Repita, pero cada vez de una manera nueva, ¿no es este arte?
Stanislav Jerzy Lec, del libro "Pensamientos sin peinar"
El diccionario define la replicación como el proceso de mantener dos (o más) conjuntos de datos en un estado consistente. Cuál es el "estado consistente de los conjuntos de datos" es una gran pregunta separada, así que reformulemos la definición de una manera más simple: el proceso de cambiar un conjunto de datos, llamado réplica, en respuesta a cambios en otro conjunto de datos, llamado maestro. Los conjuntos no son necesariamente los mismos.

La compatibilidad con la replicación de bases de datos es una de las tareas más importantes de un administrador: casi todas las bases de datos de importancia tienen una réplica, o incluso más de una.
Las tareas de replicación incluyen al menos
- soporte de la base de datos de respaldo en caso de pérdida de la principal;
- reducir la carga en la base debido a la transferencia de parte de las solicitudes a réplicas;
- transferencia de datos a sistemas de archivo o analíticos.
En este artículo hablaré sobre los tipos de replicación y qué tareas resuelve cada tipo de replicación.
Hay tres enfoques para la replicación:
- Bloquear la replicación a nivel del sistema de almacenamiento;
- Replicación física a nivel DBMS;
- Replicación lógica a nivel DBMS.
Replicación de bloque
Con la replicación en bloque, cada operación de escritura se realiza no solo en el disco principal, sino también en la copia de seguridad. Por lo tanto, un volumen en una matriz corresponde a un volumen reflejado en otra matriz, repitiendo el volumen principal con una precisión de bytes: las
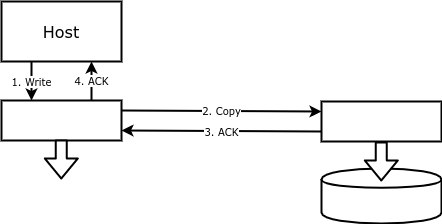
ventajas de dicha replicación incluyen la facilidad de configuración y confiabilidad. Una matriz de discos o algo (un dispositivo o software) entre el host y el disco puede escribir datos en un disco remoto.
Las matrices de discos se pueden complementar con opciones para permitir la replicación. El nombre de la opción depende del fabricante de la matriz:
| Fabricante | Marca comercial
|
|---|---|
| EMC | SRDF (instalación de datos remotos de Symmetrix) |
| IBM | Metro Mirror - replicación sincrónica
Global Mirror - replicación asincrónica |
| Hitachi | Copia original |
| Hewlett Packard | Acceso continuo |
| Huawei | HyperReplicación |
Si la matriz de discos no es capaz de replicar datos, se puede instalar un agente entre el host y la matriz, que escribe en dos matrices a la vez. Un agente puede ser un dispositivo independiente (EMC VPLEX) o un componente de software (HPE PeerPersistence, Windows Server Storage Replica, DRBD). A diferencia de una matriz de discos, que solo puede funcionar con la misma matriz, o al menos con una matriz del mismo fabricante, un agente puede trabajar con dispositivos de disco completamente diferentes.
El objetivo principal de la replicación de bloques es proporcionar tolerancia a errores. Si se pierde la base de datos, puede reiniciarla utilizando el volumen reflejado.
La replicación de bloques es excelente por su versatilidad, pero la versatilidad tiene un precio.
Primero, ningún servidor puede manejar un volumen reflejado porque su sistema operativo no puede controlar las escrituras en él; desde el punto de vista de un observador, los datos del volumen reflejado aparecen por sí mismos. En caso de desastre (falla del servidor primario o de todo el centro de datos donde se encuentra el servidor primario), debe detener la replicación, desmontar el volumen primario y montar el volumen reflejado. Tan pronto como sea posible, debe reiniciar la replicación en la dirección opuesta.
En el caso de utilizar un agente, todas estas acciones las realizará el agente, lo que simplifica la configuración, pero no reduce el tiempo de conmutación.
En segundo lugar, el DBMS en sí en el servidor de reserva se puede iniciar solo después de montar el disco. En algunos sistemas operativos, por ejemplo, en Solaris, la memoria para la caché se marca durante la asignación y el tiempo de marcado es proporcional a la cantidad de memoria asignada, es decir, el inicio de la instancia no será instantáneo. Además, la caché estará vacía después de reiniciar.
En tercer lugar, después de comenzar en el servidor de respaldo, el DBMS descubrirá que los datos en el disco son inconsistentes, y debe dedicar una cantidad significativa de tiempo a recuperarse usando registros de rehacer: primero, repita esas transacciones, cuyos resultados se guardaron en el registro, pero no tuvieron tiempo de guardarse en los archivos de datos, y luego revertir las transacciones que no tuvieron tiempo de completarse en el momento del error.
La replicación en bloque no se puede usar para el equilibrio de carga y se usa un esquema similar para actualizar el almacén de datos con el volumen reflejado en el mismo arreglo que el principal. EMC y HP llaman a este esquema BCV, solo EMC significa Business Continuance Volume y HP significa Business Copy Volume. IBM no tiene una marca comercial especial para este caso, este esquema se llama "volumen reflejado".

Se crean dos volúmenes en la matriz y las operaciones de escritura se realizan sincrónicamente en ambos (A). En un momento determinado, el espejo se rompe (B), es decir, los volúmenes se independizan. El volumen reflejado se monta en un servidor dedicado a las actualizaciones de almacenamiento y se genera una instancia de base de datos en ese servidor. La instancia tardará tanto en tomarse como lo haría con una restauración de replicación en bloque, pero este tiempo se puede reducir significativamente rompiendo el espejo durante los períodos de menor actividad. El punto es que romper el espejo en sus consecuencias equivale a una terminación anormal del DBMS, y el tiempo de recuperación en caso de terminación anormal depende significativamente del número de transacciones activas en el momento del bloqueo. La base de datos destinada a la descarga está disponible tanto para lectura como para escritura. Todos los identificadores de bloque,Los espejos cambiados después de la pausa, tanto en el volumen principal como en el espejo, se guardan en un área especial de Seguimiento de cambios de bloques - BCT.
Una vez finalizada la carga, el volumen reflejado se desmonta (C), se restaura el espejo y, después de un tiempo, el volumen reflejado vuelve a ponerse al día con el principal y se convierte en su copia.
Replicación física
Los registros (registro de rehacer o registro de escritura anticipada) contienen todos los cambios que se realizan en los archivos de la base de datos. La idea detrás de la replicación física es que los cambios de los registros se vuelven a confirmar en otra base de datos (réplica) y, por lo tanto, los datos de la réplica replican los datos del maestro byte por byte.
La capacidad de usar registros de base de datos para actualizar una réplica apareció en el lanzamiento de Oracle 7.3, que se lanzó en 1996, y ya en el lanzamiento de Oracle 8i, la entrega de registros de la base de datos principal a la réplica se automatizó y se denominó DataGuard. La tecnología resultó ser tan demandada que hoy en día el mecanismo de replicación física está presente en casi todos los DBMS modernos.
| DBMS | Opción de replicación
|
|---|---|
| Oráculo | DataGuard activo |
| IBM DB2 | HADR |
| Microsoft SQL Server | Envío de registros / Siempre activado |
| PostgreSQL | Envío de registros / replicación de transmisión |
| MySQL | Replicación física de InnoDB de Alibaba |
La experiencia muestra que si el servidor se usa solo para mantener la réplica actualizada, entonces aproximadamente el 10% de la potencia de procesamiento del servidor en el que se ejecuta la base principal es suficiente para ello.
Los registros de DBMS no están destinados a ser utilizados fuera de esta plataforma, su formato no está documentado y puede cambiar sin previo aviso. De ahí el requisito bastante natural de que la replicación física solo es posible entre instancias de la misma versión del mismo DBMS. Por lo tanto, existen posibles restricciones en el sistema operativo y la arquitectura del procesador, que también pueden afectar el formato del registro.
