
Cuando comencé mi carrera como desarrollador, mi primer trabajo fue un DBA (administrador de base de datos, DBA). En esos años, incluso antes de AWS RDS, Azure, Google Cloud y otros servicios en la nube, había dos tipos de DBA:
- , . « », , .
- : , , SQL. ETL- . , .
Los administradores de bases de datos de aplicaciones suelen formar parte de equipos de desarrollo. Tenían un conocimiento profundo de un tema específico, por lo que generalmente solo trabajaban en uno o dos proyectos. Los DBA de infraestructura solían formar parte del equipo de TI y podían trabajar en varios proyectos al mismo tiempo.
Soy el administrador de la base de datos de la aplicación
Nunca he tenido la necesidad de perder el tiempo con las copias de seguridad o modificar el almacenamiento (¡estoy seguro de que es divertido!). Hasta el día de hoy, me gusta decir que soy un administrador de bases de datos que sabe cómo desarrollar aplicaciones, no un desarrollador que comprende bases de datos.
En este artículo, compartiré algunos de los trucos de desarrollo de bases de datos que he aprendido a lo largo de mi carrera.
Contenido:
- Actualice solo lo que necesita actualizarse
- Deshabilitar restricciones e índices para cargas pesadas
- Utilice tablas DESLOGGED para datos intermedios
- Implementar procesos completos con WITH y RETURNING
- Evite índices en columnas con baja selectividad
- Usa índices parciales
- Cargar siempre datos ordenados
- Índice de columnas altamente correlacionadas con BRIN
- Hacer que los índices sean "invisibles"
- No programe procesos largos para que comiencen al comienzo de cualquier hora
- Conclusión
Actualice solo lo que necesita actualizarse
La operación
UPDATEconsume bastantes recursos. La mejor manera de acelerarlo es actualizar solo lo que necesita actualizarse.
A continuación, se muestra un ejemplo de una solicitud para normalizar una columna de correo electrónico:
db=# UPDATE users SET email = lower(email);
UPDATE 1010000
Time: 1583.935 ms (00:01.584)
Parece inocente, ¿verdad? La solicitud actualiza las direcciones de correo de 1.010.000 usuarios. Pero, ¿es necesario actualizar todas las filas?
db=# UPDATE users SET email = lower(email)
db-# WHERE email != lower(email);
UPDATE 10000
Time: 299.470 ms
Solo se necesita actualizar 10,000 filas. Al reducir la cantidad de datos procesados, redujimos el tiempo de ejecución de 1,5 segundos a menos de 300 ms. Esto también nos ahorrará más esfuerzos en el mantenimiento de la base de datos.
Actualice solo lo que necesita actualizarse.
Este tipo de gran actualización es muy común en los scripts de migración de datos. La próxima vez que escriba un script como este, asegúrese de actualizar solo lo necesario.
Deshabilitar restricciones e índices para cargas pesadas
Las restricciones son una parte importante de las bases de datos relacionales: preservan la consistencia y confiabilidad de los datos. Pero todo tiene su propio precio, y la mayoría de las veces tienes que pagar cuando descargas o actualizas una gran cantidad de filas.
Definamos un pequeño esquema de almacenamiento:
DROP TABLE IF EXISTS product CASCADE;
CREATE TABLE product (
id serial PRIMARY KEY,
name TEXT NOT NULL,
price INT NOT NULL
);
INSERT INTO product (name, price)
SELECT random()::text, (random() * 1000)::int
FROM generate_series(0, 10000);
DROP TABLE IF EXISTS customer CASCADE;
CREATE TABLE customer (
id serial PRIMARY KEY,
name TEXT NOT NULL
);
INSERT INTO customer (name)
SELECT random()::text
FROM generate_series(0, 100000);
DROP TABLE IF EXISTS sale;
CREATE TABLE sale (
id serial PRIMARY KEY,
created timestamptz NOT NULL,
product_id int NOT NULL,
customer_id int NOT NULL
);
Define diferentes tipos de restricciones, como "no nulo", así como restricciones únicas ...
Para establecer el punto de partida, comencemos a agregar
saleclaves externas a la tabla
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 18.413 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 5.464 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 12.605 ms
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 15410.234 ms (00:15.410)
Después de definir las restricciones y los índices, cargar un millón de filas en la tabla tomó aproximadamente 15,4 segundos.
