
Siempre me han interesado las fallas del sistema y las rarezas de su comportamiento, especialmente cuando funcionan en sus condiciones normales. Recientemente vi una de las diapositivas de presentación de Ian Goodfellow, que me pareció muy divertida. Se envió un ruido visual aleatorio a una red neuronal entrenada y ella lo reconoció como uno de los objetos que conocía. Aquí surgen inmediatamente muchas preguntas. ¿Las diferentes redes neuronales entrenadas verán el mismo objeto? ¿Cuál es el nivel máximo de confianza en la red neuronal de que este ruido aleatorio es de hecho un objeto reconocido? ¿Y qué es lo que realmente "ve" la red neuronal allí?
De mi curiosidad por esto, nació esta entrada. Afortunadamente, experimentos como este son muy fáciles de hacer con PyTorch.... Para visualizar por qué la red neuronal clasifica los objetos de cierta manera, utilizo el marco de interpretación del modelo Captum . El código se puede descargar desde Github .
Importancia de las preguntas
Puede preguntar por qué son importantes estas preguntas. En muchos casos, los desarrolladores no crean modelos desde cero. Eligen plataformas y redes pre-entrenadas del zoológico modelo como puntos de partida. Esto ahorra tiempo: no es necesario recopilar datos ni realizar el entrenamiento inicial de la red neuronal. Sin embargo, también significa que pueden surgir problemas inesperados en lugares inesperados. Dependiendo de cómo se utilice este modelo, pueden surgir problemas de seguridad en el proceso.
Modelos previamente entrenados
Los modelos previamente entrenados son fáciles de usar y pueden enviar datos rápidamente para su clasificación. En este caso, no necesita definir modelos y entrenarlos; todo esto ya se ha hecho antes que usted y están listos para usar inmediatamente después de la implementación. Los modelos previamente entrenados de la biblioteca de Torchvision se entrenan en un conjunto de imágenes de la base de datos de Imagenet , divididas en 1000 categorías... Es importante recordar que esta capacitación implicó identificar un solo objeto en una imagen, no analizar imágenes complejas que contienen varios objetos. En el segundo caso, también puede obtener resultados interesantes, pero este es un tema completamente diferente. Descargar modelos previamente entrenados de la biblioteca de Torchvision es muy fácil. Solo necesita importar el modelo seleccionado configurando el parámetro preentrenado en Verdadero. También he incluido un modo de evaluación en los modelos, ya que no hay curva de aprendizaje durante las pruebas.
Primero tengo una línea de código que elige usar cuda o cpu, dependiendo de si hay una GPU disponible. Para estas sencillas pruebas no se requiere una GPU, pero como tengo una, la uso.
device = "cuda" if torch.cuda.is_available() else "cpu"
import torchvision.models as models
vgg16 = models.vgg16(pretrained=True)
vgg16.eval()
vgg16.to(device)
Puede encontrar una lista de modelos previamente entrenados de Torchvision aquí . No quería usar todas las redes neuronales previamente entrenadas, esto ya es demasiado. Elegí los siguientes cinco:
- vgg16
- resnet18
- alexnet
- densenet
- comienzo
No utilicé ninguna metodología especial para elegir redes neuronales. Por ejemplo, Vgg16 e Inception se usan a menudo en diferentes ejemplos, y todos son diferentes.
Cómo crear imágenes con ruido
Necesitaremos una forma de generar automáticamente imágenes que contengan ruido que se puedan alimentar a las redes neuronales. Para hacer esto, utilicé una combinación de las bibliotecas Numpy y PIL, y escribí una pequeña función que devuelve una imagen llena de ruido aleatorio.
import numpy as np
from PIL import Image
def gen_image():
image = (np.random.standard_normal([256, 256, 3]) * 255).astype(np.uint8)
im = Image.fromarray(image)
return im
Terminas con algo como lo siguiente:

Conversión de imágenes
Después de eso, necesitamos convertir nuestras imágenes a tensor y normalizarlas. El siguiente código se puede usar no solo en ruido aleatorio, sino también en cualquier imagen que queramos alimentar a redes neuronales previamente entrenadas (por eso el código usa los valores Resize y CenterCrop).
def xform_image(image):
transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
new_image = transform(image).to(device)
new_image = new_image.unsqueeze_(0)
return new_imageObtenemos predicciones
Una vez preparadas las imágenes transformadas, es fácil obtener predicciones del modelo desplegado. En este caso, se supone que la función xform_image devuelve image_xform. En el código que utilicé para las pruebas, dividí el trabajo entre estas dos funciones, pero aquí las puse juntas para facilitar la referencia. Básicamente, necesitamos alimentar la imagen transformada a la red, ejecutar la función softmax, usar la función topk para obtener la puntuación y la ID de etiqueta predicha para obtener el mejor resultado.
with torch.no_grad():
vgg16_res = vgg16(image_xform)
vgg16_output = F.softmax(vgg16_res, dim=1)
vgg16score, pred_label_idx = torch.topk(vgg16_output, 1)
resultados
Bueno, ahora vemos cómo generar imágenes ruidosas y alimentarlas a una red previamente entrenada. ¿Entonces cuales son los resultados? Para esta prueba, decidí generar 1000 imágenes ruidosas, las ejecuté a través de 5 redes seleccionadas previamente entrenadas y las metí en un marco de datos de Pandas para un análisis rápido. Los resultados fueron interesantes y algo inesperados.
| vgg16 | resnet18 | alexnet | densenet | comienzo | |
|---|---|---|---|---|---|
| contar | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 |
| media | 0.226978 | 0.328249 | 0.147289 | 0.409413 | 0.020204 |
| std | 0.067972 | 0.071808 | 0.038628 | 0.148315 | 0.016490 |
| min | 0.074922 | 0.127953 | 0.061019 | 0.139161 | 0,005963 |
| 25% | 0.178240 | 0.278830 | 0.120568 | 0.291042 | 0.011641 |
| 50% | 0.223623 | 0.324111 | 0.143090 | 0.387705 | 0.015880 |
| 75% | 0.270547 | 0.373325 | 0.171139 | 0.511357 | 0.022519 |
| max | 0.438011 | 0.580559 | 0.328568 | 0.868025 | 0.198698 |
Como puede ver, algunas de las redes neuronales han decidido que este ruido en realidad representa algo específico con un nivel de confianza bastante alto. Resnet18 y densenet han alcanzado un máximo del 50%. Eso está muy bien, pero ¿qué "ven" exactamente estas redes en medio del ruido? Curiosamente, diferentes redes "encontraron" diferentes objetos allí. Cada una de las redes vio algo diferente. Resnet18 estaba 100% segura de que se trataba de una medusa, mientras que Inception, por el contrario, tenía muy poca confianza en las predicciones, aunque al mismo tiempo vio muchos más objetos que cualquier otra red.
Vgg16:
978
14
7
1
Resnet18:
1000
Alexnet:
942
58
Densenet:
893
37
33
20
16
1
Inception:
155
123
102
85
83
81
69
32
26
25
24
18
16
16
12
12
11
9
9
8
7
5
5
5
- 5
4
4
4
4
3
3
3
3
3
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
Solo por diversión, decidí ver qué tipo de firma Microsoft pondrá debajo de la imagen de ruido, que acerqué al comienzo de esta entrada. Para la prueba, decidí seguir el camino más simple y usé PowerPoint de Office 365. El resultado es interesante porque, a diferencia de los modelos de imagenet que intentan reconocer un solo objeto, PowerPoint intenta reconocer varios objetos para crear una descripción precisa de la imagen.
La imagen muestra un elefante, gente, gran pelota.
El resultado no me defraudó. Desde mi punto de vista, la imagen de ruido fue reconocida como un circo.
Perspectivas
Esto nos lleva a otra pregunta: ¿qué ve la red neuronal que le hace pensar que el ruido es un objeto? En nuestra búsqueda de una respuesta, podemos utilizar una herramienta de interpretación de modelos que nos permitirá comprender aproximadamente lo que "ve" la red. Captum es un marco de interpretación de modelos para PyTorch. No hice nada especial aquí, solo usé el código de los tutoriales en su sitio web. Acabo de agregar el parámetro internal_batch_size con un valor de 50, porque sin él, mi GPU se quedó sin memoria muy rápidamente.
Para las representaciones, utilicé dos atribuciones basadas en gradientes y una atribución basada en oclusión. Con estas visualizaciones, intentamos comprender qué era importante para el clasificador y, por lo tanto, "ver" lo que ve la red. También utilicé mi modelo de resnet previamente entrenado, sin embargo, puedes cambiar el código y usar cualquier otro modelo previamente entrenado.
Antes de pasar al ruido, tomé la imagen de la manzanilla como demostración del proceso de renderizado, ya que sus signos son fáciles de reconocer.
result = resnet18(image_xform)
result = F.softmax(result, dim=1)
score, pred_label_idx = torch.topk(result, 1)
integrated_gradients = IntegratedGradients(resnet18)
attributions_ig = integrated_gradients.attribute(image_xform, target=pred_label_idx,
internal_batch_size=50, n_steps=200)
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(image_xform, n_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx, internal_batch_size=50)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)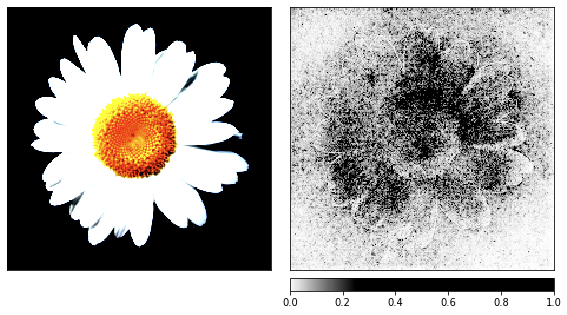
occlusion = Occlusion(resnet18)
attributions_occ = occlusion.attribute(image_xform,
strides = (3, 8, 8),
target=pred_label_idx,
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
show_colorbar=True,
outlier_perc=2,
)

Visualización de ruido
Generamos las imágenes anteriores basadas en la manzanilla, y ahora es el momento de ver cómo funcionan las cosas con ruido aleatorio.
Estoy usando la red resnet18 previamente entrenada y con esta imagen ella está 40% segura de que ve una medusa. No repetiré el código, el código para renderizar es el mismo que el dado arriba.


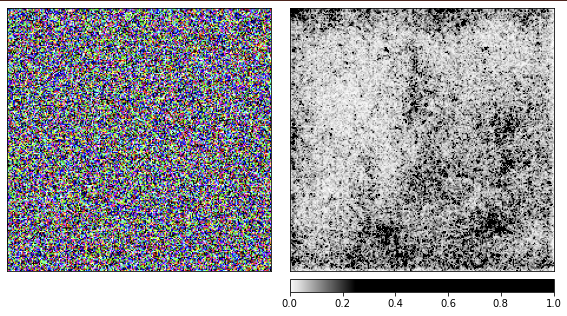

De las visualizaciones, está claro que los humanos nunca podremos entender por qué la red ve una medusa aquí. Algunas áreas de la imagen están marcadas como más importantes, pero no están tan definidas como vimos en el ejemplo de la manzanilla. A diferencia de la manzanilla, las medusas son amorfas y difieren en el nivel de transparencia.
Quizás se esté preguntando cómo sería el procesamiento de una imagen real de una medusa. Mi código está publicado en Github y será fácil obtener una respuesta a esta pregunta con su ayuda.
Conclusión
Con base en esta grabación, es fácil ver lo fácil que es engañar a las redes neuronales alimentándolas con entradas inesperadas. A su favor, diremos que hicieron su trabajo y dieron el mejor resultado que pudieron. También se puede ver en los resultados del trabajo que en tales casos no es suficiente filtrar las opciones con poca confianza, ya que algunas opciones tenían una confianza bastante alta. Necesitamos estar atentos a situaciones en las que los sistemas del mundo real fallan con tanta facilidad. No deberíamos sorprendernos por la entrada de datos inesperados en el sistema, y esto es lo que los expertos en seguridad han estado haciendo durante bastante tiempo.