
Este artículo recopila algunos patrones comunes para ayudar a los ingenieros a trabajar con servicios a gran escala que están solicitando millones de usuarios.
Según la experiencia del autor, esta no es una lista exhaustiva, sinoconsejosrealmente efectivos . Vamos a empezar.
Traducido con el apoyo de Mail.ru Cloud Solutions .
Primer nivel
Las medidas que se enumeran a continuación son relativamente fáciles de implementar, pero producen altos rendimientos. Si no los ha probado antes, se sorprenderá con las importantes mejoras.
Infraestructura como código
El primer consejo es implementar la infraestructura como código. Esto significa que debe tener una forma programática de implementar toda su infraestructura. Suena complicado, pero en realidad estamos hablando del siguiente código:
Implementar 100 máquinas virtuales
- con Ubuntu
- 2 GB de RAM cada uno
- ellos tendrán el siguiente código
- con tales parámetros
Puede rastrear y revertir los cambios de infraestructura rápidamente usando el control de fuente.
El modernista que hay en mí dice que puedes usar Kubernetes / Docker para hacer todo lo anterior, y tiene razón.
Alternativamente, puede proporcionar automatización con Chef, Puppet o Terraform.
Integración y entrega continuas
Para crear un servicio escalable, es importante tener una canalización de compilación y prueba para cada solicitud de extracción. Incluso si la prueba es la más simple, al menos garantizará que el código que implemente se compile.
Cada vez en esta etapa, está respondiendo a la pregunta: ¿mi ensamblado compilará y pasará las pruebas, es válido? Esto puede parecer una barra baja, pero resuelve muchos problemas.
No hay nada más hermoso que ver estas casillas de verificación.
Para esta tecnología, puede consultar Github, CircleCI o Jenkins.
Equilibradores de carga
Por lo tanto, queremos iniciar un equilibrador de carga para redirigir el tráfico y asegurarnos de que la carga en todos los nodos sea igual o que el servicio funcione en caso de falla:
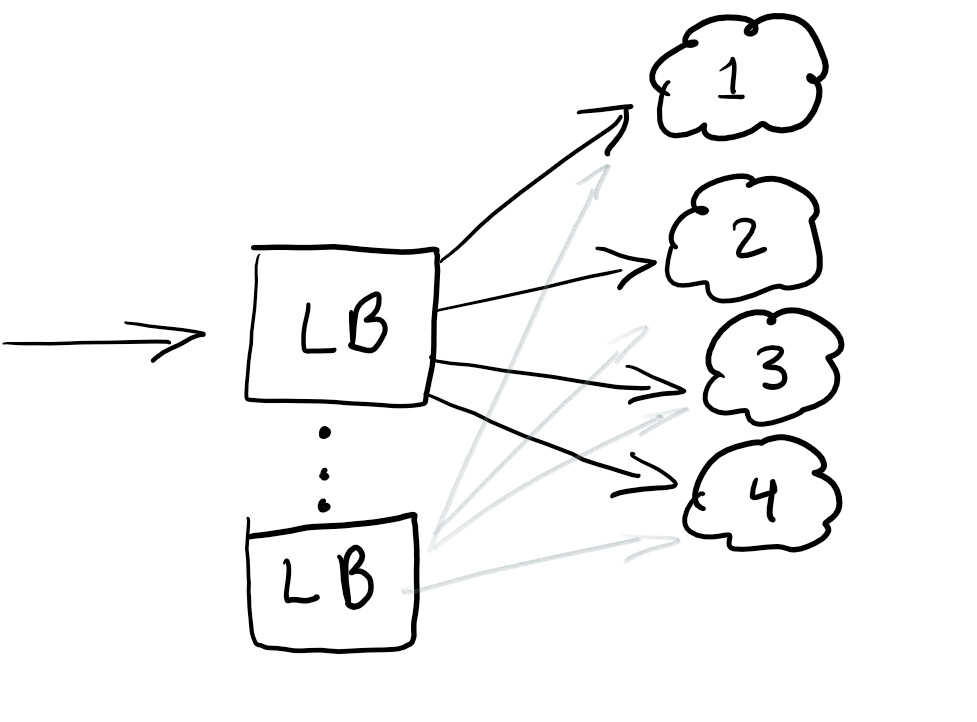
Un equilibrador de carga generalmente es bueno para ayudar a distribuir el tráfico. La mejor práctica es sobrebalancear para que no tenga un solo punto de falla.
