
Estos lagos (lagos de datos ) se convierten en realidad en el estándar para las empresas y corporaciones que intentan utilizar toda la información disponible. Los componentes de código abierto suelen ser una opción atractiva al desarrollar grandes lagos de datos. Examinaremos los patrones arquitectónicos generales necesarios para crear un lago de datos para soluciones híbridas o en la nube, y también destacaremos una serie de detalles críticos a tener en cuenta al implementar componentes clave.
Diseño de flujo de datos
Un flujo de lago de datos lógico típico incluye los siguientes bloques funcionales:
- Fuentes de datos;
- Recibiendo información;
- Nodo de almacenamiento;
- Procesamiento y enriquecimiento de datos;
- Análisis de los datos.
En este contexto, las fuentes de datos suelen ser flujos o colecciones de datos de eventos sin procesar (por ejemplo, registros, clics, telemetría de IoT, transacciones).
La característica clave de tales fuentes es que los datos sin procesar se almacenan en su forma original. El ruido en estos datos generalmente consiste en registros duplicados o incompletos con campos redundantes o erróneos.
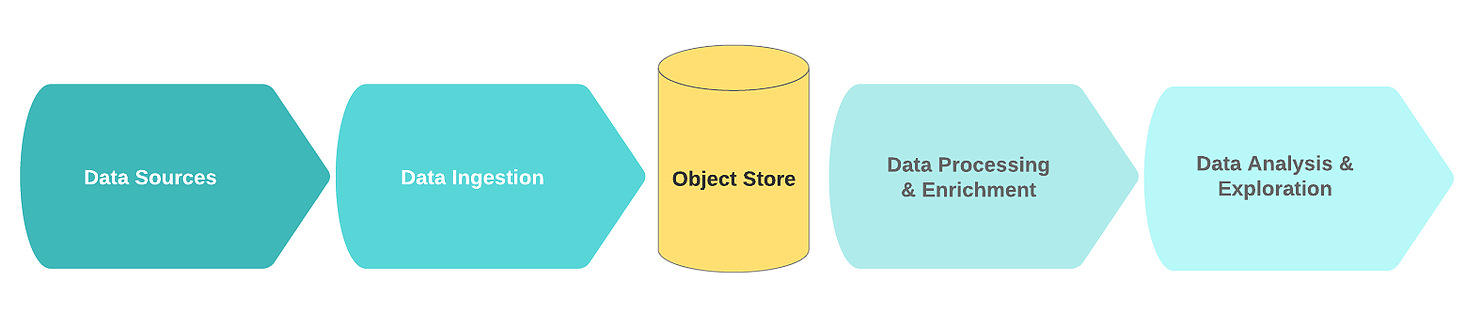
En la etapa de ingestión, los datos sin procesar provienen de una o más fuentes de datos. El mecanismo de recepción se implementa con mayor frecuencia en forma de una o más colas de mensajes con un componente simple destinado a la limpieza primaria y el almacenamiento de datos. Para construir un lago de datos eficiente, escalable y consistente, se recomienda distinguir entre limpieza de datos simple y tareas de enriquecimiento de datos más complejas. Una buena regla general es que las tareas de limpieza requieren datos de una sola fuente dentro de una ventana deslizante.
Texto oculto
( - , ..). , .
, , , 60 , . , (, 24 ), .
, , , 60 , . , (, 24 ), .
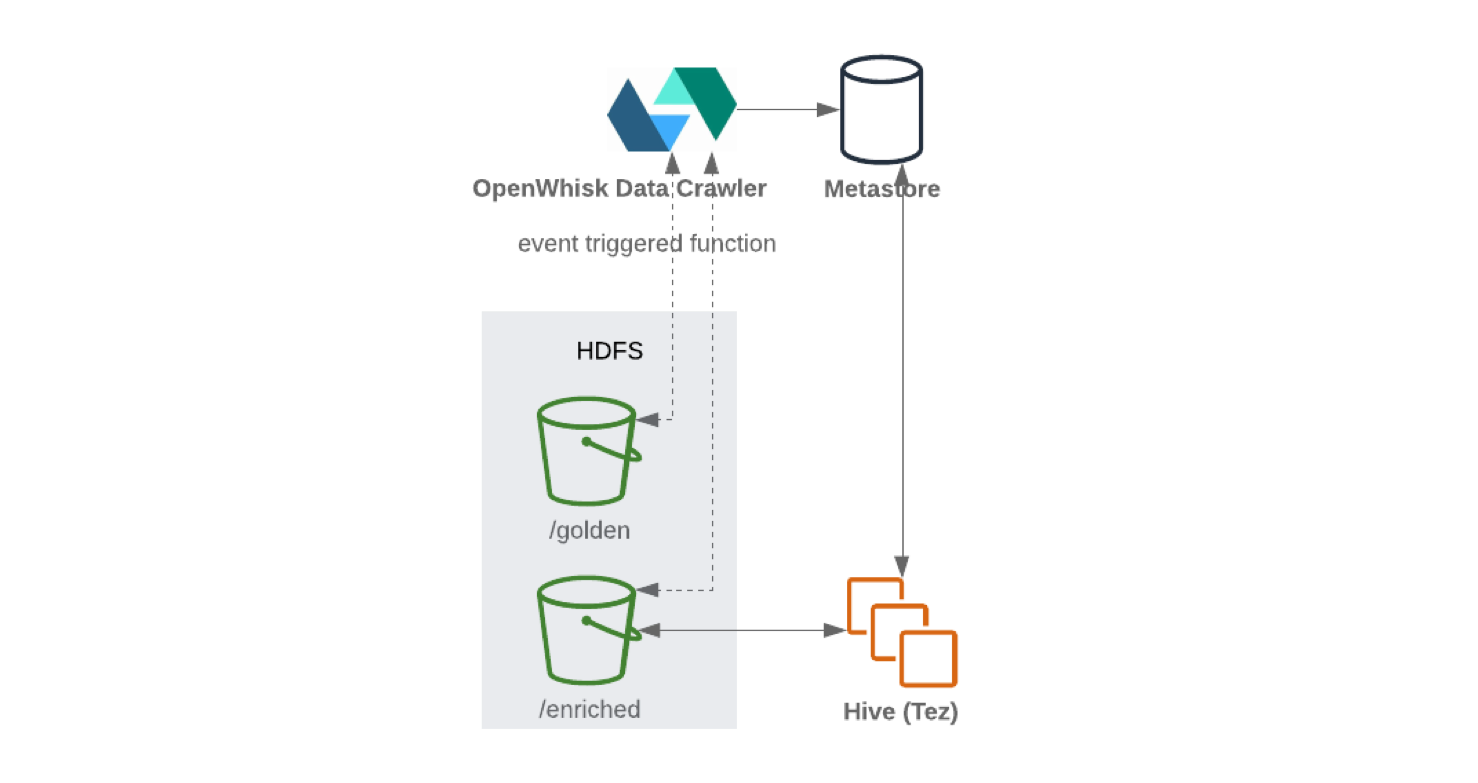
Una vez que los datos se reciben y se limpian, se almacenan en el sistema de archivos distribuido (para mejorar la tolerancia a fallas). Los datos a menudo se escriben en formato tabular. Cuando se escribe nueva información en el nodo de almacenamiento, el catálogo de datos que contiene el esquema y los metadatos se puede actualizar mediante un rastreador sin conexión. El lanzamiento del rastreador generalmente se desencadena por un evento, por ejemplo, cuando llega un nuevo objeto al almacenamiento. Los repositorios suelen estar integrados con sus catálogos. Descargan el esquema subyacente para que se pueda acceder a los datos.
Luego, los datos pasan a un área especial dedicada a los "datos de oro". A partir de este momento, los datos están listos para ser enriquecidos por otros procesos.
Texto oculto
, , .
Durante el proceso de enriquecimiento, los datos se modifican y limpian adicionalmente de acuerdo con la lógica empresarial. Como resultado, se almacenan en un formato estructurado en un almacén de datos o una base de datos que se utiliza para recuperar rápidamente información, análisis o un modelo de entrenamiento.
Finalmente, el uso de datos es análisis e investigación. Aquí es donde la información extraída se transforma en ideas comerciales a través de visualizaciones, cuadros de mando e informes. Además, estos datos son una fuente de pronóstico mediante el aprendizaje automático, cuyo resultado ayuda a tomar mejores decisiones.