Naturalmente, la replicación física no impone restricciones a los modelos de almacenamiento. Además, los archivos en la base de réplicas se pueden ubicar de una manera completamente diferente a la base de origen; solo necesita describir la correspondencia entre los volúmenes en los que se encuentran estos archivos.
Oracle DataGuard le permite eliminar algunos de los archivos de la réplica de la base de datos; en este caso, se ignorarán los cambios en los registros relacionados con estos archivos.
La replicación de la base de datos física tiene muchas ventajas sobre la replicación del almacenamiento:
- la cantidad de datos transferidos es menor debido al hecho de que solo se transfieren registros, pero no archivos de datos; los experimentos muestran una disminución del tráfico de 5 a 7 veces;
- : - , ; , ;
- , . , .
La capacidad de leer datos de una réplica se introdujo en 2007 con el lanzamiento de Oracle 11g, como lo indica el epíteto "activo" agregado al nombre de la tecnología DataGuard. Otros DBMS también tienen la capacidad de leer desde una réplica, pero esto no se refleja en el nombre.
Escribir datos en una réplica es imposible, ya que los cambios se producen byte a byte y la réplica no puede proporcionar la ejecución simultánea de sus solicitudes. Oracle Active DataGuard en versiones recientes permite escribir en la réplica, pero esto no es más que "azúcar": de hecho, los cambios se realizan en la base principal y el cliente está esperando a que lleguen a la réplica.
Si un archivo de la base de datos principal está dañado, simplemente puede copiar el archivo correspondiente de la réplica (¡lea atentamente el manual del administrador antes de hacer esto con su base de datos!). El archivo de la réplica puede no ser idéntico al archivo de la base de datos principal: el hecho es que cuando se expande el archivo, los nuevos bloques no se llenan con nada para acelerar y su contenido es accidental. Es posible que la base no utilice todo el espacio del bloque (por ejemplo, puede haber espacio libre en el bloque), pero el contenido del espacio utilizado coincide con el byte.
La replicación física puede ser sincrónica o asincrónica. Con la replicación asincrónica, siempre hay un determinado conjunto de transacciones que se han completado en la base principal, pero que aún no han alcanzado la base en espera, y en el caso de una transición a la base en espera, si la base principal falla, estas transacciones se perderán. En la replicación sincrónica, la finalización de la operación de confirmación significa que todos los registros relacionados con esta transacción se han comprometido en la réplica. Es importante comprender que obtener una réplica de registro no significa que los cambios se apliquen a los datos. Si se pierde la base de datos principal, las transacciones no se perderán, pero si la aplicación escribe datos en la base de datos principal y los lee de la réplica, entonces tiene la posibilidad de obtener la versión anterior de estos datos.
En PostgreSQL, es posible configurar la replicación para que la confirmación se complete solo después de que los cambios se apliquen a los datos de la réplica (opción
synchronous_commit = remote_apply), mientras que en Oracle, puede configurar la réplica completa o las sesiones individuales para que las consultas se ejecuten solo si la réplica no se queda atrás de la base de datos principal ( STANDBY_MAX_DATA_DELAY=0). Sin embargo, es mejor diseñar la aplicación para que la escritura en la base de datos principal y la lectura de réplicas se realicen en diferentes módulos.
Al buscar una respuesta a la pregunta de qué modo elegir, sincrónico o asincrónico, los especialistas en marketing de Oracle acuden en nuestra ayuda. DataGuard proporciona tres modos, cada uno de los cuales maximiza uno de los parámetros (seguridad de los datos, rendimiento, disponibilidad) a expensas de los demás:
- Máximo rendimiento: la replicación es siempre asincrónica;
- Maximum protection: ; , commit ;
- Maximum availability: ; , , , .
A pesar de las innegables ventajas de la replicación de bases de datos sobre la replicación de bloques, los administradores de muchas empresas, especialmente aquellas con antiguas tradiciones de confiabilidad, todavía son muy reacios a abandonar la replicación de bloques. Hay dos razones para esto.
En primer lugar, en el caso de la replicación de la matriz de discos, el tráfico no pasa por la red de transmisión de datos (LAN), sino por la red de área de almacenamiento. A menudo, en las infraestructuras construidas hace mucho tiempo, una SAN es mucho más confiable y más eficiente que una red de datos.
En segundo lugar, la replicación síncrona mediante un DBMS se ha vuelto confiable hace relativamente poco tiempo. En Oracle, el avance se produjo en la versión 11g, que salió en 2007, y en otros DBMS, la replicación sincrónica apareció incluso más tarde. Por supuesto, 10 años según los estándares de la esfera de la tecnología de la información no es tan corto, pero cuando se trata de seguridad de datos, algunos administradores todavía se guían por el principio de "pase lo que pase" ...
Replicación lógica
Todos los cambios en la base de datos ocurren como resultado de llamadas a su API, por ejemplo, como resultado de la ejecución de consultas SQL. La idea de ejecutar la misma secuencia de consultas en dos bases de datos diferentes parece muy tentadora. Para la replicación, debe cumplir con dos reglas:
- , , . D, A B.
- , , . B , , C.
La replicación de comandos (replicación basada en instrucciones) se implementa, por ejemplo, en MySQL. Desafortunadamente, este diseño simple no produce conjuntos de datos idénticos por dos razones.
Primero, no todas las API son deterministas. Por ejemplo, si la función now () o sysdate () se encuentra en una consulta SQL, que devuelve la hora actual, devolverá resultados diferentes en diferentes servidores, debido al hecho de que las consultas no se ejecutan simultáneamente. Además, diferentes estados de desencadenadores y funciones almacenadas, diferentes configuraciones regionales que afectan el orden de clasificación y mucho más pueden generar diferencias.
En segundo lugar, la replicación paralela basada en comandos no se puede pausar y reiniciar correctamente.
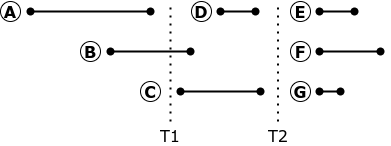
Si la replicación se detiene en el momento T1, la transacción B debe abortarse y revertirse. Cuando reinicia la replicación, la ejecución de la transacción B puede llevar la réplica a un estado diferente del estado de la base de datos de origen: en el origen, la transacción B comenzó antes de que finalizara la transacción A, lo que significa que no vio los cambios realizados por la transacción A. La
replicación de solicitudes se puede detener y se reinicia solo en el momento T2, cuando no hay transacciones activas en la base de datos. Por supuesto, no existen esos momentos en una base industrial muy cargada.
Normalmente, la replicación lógica utiliza consultas deterministas. El determinismo de la solicitud lo proporcionan dos propiedades:
- la consulta actualiza (o inserta o elimina) un solo registro, identificándolo por su clave principal (o única);
- todos los parámetros de la solicitud se establecen explícitamente en la propia solicitud.
A diferencia de la replicación basada en instrucciones, este enfoque se denomina replicación basada en filas.
Supongamos que tenemos una tabla de empleados con los siguientes datos:
| CARNÉ DE IDENTIDAD | Nombre | Departamento | Salario
|
|---|---|---|---|
| 3817 | Ivanov Ivan Ivanovich | 36 | 1800 |
| 2274 | Petrov Petr Petrovich | 36 | 1600 |
| 4415 | Kuznetsov Semyon Andreevich | 41 | 2100 |
En esta mesa se realizó la siguiente operación:
update employee set salary = salary*1.2 where dept=36;Para poder replicar correctamente los datos, se ejecutarán las siguientes consultas en la réplica:
update employee set salary = 2160 where id=3817;
update employee set salary = 1920 where id=2274;Las consultas producen el mismo resultado que en la base original, pero no son equivalentes a las consultas ejecutadas.
La base de la réplica está abierta y disponible no solo para leer, sino también para escribir. Esto permite que la réplica se utilice para ejecutar parte de las consultas, incluso para crear informes que requieran la creación de tablas o índices adicionales.
Es importante comprender que una réplica lógica será equivalente a la base original solo si no se le realizan cambios adicionales. Por ejemplo, si en el ejemplo anterior, en la réplica, el departamento de Sidorov se agrega al 36, entonces no recibirá una promoción, y si Ivanov es transferido del departamento 36, recibirá una promoción, pase lo que pase.
La replicación lógica proporciona una serie de capacidades que no se encuentran en otros tipos de replicación:
- configurar un conjunto de datos replicados a nivel de tabla (para la replicación física, a nivel de archivo y espacio de tabla, para replicación de bloques, a nivel de volumen);
- construir topologías de replicación complejas, por ejemplo, consolidar varias bases de datos en una replicación bidireccional o una;
- disminución de la cantidad de datos transmitidos;
- replicación entre diferentes versiones de un DBMS o incluso entre DBMS de diferentes fabricantes;
- procesamiento de datos durante la replicación, incluida la reestructuración, el enriquecimiento y la conservación de la historia.
También existen desventajas que impiden que la replicación lógica reemplace a la replicación física:
- todos los datos replicados deben tener claves primarias;
- La replicación lógica no admite todos los tipos de datos; por ejemplo, puede haber problemas con los BLOB.
- : , ;
- ;
- , , – , .
Las dos últimas desventajas limitan significativamente el uso de una réplica lógica como herramienta de tolerancia a fallas. Si una consulta en la base de datos principal cambia muchas filas a la vez, la réplica puede retrasarse significativamente. Y la capacidad de cambiar roles requiere esfuerzos notables tanto de los desarrolladores como de los administradores.
Hay varias formas de implementar la replicación lógica y cada uno de estos métodos implementa una parte de las capacidades y no implementa la otra:
- replicación por disparadores;
- utilizando registros DBMS;
- uso de software CDC (captura de datos de cambios);
- replicación aplicada.
Desencadenar replicación
Trigger es un procedimiento almacenado que se ejecuta automáticamente ante cualquier acción para modificar datos. El activador, que se llama cuando cambia cada registro, tiene acceso a la clave de ese registro, así como a los valores de campo nuevos y antiguos. Si es necesario, el disparador puede guardar nuevos valores de fila en una tabla especial, desde donde un proceso especial en el lado de la réplica los leerá. La cantidad de código en los desencadenadores es grande, por lo que existe un software especial que genera tales desencadenantes, por ejemplo, "replicación de combinación", un componente de Microsoft SQL Server o Slony-I, un producto separado para la replicación de PostgreSQL.
Fortalezas de la replicación del gatillo:
- independencia de las versiones de la base principal y la réplica;
- amplias capacidades de conversión de datos.
Desventajas:
- carga en la base principal;
- alta latencia de replicación.
Uso de registros DBMS
Los propios DBMS también pueden proporcionar capacidades de replicación lógica. Los registros son la fuente de datos, al igual que para la replicación física. La información sobre el cambio de byte también se complementa con información sobre los campos modificados (registro suplementario en Oracle,
wal_level = logicalen PostgreSQL), así como el valor de la clave única, incluso si no cambia. Como resultado, el volumen de registros de la base de datos está aumentando, según varias estimaciones, del 10 al 15%.
Las capacidades de replicación dependen de la implementación en un DBMS en particular: si puede construir una reserva lógica en Oracle, entonces en PostgreSQL o Microsoft SQL Server puede implementar un sistema complejo de suscripciones mutuas y publicaciones utilizando las herramientas de plataforma integradas. Además, el DBMS proporciona supervisión y control de la replicación integrados.
Las desventajas de este enfoque incluyen un aumento en el volumen de registros y un posible aumento en el tráfico entre nodos.
Usando CDC
Existe toda una clase de software diseñado para organizar la replicación lógica. Este software se llama CDC, captura de datos de cambios. Aquí hay una lista de las plataformas más famosas de esta clase:
- Oracle GoldenGate (adquirido por GoldenGate en 2009);
- IBM InfoSphere Data Replication (anteriormente InfoSphere CDC; incluso antes, DataMirror Transformation Server, adquirido por DataMirror en 2007);
- VisionSolutions DoubleTake / MIMIX (anteriormente Vision Replicate1);
- Plataforma de integración de datos de Qlik (anteriormente Attunity);
- Informatica PowerExchange CDC;
- Debezium;
- Recopilador de datos StreamSets ...
La tarea de la plataforma es leer los registros de la base de datos, transformar información, transferir información a una réplica y aplicar. Como en el caso de la replicación mediante el propio DBMS, el log debe contener información sobre los campos modificados. El uso de una aplicación adicional le permite realizar transformaciones complejas de los datos replicados sobre la marcha y crear topologías de replicación bastante complejas.
Fortalezas:
- la capacidad de replicar entre diferentes DBMS, incluida la carga de datos en sistemas de informes;
- las más amplias posibilidades de procesamiento y transformación de datos;
- tráfico mínimo entre nodos: la plataforma corta los datos innecesarios y puede comprimir el tráfico;
- capacidades integradas para monitorear el estado de la replicación.
No hay muchas desventajas:
- aumento del volumen de logs, como ocurre con la replicación lógica por medio de un DBMS;
- el software nuevo es difícil de configurar y / o tiene licencias caras.
Son las plataformas CDC las que se utilizan tradicionalmente para actualizar los almacenes de datos corporativos casi en tiempo real.
Replicación aplicada
Finalmente, otra forma de replicación es la formación de vectores de cambio directamente en el lado del cliente. El cliente debe emitir consultas deterministas que afecten a un solo registro. Esto se puede lograr mediante el uso de una biblioteca de base de datos especial, como Borland Database Engine (BDE) o Hibernate ORM.
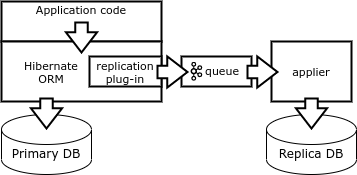
Cuando la aplicación completa la transacción, el complemento Hibernate ORM escribe el vector de cambio en la cola y ejecuta la transacción en la base de datos. Un proceso de replicador especial resta vectores de la cola y realiza transacciones en la base de réplicas.
Este mecanismo es bueno para actualizar los sistemas de informes. También se puede utilizar para proporcionar tolerancia a fallos, pero en este caso, la aplicación debe implementar el control del estado de replicación.
Tradicionalmente, fortalezas y debilidades de este enfoque:
- la capacidad de replicar entre diferentes DBMS, incluida la carga de datos en sistemas de informes;
- la capacidad de procesar y transformar datos, monitoreo de condiciones, etc.;
- tráfico mínimo entre nodos: la plataforma corta los datos innecesarios y puede comprimir el tráfico;
- completa independencia de la base de datos, tanto del formato como de los mecanismos internos.
Las ventajas de este método son innegables, pero existen dos desventajas muy serias:
- restricciones sobre la arquitectura de la aplicación;
- una gran cantidad de código de replicación nativo.
Entonces, ¿cuál es mejor?
No hay una respuesta inequívoca a esta pregunta, así como a muchas otras. Pero espero que la tabla a continuación lo ayude a tomar la decisión correcta para cada tarea específica:
| Replicación de bloques de almacenamiento | Bloquear la replicación por agente | Replicación física | Replicación lógica DBMS | CDC |
|
||
|---|---|---|---|---|---|---|---|
| X | X | X/7..X/5 | X/7..X/5 | ≤X/10 | ≤X/10 | ≤X/10 | |
| 5 … | 5 … | 1..10 | 1..10 | 1..2 | 1..2 | 1..2 | |
| + | + | +++ | + | ∅ | ∅ | ∅ | |
| ∅ | ∅ | RO | R/W | R/W | R/W | R/W | |
| - | -
broadcast |
-
broadcast |
-
broadcast * p2p* |
-
broadcast * p2p* |
-
broadcast * p2p* |
-
broadcast * p2p* |
|
| ∅ | ∅ | – | – – | – – – | – – | ∅ | |
| + + + | + + | + + | + + | – | + | – – – | |
| – – | – – | – | – | ∅ | – – – | ∅ | |
| ∅ | + | + + | + + | + + | + + + | + + + |
- , ; .
- , .
- , .
- .
- , , .
- CDC , / .
- .