
Llevar un diario es una de esas cosas que solo se recuerda cuando se rompe. Y esto no es una crítica en absoluto. El caso es que los troncos no generan dinero como tales. Proporcionan información sobre lo que los programas están (o han estado haciendo), lo que ayuda a mantener en funcionamiento las cosas que nos hacen ganar dinero. A pequeña escala (o durante el desarrollo), la información necesaria se puede obtener simplemente mostrando mensajes en
stdout... Pero tan pronto como se pasa a un sistema distribuido, e inmediatamente hay una necesidad de agregar estos mensajes y enviarlos a algún repositorio central, donde traerán el mayor beneficio. Esta necesidad es aún más relevante si se trata de contenedores en una plataforma como Kubernetes, donde los procesos y el almacenamiento local son efímeros.
Un enfoque familiar para procesar registros
Desde los primeros días de los contenedores y la publicación del manifiesto de los Doce Factores , se ha formado un cierto patrón general en el procesamiento de los registros generados por los contenedores:
- procesa mensajes de salida hacia
stdoutostderr, -
containerd(Docker) redirige las transmisiones estándar a archivos fuera de los contenedores, - y la cola del reenviador de registros lee esos archivos (es decir, obtiene las últimas líneas de ellos) y envía los datos a la base de datos.
El popular reenviador de registros fluentd es un proyecto de CNCF (como containerd). Con el tiempo, se convirtió en el estándar de facto para leer, transformar, transferir e indexar registros. Cuando creas un clúster de Kubernetes en GKE con Cloud Logging (anteriormente Stackdriver) conectado, obtendrás casi el mismo patrón, solo que con el sabor fluido de Google.
Fue este patrón el que surgió cuando Olark (la empresa para la que trabaja el autor del artículo, aprox. Transl.)comenzó a migrar servicios a K8 como GKE hace cuatro años. Y cuando superamos el registro como servicio, se siguió este patrón, creando nuestro propio sistema de agregación de registros capaz de procesar de 15 a 20 mil líneas por segundo en la carga máxima.
Hay razones por las que este enfoque funciona bien y por qué los principios de 12 factores recomiendan directamente la salida de registros a flujos estándar . El hecho es que permite que la aplicación no se preocupe por el enrutamiento de logs y hace que los contenedores sean fácilmente "observables" (estamos hablando de observabilidad) durante el desarrollo o en producción. Y si su sistema de registro se estropea, al menos existe la posibilidad de que los registros permanezcan en los discos host del nodo del clúster.
La desventaja de este enfoque es que los registros finales son relativamente costosos en términos de uso de CPU . Comenzamos a prestar atención a esto después, durante la siguiente optimización del sistema de registro, resultó que fluentd consume 1/8 de la cuota total de solicitudes de CPU en producción:
- Esto se debe en parte a la topología del clúster: fluentd está alojado en cada nodo para rastrear archivos locales (como DaemonSet , en el lenguaje K8s), tiene nodos de cuatro núcleos y tiene que reservar el 50% del núcleo para procesar registros, y ... bueno, ya se hace una idea.
- Otra parte de los recursos se destina al procesamiento de textos, que también asignamos a fluentd. De hecho, ¿quién dejaría pasar la oportunidad de limpiar las entradas de registro ofuscadas?
- El resto va a inotifywait , que supervisa los archivos en el disco, procesa las lecturas y realiza un seguimiento de los archivos.
Queríamos saber cuánto cuesta todo: hay otras formas de enviar registros a fluentd. Por ejemplo, se puede utilizar con visión de puerto (se trata de la utilización del tipo de
forwarden source-.. Ca. Perevi). Será más barato?
Experimento practico
Para aislar el costo de buscar líneas de troncos usando relaves, armé un pequeño banco de pruebas . Incluye los siguientes componentes:
- Programa Python para crear un cierto número de escritores de registros con frecuencia y tamaño de mensajes configurables;
- archivo para docker compose en ejecución:
- fluentd para procesar registros,
- Asesor para monitorear el contenedor fluentd,
- Prometheus para recopilar métricas de cAdvisor,
- Grafana para visualización de datos en Prometheus.
Notas sobre este diagrama:
- Los escritores de registros generan mensajes en un formato JSON uniforme (que también usa containerd) y pueden escribirlos en archivos o reenviarlos al puerto de reenvío de fluentd.
- Al escribir en archivos, se usa una clase
RotatingFileHandlerpara simular mejor las condiciones del clúster. - Fluentd está configurado para "lanzar" todos los registros
nully no procesar expresiones regulares o verificar registros en busca de etiquetas. Por lo tanto, su trabajo principal será obtener las líneas de registro. - , Prometheus cAdvisor, fluentd.
La selección de parámetros para la comparación se llevó a cabo de forma bastante subjetiva. Escribí otra utilidad para estimar el volumen de registros que generan los nodos de nuestro clúster. No es sorprendente que varíe ampliamente: desde varias decenas de líneas por segundo hasta 500 o más en los nodos más ocupados.
Esta es otra fuente de problemas: si usa un DaemonSet, entonces fluentd debe configurarse para manejar los nodos más ocupados del clúster. En principio, el desequilibrio se puede evitar asignando etiquetas apropiadas a los principales generadores de registros y utilizando reglas suaves de antiafinidad para distribuirlos de manera uniforme, pero esto está más allá del alcance de este artículo. Inicialmente, planeé comparar diferentes mecanismos de "entrega" de registros.a una carga de 500/1000 líneas por segundo utilizando de 1 a 10 escritores de registros.
Resultados de la prueba
Las primeras pruebas mostraron que las líneas por segundo eran el principal contribuyente a la utilización de la CPU en las colas , independientemente de la cantidad de archivos de registro que observamos. Los dos gráficos a continuación comparan la carga a 1000 p / s de un escritor de registro y de 10. Se puede ver que son casi lo mismo:
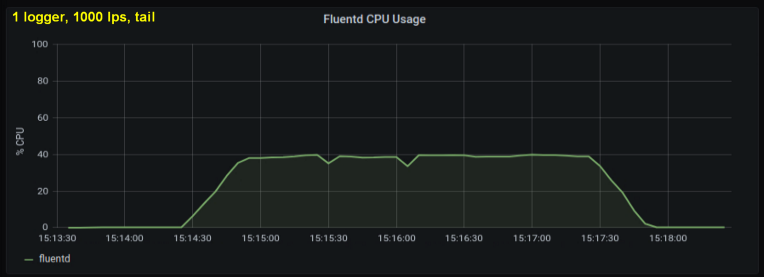
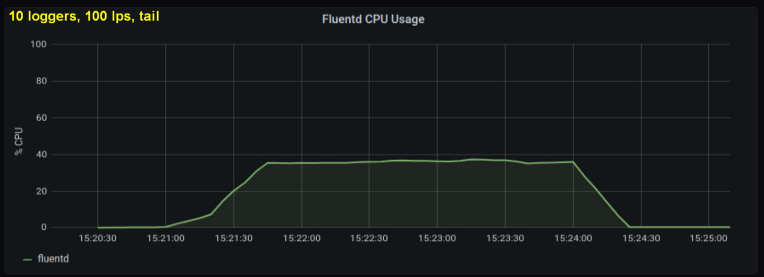
Una pequeña digresión: no incluí el gráfico correspondiente aquí, pero en mi máquina resultó que diez procesos de registro escribir 100 líneas por segundo tiene un rendimiento agregado más alto que un solo proceso que escribe 1000 líneas por segundo. Esto puede deberse a los detalles de mi código; no profundicé deliberadamente en este problema.
En cualquier caso, esperaba que la cantidad de archivos de registro abiertos fuera un factor significativo, pero resultó que realmente no afecta los resultados. Otra variable tan insignificante es la longitud de la cuerda. La prueba anterior utilizó una longitud de cadena estándar de 100 caracteres. Hice ejecuciones con líneas diez veces más largas, pero esto no tuvo un efecto notable en la carga del procesador durante la prueba, que en todos los casos fue de 180 segundos.
Teniendo en cuenta lo anterior, decidí probar 2 escritores, ya que un proceso, según me pareció, estaba alcanzando algún límite interno. Por otro lado, tampoco se necesitaron más procesos. Hice pruebas con 500 y 1000 líneas por segundo. El siguiente conjunto de gráficos muestra los resultados tanto para los archivos de cola como para el puerto de reenvío:

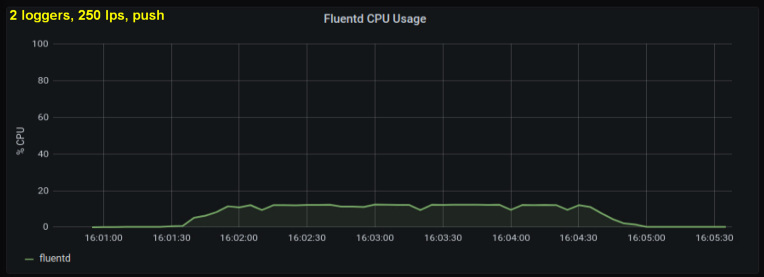
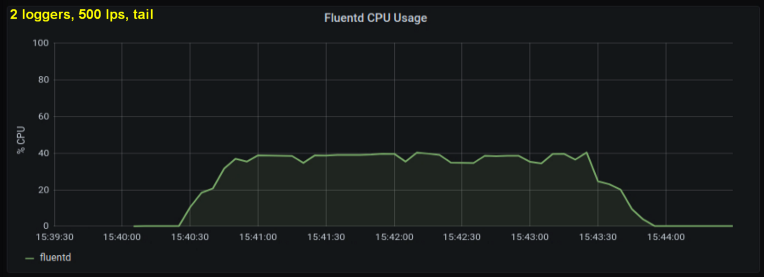

conclusiones
En el transcurso de una semana, realicé estas pruebas de muchas maneras diferentes y terminé con dos conclusiones clave:
- El método con un socket directo consume constantemente entre un 30% y un 50% menos de potencia de procesamiento que la lectura de líneas de archivos de registro con el mismo tamaño. Una posible explicación (para al menos parte de la diferencia observable) es que al serializar los datos en el paquete de mensajes - fluentd. fluentd , messagepack. , Python- forward-, . , : , fluentd, .
