
Hoy les contaré un poco sobre mis pensamientos sobre la conmutación por error de tarantool / cartucho. Primero, algunas palabras sobre lo que es el cartucho: este es un fragmento de código lua que funciona dentro de tarantool y combina tarántulas entre sí en un "grupo" condicional. Esto se debe a dos cosas:
- cada tarántula conoce las direcciones de red de todas las demás tarántulas;
- las tarántulas regularmente se "hacen ping" entre sí a través de UDP para comprender quién está vivo y quién no. Aquí intencionalmente simplifico un poco, el algoritmo de ping es más complicado que solo solicitud-respuesta, pero esto no es muy importante para el análisis. Si está interesado, busque en Google el algoritmo SWIM.
Dentro de un clúster, todo se suele dividir en tarántulas con estado (maestra / réplica) y sin estado (enrutador). Las tarántulas sin estado son responsables de almacenar datos y las tarántulas sin estado son responsables de enrutar las solicitudes.
Así es como se ve en la imagen:
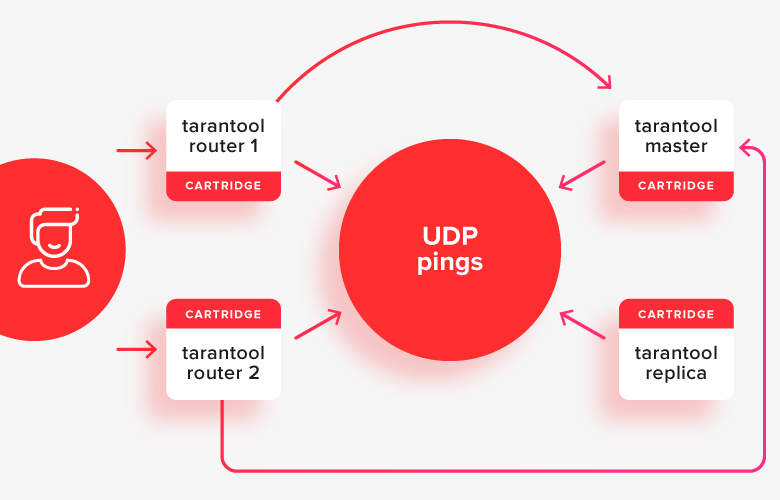
el cliente realiza solicitudes a cualquiera de los enrutadores activos y ellos redirigen las solicitudes a una de las tiendas, que ahora es el maestro activo. En la imagen, estos caminos se muestran con flechas.
Ahora no quiero complicar e introducir fragmentos en la conversación sobre la elección de un líder, pero la situación con él será un poco diferente. La única diferencia es que el enrutador aún debe decidir qué conjunto de réplicas usar de la tienda.
Primero, hablemos de cómo los nodos aprenden las direcciones de los demás. Para ello, cada uno de ellos tiene un archivo yaml en el disco con la topología del cluster, es decir, con información sobre las direcciones de red de todos los miembros, y quién de ellos es quién (con o sin estado). Más personalización potencialmente adicional, pero por ahora, dejemos eso de lado. Los archivos de configuración contienen la configuración de todo el clúster como un todo y son los mismos para cada tarántula. Si se les hacen cambios, entonces se hacen sincrónicamente para todas las tarántulas.
Ahora los cambios de configuración se pueden realizar a través de la API de cualquiera de las tarántulas del cluster: se conectará a todos los demás, les enviará una nueva versión de la configuración, todos la aplicarán, y en todas partes habrá una nueva versión, lo mismo nuevamente.
Escenario: fallo de nodo, conmutación
En una situación en la que falla un enrutador, todo es más o menos simple: el cliente solo necesita ir a cualquier otro enrutador activo, y entregará la solicitud a la tienda deseada. Pero, ¿y si, por ejemplo, cayera el amo de uno de los Storaja?
Ahora mismo hemos implementado un algoritmo "ingenuo" para tal caso, que se basa en el ping UDP. Si la réplica no “ve” las respuestas del maestro al ping durante un período corto de tiempo, considera que el maestro ha caído y se convierte en el maestro mismo, cambiando al modo de lectura-escritura de solo lectura. Los enrutadores actúan de la misma manera: si no ven algún tiempo de respuesta de ping del maestro, cambian el tráfico a la réplica.
Esto funciona relativamente bien en casos simples, excepto en una situación de "cerebro dividido", cuando la mitad de los nodos están separados de otros por algún tipo de problema de red:
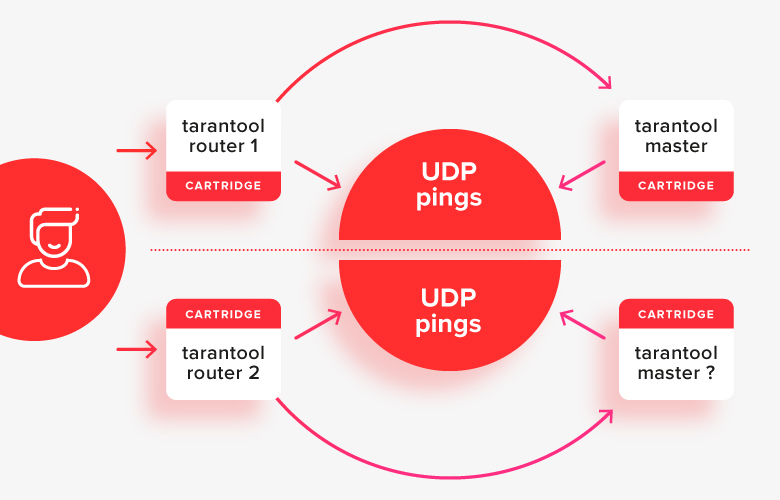
En esta situación, los enrutadores verán que la “otra mitad” del clúster no está disponible y considerarán que su mitad es la principal, y resulta que hay dos maestros en el sistema al mismo tiempo. Este es el primer caso importante que se resuelve.
Escenario: Editar configuración en caso de fallos
Otro escenario importante es reemplazar una tarántula fallida en un clúster por una nueva, o agregar nodos al clúster cuando una de las réplicas o enrutadores no está disponible.
Durante el funcionamiento normal, cuando todo en el clúster está disponible, podemos conectarnos vía API a cualquier nodo, pedirle que edite la configuración y, como dije anteriormente, el nodo "desplegará" la nueva configuración a todo el clúster.
Pero cuando alguien no está disponible, no puede aplicar la nueva configuración, porque cuando estos nodos vuelvan a estar disponibles, no estará claro cuál de ellos en el clúster tiene la configuración correcta y cuál no. Aún así, la inaccesibilidad de los nodos entre sí puede significar que hay un cerebro dividido entre ellos. Y editar la configuración es simplemente inseguro, porque puede editarla por error de diferentes maneras en diferentes mitades.
Por estas razones, ahora prohibimos editar la configuración a través de la API cuando alguien no está disponible. Solo se puede corregir en disco, mediante archivos de texto (manualmente). Aquí debes entender bien lo que estás haciendo y tener mucho cuidado: la automatización no te ayudará en nada.
Esto hace que la operación sea incómoda, y este es el segundo caso que debe resolverse.
Escenario: conmutación por error estable
Otro problema con el modelo de conmutación por error ingenuo es que el cambio de maestro a réplica en caso de falla del maestro no se registra en ninguna parte. Todos los nodos toman la decisión de cambiar por sí mismos y, cuando el maestro cobra vida, el tráfico lo cambiará de nuevo.
Esto puede ser un problema o no. Antes de encender el maestro, el maestro "se pondrá al día" con los registros transaccionales de la réplica, por lo que lo más probable es que no haya un retraso de big data. El problema será solo en el caso de que haya un problema en la red y haya una pérdida de paquetes: entonces lo más probable es que haya "parpadeo" periódico del maestro (aleteo).
La solución es un coordinador "fuerte" (etcd / consul / tarantool)
Para evitar problemas con un cerebro dividido y hacer posible editar la configuración cuando el clúster no está parcialmente disponible, necesitamos un coordinador fuerte que sea resistente a la segmentación de la red. El coordinador debe estar distribuido en 3 centros de datos para que, si alguno de ellos falla, siga funcionando.
Ahora hay 2 coordinadores populares basados en RAFT que usan etcd y consul para esto. Cuando aparece la replicación sincrónica en tarantool, también se puede utilizar para esto.
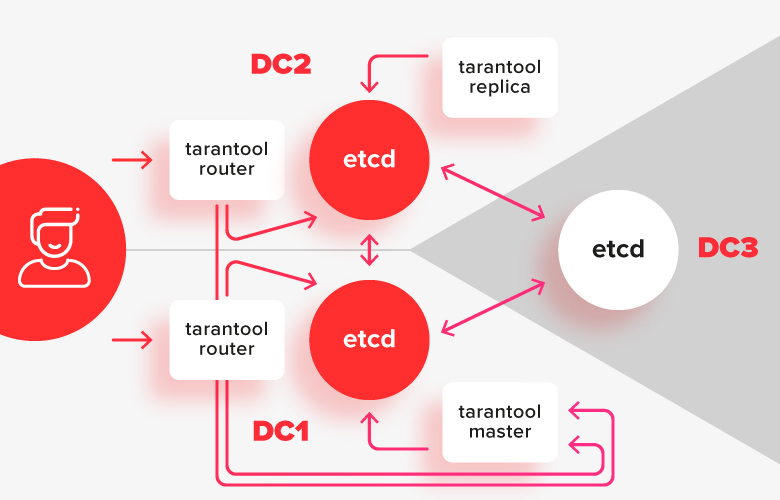
En este esquema, las instalaciones de tarántulas se dividen en dos centros de datos y están conectadas a su instalación local etcd. Una instancia de etcd en el tercer centro de datos sirve como árbitro para que en caso de falla de uno de los centros de datos, sea precisamente cuál de ellos quedó en la mayoría.
Gestión de la configuración con un coordinador fuerte
Como dije anteriormente, ante la ausencia de un coordinador y la falla de una de las tarántulas, no pudimos editar la configuración de manera centralizada, porque entonces es imposible decir qué configuración sobre cuál de los nodos es la correcta.
En el caso de un coordinador fuerte, todo es más simple: podemos almacenar la configuración en el coordinador, y cada instancia de la tarántula contendrá un caché de esta configuración en su sistema de archivos. Tras la conexión exitosa con el coordinador, actualizará su copia de la configuración a la del coordinador.
Editar la configuración también se vuelve más fácil: se puede hacer a través de la API de cualquier tarántula. Tomará el bloqueo en el coordinador, reemplazará los valores deseados en la configuración, esperará a que todos los nodos lo apliquen y liberará el bloqueo. Bueno, o como último recurso, puede editar la configuración en etcd manualmente y se aplicará a todo el clúster.
Será posible editar la configuración incluso si algunas tarántulas no están disponibles. Lo principal es que la mayoría de los nodos coordinadores están disponibles.
Conmutación por error con un coordinador sólido
La conmutación confiable de nodos con un coordinador se resuelve debido a que además de la configuración, almacenaremos en el coordinador información sobre quién es el maestro actual en la réplica y dónde se realizaron los conmutadores.
El algoritmo de conmutación por error cambia de la siguiente manera:
- «» .
- UDP-, - , .
- , .
- .
- , read-only read-write.
- , , .
Con un coordinador, también es posible la protección de aleteo. En el coordinador, puede registrar todo el historial de conmutación, y si durante los últimos X minutos el maestro cambió a una réplica, la conmutación inversa solo la realiza explícitamente el administrador.
Otro punto importante es el llamado "Esgrima". Las tarántulas que están aisladas de otros centros de datos (o conectadas a un coordinador que ha perdido la mayoría) deben asumir que lo más probable es que el resto del clúster, al que se pierde el acceso, tenga la mayoría. Y eso significa que, dentro de un cierto tiempo, todos los nodos separados de la mayoría deben pasar a ser de solo lectura.
Problema de indisponibilidad del coordinador
Mientras discutíamos los enfoques para trabajar con el coordinador, recibimos una solicitud para asegurarnos de que si el coordinador se cae, pero todas las tarántulas están intactas, no traduzca todo el grupo en solo lectura.
Al principio parecía que no era muy realista hacer esto, pero luego recordamos que el propio clúster monitorea la disponibilidad de otros nodos a través de pings UDP. Esto significa que podemos apuntar a ellos y no activar la reelección del maestro dentro del conjunto de réplicas, si queda claro a través de los pings UDP que todo el conjunto de réplicas está activo.
Este enfoque le ayudará a preocuparse menos por la disponibilidad del coordinador, especialmente si necesita reiniciarlo, por ejemplo, para una actualización.
Planes de implementación
Ahora estamos recopilando comentarios y comenzando la implementación. Si tiene algo que decir, escriba en los comentarios o en un personal.
El plan es algo como esto:
- Hacer soporte etcd en tarantool [hecho]
- Conmutación por error usando etcd como coordinador, con estado [hecho]
- Conmutación por error con tarántula como coordinador, enclavamiento [hecho]
- Almacenando la configuración en etcd [en curso]
- Escribiendo herramientas CLI para la reparación de clústeres [en curso]
- Almacenar la configuración en la tarántula
- Gestión de clústeres cuando parte del clúster no está disponible
- Esgrima
- Protección de aleteo
- Conmutación por error utilizando cónsul como coordinador
- Almacenamiento de la configuración en cónsul
En el futuro, es casi seguro que abandonaremos el grupo por completo sin un coordinador fuerte. Lo más probable es que esto coincida con la implementación basada en RAFT de la replicación sincrónica en la tarántula.
Expresiones de gratitud
Gracias a los desarrolladores y administradores de Mail.ru por los comentarios, las críticas y las pruebas proporcionadas.