Ahora, primero, carguemos los datos en la tabla, y solo luego agreguemos restricciones e índices:
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 2277.824 ms (00:02.278)
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 169.193 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 185.633 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 484.244 ms
La carga fue mucho más rápida, 2,27 segundos. en lugar de 15,4. Los índices y límites se crearon mucho más tiempo después de cargar los datos, pero todo el proceso fue mucho más rápido: 3,1 s. en lugar de 15,4.
Desafortunadamente, en PostgreSQL no puede hacer lo mismo con los índices, solo puede desecharlos y volver a crearlos. En otras bases de datos, como Oracle, puede deshabilitar y habilitar índices sin reconstruir.
UNLOGGED-
Cuando cambia datos en PostgreSQL, los cambios se escriben en el registro de escritura anticipada (WAL ). Se utiliza para mantener la coherencia, reindexar rápidamente durante la recuperación y mantener la replicación.
A menudo es necesario escribir en WAL, pero hay algunas circunstancias en las que puede optar por no participar en WAL para acelerar las cosas. Por ejemplo, en el caso de tablas intermedias.
Las tablas intermedias se denominan tablas únicas, que almacenan datos temporales que se utilizan para implementar algunos procesos. Por ejemplo, en los procesos ETL, es muy común cargar datos de archivos CSV en tablas de preparación, borrar la información y luego cargarla en la tabla de destino. En tal escenario, la tabla de preparación es de un solo uso y no se usa en copias de seguridad o réplicas.
Tabla DESLOGGED.
Las tablas de preparación que no es necesario recuperar en caso de falla y que no se necesitan en las réplicas se pueden configurar como DESLOGGED :
CREATE UNLOGGED TABLE staging_table ( /* table definition */ );
Precaución : antes de usar
UNLOGGED, asegúrese de comprender completamente todas las implicaciones.
Implementar procesos completos con WITH y RETURNING
Supongamos que tiene una tabla de usuarios y encuentra que contiene datos duplicados:
Table setup
db=# SELECT u.id, u.email, o.id as order_id
FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
3 | ME@hakibenita.com | 4
3 | ME@hakibenita.com | 5
El usuario haki benita se registró dos veces, con correo
ME@hakibenita.comy me@hakibenita.com. Dado que no estamos normalizando las direcciones de correo electrónico al ingresarlas en la tabla, ahora tenemos que lidiar con los duplicados.
Nosotros necesitamos:
- Identifique direcciones duplicadas en minúsculas y vincule a usuarios duplicados entre sí.
- Actualice los pedidos para que solo se refieran a uno de los duplicados.
- Elimina los duplicados de la mesa.
Puede vincular usuarios duplicados mediante una tabla de preparación:
db=# CREATE UNLOGGED TABLE duplicate_users AS
db-# SELECT
db-# lower(email) AS normalized_email,
db-# min(id) AS convert_to_user,
db-# array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
db-# FROM
db-# users
db-# GROUP BY
db-# normalized_email
db-# HAVING
db-# count(*) > 1;
CREATE TABLE
db=# SELECT * FROM duplicate_users;
normalized_email | convert_to_user | convert_from_users
-------------------+-----------------+--------------------
me@hakibenita.com | 2 | {3}
La tabla intermedia contiene enlaces entre tomas. Si un usuario con una dirección de correo electrónico normalizada aparece más de una vez, le asignamos un ID de usuario mínimo, en el que colapsamos todos los duplicados. El resto de los usuarios se almacenan en la columna de la matriz y se actualizarán todas las referencias a ellos.
Usando la tabla intermedia, actualizamos los enlaces a duplicados en la tabla
orders:
db=# UPDATE
db-# orders o
db-# SET
db-# user_id = du.convert_to_user
db-# FROM
db-# duplicate_users du
db-# WHERE
db-# o.user_id = ANY(du.convert_from_users);
UPDATE 2
Ahora puede eliminar de forma segura los duplicados de
users:
db=# DELETE FROM
db-# users
db-# WHERE
db-# id IN (
db(# SELECT unnest(convert_from_users)
db(# FROM duplicate_users
db(# );
DELETE 1
Tenga en cuenta que usamos la función unnest para "transformar" la matriz , que convierte cada elemento en una cadena.
Resultado:
db=# SELECT u.id, u.email, o.id as order_id
db-# FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
2 | me@hakibenita.com | 4
2 | me@hakibenita.com | 5
Genial, todas las instancias de user
3( ME@hakibenita.com) se convierten a user 2( me@hakibenita.com).
También podemos comprobar que se eliminan los duplicados de la tabla
users:
db=# SELECT * FROM users;
id | email
----+-------------------
1 | foo@bar.baz
2 | me@hakibenita.com
Ahora podemos deshacernos de la tabla de preparación:
db=# DROP TABLE duplicate_users;
DROP TABLE
Está bien, ¡pero lleva demasiado tiempo y necesita limpieza! ¿Existe una forma mejor?
Expresiones de tabla generalizadas (CTE)
Con las expresiones de tabla genéricas , también conocidas como expresiones
WITH, podemos ejecutar todo el procedimiento con una sola expresión SQL:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
)
DELETE FROM
users
WHERE
id IN (
SELECT
unnest(convert_from_users)
FROM
duplicate_users
);
En lugar de una tabla de preparación, creamos una expresión de tabla genérica y la reutilizamos.
Devolver resultados de CTE
Una de las ventajas de ejecutar DML dentro de una expresión
WITHes que puede devolver datos de ella utilizando la palabra clave RETURNING . Digamos que necesitamos un informe sobre la cantidad de filas actualizadas y eliminadas:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
RETURNING o.id
),
delete_duplicate_user AS (
DELETE FROM
users
WHERE
id IN (
SELECT unnest(convert_from_users)
FROM duplicate_users
)
RETURNING id
)
SELECT
(SELECT count(*) FROM update_orders_of_duplicate_users) AS orders_updated,
(SELECT count(*) FROM delete_duplicate_user) AS users_deleted
;
Resultado:
orders_updated | users_deleted
----------------+---------------
2 | 1
La belleza de este enfoque es que todo el proceso se realiza con un solo comando, por lo que no hay necesidad de administrar transacciones o preocuparse por vaciar la tabla de preparación en caso de una falla del proceso.
Advertencia : un lector de Reddit me señaló el posible comportamiento impredecible de la ejecución de DML en expresiones de tabla genéricas :
Las subexpresiones enWITHse ejecutan simultáneamente entre sí y con la consulta principal. Por lo tanto, cuando se usa enWITHexpresiones de modificación de datos, el orden real de las actualizaciones será impredecible.
Esto significa que no puede confiar en el orden en el que se ejecutan las subexpresiones independientes. Resulta que si hay una dependencia entre ellos, como en el ejemplo anterior, puede confiar en la ejecución de la subexpresión dependiente antes de usarlos.
Evite índices en columnas con baja selectividad
Supongamos que tiene un proceso de registro en el que un usuario inicia sesión en una dirección de correo electrónico. Para activar su cuenta, debe verificar su correo. La tabla podría verse así:
db=# CREATE TABLE users (
db-# id serial,
db-# username text,
db-# activated boolean
db-#);
CREATE TABLE
La mayoría de sus usuarios son ciudadanos conscientes, se registran con la dirección de correo correcta y activan inmediatamente la cuenta. Completemos la tabla con datos de usuario y supongamos que el 90% de los usuarios están activados:
db=# INSERT INTO users (username, activated)
db-# SELECT
db-# md5(random()::text) AS username,
db-# random() < 0.9 AS activated
db-# FROM
db-# generate_series(1, 1000000);
INSERT 0 1000000
db=# SELECT activated, count(*) FROM users GROUP BY activated;
activated | count
-----------+--------
f | 102567
t | 897433
db=# VACUUM ANALYZE users;
VACUUM
Para consultar el número de usuarios activados y no activados, puede crear un índice por columna
activated:
db=# CREATE INDEX users_activated_ix ON users(activated);
CREATE INDEX
Y si pregunta la cantidad de usuarios no activados , la base usará el índice:
db=# EXPLAIN SELECT * FROM users WHERE NOT activated;
QUERY PLAN
--------------------------------------------------------------------------------------
Bitmap Heap Scan on users (cost=1923.32..11282.99 rows=102567 width=38)
Filter: (NOT activated)
-> Bitmap Index Scan on users_activated_ix (cost=0.00..1897.68 rows=102567 width=0)
Index Cond: (activated = false)
La base decidió que el filtro devolvería 102,567 elementos, aproximadamente el 10% de la tabla. Esto es coherente con los datos que cargamos, por lo que la tabla hizo un buen trabajo.
Sin embargo, si consultamos el número de usuarios activados , encontramos que la base de datos ha decidido no usar el índice :
db=# EXPLAIN SELECT * FROM users WHERE activated;
QUERY PLAN
---------------------------------------------------------------
Seq Scan on users (cost=0.00..18334.00 rows=897433 width=38)
Filter: activated
Muchos desarrolladores se confunden cuando la base de datos no utiliza el índice. Para explicar por qué hace esto, lo siguiente es: si necesitara leer toda la tabla, ¿usaría un índice ?
Probablemente no, ¿por qué es necesario? Leer desde el disco es caro, por lo que querrá leer lo menos posible. Por ejemplo, si la tabla tiene 10 MB y el índice es 1 MB, para leer la tabla completa, tendrá que leer 10 MB del disco. Y si agrega un índice, obtiene 11 MB. Es un desperdicio.
Echemos ahora un vistazo a las estadísticas que PostgreSQL ha recopilado en nuestra tabla:
db=# SELECT attname, n_distinct, most_common_vals, most_common_freqs
db-# FROM pg_stats
db-# WHERE tablename = 'users' AND attname='activated';
------------------+------------------------
attname | activated
n_distinct | 2
most_common_vals | {t,f}
most_common_freqs | {0.89743334,0.10256667}
Cuando PostgreSQL analizó la tabla, encontró que
activatedhabía dos valores diferentes en la columna . El valor tde la columna most_common_valscorresponde a la frecuencia 0.89743334de la columna most_common_freqsy el valor fcorresponde a la frecuencia 0.10256667. Tras analizar la tabla, la base de datos determinó que el 89,74% de los registros eran usuarios activados y el 10,26% restante no estaban activados.
Con base en estas estadísticas, PostgreSQL decidió que era mejor escanear toda la tabla que asumir que el 90% de las filas cumplen la condición. El umbral más allá del cual una base puede decidir si utilizar un índice depende de muchos factores y no existe una regla general.
Índice para columnas con baja y alta selectividad.
Usa índices parciales
En el capítulo anterior, creamos un índice para una columna booleana que tenía aproximadamente el 90% de los registros
true(usuarios activados).
Cuando preguntamos por el número de usuarios activos, la base de datos no usó el índice. Y cuando se le preguntó por el número de no activados, la base de datos utilizó el índice.
Surge la pregunta: si la base de datos no va a utilizar el índice para filtrar usuarios activos, ¿por qué los indexaríamos en primer lugar?
Antes de responder esta pregunta, veamos el peso del índice completo por columna
activated:
db=# \di+ users_activated_ix
Schema | Name | Type | Owner | Table | Size
--------+--------------------+-------+-------+-------+------
public | users_activated_ix | index | haki | users | 21 MB
El índice pesa 21 MB. Solo como referencia: la tabla con usuarios es de 65 MB. Es decir, el peso del índice es ~ 32% del peso base. Dicho esto, sabemos que es poco probable que se utilice ~ 90% del contenido del índice.
En PostgreSQL, puede crear un índice en solo una parte de una tabla, el llamado índice parcial :
db=# CREATE INDEX users_unactivated_partial_ix ON users(id)
db-# WHERE not activated;
CREATE INDEX
Usamos una expresión
WHEREpara restringir las cadenas cubiertas por el índice. Comprobemos si funciona:
db=# EXPLAIN SELECT * FROM users WHERE not activated;
QUERY PLAN
------------------------------------------------------------------------------------------------
Index Scan using users_unactivated_partial_ix on users (cost=0.29..3493.60 rows=102567 width=38)
Genial, la base de datos resultó ser lo suficientemente inteligente como para darse cuenta de que la expresión booleana que usamos en nuestra consulta podría funcionar para un índice parcial.
Este enfoque tiene otra ventaja:
db=# \di+ users_unactivated_partial_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+------------------------------+-------+-------+-------+---------
public | users_unactivated_partial_ix | index | haki | users | 2216 kB
El índice de la columna completa pesa 21 MB y el índice parcial es de solo 2,2 MB. Eso es el 10%, que corresponde a la proporción de usuarios no activados en la tabla.
Cargar siempre datos ordenados
Este es uno de mis comentarios más frecuentes al analizar código. El consejo no es tan intuitivo como los demás y puede tener un gran impacto en la productividad.
Digamos que tiene una mesa enorme con ventas específicas:
db=# CREATE TABLE sale_fact (id serial, username text, sold_at date);
CREATE TABLE
Todas las noches durante el proceso ETL, carga datos en una tabla:
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000);
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
Para simular la descarga, utilizamos datos aleatorios. Insertamos 100 mil líneas con nombres aleatorios y las fechas de venta para el período comprendido entre el 1 de enero de 2020 y los dos años siguientes.
En su mayor parte, la tabla se utiliza para informes resumidos de ventas. La mayoría de las veces, filtran por fecha para ver las ventas de un período específico. Para acelerar el escaneo de rango, creemos un índice de la siguiente manera
sold_at:
db=# CREATE INDEX sale_fact_sold_at_ix ON sale_fact(sold_at);
CREATE INDEX
Echemos un vistazo al plan de ejecución de la solicitud para obtener todas las ventas en junio de 2020:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
-----------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=108.30..1107.69 rows=4293 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Heap Blocks: exact=927
-> Bitmap Index Scan on sale_fact_sold_at_ix (cost=0.00..107.22 rows=4293 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.191 ms
Execution Time: 5.906 ms
Después de ejecutar la solicitud varias veces para calentar la caché, el tiempo de ejecución se estabilizó en el nivel de 6 ms.
Escaneo de mapa de bits
En términos de ejecución, vemos que la base utilizó escaneo de mapa de bits. Se desarrolla en dos etapas:
(Bitmap Index Scan): la base recorre todo el índicesale_fact_sold_at_ixy busca todas las páginas de la tabla que contienen las filas relevantes.(Bitmap Heap Scan): la base lee las páginas que contienen las cadenas relevantes y busca aquellas que satisfacen la condición.
Las páginas pueden contener muchas líneas. En el primer paso, el índice se utiliza para buscar páginas . La segunda etapa busca líneas en las páginas, de ahí la operación
Recheck Conden el plan de ejecución.
En este punto, muchos DBA y desarrolladores completarán y pasarán a la siguiente consulta. Pero hay una forma de mejorar esta consulta.
Escaneo de índice
Hagamos un pequeño cambio en la carga de datos.
db=# TRUNCATE sale_fact;
TRUNCATE TABLE
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
db-# ORDER BY sold_at;
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
Esta vez cargamos datos ordenados por
sold_at.
Ahora, el plan de ejecución para la misma consulta se ve así:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.29..184.73 rows=4272 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.145 ms
Execution Time: 2.294 ms
Después de varias ejecuciones, el tiempo de ejecución se estabilizó en 2,3 ms. Hemos logrado ahorros sostenibles de alrededor del 60%.
También vemos que esta vez la base de datos no usó escaneo de mapa de bits, sino que aplicó un escaneo de índice "normal". ¿Por qué?
Correlación
Cuando la base de datos analiza la tabla, recopila todas las estadísticas que puede obtener. Uno de los parámetros es la correlación :
Correlación estadística entre el orden físico de las filas y el orden lógico de los valores en las columnas. Si el valor es alrededor de -1 o +1, una exploración de índice en la columna se considera más ventajosa que cuando el valor de correlación es alrededor de 0, ya que se reduce el número de accesos aleatorios al disco.
Como se explica en la documentación oficial, la correlación es una medida de cómo se ordenan los valores en una columna particular del disco.
Correlación = 1.
Si la correlación es 1 más o menos, significa que las páginas se almacenan en el disco aproximadamente en el mismo orden que las filas de la tabla. Esto es muy común. Por ejemplo, los ID de incremento automático tienden a tener una correlación cercana a 1. Las columnas de fecha y marca de tiempo que muestran cuándo se crearon las filas también tienen una correlación cercana a 1.
Si la correlación es -1, las páginas se ordenan en orden inverso de las columnas.
Correlación ~ 0.
Si la correlación es cercana a 0, significa que los valores de la columna no se correlacionan o apenas se correlacionan con el orden de las páginas de la tabla.
Volvamos a
sale_fact. Cuando cargamos los datos en la tabla sin clasificarlos previamente, las correlaciones fueron así:
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db=# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale | id | 1
sale | username | -0.005344716
sale | sold_at | -0.011389783
El ID de columna generado automáticamente tiene una correlación de 1. La columna tiene una
sold_atcorrelación muy baja: los valores consecutivos están dispersos por toda la tabla.
Cuando cargamos los datos ordenados en la tabla, ella calculó las correlaciones:
tablename | attname | correlation
-----------+----------+----------------
sale_fact | id | 1
sale_fact | username | -0.00041992788
sale_fact | sold_at | 1
La correlación ahora
sold_ates igual 1.
Entonces, ¿por qué la base utilizó escaneos de mapa de bits cuando la correlación era baja, pero escaneos de índice cuando la correlación era alta?
- Cuando la correlación era 1, la base determinaba que las filas del rango solicitado probablemente estuvieran en páginas consecutivas. Entonces es mejor utilizar un escaneo de índice para leer varias páginas.
- Cuando la correlación era cercana a 0, la base determinaba que era probable que las filas del rango solicitado estuvieran dispersas por toda la tabla. Entonces es aconsejable usar un escaneo de mapa de bits de aquellas páginas que contienen las líneas requeridas, y solo luego extraerlas usando la condición.
La próxima vez que cargue datos en una tabla, piense en cuánta información se solicitará y ordene para que los índices puedan escanear rangos rápidamente.
Comando CLUSTER
Otra forma de "ordenar una tabla en el disco" por un índice específico es usar el comando CLUSTER .
Por ejemplo:
db=# TRUNCATE sale_fact;
TRUNCATE TABLE
-- Insert rows without sorting
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
INSERT 0 100000
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+-----------+----------------
sale_fact | sold_at | -5.9702674e-05
sale_fact | id | 1
sale_fact | username | 0.010033822
Cargamos los datos en la tabla en un orden aleatorio, por lo que la correlación
sold_ates cercana a cero.
Para "recomponer" la tabla
sold_at, usamos el comando CLUSTERpara ordenar la tabla en el disco de acuerdo con el índice sale_fact_sold_at_ix:
db=# CLUSTER sale_fact USING sale_fact_sold_at_ix;
CLUSTER
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale_fact | sold_at | 1
sale_fact | id | -0.002239401
sale_fact | username | 0.013389298
Después de agrupar la tabla, la correlación se
sold_atconvirtió en 1.
Comando CLUSTER.
Puntos a tener en cuenta:
- Agrupar una tabla en una columna en particular puede afectar la correlación de otra columna. Por ejemplo, observe la correlación de ID después de agrupar por
sold_at. CLUSTEREs una operación pesada y de bloqueo, por lo que no la aplique a una mesa en vivo.
Por estas razones, es mejor insertar datos que ya están ordenados y no confiar
CLUSTER.
Índice de columnas altamente correlacionadas con BRIN
Cuando se trata de índices, muchos desarrolladores piensan en árboles B. Pero PostgreSQL ofrece otros tipos de índices, como BRIN :
BRIN está diseñado para trabajar con tablas muy grandes en las que algunas columnas se correlacionan naturalmente con su ubicación física dentro de la tabla.
BRIN son las siglas de Block Range Index. Según la documentación, BRIN funciona mejor con columnas altamente correlacionadas. Como hemos visto en capítulos anteriores, los ID y las marcas de tiempo que se incrementan automáticamente se correlacionan naturalmente con la estructura física de la tabla, por lo que BRIN es más beneficioso para ellos.
Bajo ciertas condiciones, BRIN puede ofrecer una mejor "relación calidad-precio" en términos de tamaño y rendimiento en comparación con un índice de árbol B comparable.
BRIN.
BRIN es un rango de valores dentro de varias páginas adyacentes en una tabla. Digamos que tenemos los siguientes valores en una columna, cada uno en una página separada:
1, 2, 3, 4, 5, 6, 7, 8, 9
BRIN trabaja con rangos de páginas adyacentes. Si especifica tres páginas adyacentes, el índice divide la tabla en rangos:
[1,2,3], [4,5,6], [7,8,9]
Para cada rango, BRIN almacena el valor mínimo y máximo :
[1–3], [4–6], [7–9]
Usemos este índice para buscar el valor 5:
- [1-3] - ciertamente no está aquí.
- [4-6] - tal vez aquí.
- [7-9] - ciertamente no está aquí.
Con BRIN hemos limitado el área de búsqueda al bloque 4-6.
Tomemos otro ejemplo. Dejar que los valores de la columna tienen una correlación cercana a cero, es decir, que están no ordenados:
[2,9,5], [1,4,7], [3,8,6]
Indexar tres bloques adyacentes nos dará los siguientes rangos:
[2–9], [1–7], [3–8]
Busquemos el valor 5:
- [2-9] - puede estar aquí.
- [1-7] - puede estar aquí.
- [3–8] - puede estar aquí.
En este caso, el índice no reduce la búsqueda en absoluto, por lo que es inútil.
Entendiendo las páginas_por_rango
El número de páginas adyacentes está determinado por el parámetro
pages_per_range. El número de páginas de un rango afecta el tamaño y la precisión del BRIN:
- Un
pages_per_rangeíndice más pequeño y menos preciso dará un gran valor . - Un valor pequeño
pages_per_rangedará un índice más grande y más preciso.
El valor predeterminado
pages_per_rangees 128.
BRIN con páginas_por_rango más bajas
Para ilustrar, creemos un BRIN con rangos de dos páginas y busquemos un valor de 5:
- [1–2] - ciertamente no está aquí.
- [3-4] - ciertamente no está aquí.
- [5-6] - puede estar aquí.
- [7-8] - ciertamente no está aquí.
- [9] - aquí definitivamente no lo es.
Con un rango de dos páginas, podemos restringir la búsqueda a los bloques 5 y 6. Si el rango es de tres páginas, el índice limitará la búsqueda a los bloques 4, 5 y 6.
Otra diferencia entre los dos índices es que cuando el rango era de tres páginas, necesitábamos almacenar tres rangos , y con dos páginas en un rango, ya obtenemos cinco rangos y el índice aumenta.
Crear BRIN
Tomemos una tabla
sales_facty creemos un BRIN por columna sold_at:
db=# CREATE INDEX sale_fact_sold_at_bix ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 128);
CREATE INDEX
El predeterminado es
pages_per_range = 128.
Ahora consultemos el período de la fecha de venta:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.11..1135.61 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 23130
Heap Blocks: lossy=256
-> Bitmap Index Scan on sale_fact_sold_at_bix (cost=0.00..12.03 rows=12500 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 8.877 ms
La base obtuvo el período de fecha usando BRIN, pero esto no es nada interesante ...
Optimización de pages_per_range
db=# CREATE INDEX sale_fact_sold_at_bix64 ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 64);
CREATE INDEX
db=# EXPLAIN (ANALYZE)
db- SELECT *
db- FROM sale_fact
db- WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.10..1048.10 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 9434
Heap Blocks: lossy=128
-> Bitmap Index Scan on sale_fact_sold_at_bix64 (cost=0.00..12.02 rows=6667 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 5.491 ms
64 , - 9 434. , -, , ~ 5,5 ~ 8,9 .
pages_per_range:
| páginas_por_rango | |
| 128 | 23 130 |
| 64 | 9 434 |
| 8 | 874 |
| 4 | 446 |
| 2 | 446 |
Disminuir el
pages_per_rangeíndice se vuelve más preciso y elimina menos filas de las páginas que encuentra.
Tenga en cuenta que hemos optimizado una consulta muy específica. Esto está bien para ilustrar, pero en la vida real es mejor usar valores que satisfagan las necesidades de la mayoría de las consultas.
Estimando el tamaño del índice
Otra gran ventaja de BRIN es su tamaño. En los capítulos anteriores,
sold_atcreamos un índice de árbol B para el campo . Su tamaño era de 2.224 KB. Y el tamaño BRIN con el parámetro es pages_per_range=128solo 48 KB: 46 veces más pequeño.
Schema | Name | Type | Owner | Table | Size
--------+-----------------------+-------+-------+-----------+-------
public | sale_fact_sold_at_bix | index | haki | sale_fact | 48 kB
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
El tamaño de BRIN también se ve afectado
pages_per_range. Por ejemplo, BRIN s pages_per_range=2pesa 56 Kb, algo más de 48 Kb.
Hacer que los índices sean "invisibles"
PostgreSQL tiene una característica DDL transaccional genial . A lo largo de los años con Oracle, me he acostumbrado a usar comandos DDL como
CREATE, DROPy ALTER. Pero en PostgreSQL, puede ejecutar comandos DDL dentro de una transacción, y los cambios se aplicarán solo después de que se confirme la transacción.
Recientemente descubrí que el uso de DDL transaccional puede hacer que los índices sean invisibles. Esto es útil cuando desea ver un plan de ejecución sin índices.
Por ejemplo, en una tabla
sale_facthemos creado un índice en una columna sold_at. El plan de ejecución para la solicitud de recuperación de ventas de julio tiene este aspecto:
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.42..182.80 rows=4319 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))P
Para ver cómo se vería el plan si no hubiera un índice
sale_fact_sold_at_ix, puede colocar el índice dentro de una transacción y revertirlo inmediatamente:
db=# BEGIN;
BEGIN
db=# DROP INDEX sale_fact_sold_at_ix;
DROP INDEX
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on sale_fact (cost=0.00..2435.00 rows=4319 width=41)
Filter: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
db=# ROLLBACK;
ROLLBACK
Primero, comencemos una transacción con
BEGIN. Luego soltamos el índice y generamos el plan de ejecución. Tenga en cuenta que el plan ahora utiliza un escaneo completo de la tabla como si el índice no existiera. En este punto, la transacción aún está en curso, por lo que el índice aún no se ha eliminado. Para completar la transacción sin eliminar el índice, revuélvalo usando el comando ROLLBACK.
Comprobemos que el índice aún existe:
db=# \di+ sale_fact_sold_at_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+----------------------+-------+-------+-----------+---------
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
Otras bases de datos que no admiten DDL transaccional pueden lograr el objetivo de manera diferente. Por ejemplo, Oracle le permite marcar un índice como invisible y el optimizador lo ignorará.
Advertencia : si usted deje caer el índice dentro de una transacción, que dará lugar al bloqueo de las operaciones competitivas
SELECT, INSERT, UPDATEy DELETEen la tabla hasta que la transacción está activo. Úselo con precaución en entornos de prueba y evite su uso en instalaciones de producción.
No programe procesos largos para que comiencen al comienzo de cualquier hora
Los inversores saben que pueden suceder cosas extrañas cuando el precio de las acciones alcanza hermosos valores redondos, por ejemplo, $ 10, $ 100, $ 1000. Esto es lo que escriben al respecto :
[...] el precio de los activos puede cambiar de manera impredecible, cruzando valores redondos como $ 50 o $ 100 por acción. A muchos traders sin experiencia les gusta comprar o vender activos cuando el precio alcanza números redondos , porque piensan que son precios justos.
Desde este punto de vista, los desarrolladores no son muy diferentes de los inversores. Cuando necesitan programar un proceso largo, generalmente eligen una hora.
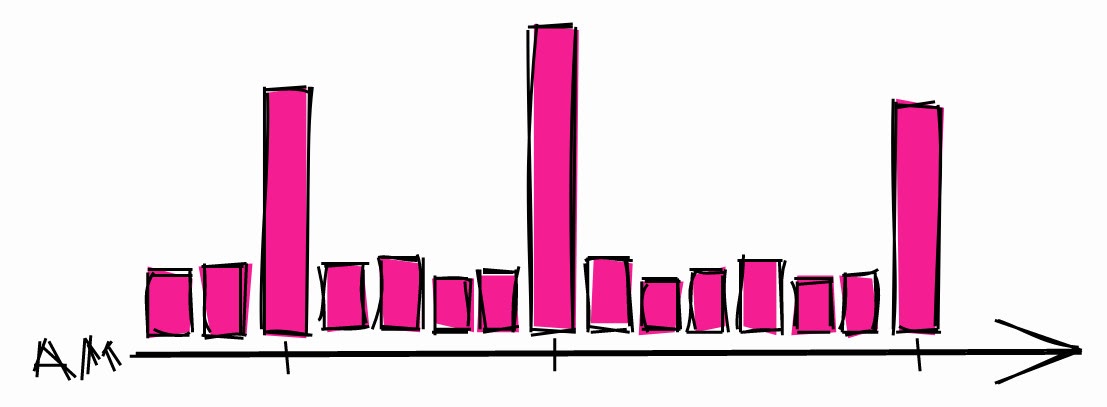
Carga típica del sistema durante la noche.
Esto puede provocar picos de carga durante estas horas. Entonces, si necesita programar un proceso largo, existe una mayor posibilidad de que el sistema esté inactivo en otros momentos.
También se recomienda utilizar retrasos aleatorios en sus horarios para que no comience a la misma hora cada vez. Entonces, incluso si se programa otra tarea para esta hora, no será un gran problema. Si está utilizando un temporizador systemd, puede utilizar la opción RandomizedDelaySec .
Conclusión
Este artículo proporciona consejos de diversos grados de evidencia basados en mi experiencia. Algunas son fáciles de implementar, otras requieren un conocimiento profundo de cómo funcionan las bases de datos. Las bases de datos son la columna vertebral de la mayoría de los sistemas modernos, por lo que el tiempo dedicado a aprender a trabajar es una buena inversión para cualquier desarrollador.