- , CPU , . tailing', forward-. , (1000 writer' 10 writer'), forward-:


¿Significan estos resultados que todos deberíamos escribir registros en el socket en lugar de archivos? Obviamente, no es tan simple ...
Si pudiéramos cambiar la forma en que recopilamos registros tan fácilmente, entonces la mayoría de los problemas existentes no serían problemas. La salida de registros
stdouthace que sea mucho más fácil monitorear y trabajar con contenedores durante el desarrollo. La salida de registros de ambas formas, según el contexto, aumentará en gran medida la complejidad; de manera similar, la configuración de fluentd para representar registros durante el desarrollo (por ejemplo, utilizando el complemento de salida stdout) la aumentará .
Quizás una interpretación más práctica de estos resultados sería una recomendación para agrandar los ganglios... Dado que fluentd debe configurarse para trabajar con los nodos más ocupados (más ruidosos), es lógico reducir su número. Combinado con un mecanismo de antiafinidad que distribuiría los principales generadores de registros de manera uniforme, sería una gran estrategia. Por desgracia, el cambio de tamaño de los nodos implica muchos matices y compensaciones que van mucho más allá de las necesidades del sistema de registro.
La escala obviamente también importa... A pequeña escala, los inconvenientes y la complejidad añadida quizás no sean prácticos. Además, suele haber problemas más urgentes. Si recién está comenzando y el olor a "pintura fresca" no ha desaparecido del proceso de ingeniería, puede estandarizar su formato de registro con anticipación y reducir costos utilizando el método de socket sin abrumar a los desarrolladores.
Para quienes trabajan con proyectos a gran escala, las conclusiones de este artículo son inapropiadas, porque empresas como Google han hecho un análisis mucho más completo y con conocimiento intensivo del problema (en comparación con el mío). A esta escala, obviamente, implementa sus propios clústeres y puede hacer lo que quiera con la canalización de registro (en otras palabras, aproveche ambos enfoques).
En conclusión, permítanme adelantarme un par de preguntas y responderlas con anticipación. Primero, “¿No es este artículo sobre fluentd realmente? ¿Y qué tiene que ver con Kubernetes en general ? " ... La respuesta a ambos lados de esta pregunta es: "Bueno, quizás ".
- En mi comprensión y experiencia general, esta herramienta es una ocurrencia común al rastrear archivos en Linux en situaciones en las que tiene una gran cantidad de E / S de disco. No he hecho pruebas con otro reenviador de registros como Logstash , pero sería interesante ver los resultados.
- Kubernetes, CPU, , . , , . , Kubernetes, tailing' Kubernetes-as-a-Service.
Finalmente, unas palabras sobre otro recurso consumible: la memoria . Inicialmente, lo iba a incluir en el artículo: un tablero especialmente preparado para él muestra el uso de memoria de fluentd. Pero al final resultó que este factor no es importante. Según los resultados de la prueba, la cantidad máxima de memoria utilizada no superó los 85 MB, y la diferencia entre las pruebas individuales rara vez superó los 10 MB. Este consumo de memoria bastante bajo se debe obviamente al hecho de que no he utilizado complementos de salida almacenados en búfer. Más importante aún, resultó ser casi el mismo para ambos métodos. Y el artículo ya se estaba volviendo demasiado voluminoso ...
Cabe señalar que hay muchos más "rincones" en los que puede examinar si desea hacer pruebas más profundas. Por ejemplo, puede averiguar en qué estados del procesador y llamadas al sistema pasa la mayor parte del tiempo fluentd, pero para hacer esto, debe crear el contenedor adecuado para ello.
PD del traductor
Lea también en nuestro blog: