemos registros relacionados con usuarios cuya edad no supera los 22 años:
with con:
data = con.execute("SELECT * FROM USER WHERE age <= 22")
for row in data:
print(row)
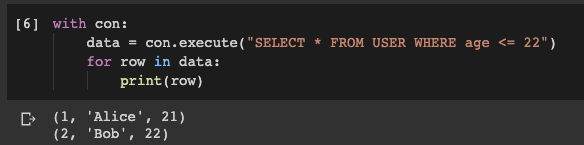
El resultado de ejecutar una consulta a la base de datos
Como puede ver, logramos obtener lo que se necesitaba. Y fue muy fácil hacerlo.
Además, aunque SQLite es un DBMS simple, tiene un soporte extremadamente amplio. Por lo tanto, puede trabajar con él utilizando la mayoría de los clientes SQL.
Estoy usando DBeaver. Echemos un vistazo a cómo se ve.
Conexión a la base de datos SQLite desde el cliente SQL (DBeaver)
Estoy usando el servicio en la nube de Google Colab y quiero descargar un archivo
my-test.dba mi computadora. Si está experimentando con SQLite en una computadora, significa que puede conectarse utilizando el cliente SQL sin tener que descargar el archivo de base de datos desde algún lugar.
En el caso de DBeaver, para conectarse a la base de datos SQLite, debe crear una nueva conexión y seleccionar SQLite como tipo de base de datos.
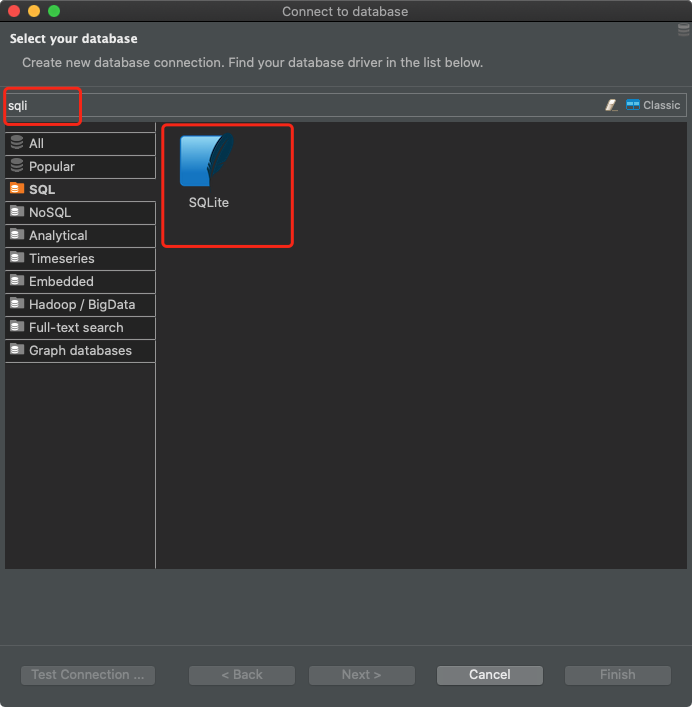
Preparando la conexión en DBeaver
A continuación, necesita encontrar el archivo de la base de datos.
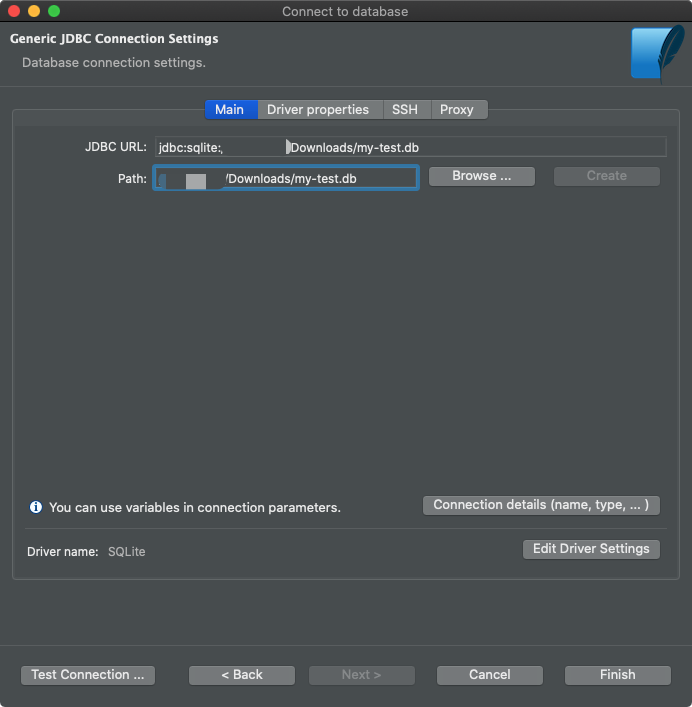
Conexión del archivo de base de datos Ahora
puede ejecutar consultas SQL en la base de datos. Aquí no hay nada especial que difiera de trabajar con bases de datos relacionales normales.
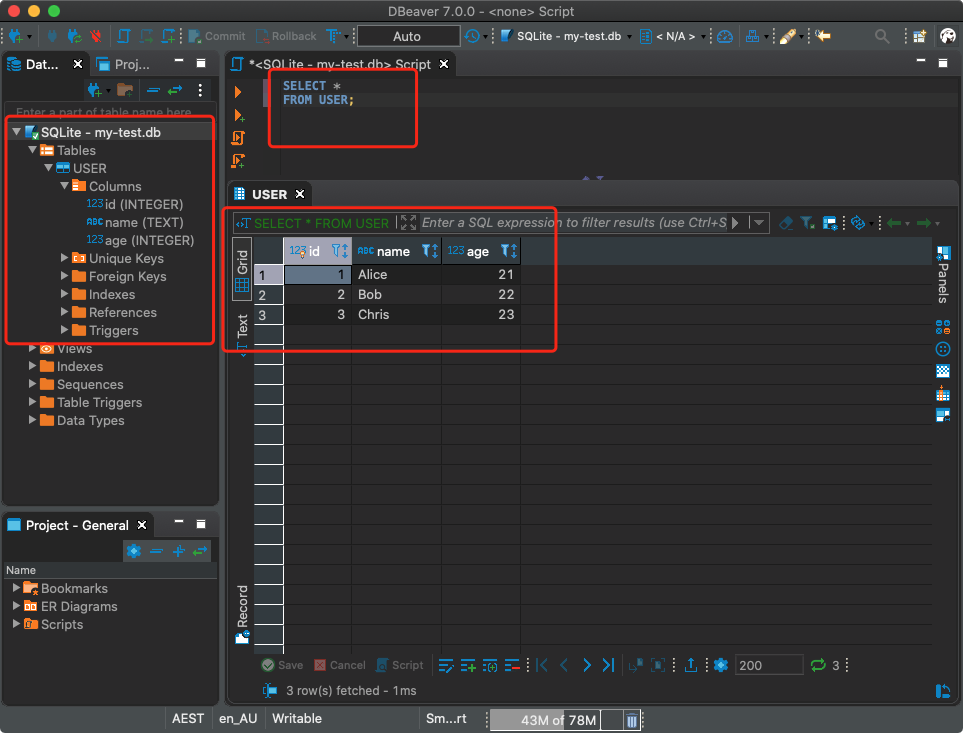
Ejecución de consultas de base de datos
Integración con pandas
¿Crees que aquí es donde terminamos nuestra conversación sobre el soporte de SQLite en Python? No, todavía tenemos mucho de qué hablar. Es decir, debido a que SQLite es un módulo estándar de Python, se integra fácilmente con los marcos de datos de pandas.
Declaremos el marco de datos:
df_skill = pd.DataFrame({
'user_id': [1,1,2,2,3,3,3],
'skill': ['Network Security', 'Algorithm Development', 'Network Security', 'Java', 'Python', 'Data Science', 'Machine Learning']
})
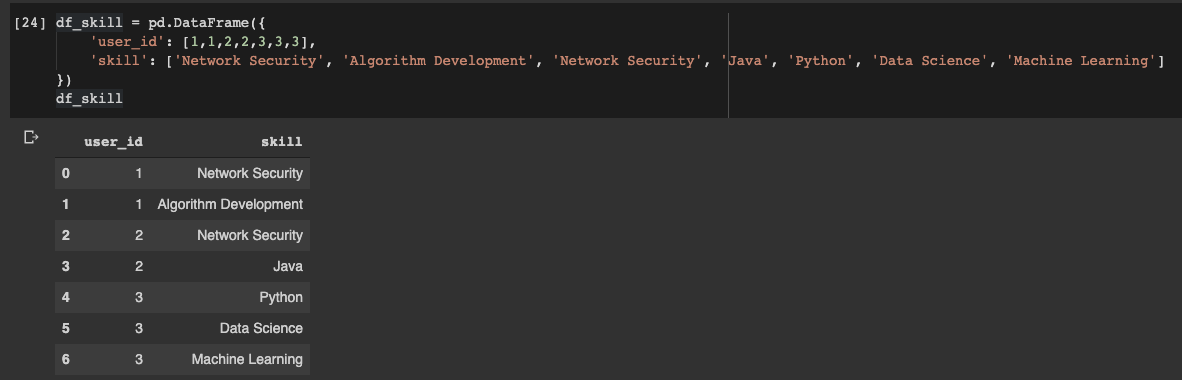
Marco de datos de Pandas
Para guardar un marco de datos en la base de datos, simplemente puede usar su método
to_sql():
df_skill.to_sql('SKILL', con)
¡Eso es todo! Ni siquiera necesitamos crear una tabla de antemano. Los tipos de datos y las características de los campos se configurarán automáticamente en función de las características del marco de datos. Por supuesto, puede personalizar todo usted mismo si es necesario.
