
Fuente: Vecteezy
Sí, la regresión lineal no es la única.
Nombre rápidamente cinco algoritmos de aprendizaje automático.
Es poco probable que nombre muchos algoritmos de regresión. Después de todo, el único algoritmo de regresión ampliamente utilizado es la regresión lineal, principalmente debido a su simplicidad. Sin embargo, la regresión lineal a menudo es inaplicable a datos reales debido a opciones demasiado limitadas y libertad de maniobra limitada. A menudo se utiliza solo como modelo de base para la evaluación y comparación con nuevos enfoques de investigación.
Equipo de soluciones en la nube de Mail.rutradujo un artículo, cuyo autor describe 5 algoritmos de regresión. Vale la pena tenerlos en su caja de herramientas junto con algoritmos de clasificación populares como SVM, árbol de decisión y redes neuronales.
1. Regresión de la red neuronal
Teoría
Las redes neuronales son increíblemente poderosas, pero se usan comúnmente para la clasificación. Las señales viajan a través de capas de neuronas y se resumen en una de varias clases. Sin embargo, se pueden adaptar muy rápidamente a modelos de regresión cambiando la última función de activación.
Cada neurona transmite valores de la conexión anterior a través de una función de activación que tiene el propósito de generalizar y no linealizar. Por lo general, la función de activación es algo así como una función sigmoidea o ReLU (unidad lineal rectificada).
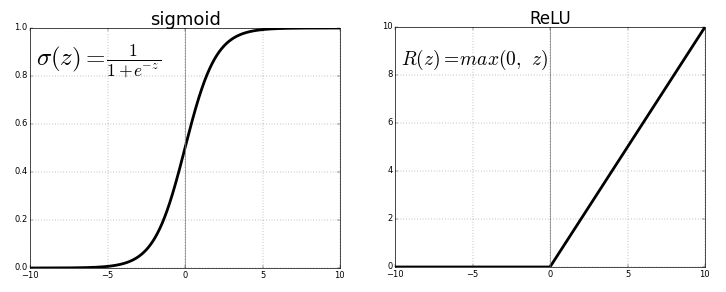
Fuente . Imagen libre
Pero, reemplazando la última función de activación (neurona de salida) por una linealla función de activación, la señal de salida se puede asignar a muchos valores fuera de las clases fijas. Por lo tanto, la salida no será la probabilidad de asignar la señal de entrada a cualquier clase, sino un valor continuo en el que la red neuronal fija sus observaciones. En este sentido, podemos decir que la red neuronal complementa la regresión lineal.
La regresión de la red neuronal tiene la ventaja de la no linealidad (además de la complejidad) que se puede introducir con funciones de activación sigmoidea y no lineal antes en la red neuronal. Sin embargo, el uso excesivo de ReLU como función de activación puede significar que el modelo tiende a evitar generar valores negativos, ya que ReLU ignora las diferencias relativas entre valores negativos.
Esto se puede resolver limitando el uso de ReLU y agregando más valores negativos de las funciones de activación correspondientes, o normalizando los datos a un rango estrictamente positivo antes del entrenamiento.
Implementación
Usando Keras, construyamos la estructura de una red neuronal artificial, aunque lo mismo se podría hacer con una red neuronal convolucional u otra red si la última capa es una capa densa con activación lineal o simplemente una capa con activación lineal. ( Tenga en cuenta que las importaciones de Keras no se enumeran para ahorrar espacio ).
model = Sequential()
model.add(Dense(100, input_dim=3, activation='sigmoid'))
model.add(ReLU(alpha=1.0))
model.add(Dense(50, activation='sigmoid'))
model.add(ReLU(alpha=1.0))
model.add(Dense(25, activation='softmax'))
#IMPORTANT PART
model.add(Dense(1, activation='linear'))
El problema con las redes neuronales siempre ha sido su gran variación y tendencia a sobreajustarse. Hay muchas fuentes de no linealidad en el ejemplo de código anterior como SoftMax o sigmoide.
Si su red neuronal hace un buen trabajo con los datos de entrenamiento con una estructura puramente lineal, podría ser mejor usar la regresión de árbol de decisión truncado, que emula una red neuronal lineal y altamente dispersa, pero permite al científico de datos tener un mejor control sobre la profundidad, el ancho y otros atributos para controlar el sobreajuste.
2. Regresión del árbol de decisiones
Teoría
Los árboles de decisión en clasificación y regresión son muy similares en que funcionan construyendo árboles con nodos sí / no. Sin embargo, mientras que los nodos hoja de clasificación dan como resultado un valor de clase único (por ejemplo, 1 o 0 para un problema de clasificación binaria), los árboles de regresión terminan con un valor en modo continuo (por ejemplo, 4593.49 o 10.98).
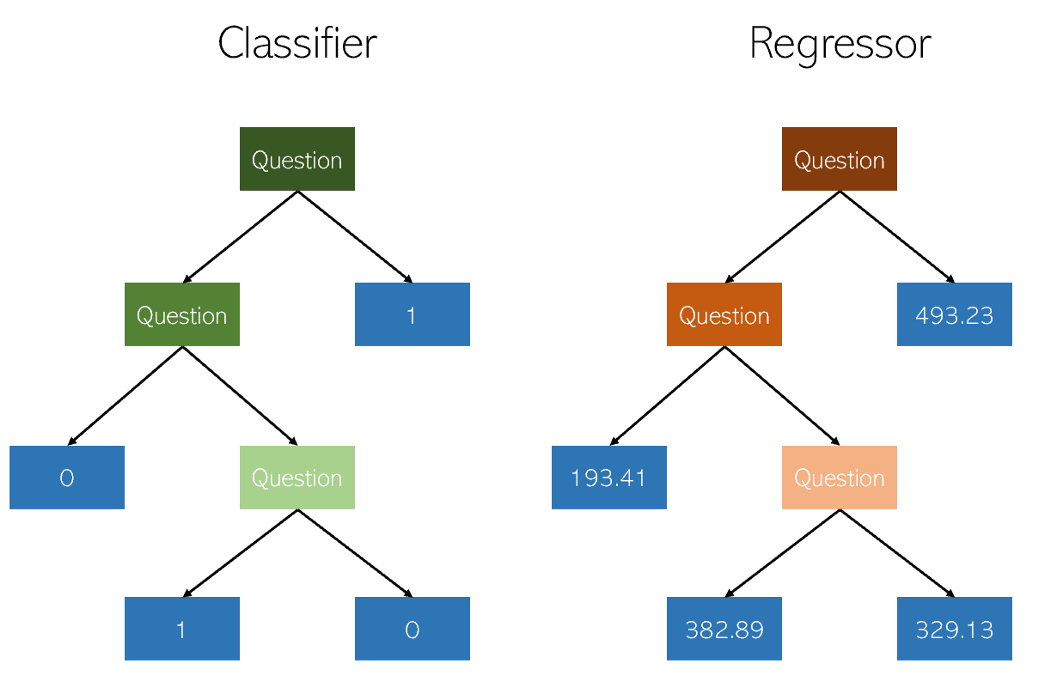
Ilustración del autor
Debido a la naturaleza específica y altamente dispersa de la regresión como un mero problema de aprendizaje automático, los regresores de árboles de decisión deben podarse cuidadosamente. Sin embargo, el enfoque de regresión es irregular: en lugar de calcular el valor en una escala continua, llega a los nodos finales dados. Si el regresor se recorta demasiado, tiene muy pocos nodos de hojas para cumplir adecuadamente su propósito.
En consecuencia, el árbol de decisión debe podarse para que tenga la mayor libertad (los posibles valores de salida de la regresión son el número de nodos de hoja), pero no lo suficiente como para ser demasiado profundo. Si no lo recorta, el algoritmo ya altamente disperso se volverá demasiado complejo debido a la naturaleza de la regresión.
Implementación
La regresión del árbol de decisiones se puede crear fácilmente en
sklearn:
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor()
model.fit(X_train, y_train)
Dado que los parámetros de la variable independiente árbol de decisión muy importante, se recomienda utilizar una herramienta de optimización de los parámetros del motor de búsqueda
GridCVde sklearn, para encontrar la recomendación adecuada para este modelo.
Al evaluar el desempeño formalmente, utilice pruebas en
K-foldlugar de pruebas estándar train-test-splitpara evitar la aleatoriedad de estas últimas que podrían violar los resultados sensibles de un modelo de alta varianza.
Prima: Un pariente cercano del árbol de decisión, el algoritmo de bosque aleatorio, también se puede implementar como regresor. Un regresor de bosque aleatorio puede o no funcionar mejor que un árbol de decisión en la regresión (aunque generalmente funciona mejor en la clasificación) debido al delicado equilibrio entre la redundancia y la deficiencia en la naturaleza de los algoritmos de construcción de árboles.
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
model.fit(X_train, y_train)
3. Regresión LASSO
El método de regresión de lazo (LASSO, Operador de selección y contracción mínima absoluta) es una variación de la regresión lineal especialmente adaptada para datos que exhiben una fuerte multicolinealidad (es decir, una fuerte correlación de características entre sí).
Automatiza partes de la selección del modelo, como la selección de variables o la exclusión de parámetros. LASSO utiliza la contracción, que es un proceso en el que los valores de los datos se acercan a un punto central (como un promedio).

Ilustración del autor. Visualización simplificada del
proceso de compresión El proceso de compresión agrega varias ventajas a los modelos de regresión:
- Estimaciones más precisas y estables de parámetros reales.
- Reducir los errores de muestreo y la falta de muestreo.
- Suavizado de fluctuaciones espaciales.
En lugar de ajustar la complejidad del modelo para compensar la complejidad de los datos, como la red neuronal de alta varianza y los métodos de regresión del árbol de decisión, el lazo intenta reducir la complejidad de los datos para que puedan manejarse mediante métodos de regresión simples al curvar el espacio en el que se encuentra. En este proceso, el lazo ayuda automáticamente a eliminar o distorsionar características altamente correlacionadas y redundantes en un método de baja variación.
La regresión de lazo utiliza la regularización L1, es decir, pondera los errores por su valor absoluto. En lugar de, por ejemplo, la regularización L2, que pondera los errores por su cuadrado, para castigar con más fuerza los errores más significativos.
Esta regularización a menudo conduce a modelos más dispersos con menos coeficientes, ya que algunos coeficientes pueden volverse cero y, por lo tanto, ser excluidos del modelo. Esto permite que se interprete.
Implementación
El
sklearnlazo de regresión viene con un modelo de validación cruzada que selecciona el más efectivo de los muchos modelos entrenados con diferentes parámetros fundamentales y rutas de aprendizaje que automatiza una tarea que de otro modo tendría que realizarse manualmente.
from sklearn.linear_model import LassoCV
model = LassoCV()
model.fit(X_train, y_train)
4. Regresión de crestas (regresión de crestas)
Teoría
La regresión de crestas o regresión de crestas es muy similar a la regresión LASSO en que aplica compresión. Ambos algoritmos son adecuados para conjuntos de datos con una gran cantidad de características que no son independientes entre sí (colinealidad).
Sin embargo, la mayor diferencia entre ellos es que la regresión de la cresta usa la regularización L2, es decir, ninguno de los coeficientes no se vuelve cero, como es la regresión LASSO. En cambio, los coeficientes se acercan cada vez más a cero, pero tienen pocos incentivos para lograrlo debido a la naturaleza de la regularización L2.
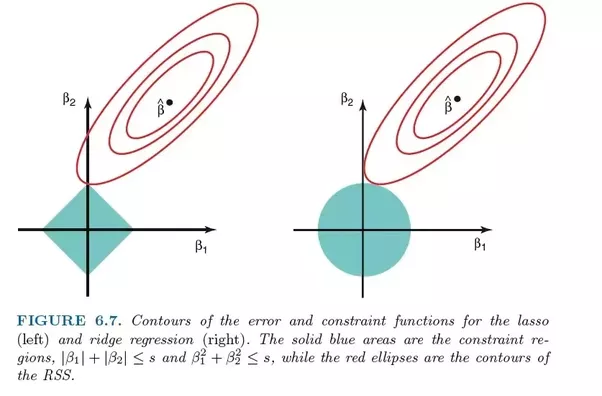
Comparación de errores en regresión de lazo (izquierda) y regresión de cresta (derecha). Dado que Ridge Regression usa la regularización L2, su área se asemeja a un círculo, mientras que la regularización de lazo L1 dibuja líneas rectas. Imagen libre. Fuente
En el lazo, la mejora del error 5 al error 4 se pondera de la misma manera que la mejora de 4 a 3, y también de 3 a 2, de 2 a 1 y de 1 a 0. Por tanto, más coeficientes llegan a cero y se eliminan más características.
Sin embargo, en la regresión de la cresta, la mejora del error 5 al error 4 se calcula como 5² - 4² = 9, mientras que la mejora de 4 a 3 se pondera sólo como 7. Gradualmente, la recompensa por la mejora disminuye; por lo tanto, se eliminan menos funciones.
La regresión de crestas es más adecuada para situaciones en las que queremos priorizar una gran cantidad de variables, cada una de las cuales tiene un efecto pequeño. Si su modelo necesita tener en cuenta múltiples variables, cada una de las cuales tiene un efecto de mediano a grande, el lazo es la mejor opción.
Implementación
La regresión de crestas
sklearnse puede implementar de la siguiente manera (ver más abajo). Al igual que con la regresión de lazo, sklearnexiste una implementación para validar de forma cruzada la selección del mejor de muchos modelos entrenados.
from sklearn.linear_model import RidgeCV
model = Ridge()
model.fit(X_train, y_train)
5. Regresión de ElasticNet
Teoría
ElasticNet tiene como objetivo combinar lo mejor de Ridge Regression y Lasso Regression combinando la regularización L1 y L2.
Lasso y Ridge Regression son dos métodos de regularización diferentes. En ambos casos, λ es el factor clave que controla el tamaño de la multa:
- λ = 0, , .
- λ = ∞, - . , , .
- 0 < λ < ∞, λ , .
Al parámetro λ, la regresión de ElasticNet agrega un parámetro adicional α , que mide qué tan "mezcladas" deben ser las regularizaciones L1 y L2. Cuando α es 0, el modelo es pura regresión de cresta, y cuando α es 1, es pura regresión de lazo.
El “factor de mezcla” α simplemente define cuánta regularización L1 y L2 se debe considerar en la función de pérdida. Los tres modelos de regresión populares (Ridge, Lasso y ElasticNet) tienen como objetivo reducir el tamaño de sus coeficientes, pero cada uno actúa de manera diferente.
Implementación
ElasticNet se puede implementar utilizando el modelo de validación cruzada de sklearn:
from sklearn.linear_model import ElasticNetCV
model = ElasticNetCV()
model.fit(X_train, y_train)
Qué más leer sobre el tema: