Por tanto, dentro de cada proceso por separado no existen los tradicionales problemas "extraños" de ejecución de código paralelo, bloqueos, condiciones de carrera , ... Y el desarrollo del DBMS en sí es agradable y sencillo.
Pero la misma sencillez impone una limitación significativa. Dado que solo hay un hilo de trabajo dentro del proceso, no puede usar más de un núcleo de CPU para ejecutar una solicitud , lo que significa que la velocidad del servidor depende directamente de la frecuencia y arquitectura de un núcleo separado.
En nuestra era de la "carrera de megahercios" acabada y los victoriosos sistemas multinúcleo y multiprocesador, tal comportamiento es un lujo y un despilfarro inadmisibles. Por lo tanto, a partir de PostgreSQL 9.6, al procesar una consulta, algunas operaciones pueden ser realizadas por varios procesos simultáneamente.
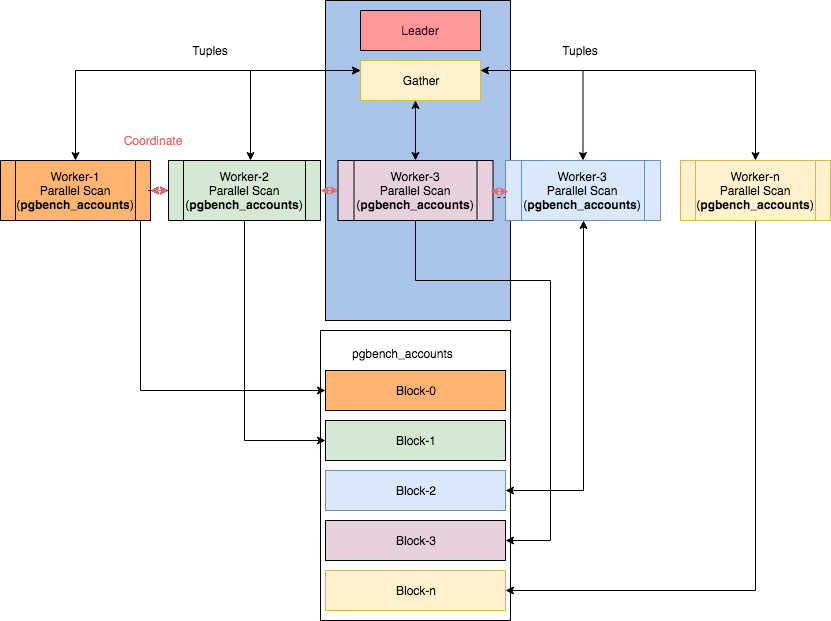
Algunos nodos paralelos se pueden encontrar en el artículo "Paralelismo en PostgreSQL" de Ibrar Ahmed, de donde se tomó esta imagen.Sin embargo, en este caso se vuelve… no trivial leer los planos.
Brevemente, la cronología de la implementación de la ejecución paralela de las operaciones del plan se ve así:
- 9.6 - funcionalidad básica: Seq Scan , Join, Aggregate
- 10 - Escaneo de índice (para btree), escaneo de montón de mapa de bits, combinación hash, combinación de combinación, escaneo de subconsultas
- 11 - operaciones de grupo : Hash Join con tabla hash compartida, Append (UNION)
- 12 - estadísticas básicas por trabajador en los nodos del plan
- 13 - estadísticas detalladas por trabajador
Por lo tanto, si está utilizando una de las últimas versiones de PostgreSQL, las posibilidades de verla en el plan son
Parallel ...muy altas. Y con él vienen y ...
Rarezas a lo largo del tiempo
Tomemos un plan de PostgreSQL 9.6 :
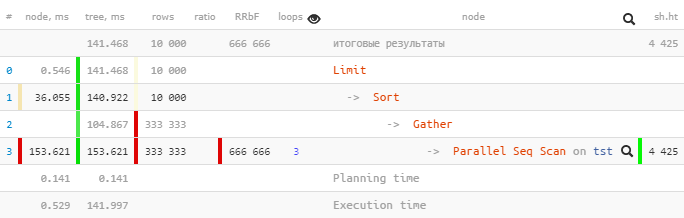
[mira explica.tensor.ru]
Solo uno se
Parallel Seq Scanejecutó 153.621 ms dentro de un subárbol, y Gatherjunto con todos los subnodos, solo 104.867 ms.
¿Cómo es eso? ¿Se ha reducido el tiempo total "arriba"? ...
Echemos un vistazo al
Gather-nodo con más detalle:
Gather (actual time=0.969..104.867 rows=333333 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4425Workers Launched: 2nos dice que, además del proceso principal en el árbol, estuvieron involucrados 2 procesos adicionales, un total de 3. Por lo tanto, todo lo que sucedió dentro del Gathersubárbol es la creatividad total de los 3 procesos a la vez.
Ahora veamos qué hay ahí
Parallel Seq Scan:
Parallel Seq Scan on tst (actual time=0.024..51.207 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425¡Ajá!
loops=3Es un resumen de los 3 procesos. Y, en promedio, cada uno de esos ciclos tomó 51.207 ms. Es decir, el servidor tardó 51.207 x 3 = 153.621milisegundos de tiempo de procesador en completar este nodo . Es decir, si queremos comprender "qué estaba haciendo el servidor", es este número el que nos ayudará a comprender.
Tenga en cuenta que para comprender el tiempo de ejecución "real" , es necesario dividir el tiempo total por el número de trabajadores, es decir [actual time] x [loops] / [Workers Launched].
En nuestro ejemplo, cada trabajador realizó solo un ciclo a través del nodo, por lo tanto
153.621 / 3 = 51.207. Y sí, ahora no tiene nada de extraño que el único Gatheren el proceso de cabeza se haya completado en "por así decirlo, en menos tiempo".
Total: observe el tiempo de nodo total (para todos los procesos) en el archivo explicativo.tensor.ru para comprender con qué tipo de carga estaba ocupado su servidor y para optimizar qué parte de la consulta vale la pena dedicar tiempo.
En este sentido, el comportamiento del mismo explica.depesz.com , que muestra el tiempo "promedio real" a la vez, parece menos útil a efectos de depuración:
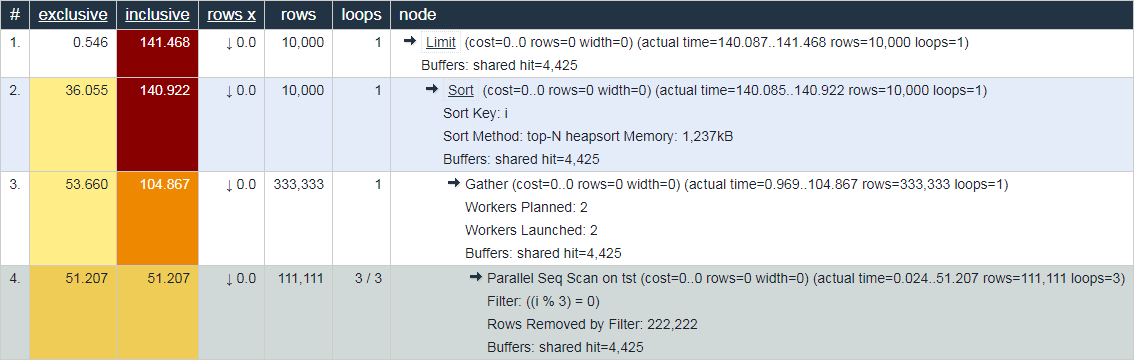
¿No estás de acuerdo? ¡Bienvenidos a los comentarios!
Gather Merge pierde todo
Ahora, ejecutemos la misma consulta para las versiones de PostgreSQL 10 :
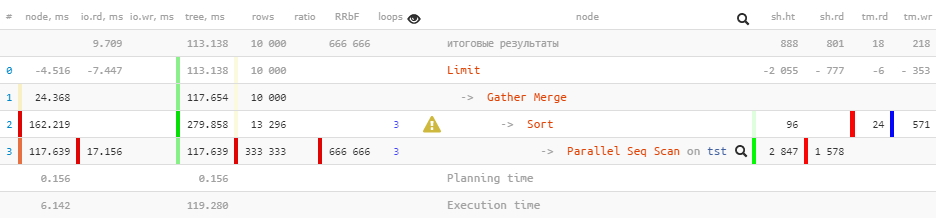
[mira explica.tensor.ru]
Tenga en cuenta que
Gatherahora tenemos un nodo en lugar de un nodo en el plan Gather Merge. Esto es lo que dice el manual sobre esto :
Cuando un nodo está por encima de la parte paralela del planGather Merge, en lugar deGather, significa que todos los procesos que ejecutan partes del plan paralelo están generando tuplas en orden ordenado y que el proceso principal está realizando una combinación que conserva el orden. El nodoGather, en cambio, recibe tuplas de procesos subordinados en un orden arbitrario que le conviene, violando el orden de clasificación que pudiera existir.
Pero no todo está bien en el reino danés:
Limit (actual time=110.740..113.138 rows=10000 loops=1)
Buffers: shared hit=888 read=801, temp read=18 written=218
I/O Timings: read=9.709
-> Gather Merge (actual time=110.739..117.654 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=2943 read=1578, temp read=24 written=571
I/O Timings: read=17.156Al pasar atributos
Buffersy I/O Timingssubir por el árbol, algunos de los datos se perdieron prematuramente . Podemos estimar el tamaño de esta pérdida en aproximadamente 2/3 , que están formados por procesos auxiliares.
Por desgracia, en el plan en sí, no hay ningún lugar para obtener esta información, de ahí las "desventajas" del nodo superpuesto. Y si observa la evolución posterior de este plan en PostgreSQL 12 , entonces no cambia fundamentalmente, excepto que se agregan algunas estadísticas para cada trabajador en el
Sort-nodo:
Limit (actual time=77.063..80.480 rows=10000 loops=1)
Buffers: shared hit=1764, temp read=223 written=355
-> Gather Merge (actual time=77.060..81.892 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4519, temp read=575 written=856
-> Sort (actual time=72.630..73.252 rows=4278 loops=3)
Sort Key: i
Sort Method: external merge Disk: 1832kB
Worker 0: Sort Method: external merge Disk: 1512kB
Worker 1: Sort Method: external merge Disk: 1248kB
Buffers: shared hit=4519, temp read=575 written=856
-> Parallel Seq Scan on tst (actual time=0.014..44.970 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425
Planning Time: 0.142 ms
Execution Time: 83.884 msTotal: no confíe en los datos del nodo anteriores
Gather Merge.