Ahora suponga que necesitamos obtener la unión de las tablas
USERy SKILL, y escribir los datos en pandas datafreym. También es muy simple:
df = pd.read_sql('''
SELECT s.user_id, u.name, u.age, s.skill
FROM USER u LEFT JOIN SKILL s ON u.id = s.user_id
''', con)
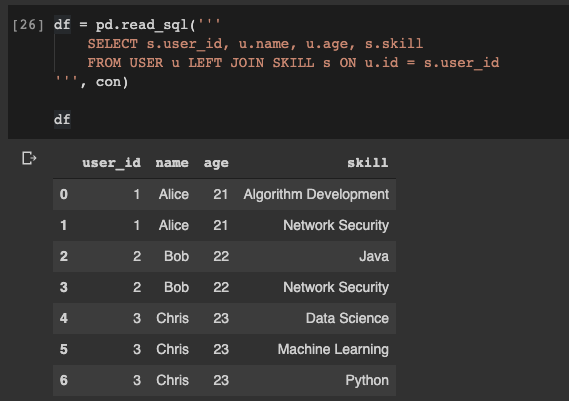
Leer datos de una base de datos en un marco de datos de pandas ¡
Genial! Ahora escribamos lo que llegamos a una nueva tabla llamada
USER_SKILL:
df.to_sql('USER_SKILL', con)
Por supuesto, puede trabajar con esta tabla utilizando el cliente SQL.
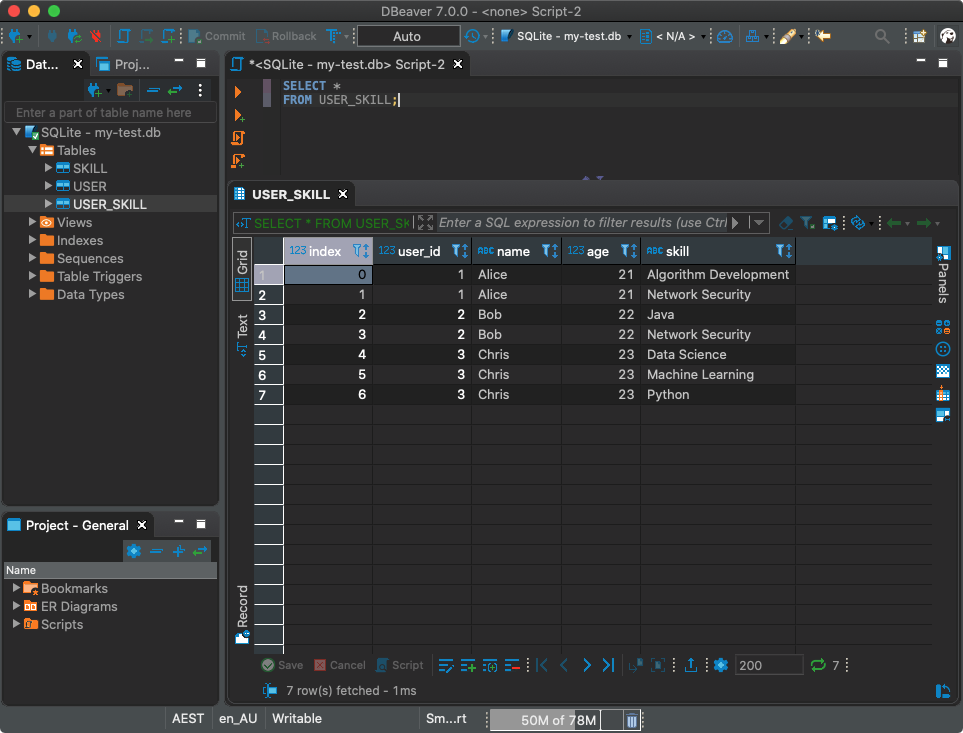
Usar un cliente SQL para trabajar con una base de datos
Salir
Sin duda, hay muchas sorpresas agradables en Python que, a menos que las busque específicamente, es posible que no las note. Nadie ocultó estas características de manera especial, pero debido al hecho de que muchas cosas están integradas en Python, simplemente no puede prestar atención a algunas de estas características o, habiendo aprendido sobre ellas en algún lugar, simplemente olvidarse de ellas.
Aquí hablé sobre cómo usar la biblioteca Python incorporada
sqlite3para crear y trabajar con bases de datos. Por supuesto, estas bases de datos admiten no solo la operación de agregar datos, sino también las operaciones de cambiar y eliminar información. Creo que, habiendo aprendido sqlite3, lo experimentará todo usted mismo.
Lo más importante es que SQLite hace un gran trabajo con los pandas. Es muy fácil leer datos de la base de datos colocándolos en marcos de datos. La operación de guardar el contenido de los marcos de datos en una base de datos no es menos simple. Esto hace que SQLite sea aún más fácil de usar.
¡Invito a todos los que han leído hasta aquí a hacer su propia investigación en busca de características interesantes de Python!
El código que he demostrado en este artículo se puede encontrar aquí .
¿Utiliza SQLite en sus proyectos de Python?
