Toda la implementación en un archivo .h de encabezado: [fast_mem_pool.h]
Chips, por qué este asignador es mejor que cientos de otros similares, por debajo del corte.
Así es como funciona mi bicicleta.
1) En la versión de versión, no hay mutex ni ciclos de espera para atómico, pero el asignador es cíclico y regenera continuamente los recursos a medida que los subprocesos los liberan. ¿Cómo lo hace?
Cada asignación de RAM que FastMemPool proporciona a través de fmalloc es en realidad más para un encabezado:
struct AllocHeader {
// : tag_this = this + leaf_id
uint64_t tag_this { 2020071700 };
// :
int size;
// :
int leaf_id { -2020071708 };
};
Este encabezado siempre se puede obtener del puntero propiedad del usuario retrocediendo desde el puntero (res_ptr) sizeof (AllocHeader):

Por el contenido del encabezado AllocHeader, el método ffree (void * ptr) reconoce sus asignaciones y descubre en cuál de las hojas de la memoria intermedia circular se devuelve :
void ffree(void *ptr)
{
char *to_free = static_cast<char *>(ptr)
- sizeof(AllocHeader);
AllocHeader *head = reinterpret_cast<AllocHeader *>(to_free);
Cuando se le pide al asignador que asigne memoria, mira la hoja actual de la matriz de hojas para ver si puede cortar el tamaño requerido + el tamaño del tamaño del encabezado de (AllocHeader).
En el asignador, las hojas de memoria Leaf_Cnt se reservan por adelantado, cada hoja del tamaño Leaf_Size_Bytes (aquí todo es tradicional). En busca de una oportunidad de asignación, el método fmalloc (std :: size_t deployment_size) circulará a través de las hojas de la matriz leaf_array, y si todo está ocupado en todas partes, entonces, siempre que la bandera Do_OS_malloc esté habilitada, tomará memoria del sistema operativo más grande que el tamaño requerido por sizeof (AllocHeader) - afuera la memoria se toma del búfer circular interno o del sistema operativo, el asignador siempre crea un encabezado con información de servicio. Si el asignador se queda sin memoria y el indicador Do_OS_malloc == false, fmalloc devolverá nullptr; este comportamiento es útil para controlar la carga (por ejemplo, omitir fotogramas de una cámara de video cuando los módulos de procesamiento de fotogramas no se mantienen al día con el FPS de la cámara).
Cómo se implementa el ciclismo
Los asignadores cíclicos están diseñados para tareas cíclicas; las tareas no deberían durar para siempre. Por ejemplo, puede ser:
- asignaciones para sesiones de usuario
- procesamiento de fotogramas de transmisión de video para análisis de video
- la vida de las unidades de combate en el juego
Dado que puede haber cualquier cantidad de hojas de memoria en la matriz leaf_array, en el límite es posible hacer una página para la cantidad teóricamente posible de unidades de combate en el juego, de modo que con la condición de que las unidades abandonen, tenemos la garantía de obtener una hoja de memoria gratis. En la práctica, para el análisis de video, normalmente me bastan 16 hojas grandes, de las cuales las primeras hojas se donan para asignaciones no cíclicas largas cuando se inicializa el detector.
Cómo se implementa la seguridad de subprocesos
Un conjunto de hojas de asignación funciona sin mutex ... La protección contra errores del tipo "carrera de datos" se realiza de la siguiente manera:
char *buf;
// available == offset
std::atomic<int> available { Leaf_Size_Bytes };
// allocated ==
std::atomic<int> deallocated { 0 };
Cada hoja de memoria tiene 2 contadores:
- disponible inicializado por el tamaño de Leaf_Size_Bytes. Con cada asignación, este contador disminuye, y el mismo contador sirve como un desplazamiento relativo al comienzo de la hoja de memoria == la memoria se asigna desde el final del búfer:
result_ptr = leaf_array[leaf_id].buf + available_after;
- la desasignación se inicializa {0} a cero, y con cada desasignación en esta hoja (me enteré de AllocHeader en qué hoja o sistema operativo se está tratando el trato) el contador aumenta en el volumen liberado:
const int deallocated = leaf_array[head->leaf_id].deallocated.fetch_add(real_size, std::memory_order_acq_rel) + real_size;
Tan pronto como los contadores como este (desasignados == (Leaf_Size_Bytes - disponible)) coincidan, esto significa que todo lo que se ha asignado ahora se libera y puede restablecer la hoja a su estado original, pero aquí hay un punto sutil: qué pasará si después de la decisión de restablecer la hoja de vuelta al original, alguien asigna otra pequeña parte de la memoria de la hoja ... Para excluir esto, use la verificación compare_exchange_strong:
if (deallocated == (Leaf_Size_Bytes - available))
{ // ,
// , , Leaf
if (leaf_array[head->leaf_id].available
.compare_exchange_strong(available, Leaf_Size_Bytes))
{
leaf_array[head->leaf_id].deallocated -= deallocated;
}
}
La hoja de memoria se restablece a su estado original solo si en el momento del restablecimiento permanece el mismo estado del contador disponible, que estaba en el momento de la decisión. Ta-daa !!!
Una buena ventaja es que puede detectar los siguientes errores utilizando el encabezado AllocHeader de cada asignación:
- reasignación
- desasignación de la memoria de otra persona
- desbordamiento de búfer
- acceso al área de memoria de otra persona
La segunda característica se implementa en estas oportunidades.
2) La compilación Debug proporciona la información exacta donde estaba la desasignación anterior durante la reasignación: nombre de archivo, número de línea de código, nombre del método. Esto se implementa en forma de decoradores alrededor de los métodos base (fmallocd, ffreed, check_accessd; la versión de depuración de los métodos tiene una d al final):
/**
* @brief FFREE - free
* @param iFastMemPool - FastMemPool
* @param ptr - fmaloc
*/
#if defined(Debug)
#define FFREE(iFastMemPool, ptr) \
(iFastMemPool)->ffreed (__FILE__, __LINE__, __FUNCTION__, ptr)
#else
#define FFREE(iFastMemPool, ptr) \
(iFastMemPool)->ffree (ptr)
#endif
Se utilizan las macros del preprocesador:
- __FILE__ - archivo fuente de c ++
- __LINE__ - número de línea en el archivo fuente de c ++
- __FUNCTION__ - nombre de la función donde sucedió esto
Esta información se almacena como una coincidencia entre el puntero de asignación y la información de asignación en el mediador:
struct AllocInfo {
// : , , :
std::string who;
// true - , false - :
bool allocated { false };
};
std::map<void *, AllocInfo> map_alloc_info;
std::mutex mut_map_alloc_info;
Dado que la velocidad no es tan importante para la depuración, se utilizó un mutex para proteger el estándar std :: map. El parámetro de plantilla (bool Raise_Exeptions = DEF_Raise_Exeptions) afecta si lanzar una excepción en caso de error.
Para aquellos que desean la máxima comodidad en la compilación de la versión, puede configurar el indicador DEF_Auto_deallocate, luego se escribirán todas las asignaciones de malloc del sistema operativo (ya bajo el mutex en std :: set <>) y se liberarán en el destructor FastMemPool (utilizado como un rastreador de asignaciones).
3)Para evitar errores como "desbordamiento de búfer", recomiendo usar la verificación FastMemPool :: check_access antes de comenzar a trabajar con la memoria asignada. Si bien el sistema operativo solo se queja cuando ingresa a la RAM de otra persona, la función check_access (o la macro FCHECK_ACCESS) calcula mediante el encabezado AllocHeader si habrá un exceso de la asignación dada:
/**
* @brief check_access -
* @param base_alloc_ptr - FastMemPool
* @param target_ptr -
* @param target_size - ,
* @return - true FastMemPool
*/
bool check_access(void *base_alloc_ptr, void *target_ptr, std::size_t target_size)
// :
if (FCHECK_ACCESS(fastMemPool, elem.array,
&elem.array[elem.array_size - 1], sizeof (int)))
{
elem.array[elem.array_size - 1] = rand();
}
Al conocer el puntero de la asignación inicial, siempre puede obtener el encabezado, del encabezado averiguamos el tamaño de la asignación y luego calculamos si el elemento de destino estará dentro de la asignación inicial. Es suficiente verificar una vez antes de iniciar el ciclo de procesamiento en el acceso máximo teóricamente posible. Es muy posible que los valores límite superen los límites de asignación (por ejemplo, en los cálculos se supone que alguna variable solo puede caminar en un cierto rango debido a la física del proceso y, por lo tanto, no verifica si se rompió el límite de asignación).
Es mejor verificar una vez que matar una semana después buscando a alguien que ocasionalmente escriba datos aleatorios en sus estructuras ...
4) Establecer el código de plantilla predeterminado en tiempo de compilación a través de CMake.
CmakeLists.txt contiene parámetros configurables, por ejemplo:
set(DEF_Leaf_Size_Bytes "65536" CACHE PATH "Size of each memory pool leaf")
message("DEF_Leaf_Size_Bytes: ${DEF_Leaf_Size_Bytes}")
set(DEF_Leaf_Cnt "16" CACHE PATH "Memory pool leaf count")
message("DEF_Leaf_Cnt: ${DEF_Leaf_Cnt}")
Esto hace que sea muy conveniente editar los parámetros en QtCreator:

o CMake GUI:

Luego, los parámetros se pasan al código durante la compilación de la siguiente manera:
set(SPEC_DEFINITIONS
${CMAKE_SYSTEM_NAME}
${CMAKE_BUILD_TYPE}
${SPEC_BUILD}
SPEC_VERSION="${Proj_VERSION}"
DEF_Leaf_Size_Bytes=${DEF_Leaf_Size_Bytes}
DEF_Leaf_Cnt=${DEF_Leaf_Cnt}
DEF_Average_Allocation=${DEF_Average_Allocation}
DEF_Need_Registry=${DEF_Need_Registry}
)
#
target_compile_definitions(${TARGET} PUBLIC ${TARGET_DEFINITIONS})
y en el código anula los valores de la plantilla en Default:
#ifndef DEF_Leaf_Size_Bytes
#define DEF_Leaf_Size_Bytes 65535
#endif
template<int Leaf_Size_Bytes = DEF_Leaf_Size_Bytes,
int Leaf_Cnt = DEF_Leaf_Cnt,
int Average_Allocation = DEF_Average_Allocation,
bool Do_OS_malloc = DEF_Do_OS_malloc,
bool Need_Registry = DEF_Need_Registry,
bool Raise_Exeptions = DEF_Raise_Exeptions>
class FastMemPool
{
// ..
};
Por lo tanto, la plantilla del asignador se puede ajustar cómodamente con el mouse activando / desactivando las casillas de verificación de los parámetros de CMake.
5) Para poder usar el asignador en contenedores STL en el mismo archivo .h, las capacidades de std :: allocator se implementan parcialmente en la plantilla FastMemPoolAllocator:
// compile time :
std::unordered_map<int, int, std::hash<int>,
std::equal_to<int>,
FastMemPoolAllocator<std::pair<const int, int>> > umap1;
// runtime :
std::unordered_map<int, int> umap2(
1024, std::hash<int>(),
std::equal_to<int>(),
FastMemPoolAllocator<std::pair<const int, int>>());
Se pueden encontrar ejemplos de uso aquí: test_allocator1.cpp y test_stl_allocator2.cpp .
Por ejemplo, el trabajo de constructores y destructores en asignaciones:
bool test_Strategy()
{
/*
* Runtime
* ( )
*/
using MyAllocatorType = FastMemPool<333, 33>;
// instance of:
MyAllocatorType fastMemPool;
// inject instance:
FastMemPoolAllocator<std::string,
MyAllocatorType > myAllocator(&fastMemPool);
// 3 :
std::string* str = myAllocator.allocate(3);
// :
myAllocator.construct(str, "Mother ");
myAllocator.construct(str + 1, " washed ");
myAllocator.construct(str + 2, "the frame");
//-
std::cout << str[0] << str[1] << str[2];
// :
myAllocator.destroy(str);
myAllocator.destroy(str + 1);
myAllocator.destroy(str + 2);
// :
myAllocator.deallocate(str, 3);
return true;
}
6) A veces, en un proyecto grande, haces algún tipo de módulo, probaste todo a fondo; funciona como un reloj suizo. Su módulo está incluido en el Detector, libra una batalla y, a veces, una vez al día, la biblioteca comienza a caer en un basurero. Al ejecutar un volcado en el depurador, descubre que en uno de los recorridos de bucle de punteros, en lugar de nullptr, alguien escribió el número 8 en su puntero; al ir a este puntero, naturalmente enojó al sistema operativo.
¿Cómo podemos reducir la gama de posibles culpables? Es muy simple excluir sus estructuras de los sospechosos: deben trasladarse a RAM a otro lugar (donde el saboteador no bombardea):
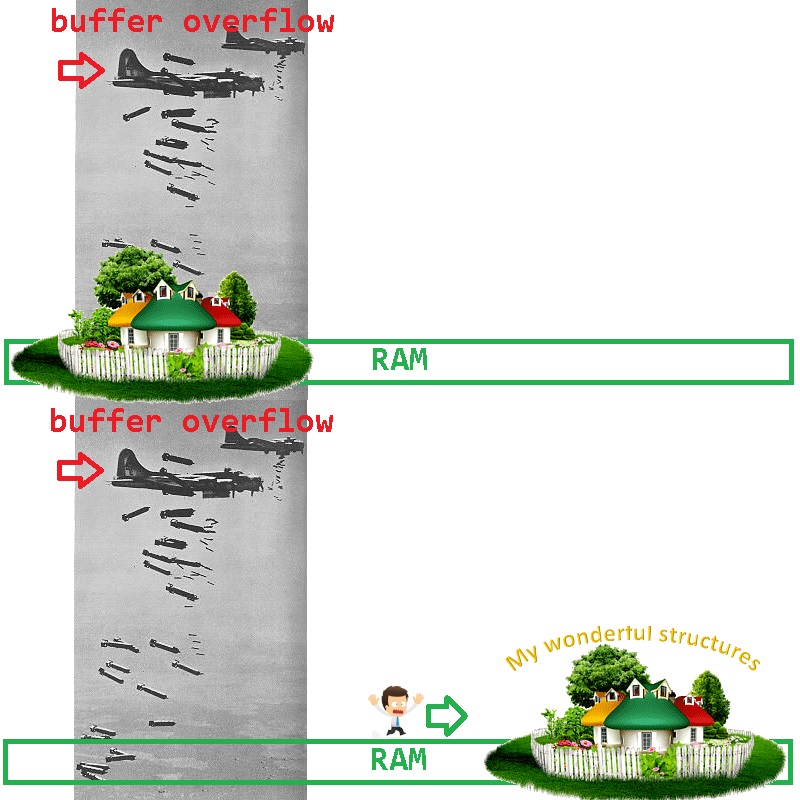
¿Cómo se puede hacer esto fácilmente con FastMemPool? Es muy simple: en FastMemPool, la asignación se produce partiendo desde el final de la página de memoria; al solicitar una página de memoria más de la que necesita para trabajar, garantiza que el comienzo de la página de memoria sigue siendo un campo de pruebas para el bombardeo de errores. Por ejemplo:
FastMemPool<100000000, 1, 1024, true, true> bulletproof_mempool;
void *ptr = bulletproof_mempool.fmalloc(1234567);
// ..
// - c ptr
// ..
bulletproof_mempool.ffree(ptr);
Si en un lugar nuevo alguien está bombardeando tus estructuras, lo más probable es que seas tú mismo ...
De lo contrario, si la biblioteca se estabiliza, el equipo recibirá varios obsequios a la vez:
- tu algoritmo vuelve a funcionar como un reloj suizo
- el codificador con errores ahora puede bombardear con seguridad un área de memoria vacía (mientras todos la buscan), la biblioteca es estable.
- el rango de bombardeo se puede monitorear para cambiar la memoria, para colocar trampas en un codificador con errores.
En total , cuáles son las ventajas de esta bicicleta en particular:
- ( / )
- , Debug ,
- , /
- , ( nullptr), — , ( FPS , FastMemPool -).
En nuestra empresa, la instalación del análisis de geometría 3D de láminas de metal requirió procesamiento multiproceso de fotogramas de video (50FPS). Las hojas pasan por debajo de la cámara y sobre el reflejo del láser construyo un mapa 3D de la hoja. FastMemPool se utilizó para garantizar la máxima velocidad de trabajo con memoria y seguridad. Si los flujos no hacen frente a las tramas entrantes, guardar las tramas para el procesamiento futuro de la forma habitual conduce a un consumo incontrolado de RAM. Con FastMemPool, en caso de desbordamiento, nullptr simplemente se devolverá durante la asignación y se omitirá el marco; en la imagen 3D final, tal defecto en forma de salto en un paso muestra que es necesario agregar subprocesos de CPU al procesamiento.
La operación de subprocesos sin mutex con un asignador de memoria circular y una pila de tareas hizo posible procesar las tramas entrantes muy rápidamente, sin pérdida de tramas y sin desbordamiento de RAM. Ahora este código se ejecuta en 16 subprocesos en una CPU AMD Ryzen 9 3950X, no se han identificado fallas en la clase FastMemPool.
Se puede ver un diagrama de ejemplo simplificado del proceso de análisis de video con control de desbordamiento de RAM en el código fuente test_memcontrol1.cpp .
Y para el postre: el mismo esquema de ejemplo usa una pila sin mutex:
using TWorkStack = SpecSafeStack<VideoFrame>;
//..
// Video frames exchanger:
TWorkStack work_stack;
//..
work_staff->work_stack.push(frame);
//..
VideoFrame * frame = work_staff->work_stack.pop();
Un soporte de demostración en funcionamiento con todas las fuentes está aquí en gihub .