Componentes de la plataforma
La infraestructura de nube de lago de datos requiere una capa robusta y, en el caso de sistemas de nube híbrida, una capa de abstracción unificada que pueda ayudar a implementar, coordinar y ejecutar tareas computacionales sin las limitaciones de los proveedores de API.
Kubernetes es una gran herramienta para este trabajo. Le permite implementar, organizar y ejecutar de manera eficiente varios servicios y tareas computacionales de un lago de datos de una manera confiable y rentable. Ofrece una API unificada que funcionará tanto en las instalaciones como en cualquier nube pública o privada.
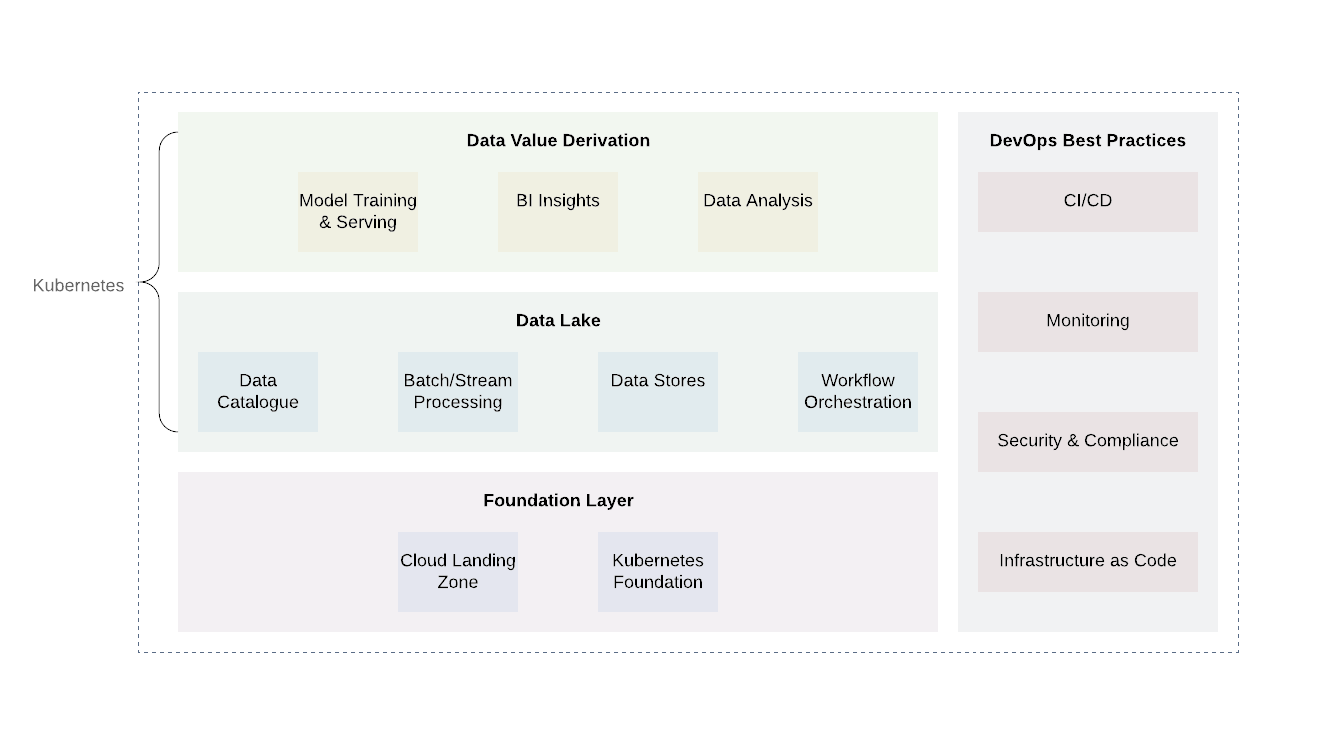
La plataforma se puede dividir aproximadamente en varias capas. La capa base es donde implementamos Kubernetes o su equivalente. La capa base también se puede utilizar para manejar tareas computacionales fuera del dominio del lago de datos. Al utilizar proveedores en la nube, sería prometedor utilizar las prácticas ya establecidas de los proveedores en la nube (registro y auditoría, diseño de acceso mínimo, escaneo e informes de vulnerabilidades, arquitectura de red, arquitectura IAM, etc.). Esto logrará el nivel requerido de seguridad y el cumplimiento de otros requisitos. ...
Hay dos niveles adicionales por encima del nivel base: el lago de datos en sí y el nivel de salida de valor. Estas dos capas son responsables del núcleo de la lógica empresarial, así como del procesamiento de datos. Si bien hay muchas tecnologías para estos dos niveles, Kubernetes volverá a demostrar ser una buena opción debido a su flexibilidad para admitir una variedad de tareas informáticas.
La capa de lago de datos incluye todos los servicios necesarios para recibir ( Kafka , Kafka Connect ), filtrar, enriquecer y procesar ( Flink y Spark ), gestión del flujo de trabajo ( Airflow ). Además, incluye almacenamiento de datos y sistemas de archivos distribuidos ( HDFS) así como bases de datos RDBMS y NoSQL .
El nivel superior es obtener valores de datos. Básicamente, este es el nivel de consumo. Incluye componentes como herramientas de visualización para comprender la inteligencia empresarial, herramientas de minería de datos ( Jupyter Notebooks ). Otro proceso importante que tiene lugar en este nivel es el aprendizaje automático utilizando muestras de entrenamiento de un lago de datos.
Es importante tener en cuenta que una parte integral de cada lago de datos es la implementación de prácticas DevOps comunes: infraestructura como código, observabilidad, auditoría y seguridad. Desempeñan un papel importante en la resolución de problemas cotidianos y deben aplicarse en todos los niveles para garantizar la estandarización, la seguridad y la facilidad de uso.
, — , opensource-.
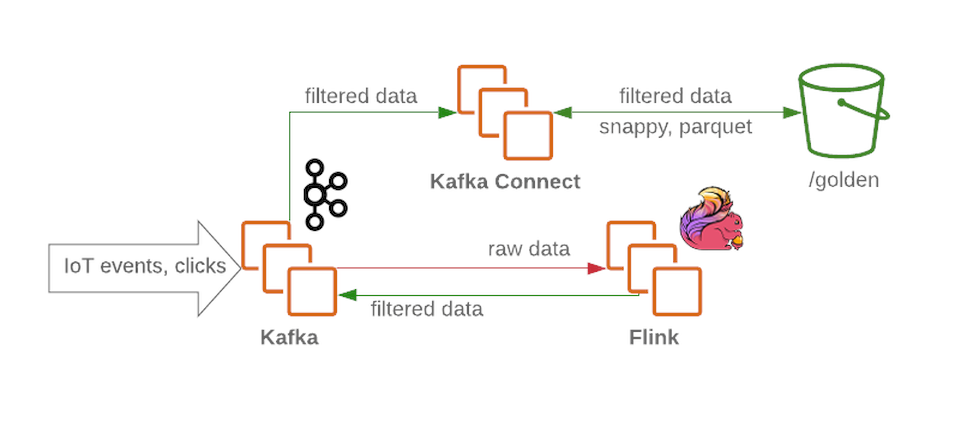
El clúster de Kafka recibirá mensajes sin filtrar ni procesar y funcionará como un nodo de recepción en el lago de datos. Kafka proporciona un alto rendimiento de mensajes de forma fiable. Un clúster generalmente contiene varias secciones para datos sin procesar, procesados (para transmisión) y datos no entregados o con formato incorrecto.
Flink acepta un mensaje de un nodo de datos sin procesar de Kafka , filtra los datos y pre-enriquece los datos si es necesario. Luego, los datos se devuelven a Kafka (en una sección separada para datos filtrados y enriquecidos). En caso de falla, o cuando cambia la lógica empresarial, estos mensajes se pueden llamar nuevamente, porque que se guardan enKafka . Esta es una solución común para los procesos de transmisión. Mientras tanto, Flink escribe todos los mensajes con formato incorrecto en otra sección para su posterior análisis.
Con Kafka Connect, tenemos la capacidad de guardar datos en los backends de almacenamiento de datos necesarios (como la zona dorada en HDFS ). Kafka Connect se escala fácilmente y lo ayudará a aumentar rápidamente la cantidad de procesos simultáneos al aumentar el rendimiento bajo una gran carga de trabajo:
Al escribir desde Kafka Connect a HDFS, se recomienda realizar la división de contenido para un manejo eficiente de los datos (cuantos menos datos escanear, menos solicitudes y respuestas). Una vez que los datos se han escrito en HDFS , la funcionalidad sin servidor (como OpenWhisk o Knative ) actualizará periódicamente el almacenamiento de parámetros de esquema y metadatos. Como resultado, se puede acceder al esquema actualizado a través de una interfaz similar a SQL (por ejemplo, Hive o Presto ).
Apache Airflow se puede utilizar para flujos de datos posteriores y control de procesos ETL . Permite a los usuarios ejecutar piplines de varios pasos utilizando Python y objetos de gráfico acíclico dirigido ( DAG ). El usuario puede definir dependencias, programar procesos complejos y realizar un seguimiento de las tareas a través de una interfaz gráfica. Apache Airflow también puede manejar todos los datos externos. Por ejemplo, para recibir datos a través de una API externa y almacenarlos en almacenamiento persistente. Spark impulsado por Apache Airflow
a través de un complemento especial, puede enriquecer periódicamente los datos sin procesar filtrados de acuerdo con los objetivos comerciales y preparar los datos para la investigación por parte de científicos de datos y analistas comerciales. Los científicos de datos pueden usar JupyterHub para administrar varios Jupyter Notebooks . Por lo tanto, vale la pena usar Spark para configurar interfaces multiusuario para trabajar con datos, recopilarlos y analizarlos.

Para el aprendizaje automático, puede usar marcos como Kubeflow , aprovechando la escalabilidad de Kubernetes . Los modelos de entrenamiento resultantes se pueden devolver al sistema.
Si armamos el rompecabezas, obtenemos algo como esto:

Excelencia operativa
Hemos dicho que los principios de DevOps y DevSecOps son componentes esenciales de cualquier lago de datos y nunca deben pasarse por alto. Con mucho poder viene mucha responsabilidad, especialmente cuando todos los datos estructurados y no estructurados sobre su negocio están en un solo lugar.
Los principios básicos serán los siguientes:
- Restringir el acceso de los usuarios;
- Vigilancia;
- Cifrado de datos;
- Soluciones sin servidor;
- Utilizando procesos CI / CD.
Los principios de DevOps y DevSecOps son componentes esenciales de cualquier lago de datos y nunca deben pasarse por alto. Con mucho poder viene mucha responsabilidad, especialmente cuando todos los datos estructurados y no estructurados sobre su negocio están en un solo lugar.
Uno de los métodos recomendados es permitir el acceso solo a ciertos servicios mediante la distribución de los derechos adecuados y negar el acceso directo de los usuarios para que los usuarios no puedan cambiar los datos (esto también se aplica a los comandos). El monitoreo completo mediante acciones de registro también es importante para proteger los datos.
El cifrado de datos es otro mecanismo para proteger los datos. Los datos almacenados se pueden cifrar mediante un sistema de gestión de claves ( KMS). Esto cifrará su sistema de almacenamiento y su estado actual. A su vez, el cifrado de transmisión se puede realizar mediante certificados para todas las interfaces y puntos finales de servicios como Kafka y ElasticSearch .
Y en el caso de los motores de búsqueda que pueden no cumplir con la política de seguridad, es mejor dar preferencia a las soluciones sin servidor . También es necesario abandonar las implementaciones manuales, los cambios de situación en cualquier componente del lago de datos; cada cambio debe provenir del control de fuente y pasar una serie de pruebas de CI antes de implementarse en el lago de datos del producto ( prueba de humo , regresión, etc.).
Epílogo
Hemos cubierto los principios básicos de diseño de una arquitectura de lago de datos de código abierto. Como suele suceder, la elección del enfoque no siempre es obvia y puede depender de diferentes requisitos comerciales, presupuestarios y de tiempo. Pero aprovechar la tecnología en la nube para crear lagos de datos, ya sea una solución híbrida o totalmente en la nube, es una tendencia emergente en la industria. Esto se debe a la gran cantidad de beneficios que ofrece este enfoque. Tiene un alto nivel de flexibilidad y no restringe el desarrollo. Es importante comprender que un modelo de trabajo flexible trae importantes beneficios económicos, lo que le permite combinar, escalar y mejorar los procesos aplicados.