¡Hola, Habr! En este artículo, le mostraré cómo hacer un análisis de frecuencia del idioma ruso moderno de Internet y cómo usarlo para descifrar el texto. ¡A quién le importa, bienvenido bajo el corte!

Análisis de frecuencia del idioma ruso de Internet.
Como fuente de donde se puede obtener una gran cantidad de texto con un lenguaje moderno de Internet, se tomó la red social Vkontakte, o para ser más precisos, estos son comentarios sobre publicaciones en diversas comunidades de esta red. Elegí el fútbol real como comunidad . Para analizar los comentarios, utilicé la API de Vkontakte :
def get_all_post_id():
sleep(1)
offset = 0
arr_posts_id = []
while True:
sleep(1)
r = requests.get('https://api.vk.com/method/wall.get',
params={'owner_id': group_id, 'count': 100,
'offset': offset, 'access_token': token,
'v': version})
for i in range(100):
post_id = r.json()['response']['items'][i]['id']
arr_posts_id.append(post_id)
if offset > 20000:
break
offset += 100
return arr_posts_id
def get_all_comments(arr_posts_id):
offset = 0
for post_id in arr_posts_id:
r = requests.get('https://api.vk.com/method/wall.getComments',
params={'owner_id': group_id, 'post_id': post_id,
'count': 100, 'offset': offset,
'access_token': token, 'v': version})
for i in range(100):
try:
write_txt('comments.txt', r.json()
['response']['items'][i]['text'])
except IndexError:
passEl resultado fue aproximadamente 200 MB de texto. Ahora consideramos qué personaje se encuentra cuántas veces:
f = open('comments.txt')
counter = Counter(f.read().lower())
def count_letters():
count = 0
for i in range(len(arr_letters)):
count += counter[arr_letters[i]]
return count
def frequency(count):
arr_my_frequency = []
for i in range(len(arr_letters)):
frequency = counter[arr_letters[i]] / count * 100
arr_my_frequency.append(frequency)
return arr_my_frequencyLos resultados obtenidos se pueden comparar con los resultados de Wikipedia y se muestran como:
1) cuadro comparativo
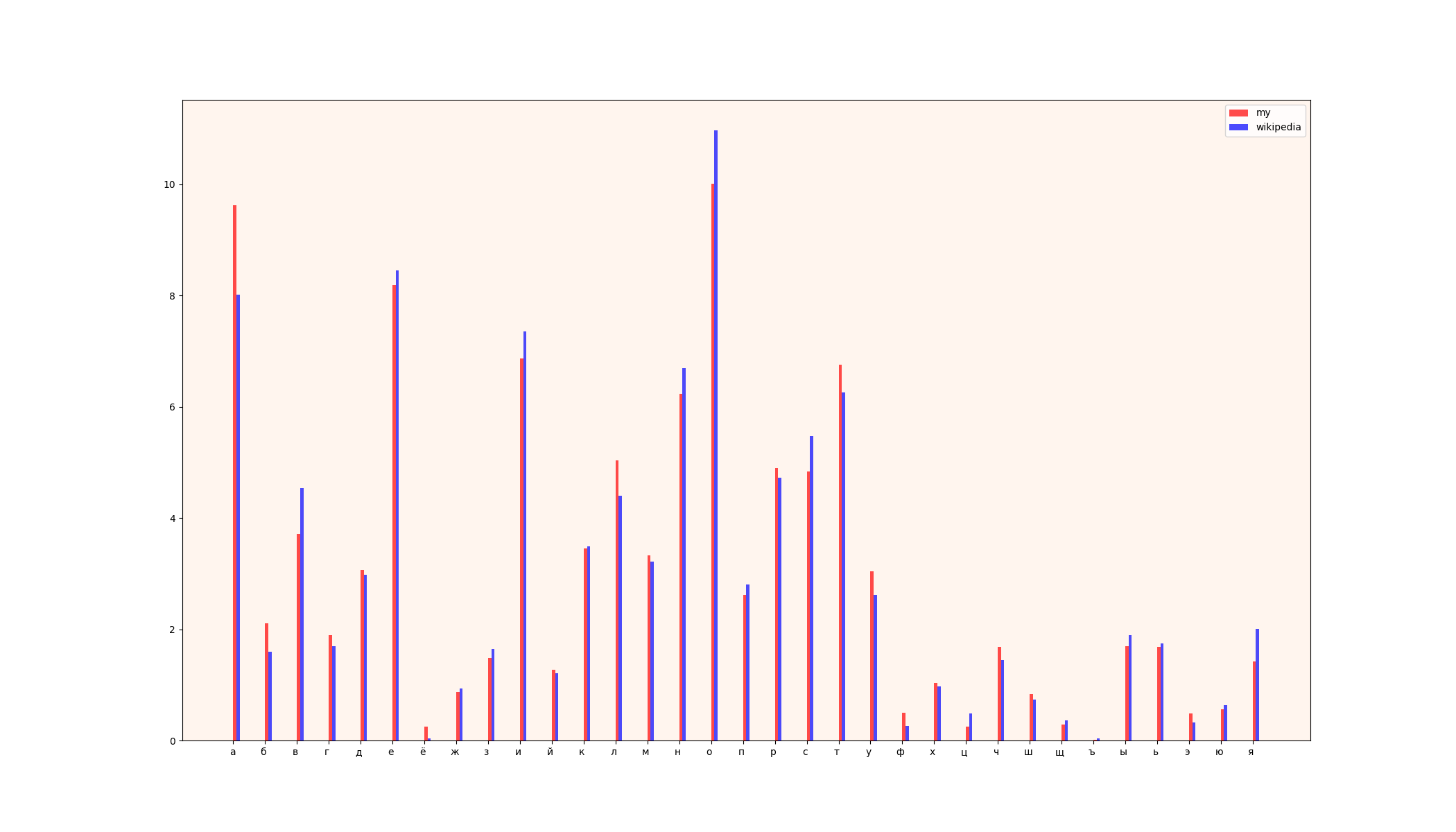
2) tablas (izquierda - datos de wikipedia, derecha - mis datos)
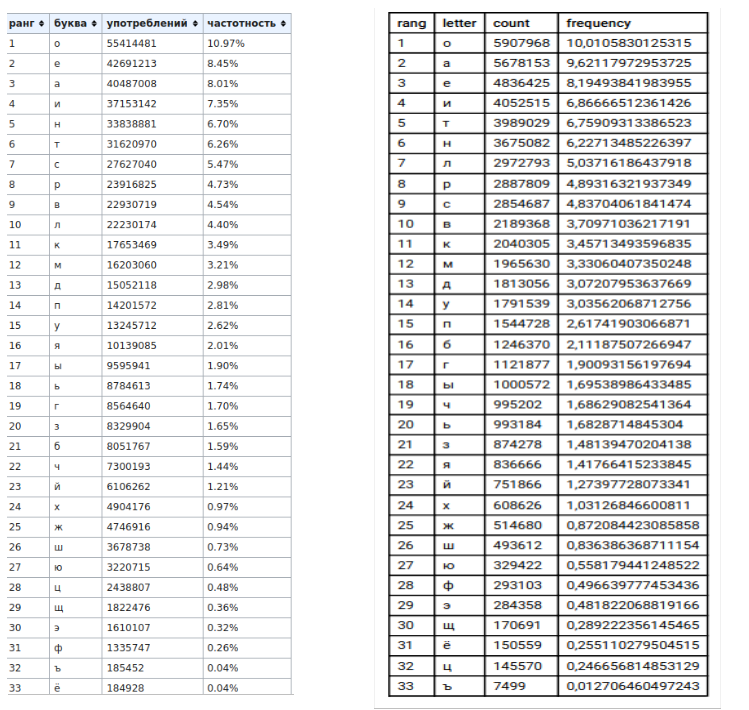
, , , «» «».
, , 2-4 :

, , , , , , , , ,
- . , — , , :
def caesar_cipher():
file = open("text.txt")
text_for_encrypt = file.read().lower().replace(',', '')
letters = ''
arr = []
step = 3
for i in text_for_encrypt:
if i == ' ':
arr.append(' ')
else:
arr.append(letters[(letters.find(i) + step) % 33])
text_for_decrypt = ''.join(arr)
return text_for_decrypt
:
def decrypt_text(text_for_decrypt, arr_decrypt_letters):
arr_encrypt_text = []
arr_encrypt_letters = [' ', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '',
'', '', '']
dictionary = dict(zip(arr_decrypt_letters, arr_encrypt_letters))
for i in text_for_decrypt:
arr_encrypt_text.append(dictionary.get(i))
text_for_decrypt = ''.join(arr_encrypt_text)
print(text_for_decrypt)
Si miras el texto descifrado, puedes adivinar dónde salió mal nuestro algoritmo: peleas → hace, vadio → radio, toho → además, abrumar → gente. Así, es posible descifrar todo el texto, al menos para captar el significado del texto. También quiero señalar que este método será eficaz para descifrar solo textos largos que se hayan cifrado con métodos de cifrado simétrico. El código completo está disponible en Github .