Pero, ¿cómo funciona exactamente el seguimiento de objetos? Hay muchas soluciones de aprendizaje profundo para este problema, y hoy quiero hablar sobre una solución común y las matemáticas detrás de ella.
Entonces, en este artículo intentaré contarte en palabras y fórmulas simples sobre:
- YOLO es un gran detector de objetos
- Filtros de Kalman
- Distancia de Mahalanobis
- SORT profundo
YOLO es un gran detector de objetos
Inmediatamente debe tomar una nota muy importante que debe recordar: la detección de objetos no es el seguimiento de objetos. Para muchos, esto no será noticia, pero a menudo la gente confunde estos conceptos. En palabras simples: la
detección de objetos es simplemente la definición de objetos en la imagen / marco. Es decir, un algoritmo o red neuronal define un objeto y registra su posición y cuadros delimitadores (parámetros de rectángulos alrededor de los objetos). Hasta el momento, no se habla de otros fotogramas y el algoritmo funciona con uno solo.
Ejemplo: el
seguimiento de objetos es otro asunto completamente diferente. Aquí la tarea no es solo identificar objetos en el marco, sino también vincular información de marcos anteriores de tal manera que no se pierda el objeto, o que sea único.
Ejemplo:

Es decir, Object Tracker incluye Detección de objetos para determinar objetos y otros algoritmos para comprender qué objeto en un nuevo marco pertenece a cuál del marco anterior.
Por lo tanto, la detección de objetos juega un papel muy importante en la tarea de seguimiento.
¿Por qué YOLO? Sí, porque YOLO se considera más eficiente que muchos otros algoritmos para identificar objetos. Aquí hay un pequeño gráfico para comparar de los creadores de YOLO:
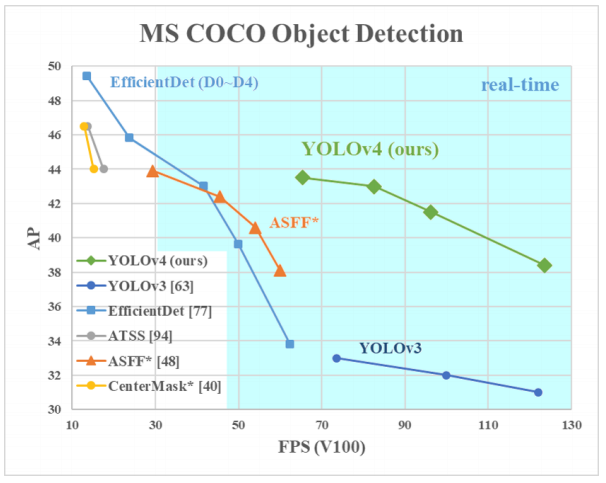
Aquí estamos viendo YOLOv3-4 ya que son las versiones más recientes y son más eficientes que las anteriores.
Arquitecturas de diferentes detectores de objetos
Entonces, hay varias arquitecturas de redes neuronales diseñadas para definir objetos. Por lo general, se clasifican en "dos niveles", como RCNN, RCNN rápido y RCNN más rápido, y "de un solo nivel", como YOLO.
Las redes neuronales de "dos capas" enumeradas anteriormente utilizan las denominadas regiones de la imagen para determinar si un objeto en particular se encuentra en esa región.
Por lo general, se ve así (para un RCNN más rápido, que es el más rápido de los dos sistemas enumerados):
- La imagen / marco se alimenta a la entrada
- El marco se ejecuta a través de CNN para formar mapas de características.
- Una red neuronal separada define regiones con una alta probabilidad de encontrar objetos en ellas
- Luego, utilizando la agrupación de RoI, estas regiones se comprimen y se alimentan a la red neuronal, que determina la clase del objeto en las regiones

Pero estas redes neuronales tienen dos problemas clave: no miran el panorama completo, sino solo regiones individuales, y son relativamente lentas.
¿Qué tiene de genial YOLO? El hecho de que esta arquitectura no tenga dos problemas desde arriba, y ha demostrado repetidamente su eficacia.
En general, la arquitectura YOLO en los primeros bloques no difiere mucho en términos de la "lógica de los bloques" de otros detectores, es decir, se envía una imagen a la entrada, luego se crean mapas de características usando CNN (aunque YOLO usa su propia CNN llamada Darknet-53), luego estos mapas de características se analizan de cierta manera (más sobre esto más adelante), dando las posiciones y tamaños de los cuadros delimitadores y las clases a las que pertenecen.

Pero, ¿qué son el cuello, la predicción densa y la predicción escasa?
Tratamos con la predicción dispersa un poco antes; es solo una repetición de cómo funcionan los algoritmos de dos niveles: definen regiones individualmente y luego clasifican esas regiones.
El cuello (o "cuello") es un bloque separado, que se crea para agregar información de capas separadas de los bloques anteriores (como se muestra en la figura anterior) para aumentar la precisión de la predicción. Si está interesado en esto, puede buscar en Google los términos "Red de agregación de rutas", "Módulo de atención espacial" y "Agrupación de pirámides espaciales".
Y finalmente, lo que distingue a YOLO de todas las demás arquitecturas es un bloque llamado (en nuestra imagen de arriba) Dense Prediction. Nos centraremos en ello un poco más, porque se trata de una solución muy interesante, que acaba de permitir que YOLO se destaque entre los líderes en términos de eficiencia de detección de objetos.
YOLO (You Only Look Once) lleva la filosofía de mirar la imagen una vez, y para esta única visualización (es decir, una pasada de la imagen a través de una red neuronal) hacer todas las definiciones de objeto necesarias. ¿Como sucedió esto?
Entonces, como resultado del trabajo de YOLO, generalmente queremos esto:
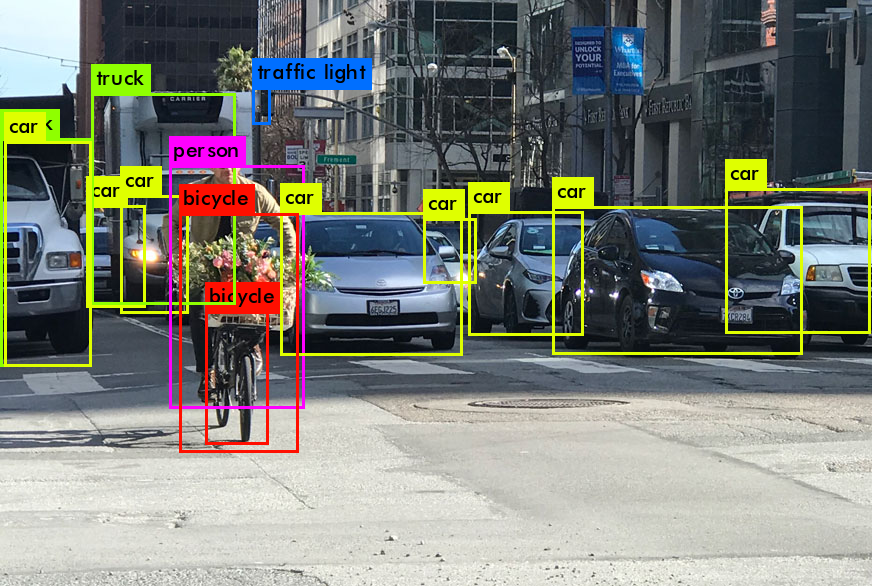
¿Qué hace YOLO cuando aprende de los datos (en palabras simples):
Paso 1: Por lo general, las imágenes se remodelarán a un tamaño de 416x416 antes de entrenar la red neuronal, para que puedan alimentarse en lotes (para acelerar el aprendizaje ).
Paso 2: Divida la imagen (por ahora mentalmente) en celdas de tamaño a x a . En YOLOv3-4, se acostumbra dividir en celdas de tamaño 13x13 (hablaremos de diferentes escalas un poco más adelante para que quede más claro).

Ahora centrémonos en estas celdas en las que dividimos la imagen / marco. Estas celdas, llamadas celdas de cuadrícula, están en el corazón de la idea de YOLO. Cada celda es un "ancla" a la que se adjuntan cuadros delimitadores. Es decir, se dibujan varios rectángulos alrededor de la celda para definir el objeto (dado que no está claro qué forma será la más adecuada para el rectángulo, se dibujan a la vez en varias y diferentes formas), y sus posiciones, ancho y alto se calculan con respecto al centro de esta celda.
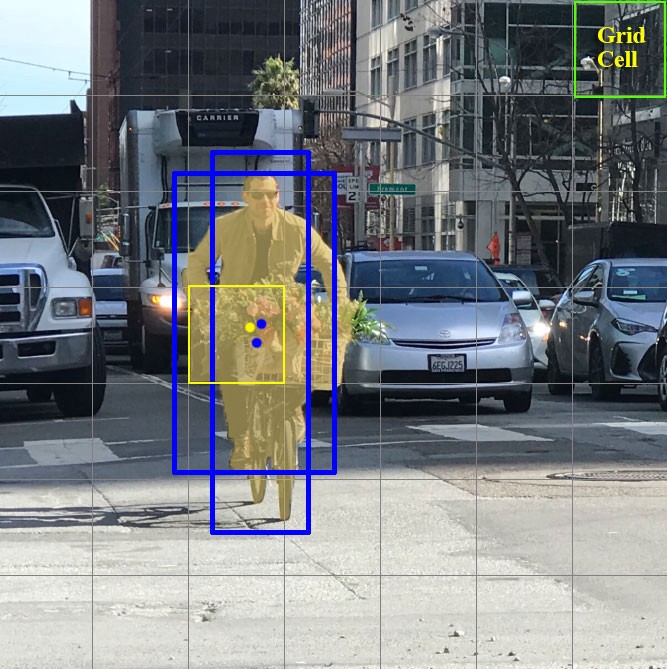
¿Cómo se dibujan estos cuadros delimitadores alrededor de la jaula? ¿Cómo se determina su tamaño y posición? Aquí es donde entra en juego la técnica de las cajas de ancla (en traducción - cajas de ancla, o "rectángulos de ancla"). Se establecen desde el principio, ya sea por el propio usuario, o sus tamaños se determinan en función de los tamaños de los cuadros delimitadores que se encuentran en el conjunto de datos en el que entrenará YOLO (la agrupación en clústeres de K-medias y IoU se utilizan para determinar los tamaños más apropiados). Por lo general, hay 3 cuadros de ancla diferentes que se dibujarán alrededor (o dentro) de una celda:

¿Por qué se hace esto? Ahora quedará claro a medida que discutamos cómo aprende YOLO.
Paso 3. La imagen del conjunto de datos se ejecuta a través de nuestra red neuronal (tenga en cuenta que, además de la imagen en el conjunto de datos de entrenamiento, debemos tener las posiciones y los tamaños de los cuadros delimitadores reales para los objetos que contiene. Esto se llama "anotación" y se hace principalmente de forma manual. ).
Pensemos ahora en lo que necesitamos para obtener la salida.
Para cada celda, necesitamos comprender dos cosas fundamentales:
- ¿Cuál de las 3 cajas de anclaje dibujadas alrededor de la jaula se adapta mejor a nosotros y cómo podemos modificarlo un poco para que encaje bien con el objeto?
- ¿Qué objeto hay dentro de esta caja de anclaje? ¿Está ahí?
¿Cuál debería ser entonces la salida de YOLO?
1. En la salida de cada celda, queremos obtener:

2. La salida debe incluir los siguientes parámetros:
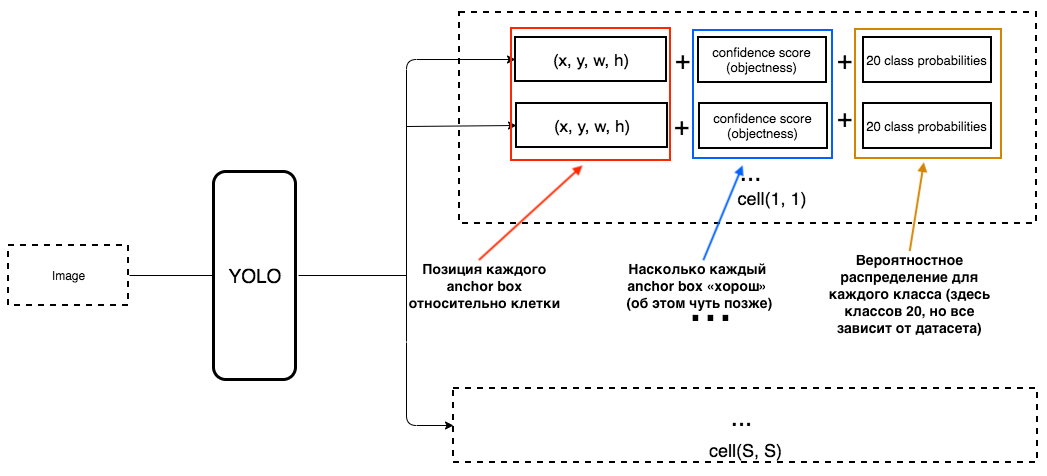
¿Cómo se determina la objetividad? De hecho, este parámetro se determina utilizando la métrica de IoU durante el entrenamiento. La métrica de IoU funciona así:
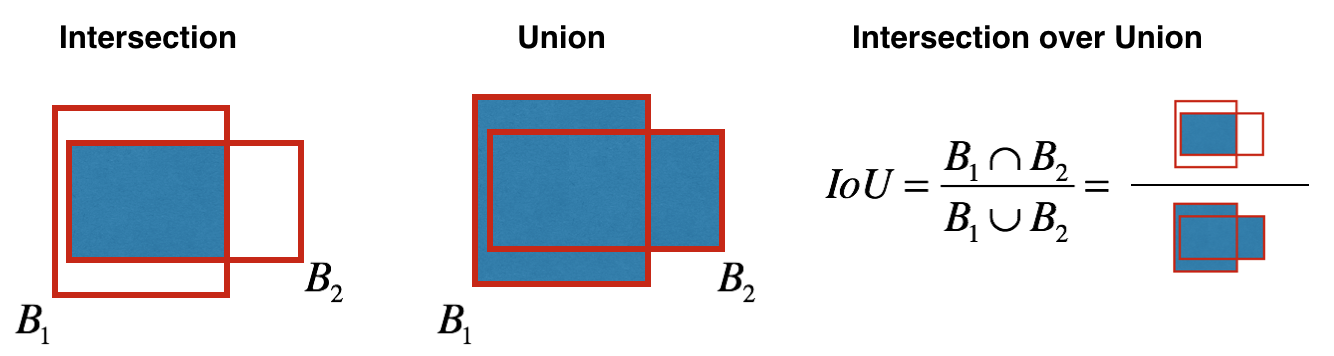
al principio, puede establecer un umbral para esta métrica, y si su cuadro delimitador previsto está por encima de este umbral, entonces tendrá objetividad igual a uno, y se excluirán todos los demás cuadros delimitadores con objetividad menor. Necesitaremos este valor de objetividad cuando calculemos el puntaje de confianza general (qué tan seguros estamos de que este es el objeto que necesitamos está ubicado dentro del rectángulo predicho) para cada objeto específico.
Y ahora comienza la diversión. Imaginemos que somos los creadores de YOLO y necesitamos entrenarla para que reconozca a las personas en el marco / imagen. Alimentamos la imagen del conjunto de datos a YOLO, donde la extracción de características ocurre al principio, y al final obtenemos una capa CNN que nos informa sobre todas las celdas en las que "dividimos" nuestra imagen. Y si esta capa nos dice una "mentira" sobre las células de la imagen, entonces debemos tener una gran pérdida, para que luego se pueda reducir cuando las siguientes imágenes se introduzcan en la red neuronal.
Para ser claros, hay un diagrama muy simple de cómo YOLO crea esta última capa:
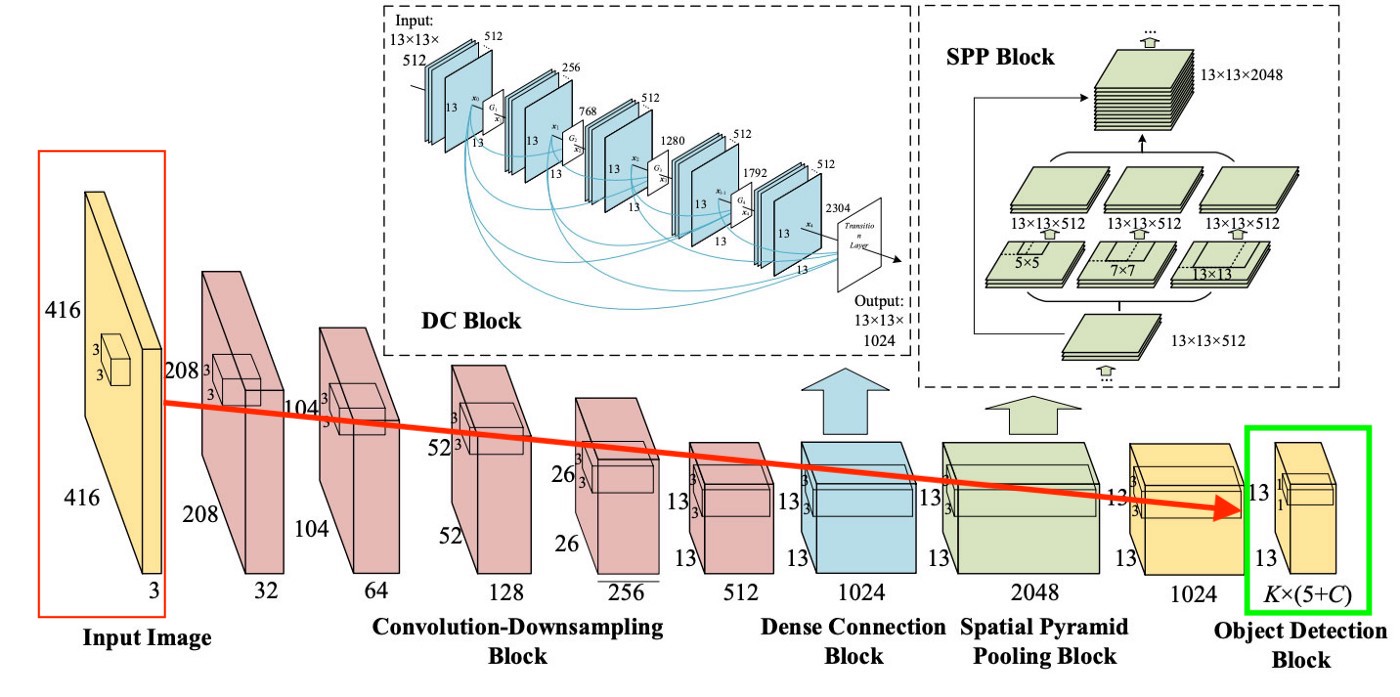
Como podemos ver en la imagen, esta capa es de 13x13 (para las imágenes, el tamaño original es 416x416) para hablar de "cada celda" en la imagen. De esta última capa se obtiene la información que queremos.
YOLO predice 5 parámetros (para cada cuadro de anclaje para una celda específica):

Para que sea más fácil de entender, hay una buena visualización sobre este tema:

Como puede entenderlos a partir de esta imagen, la tarea de YOLO es predecir estos parámetros con la mayor precisión posible para determinar el objeto en la imagen con la mayor precisión posible. Y la puntuación de confianza, que se determina para cada cuadro delimitador predicho, es una especie de filtro para filtrar predicciones completamente inexactas. Para cada cuadro delimitador predicho, multiplicamos su IoU por la probabilidad de que este sea un determinado objeto (la distribución de probabilidad se calcula durante el entrenamiento de la red neuronal), tomamos la mejor probabilidad de todas las posibles, y si el número después de la multiplicación excede un cierto umbral, entonces podemos dejar esta predicción. cuadro delimitador en la imagen.
Además, cuando solo hemos predicho cuadros delimitadores con una puntuación de confianza alta, nuestras predicciones (si se visualizan) pueden tener un aspecto similar al siguiente:

Ahora podemos usar la técnica NMS (supresión no máxima) para filtrar los cuadros delimitadores de tal manera que para de un objeto, solo había un cuadro delimitador previsto.

También debe saber que YOLOv3-4 se predice en 3 escalas diferentes. Es decir, la imagen se divide en 64 celdas de cuadrícula, 256 celdas y 1024 celdas para poder ver también objetos pequeños. Para cada grupo de células, el algoritmo repite las acciones necesarias durante la predicción / aprendizaje, que se describieron anteriormente.
Se han utilizado muchas técnicas en YOLOv4 para aumentar la precisión del modelo sin perder demasiada velocidad. Pero para la predicción en sí, Dense Prediction se dejó igual que en YOLOv3. Si está interesado en lo que los autores han hecho de manera mágica para aumentar la precisión sin perder velocidad, hay un excelente artículo escrito sobre YOLOv4 .
Espero haber podido transmitir un poco sobre cómo funciona YOLO en general (más precisamente, las dos últimas versiones, es decir, YOLOv3 y YOLOv4), y esto despierte en ustedes el deseo de usar este modelo en el futuro, o aprender un poco más sobre su trabajo.
Ahora que hemos descubierto cuál es quizás la mejor red neuronal para la detección de objetos (en términos de velocidad / calidad), finalmente pasemos a cómo podemos asociar información sobre nuestros objetos YOLO específicos entre cuadros de video. ¿Cómo puede entender el programa que la persona en el cuadro anterior es la misma persona que en el nuevo?
SORT profundo
Para comprender esta tecnología, primero debe comprender un par de aspectos matemáticos: la distancia de Mahalonobis y el filtro de Kalman.
Distancia de Mahalonobis
Veamos un ejemplo muy simple para entender intuitivamente qué es la distancia de Maholonobis y por qué es necesaria. Probablemente mucha gente sepa cuál es la distancia euclidiana. Por lo general, esta es la distancia de un punto a otro en el espacio euclidiano:
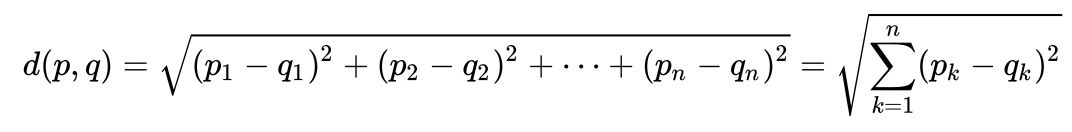

digamos que tenemos dos variables: X1 y X2. Para cada uno de ellos, tenemos muchas dimensiones.
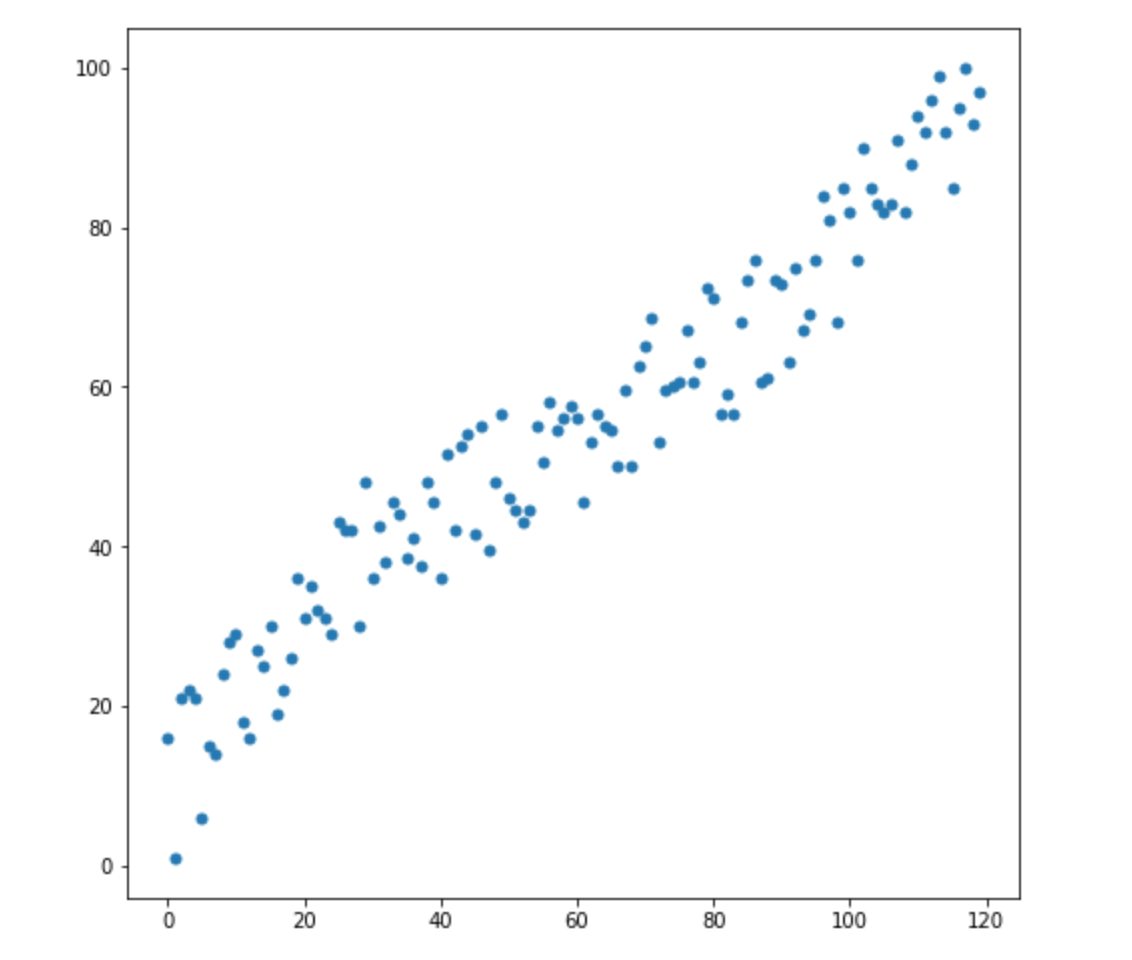
Ahora, digamos que tenemos 2 nuevas dimensiones:
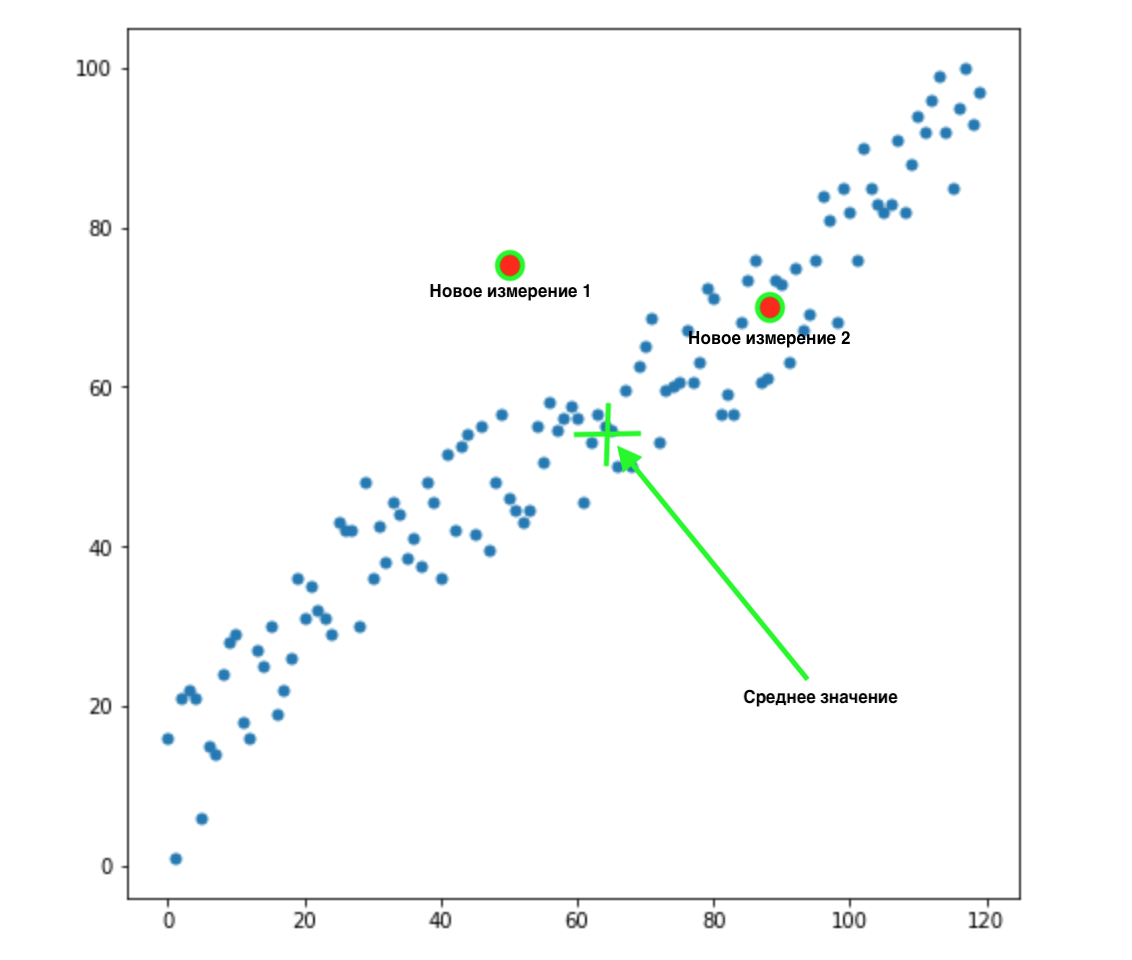
¿Cómo sabemos cuál de estos dos valores es el más apropiado para nuestra distribución? Todo es obvio a la vista, el punto 2 nos conviene. Pero la distancia euclidiana a la media es la misma para ambos puntos. En consecuencia, una simple distancia euclidiana a la media no nos funcionará.
Como podemos ver en la imagen de arriba, las variables están correlacionadas entre sí y de manera bastante fuerte. Si no se correlacionaron entre sí, o correlacionaron mucho menos, podríamos cerrar los ojos y aplicar la distancia euclidiana para ciertas tareas, pero aquí debemos corregir la correlación y tenerla en cuenta.
La distancia de Mahalonobis simplemente hace frente a esto. Dado que generalmente hay más de dos variables en los conjuntos de datos, usaremos una matriz de covarianza en lugar de correlación:
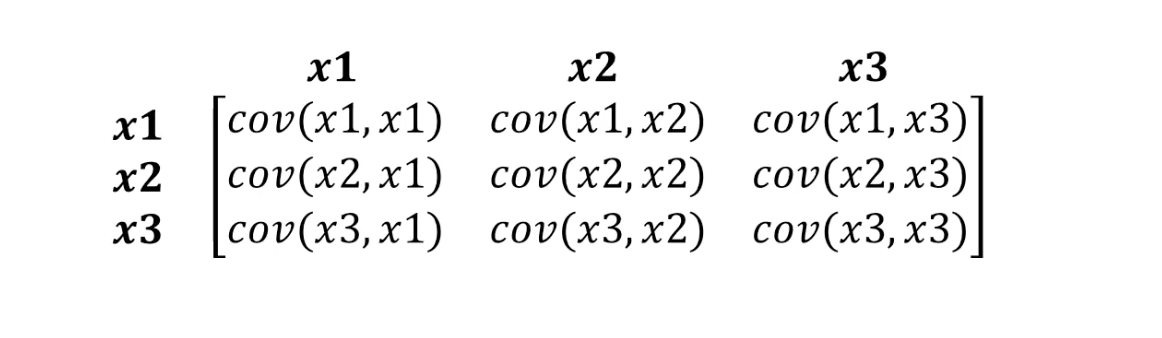
Lo que realmente hace la distancia de Mahalonobis:
- Deshazte de la covarianza variable
- Hace que la varianza de las variables sea igual a 1
- Luego usa la distancia euclidiana habitual para los datos transformados.
Veamos la fórmula de cómo se calcula la distancia de Mahalonobis:

Veamos qué significan los componentes de nuestra fórmula:
- Esta diferencia es la diferencia entre nuestro nuevo punto y las medias de cada variable.
- S es la matriz de covarianza de la que hablamos un poco antes.
Se puede entender algo muy importante a partir de la fórmula. De hecho, estamos multiplicando por la matriz de covarianza invertida. En este caso, cuanto mayor sea la correlación entre las variables, más probable es que acortemos la distancia, ya que multiplicaremos por el inverso de uno mayor, es decir, un número menor (si en palabras simples).
Probablemente no entraremos en los detalles del álgebra lineal, todo lo que necesitamos entender es que medimos la distancia entre puntos de tal manera que se tenga en cuenta la varianza de nuestras variables y la covarianza entre ellas.
Filtro de Kalman
Para darse cuenta de que esto es algo interesante y probado que se puede aplicar en tantas áreas, es suficiente saber que el filtro Kalman se usó en la década de 1960. Sí, sí, estoy insinuando esto: el vuelo a la luna. Se ha aplicado allí en varios lugares, incluido el trabajo con rutas de vuelo de ida y vuelta. El filtro de Kalman también se utiliza a menudo en el análisis de series de tiempo en los mercados financieros, en el análisis de indicadores de varios sensores en fábricas, empresas y muchos otros lugares. Espero haberlo intrigado un poco y describiremos brevemente el filtro de Kalman y cómo funciona. También te aconsejo que leas este artículo sobre Habré si quieres aprender más sobre él.
Filtro de Kalman
, . , , .
, . 4 . , 72 .
3 :
1) (Kalman Gain):

, - ( ).
2) , ( , ), , .

3) (), :
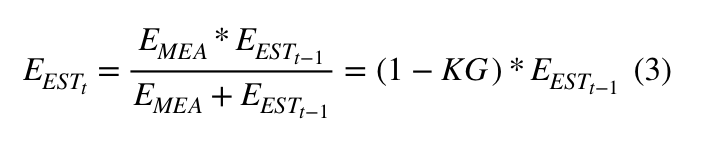
, :
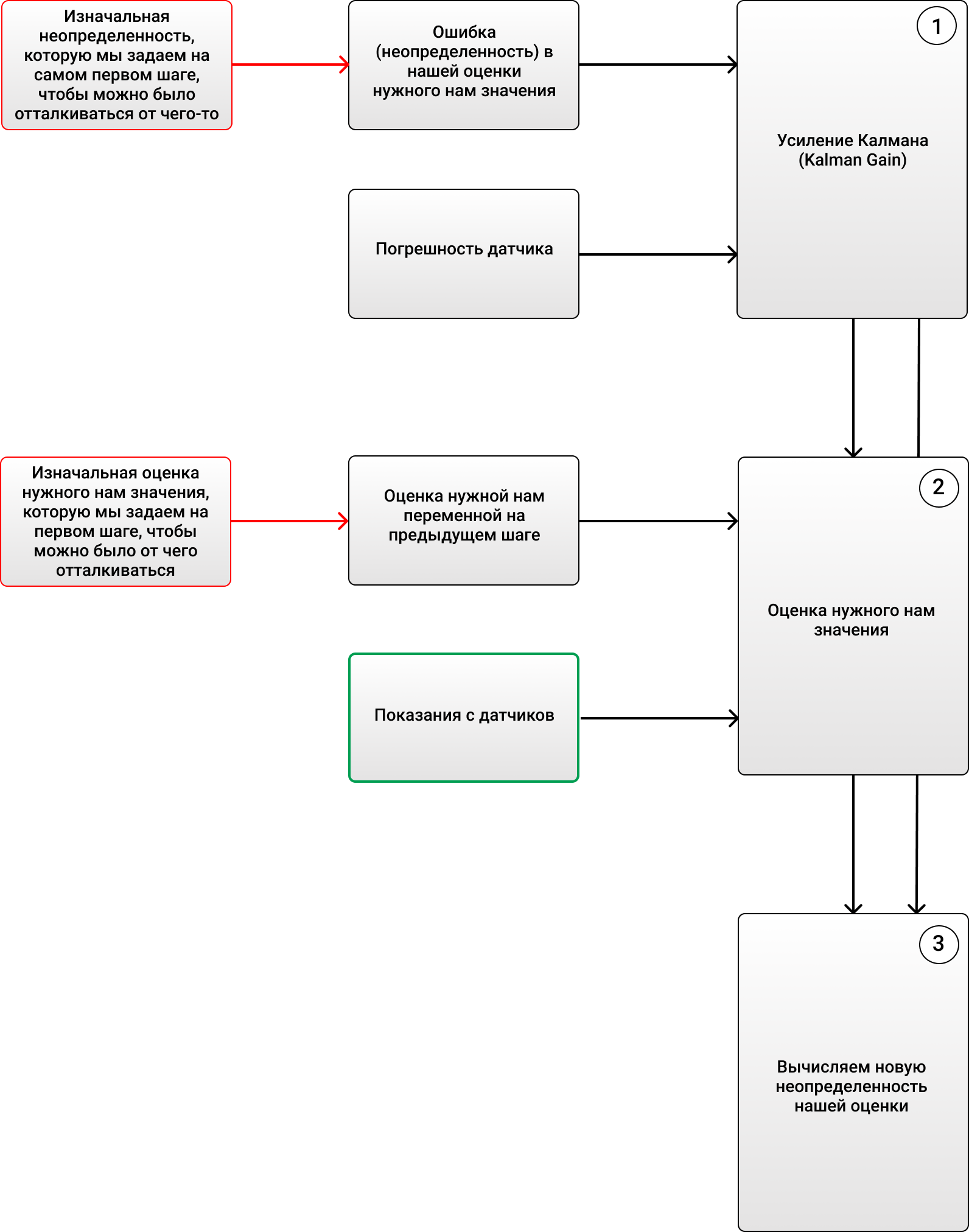
, 69 ( ), 2 . , , 4 (, , ), KG (1) 2/(2+4) = 0.33. ( ), . 70 (), . (2), , 68+0.33(70-68)=68.66. (3) (1-0.33)2 = 1.32. , , , . :
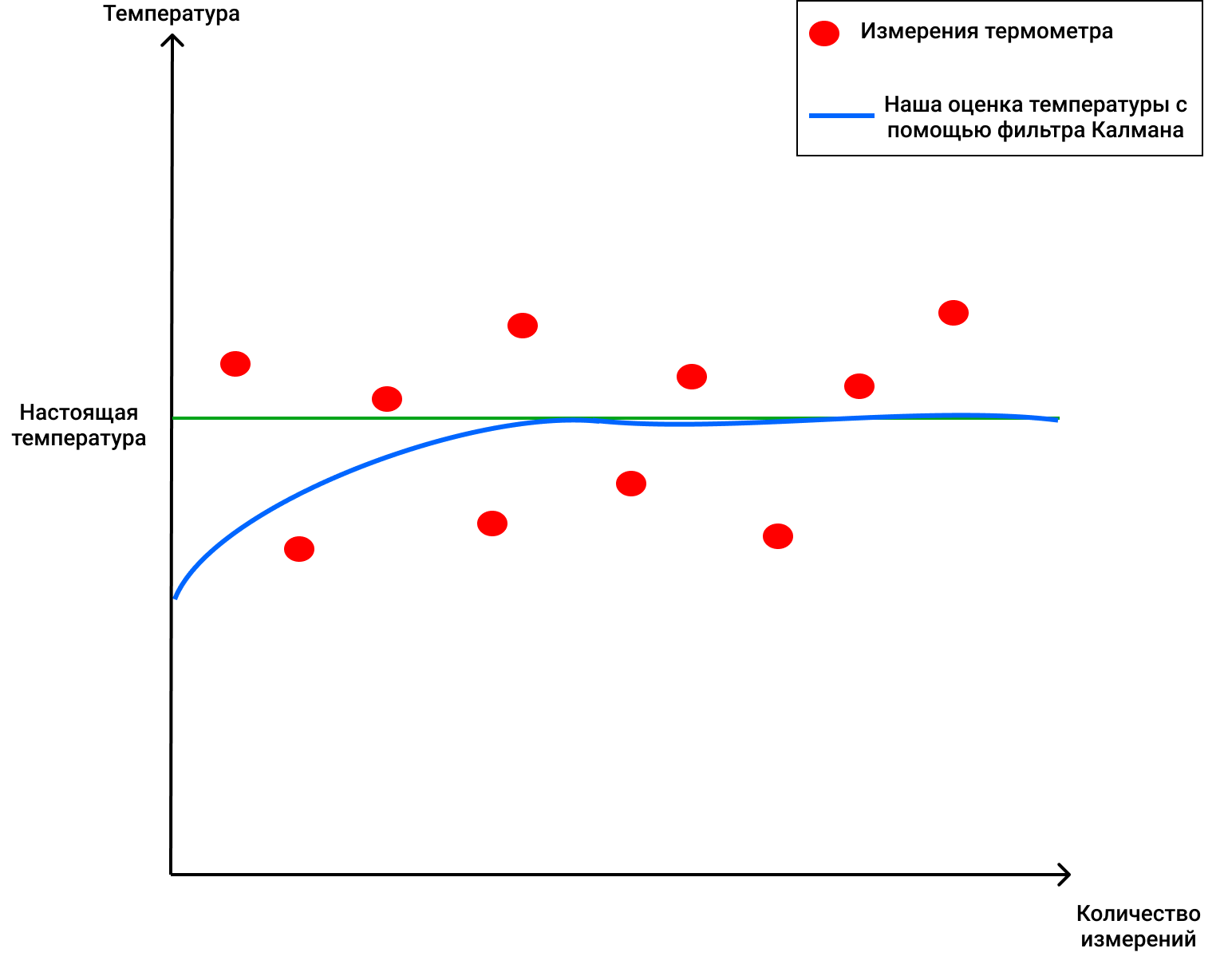
, !
, , , , , ( , ).
, . 4 . , 72 .
3 :
1) (Kalman Gain):
, - ( ).
2) , ( , ), , .
3) (), :
, :
, 69 ( ), 2 . , , 4 (, , ), KG (1) 2/(2+4) = 0.33. ( ), . 70 (), . (2), , 68+0.33(70-68)=68.66. (3) (1-0.33)2 = 1.32. , , , . :
, !
, , , , , ( , ).
DeepSORT - ¡por fin!
Entonces, ahora sabemos cuáles son el filtro de Kalman y la distancia de Mahalonobis. La tecnología DeepSORT simplemente vincula estos dos conceptos para transferir información de un marco a otro y agrega una nueva métrica llamada apariencia. Primero, utilizando la detección de objetos, se determinan la posición, el tamaño y la clase de un cuadro delimitador. Luego, puede, en principio, aplicar el algoritmo húngaro para asociar ciertos objetos con ID de objeto que estaban previamente en el marco y seguidos usando filtros de Kalman, y todo será excelente, como en el SORT original.... Pero la tecnología DeepSORT permite mejorar la precisión de detección y reducir el número de cambios entre objetos, cuando, por ejemplo, una persona en el encuadre obstruye brevemente a otra, y ahora la persona que fue obstruida se considera un objeto nuevo. Como lo hace ella?
Ella agrega un elemento interesante a su trabajo: la llamada "apariencia" de las personas que aparecen en el marco (apariencia). Esta apariencia fue entrenada por una red neuronal separada que fue creada por los autores de DeepSORT. Usaron alrededor de 1,100,000 imágenes de más de 1000 personas diferentes para hacer que la red neuronal prediga correctamenteEl SORT original tiene un problema, ya que la apariencia del objeto no se usa allí, de hecho, cuando el objeto cubre algo para varios marcos (por ejemplo, otra persona o una columna dentro de un edificio), el algoritmo luego asigna otra ID a esta persona, como resultado. por lo que la llamada "memoria" de los objetos en el SORT original es bastante efímera.
Así que ahora los objetos tienen dos propiedades: su dinámica de movimiento y su apariencia. Para la dinámica, tenemos indicadores que se filtran y predicen usando el filtro de Kalman - (u, v, a, h, u ', v', a ', h'), donde u, v es la posición X del rectángulo predicho y Y, a es la relación de aspecto del rectángulo predicho, h es la altura del rectángulo y las derivadas con respecto a cada valor. Por apariencia, se entrenó una red neuronal, que tenía la estructura:
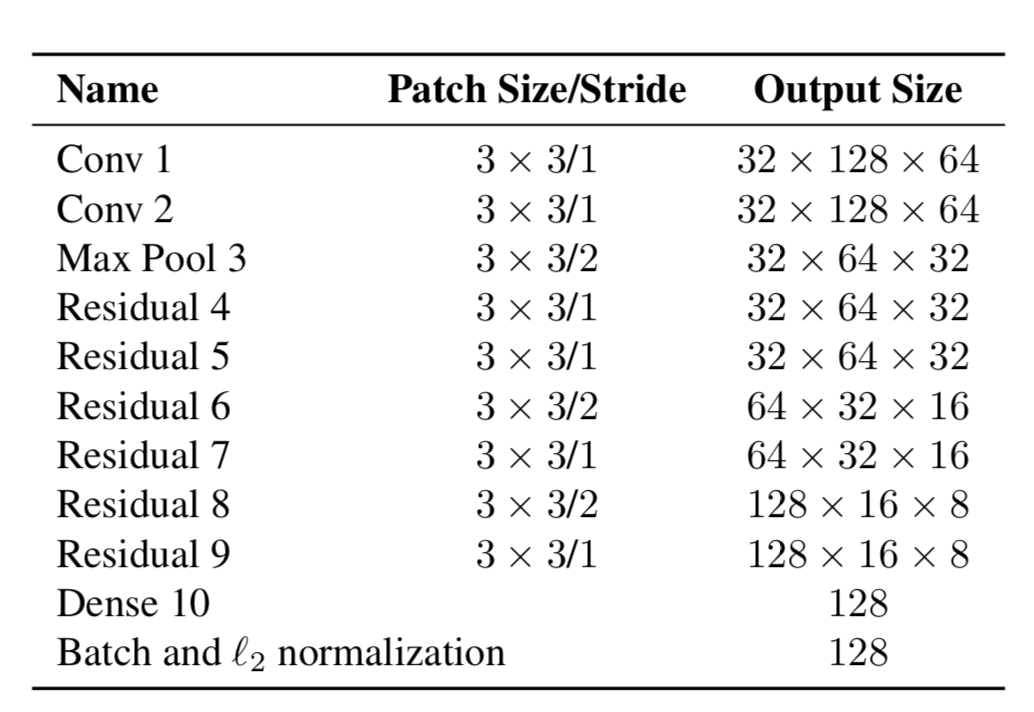
Y al final dio un vector de características, de tamaño 128x1. Y luego, en lugar de calcular la distancia entre ciertos objetos usando YOLO, y los objetos que ya seguimos en el cuadro, y luego asignar una cierta ID simplemente usando la distancia de Mahalonobis, los autores crearon una nueva métrica para calcular la distancia, que incluye ambas predicciones usando filtros de Kalman, y "distancia de coseno", como se llama de otra manera, el coeficiente de Otiai.
Como resultado, la distancia de un determinado objeto YOLO al objeto predicho por el filtro de Kalman (o un objeto que ya se encuentra entre los que se observaron en los cuadros anteriores) es:

Donde Da es la distancia de similitud externa y Dk es la distancia de Mahalonobis. Además, esta distancia híbrida se utiliza en el algoritmo húngaro para clasificar correctamente ciertos objetos con ID existentes.
Por lo tanto, una simple métrica adicional Da ayudó a crear un nuevo y elegante algoritmo DeepSORT que se usa en muchos problemas y es bastante popular en el problema de seguimiento de objetos.
El artículo resultó tener bastante peso, ¡gracias a quienes leyeron hasta el final! Espero haber podido contarte algo nuevo y ayudarte a comprender cómo funciona el seguimiento de objetos en YOLO y DeepSORT.