Actualmente trabajo en ManyChat. De hecho, esta es una startup: nueva, ambiciosa y de rápido crecimiento. Y cuando me incorporé por primera vez a la empresa, surgió la pregunta clásica: "¿Qué debería tomar ahora una startup joven del mercado de DBMS y bases de datos?"
En este artículo, basado en mi charla en el festival en línea RIT ++ 2020 , responderé esta pregunta. Una versión en video del informe está disponible en YouTube .
Bases de datos conocidas de 2020
Es 2020, miré a mi alrededor y vi tres tipos de bases de datos.
El primer tipo son las bases de datos OLTP clásicas : PostgreSQL, SQL Server, Oracle, MySQL. Fueron escritos hace mucho tiempo, pero siguen siendo relevantes porque son familiares para la comunidad de desarrolladores.
El segundo tipo - bases de "cero" . Intentaron alejarse de los patrones clásicos alejándose de SQL, estructuras tradicionales y ACID, agregando fragmentación en línea y otras características atractivas. Por ejemplo, estos son Cassandra, MongoDB, Redis o Tarantool. Todas estas soluciones querían ofrecer al mercado algo fundamentalmente nuevo y ocupaban su nicho, pues en determinadas tareas resultaban sumamente convenientes. Estas bases se denotarán con el término general NOSQL.
Los "cero" terminaron, se acostumbraron a las bases de datos NOSQL y el mundo, desde mi punto de vista, ha dado el siguiente paso: las bases de datos administradas . Estas bases de datos tienen el mismo núcleo que las bases de datos OLTP clásicas o las nuevas bases de datos NoSQL. Pero no necesitan DBA ni DevOps y se ejecutan en hardware administrado en las nubes. Para un desarrollador, esto es “solo una base” que funciona en algún lugar, pero a nadie le importa cómo se instala en el servidor, quién configuró el servidor y quién lo actualiza.
Ejemplos de tales bases:
- AWS RDS es un contenedor administrado sobre PostgreSQL / MySQL.
- DynamoDB es un análogo de AWS de una base de datos basada en documentos, similar a Redis y MongoDB.
- Amazon Redshift es una base de análisis administrada.
En esencia, se trata de bases antiguas, pero planteadas en un entorno gestionado, sin necesidad de trabajar con hardware.
Nota. Los ejemplos se toman para el entorno de AWS, pero sus contrapartes también existen en Microsoft Azure, Google Cloud o Yandex.Cloud.

¿Entonces que hay de nuevo? En 2020, nada de esto.
Concepto sin servidor
Lo que es realmente nuevo en el mercado en 2020 son las soluciones sin servidor o sin servidor.
Intentaré explicar lo que esto significa usando el ejemplo de un servicio regular o una aplicación de backend.
Para implementar una aplicación de backend normal, compramos o alquilamos un servidor, copiamos el código en él, publicamos el punto final en el exterior y pagamos regularmente el alquiler, la electricidad y los servicios del centro de datos. Este es el diseño estándar.
¿Hay alguna otra manera? Con los servicios sin servidor, puede hacerlo.
Cuál es el enfoque de este enfoque: no hay servidor, ni siquiera hay un arrendamiento de instancia virtual en la nube. Para implementar el servicio, copie el código (funciones) en el repositorio y publique el punto final fuera. Luego solo pagamos por cada llamada de esta función, ignorando por completo el hardware donde se ejecuta.
Intentaré ilustrar este enfoque en imágenes.
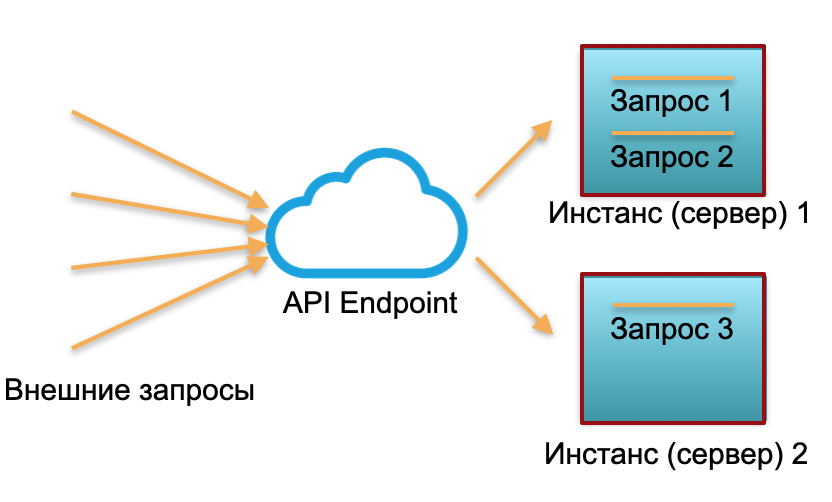
Despliegue clásico . Disponemos de un servicio con cierta carga. Planteamos dos instancias: servidores físicos o instancias en AWS. Las solicitudes externas se envían a estas instancias y se procesan allí.
Como puede ver en la imagen, los servidores se utilizan de manera diferente. Una se utiliza al 100%, hay dos solicitudes y una solo está parcialmente inactiva en un 50%. Si no llegan tres solicitudes, sino 30, todo el sistema no podrá hacer frente a la carga y comenzará a ralentizarse.

Implementación sin servidor... En un entorno sin servidor, dicho servicio no tiene instancias ni servidores. Hay un grupo de recursos calentados: pequeños contenedores Docker preparados con código de función implementado. El sistema recibe solicitudes externas y para cada una de ellas el framework sin servidor genera un pequeño contenedor con código: procesa esta solicitud en particular y mata el contenedor.
Una solicitud - un contenedor elevado, 1000 solicitudes - 1000 contenedores. Y la implementación en servidores de hierro ya es trabajo de un proveedor en la nube. Está completamente oculto por el marco sin servidor. En este concepto, pagamos por cada llamada. Por ejemplo, recibimos una llamada al día: pagamos una llamada, un millón en un minuto, pagamos un millón. O en un segundo, esto también sucede.
El concepto de publicar una función sin servidor es apropiado para un servicio sin estado. Y si necesita un servicio completo (estatal), agregue una base de datos al servicio. En este caso, cuando se trata de trabajar con estado, con estado, cada función con estado completo simplemente escribe y lee desde la base de datos. Además, a partir de una base de datos de cualquiera de los tres tipos descritos al principio del artículo.
¿Cuál es la limitación común de todas estas bases? Estos son los costos de un servidor de hierro o en la nube que se utiliza constantemente (o varios servidores). No importa si usamos una base de datos clásica o administrada, si tenemos Devops y un administrador o no, todavía pagamos las 24 horas del día, los 7 días de la semana por el alquiler del hardware, la electricidad y el centro de datos. Si tenemos una base clásica, pagamos maestro y esclavo. Si es una base fragmentada muy cargada, pagamos por 10, 20 o 30 servidores, y pagamos constantemente.
La presencia de servidores reservados permanentemente en la estructura de costos se percibía anteriormente como un mal necesario. Las bases de datos ordinarias también tienen otras dificultades, como límites en el número de conexiones, límites de escala, consenso distribuido geográficamente; de alguna manera pueden resolverse en ciertas bases de datos, pero no todas a la vez y no son ideales.
Base de datos sin servidor - teoría
Pregunta de 2020: ¿la base de datos también se puede convertir en sin servidor? Todo el mundo ha oído hablar del backend sin servidor ... pero, ¿vamos a intentar que la base de datos también sea sin servidor?
Esto suena extraño porque una base de datos es un servicio con estado, no muy adecuado para una infraestructura sin servidor. Al mismo tiempo, el estado de la base de datos es muy grande: gigabytes, terabytes e incluso petabytes en bases de datos analíticas. No es tan fácil levantarlo en contenedores Docker ligeros.
Por otro lado, casi todas las bases de datos modernas son una gran cantidad de lógica y componentes: transacciones, negociación de integridad, procedimientos, dependencias relacionales y mucha lógica. Gran parte de la lógica de la base de datos es un estado bastante pequeño. Los gigabytes y terabytes son utilizados directamente por solo una pequeña parte de la lógica de la base de datos asociada con la ejecución directa de consultas.
En consecuencia, la idea: si parte de la lógica permite la ejecución sin estado, ¿por qué no dividir la base en partes con estado y sin estado?
Sin servidor para soluciones OLAP
Veamos cómo se vería una base de datos dividida en partes con estado y sin estado con ejemplos prácticos.
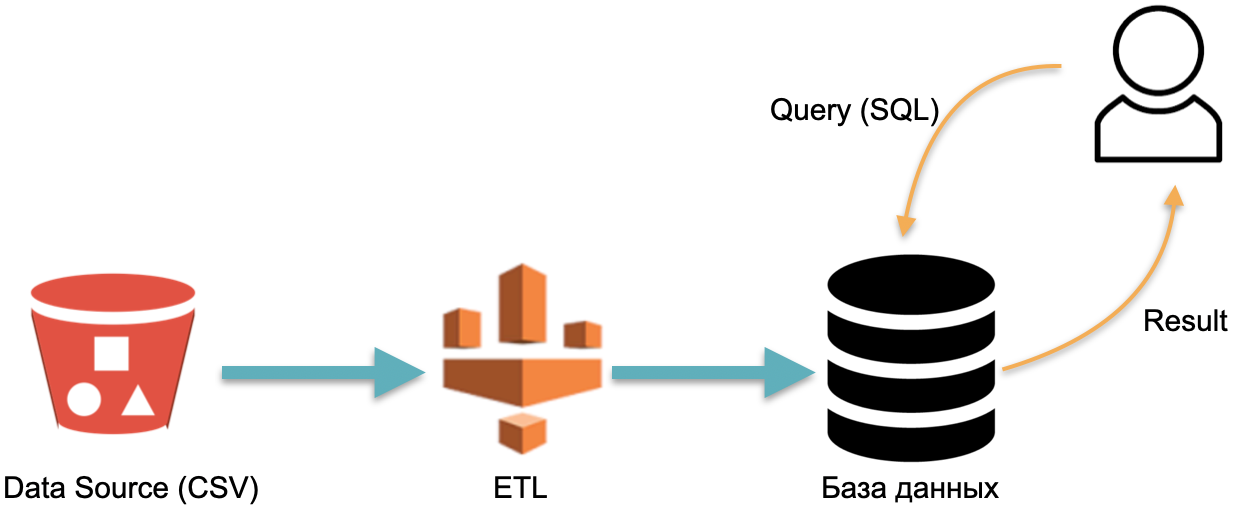
Por ejemplo, tenemos una base de datos analítica : datos externos (cilindro rojo a la izquierda), un proceso ETL que carga datos en la base de datos y un analista que envía consultas SQL a la base de datos. Esta es la forma clásica en que funciona un almacén de datos.
En este esquema, por convención, ETL se ejecuta una vez. Luego, debe pagar todo el tiempo por los servidores que ejecutan la base de datos con datos inundados con ETL, para que tenga algo para enviar solicitudes.
Considere un enfoque alternativo implementado en AWS Athena Serverless. No existe un hardware dedicado permanentemente en el que se almacenan los datos descargados. En lugar de esto:
- SQL- Athena. Athena SQL- (Metadata) , .
- , , ( ).
- SQL- , .
- , .
En esta arquitectura, solo pagamos por el proceso de ejecución de la solicitud. Sin solicitudes, sin costos.
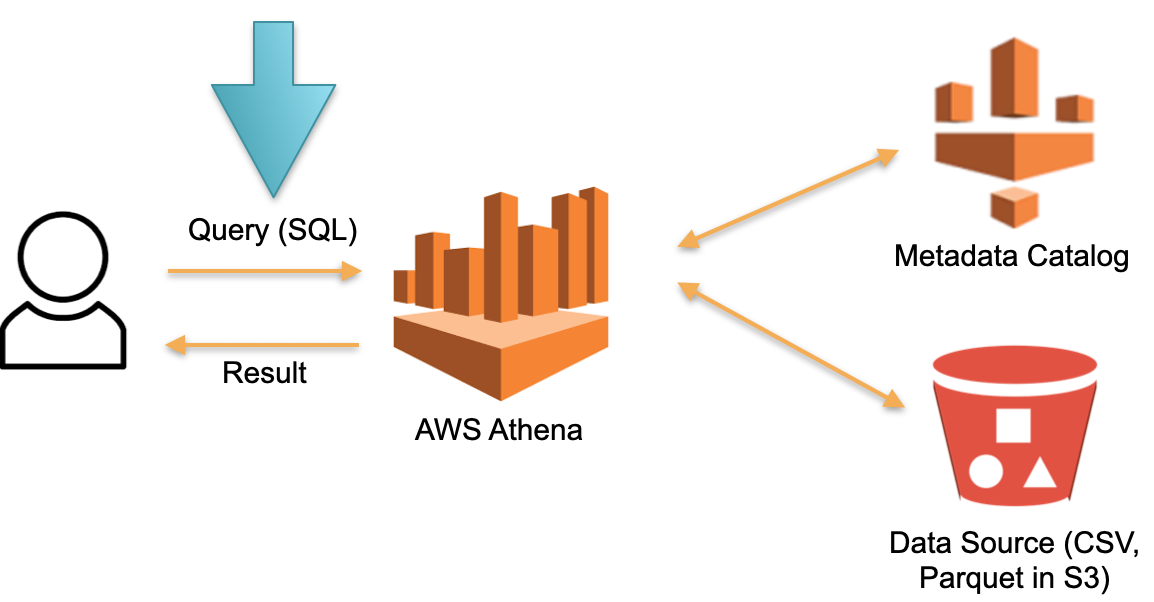
Este es un enfoque funcional y se implementa no solo en Athena Serverless, sino también en Redshift Spectrum (en AWS).
El ejemplo de Athena muestra que la base de datos sin servidor funciona en consultas reales con decenas y cientos de Terabytes de datos. Cientos de Terabytes requerirán cientos de servidores, pero no tenemos que pagarlos, pagamos las solicitudes. La velocidad de cada solicitud es (muy) lenta en comparación con las bases de datos analíticas especializadas como Vertica, pero no pagamos por el tiempo de inactividad.
Esta base de datos es útil para consultas analíticas ad-hoc poco frecuentes. Por ejemplo, cuando espontáneamente decidimos probar una hipótesis con una cantidad gigantesca de datos. Athena es perfecta para estos casos. Para consultas regulares, este sistema es caro. En este caso, almacene los datos en caché en alguna solución especializada.
Sin servidor para soluciones OLTP
En el ejemplo anterior, se consideraron las tareas OLAP (analíticas). Ahora veamos las tareas de OLTP.
Imagínese PostgreSQL o MySQL escalable. Creemos una instancia administrada regular PostgreSQL o MySQL con recursos mínimos. Cuando llegue más carga a la instancia, conectaremos réplicas adicionales a las que distribuiremos parte de la carga de lectura. Si no hay solicitudes ni carga, apagamos las réplicas. La primera instancia es la maestra y el resto son réplicas.
Esta idea se implementa en una base de datos llamada Aurora Serverless AWS. El principio es simple: las solicitudes de aplicaciones externas son aceptadas por la flota de proxy. Al ver un aumento en la carga, asigna recursos informáticos de instancias mínimas precalentadas: la conexión es lo más rápida posible. Desconectar instancias es lo mismo.
Dentro de Aurora, existe el concepto de unidad de capacidad Aurora, ACU. Esta es (condicionalmente) una instancia (servidor). Cada ACU específico puede ser maestro o esclavo. Cada unidad de capacidad tiene su propia RAM, procesador y disco mínimo. En consecuencia, un maestro, el resto son réplicas de solo lectura.
El número de estas unidades de capacidad Aurora en funcionamiento es configurable. La cantidad mínima puede ser uno o cero (en este caso, la base no funciona si no hay solicitudes).

Cuando la base recibe solicitudes, la flota de proxy aumenta Aurora CapacityUnits, aumentando los recursos productivos del sistema. La capacidad de aumentar y disminuir los recursos permite al sistema hacer "malabarismos" con los recursos: muestra automáticamente las ACU individuales (reemplazándolas por otras nuevas) e implementa todas las actualizaciones relevantes para los recursos eliminados.
La base de Aurora Serverless puede escalar la carga de lectura. Pero la documentación no lo dice directamente. Puede parecer que pueden elegir un multimaestro. No hay magia.
Esta base es adecuada para no gastar mucho dinero en sistemas con acceso impredecible. Por ejemplo, al crear sitios de marketing de tarjetas de presentación o MVP, generalmente no esperamos una carga constante. En consecuencia, en ausencia de acceso, no pagamos por instancias. Cuando surge una carga inesperadamente, por ejemplo, después de una conferencia o una campaña publicitaria, una multitud de personas visita el sitio y la carga aumenta drásticamente, Aurora Serverless se hace cargo automáticamente de esta carga y conecta rápidamente los recursos faltantes (ACU). Luego continúa la conferencia, todos se olvidan del prototipo, los servidores (ACU) se apagan y los costos bajan a cero, es conveniente.
Esta solución no es adecuada para altas cargas estables porque no puede escalar la carga de escritura. Todas estas conexiones y desconexiones de recursos ocurren en el momento del llamado "punto de escala", el momento en que la transacción no mantiene la base de datos, las tablas temporales no se mantienen. Por ejemplo, durante una semana, es posible que el punto de escala no se produzca y la base funcione con los mismos recursos y simplemente no se pueda expandir ni reducir.
No hay magia, esto es PostgreSQL normal. Pero el proceso de agregar autos y desconectar está parcialmente automatizado.
Sin servidor por diseño
Aurora Serverless es una base antigua reescrita para la nube a fin de aprovechar los beneficios individuales de Serverless. Y ahora les contaré sobre la base, que se escribió originalmente para la nube, para el enfoque sin servidor: sin servidor por diseño. Se desarrolló inmediatamente sin asumir que se ejecuta en servidores físicos.
Esta base se llama Snowflake. Tiene tres bloques clave.
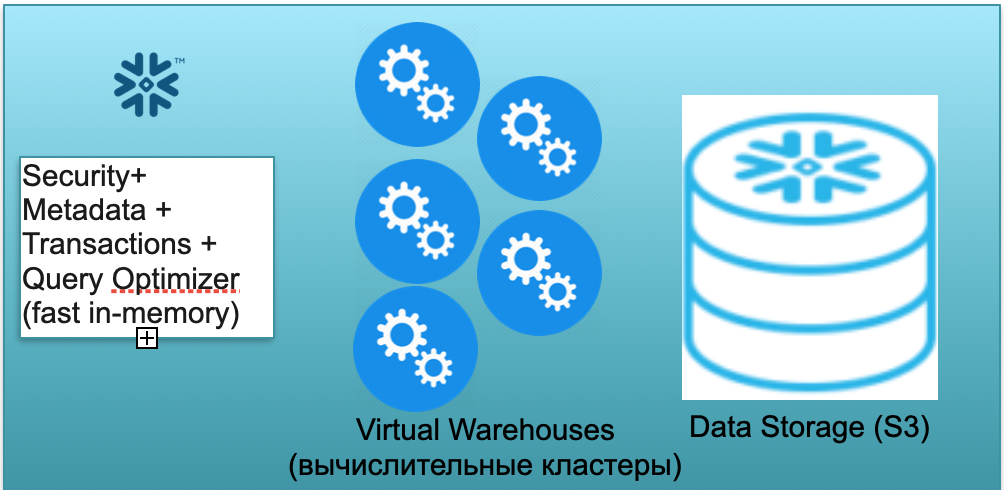
El primero es un bloque de metadatos. Es un servicio rápido en memoria que resuelve problemas de seguridad, metadatos, transacciones, optimización de consultas (en la ilustración de la izquierda).
El segundo bloque es un conjunto de clústeres computacionales virtuales para cálculos (en la ilustración, un conjunto de círculos azules).
El tercer bloque es un sistema de almacenamiento basado en S3. S3 es el almacenamiento de objetos adimensionales de AWS, similar al Dropbox adimensional para empresas.
Echemos un vistazo a cómo funciona Snowflake bajo el supuesto de arranque en frío. Es decir, la base de datos está ahí, los datos se cargan en ella, no hay consultas de trabajo. En consecuencia, si no hay consultas a la base de datos, entonces hemos generado un servicio rápido de metadatos en memoria (primer bloque). Y tenemos el almacenamiento S3, donde se almacenan los datos de la tabla, divididos en las llamadas microparticiones. Para simplificar: si la tabla contiene ofertas, los micro lotes son los días de las ofertas. Cada día es un micro-lote separado, un archivo separado. Y cuando la base de datos funciona en este modo, solo paga por el espacio ocupado por los datos. Además, la tasa por asiento es muy baja (especialmente dada la significativa compresión). El servicio de metadatos también funciona constantemente, pero no se necesitan muchos recursos para optimizar las consultas y el servicio puede considerarse shareware.
Ahora imaginemos que un usuario llegó a nuestra base de datos y lanzó una consulta SQL. La consulta SQL se envía inmediatamente al servicio de metadatos para su procesamiento. En consecuencia, al recibir una solicitud, este servicio analiza la solicitud, los datos disponibles, la autoridad del usuario y, si todo va bien, elabora un plan de procesamiento de la solicitud.
A continuación, el servicio inicia el lanzamiento del clúster computacional. Un clúster de cómputo es un clúster de servidores que realizan cálculos. Es decir, este es un clúster que puede contener 1 servidor, 2 norte, 4, 8, 16, 32, tantos como desee. Lanzas una solicitud y el lanzamiento de este clúster comienza instantáneamente debajo de él. Realmente lleva unos segundos.
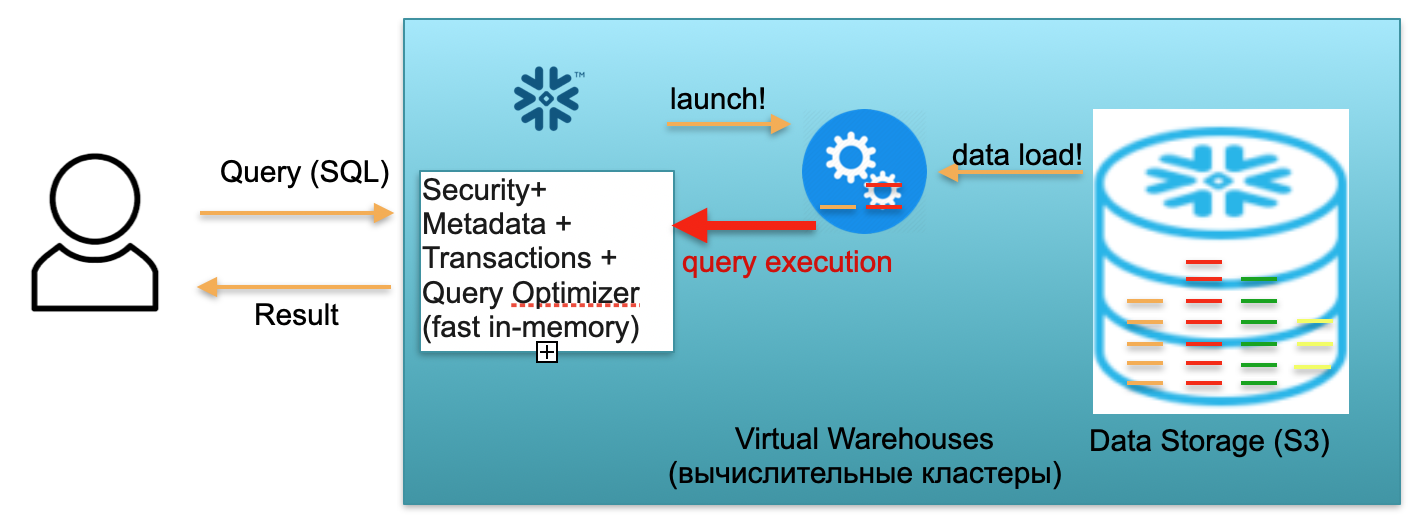
Además, una vez iniciado el clúster, las microparticiones se copian de S3 al clúster, que son necesarias para procesar su solicitud. Es decir, imagine que para ejecutar una consulta SQL, necesita dos particiones de una tabla y una de la segunda. En este caso, solo las tres particiones necesarias se copiarán en el clúster, y no todas las tablas en su totalidad. Por eso, y precisamente porque todo está dentro del marco de un centro de datos y está conectado por canales muy rápidos, todo el proceso de bombeo se lleva a cabo muy rápidamente: en segundos, muy raramente, en minutos, si no estamos hablando de algunas solicitudes monstruosas. ... En consecuencia, las microparticiones se copian en un grupo computacional y, una vez finalizado, se ejecuta una consulta SQL en este grupo computacional. El resultado de esta consulta puede ser una línea, varias líneas o una tabla; se envían al usuario,para que pueda descargarse, mostrarse en su herramienta de BI o utilizarse de alguna otra forma.
Cada consulta SQL no solo puede leer agregados de datos cargados previamente, sino también cargar / formar nuevos datos en la base de datos. Es decir, puede ser una consulta que, por ejemplo, inserta nuevos registros en otra tabla, lo que lleva a la aparición de una nueva partición en el clúster computacional, que, a su vez, se almacena automáticamente en un único almacenamiento S3.
El escenario descrito anteriormente, desde la llegada de un usuario hasta levantar el cluster, cargar datos, ejecutar consultas, obtener resultados, se paga a la tarifa por minuto de uso del cluster de computación virtual levantado, almacén virtual. La tasa varía según la zona de AWS y el tamaño del clúster, pero en promedio es de unos pocos dólares por hora. Un grupo de cuatro automóviles es dos veces más caro que un grupo de dos automóviles, y de ocho automóviles es dos veces más caro. Opciones disponibles desde 16, 32 coches, según la complejidad de las solicitudes. Pero solo paga por los minutos en los que el clúster realmente funciona, porque cuando no hay solicitudes, se quita las manos y después de 5-10 minutos de espera (un parámetro configurable) se apagará por sí solo, liberará recursos y se volverá libre.
El escenario es bastante real cuando lanza una solicitud, el clúster aparece, relativamente hablando, en un minuto, cuenta otro minuto, luego cinco minutos para apagarse, y paga como resultado por siete minutos de operación de este clúster, y no por meses y años.
El primer escenario describió el uso de Snowflake en un escenario de un solo usuario. Ahora imaginemos que hay muchos usuarios, lo que se acerca más a un escenario real.
Supongamos que tenemos muchos analistas e informes de Tableau que bombardean constantemente nuestra base de datos con muchas consultas SQL analíticas simples.
Además, digamos que tenemos científicos de datos ingeniosos que intentan hacer cosas monstruosas con datos, operar en decenas de terabytes, analizar miles de millones y billones de filas de datos.
Para los dos tipos de carga descritos anteriormente, Snowflake le permite levantar varios clústeres de cómputo independientes de diferentes capacidades. Además, estos clusters computacionales operan de forma independiente, pero con datos consistentes comunes.
Para una gran cantidad de consultas ligeras, puede generar 2-3 grupos pequeños, de tamaño convencional, 2 máquinas cada uno. Este comportamiento es realizable, entre otras cosas, mediante ajustes automáticos. Es decir, dices: “Copo de nieve, levanta un pequeño racimo. Si la carga sobre él crece más de un cierto parámetro, levante un segundo, tercero similar. Cuando la carga comience a disminuir, extinga las que sobran ". De modo que no importa cuántos analistas vengan y comiencen a mirar informes, todos tengan suficientes recursos.
Al mismo tiempo, si los analistas están dormidos y nadie está mirando los informes, los clústeres pueden desaparecer por completo y dejar de pagar por ellos.
Al mismo tiempo, para consultas pesadas (de científicos de datos), puede generar un clúster muy grande por 32 máquinas condicionales. Este clúster también se facturará solo por los minutos y horas en que su solicitud gigante se esté ejecutando allí.
La característica descrita anteriormente permite dividir en clusters no solo 2, sino también más tipos de carga (ETL, monitoreo, materialización de informes, ...).
Resumamos el copo de nieve. La base combina una hermosa idea y una implementación viable. En ManyChat, utilizamos Snowflake para analizar todos los datos que tenemos. No tenemos tres conglomerados, como en el ejemplo, sino de 5 a 9, de diferentes tamaños. Tenemos 16 máquinas condicionales, 2 máquinas, también hay 1 máquinas súper pequeñas para algunas tareas. Distribuyen con éxito la carga y nos permiten ahorrar mucho.
La base escala con éxito la carga de trabajo de lectura y escritura. Esta es una gran diferencia y un gran avance en comparación con el mismo "Aurora", que solo extrajo la carga de lectura. Snowflake permite que estos clústeres informáticos escalen y escriban cargas de trabajo. Es decir, como mencioné, usamos varios clústeres en ManyChat, los clústeres pequeños y superpequeños se usan principalmente para ETL, para cargar datos. Y los analistas ya viven en clústeres de tamaño mediano que no se ven afectados en absoluto por la carga ETL, por lo que funcionan muy rápidamente.
En consecuencia, la base es adecuada para tareas OLAP. Al mismo tiempo, lamentablemente, todavía no se aplica a las cargas de trabajo OLTP. En primer lugar, esta base es columnar, con todas las consecuencias consiguientes. En segundo lugar, el enfoque en sí mismo, cuando para cada solicitud, si es necesario, genera un clúster computacional y lo llena de datos, desafortunadamente, para las cargas de trabajo OLTP no es lo suficientemente rápido. Esperar segundos para las tareas OLAP es normal, pero para las tareas OLTP es inaceptable, 100 ms sería mejor, e incluso mejor: 10 ms.
Salir
La base de datos sin servidor es posible separando la base de datos en partes sin estado y con estado. Debe haber notado que en todos los ejemplos dados, la parte Stateful es, en términos relativos, almacenar microparticiones en S3, y Stateless es un optimizador, que trabaja con metadatos y maneja problemas de seguridad que pueden plantearse como ligeros independientes. Servicios apátridas.
La ejecución de consultas SQL también se puede considerar como servicios de estado ligero que pueden aparecer en modo sin servidor, como clústeres de cómputo Snowflake, descargar solo los datos que necesita, ejecutar la consulta y "salir".
Las bases de datos de nivel de producción sin servidor ya están disponibles para su uso, están funcionando. Estas bases de datos sin servidor ya están listas para manejar tareas OLAP. Desafortunadamente, se utilizan para tareas OLTP ... con matices, ya que existen limitaciones. Por un lado, esto es un inconveniente. Pero, por otro lado, esta es una oportunidad. Quizás algunos de los lectores encontrarán una manera de hacer que la base OLTP sea completamente sin servidor, sin las limitaciones de Aurora.
Espero que te haya resultado interesante. Sin servidor es el futuro :)