Por lo general, los balanceadores de carga se configuran en la nube que está utilizando.
RayID, ID de correlación o UUID para solicitudes
¿Alguna vez ha encontrado un error en una aplicación con un mensaje como este: “Algo salió mal. Guarde esta identificación y envíela a nuestro equipo de soporte ” ?
Identificador único, ID de correlación, RayID o cualquiera de las variaciones, es un identificador único que le permite rastrear una solicitud a lo largo de su ciclo de vida. Esto le permite realizar un seguimiento de la ruta completa de la solicitud en los registros.
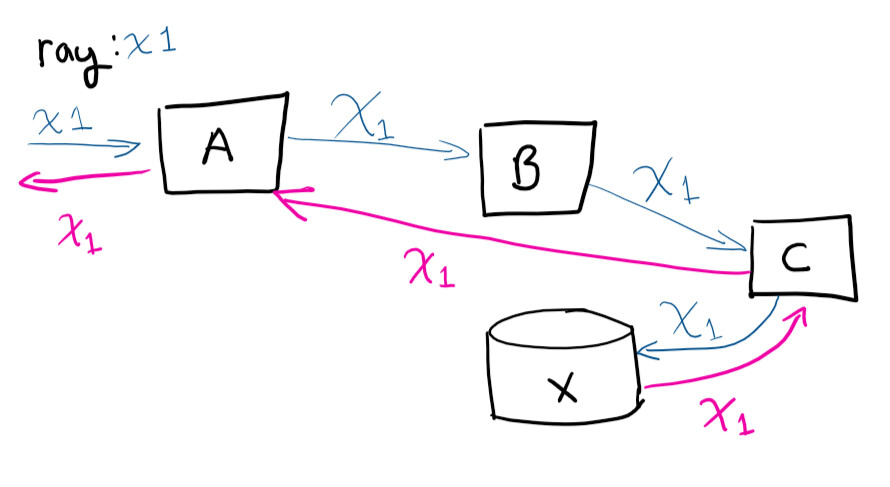
El usuario realiza una solicitud al sistema A, luego A contacta con B, que contacta con C, guarda en X, y luego la solicitud regresa a A
Si tuviera que conectarse de forma remota a máquinas virtuales e intentara rastrear la ruta de la solicitud (y correlacionar manualmente qué llamadas están ocurriendo), te volverías loco. Tener un identificador único hace la vida mucho más fácil. Esta es una de las cosas más fáciles de hacer para ahorrar tiempo a medida que crece su servicio.
Nivel medio
El asesoramiento aquí es más complejo que los anteriores, pero las herramientas adecuadas facilitan la tarea, proporcionando un retorno de la inversión incluso para las pequeñas y medianas empresas.
Registro centralizado
¡Felicidades! Ha implementado 100 máquinas virtuales. Al día siguiente, el CEO entra y se queja de un error que recibió mientras probaba el servicio. Informa la identificación correspondiente de la que hablamos anteriormente, pero tendrá que buscar en los registros de 100 máquinas para encontrar la que causó el bloqueo. Y necesita que la encuentren antes de la presentación de mañana.
Si bien esto suena como una aventura divertida, es mejor asegurarse de tener la capacidad de buscar todas las revistas desde un solo lugar. Resolví el problema de centralizar los registros con la funcionalidad incorporada de la pila ELK: admite la recopilación de registros con capacidad de búsqueda. Esto realmente ayudará a resolver el problema de encontrar un registro específico. Como beneficio adicional, puede crear diagramas y otras cosas divertidas como esa.
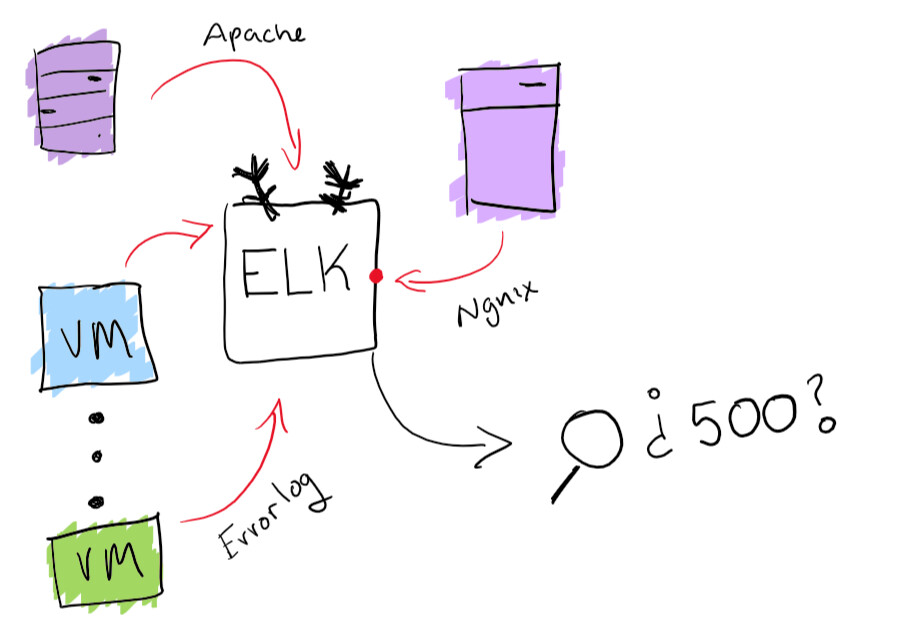
Funcionalidad de pila ELK
Agentes de seguimiento
Ahora que su servicio está en funcionamiento, debe asegurarse de que funcione sin problemas. La mejor manera de hacerlo es ejecutar varios agentes que se ejecutan en paralelo y verificar que se estén ejecutando y que se realicen las operaciones básicas.
En este punto, verifica que el ensamblaje en ejecución funciona bien y funciona bien .
Para proyectos pequeños y medianos, recomiendo Postman para monitorear y documentar API. Pero, en general, solo debe asegurarse de tener una forma de saber cuándo ha ocurrido una falla y recibir alertas oportunas.
Ajuste de escala automático basado en la carga
Es muy sencillo. Si tiene una máquina virtual que atiende solicitudes y se acerca al 80% de uso de memoria, puede aumentar sus recursos o agregar más máquinas virtuales al clúster. La ejecución automática de estas operaciones es excelente para cambios de potencia elásticos bajo carga. Pero siempre debe tener cuidado con la cantidad de dinero que gasta y establecer límites razonables.
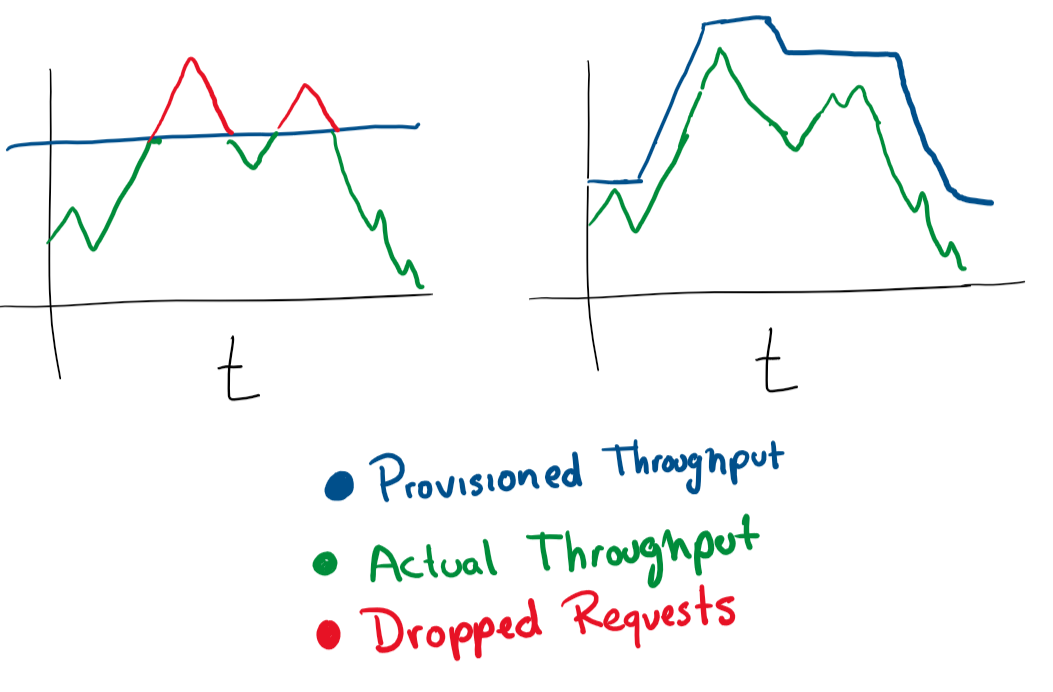
En la mayoría de los servicios en la nube, puede configurar el escalado automático con más servidores o servidores más potentes.
Sistema de experimentación
Una buena forma de implementar actualizaciones de forma segura es poder probar algo para el 1% de los usuarios en una hora. Ciertamente ha visto estos mecanismos en acción. Por ejemplo, Facebook muestra partes de la audiencia con un color diferente o cambia el tamaño de la fuente para ver cómo los usuarios perciben el cambio. Esto se llama prueba A / B.
Incluso el lanzamiento de una nueva función se puede ejecutar como un experimento y luego descubrir cómo lanzarlo. También tiene la capacidad de "recordar" o cambiar la configuración sobre la marcha, teniendo en cuenta la función que provoca la degradación de su servicio.
Nivel avanzado
Aquí hay algunos consejos que son bastante difíciles de implementar. Probablemente necesitará un poco más de recursos, por lo que será difícil para una empresa pequeña o mediana manejar esto.
Implementaciones azul-verde
Esto es lo que yo llamo el método de implementación "Erlang". Erlang fue ampliamente utilizado cuando aparecieron las compañías telefónicas. Se han utilizado interruptores suaves para enrutar llamadas telefónicas. El enfoque principal del software en estos conmutadores era no interrumpir las llamadas durante las actualizaciones del sistema. Erlang tiene una excelente manera de cargar un nuevo módulo sin fallar el anterior.
Este paso depende de la presencia de un equilibrador de carga. Supongamos que tiene la versión N de su software y luego desea implementar la versión N + 1.
Usted podría simplemente detener el servicio y desplegar la próxima versión a la vez que es conveniente para sus usuarios y conseguir un poco de tiempo de inactividad. Pero suponga que tienetérminos de SLA realmente estrictos. Por lo tanto, SLA 99,99% significa que puede desconectarse solo 52 minutos al año.
Si realmente desea lograr esto, necesita dos implementaciones al mismo tiempo:
- el que está ahora mismo (N);
- próxima versión (N + 1).
Le dice al balanceador de carga que redirija un porcentaje del tráfico a la nueva versión (N + 1) mientras usted mismo realiza un seguimiento activo de las regresiones.
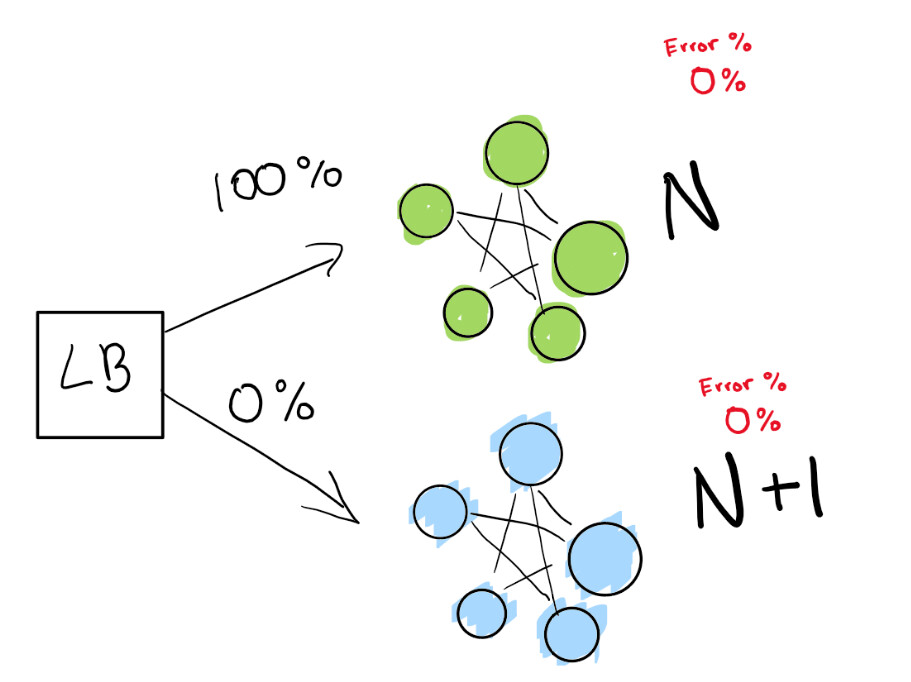
Aquí tenemos una implementación verde N que funciona bien. Estamos intentando pasar a la siguiente versión de esta implementación.
Primero, enviamos una pequeña prueba para ver si nuestra implementación N + 1 funciona con poco tráfico:
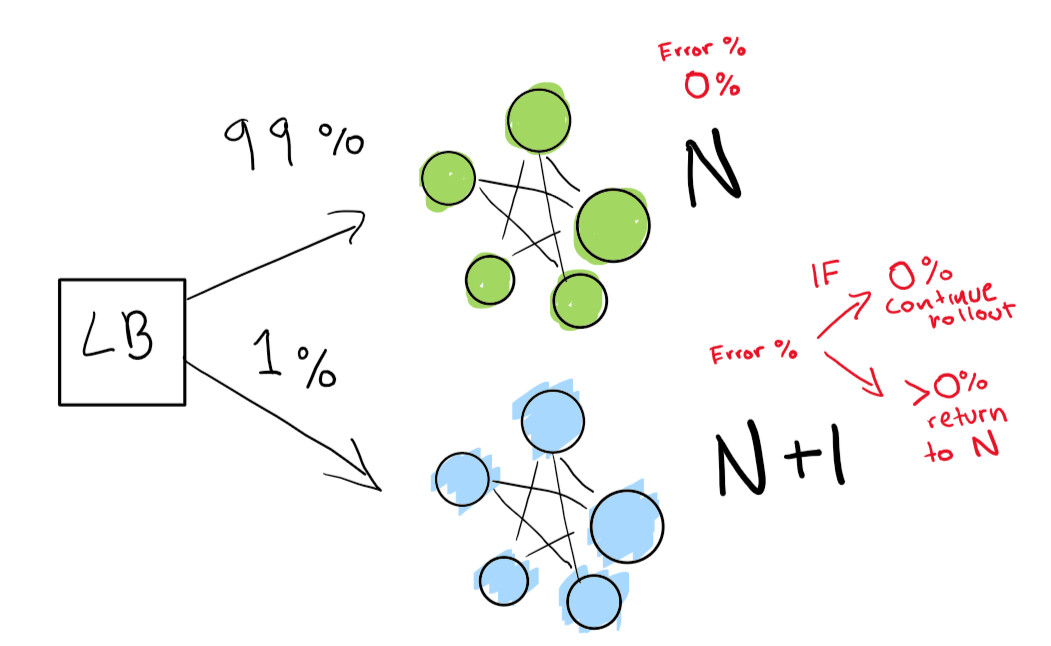
Finalmente, tenemos un conjunto de verificaciones automatizadas que terminamos ejecutando hasta que se completa nuestra implementación. Si tiene mucho, mucho cuidado, también puede mantener su implementación de N para siempre para una reversión rápida en caso de una mala regresión:
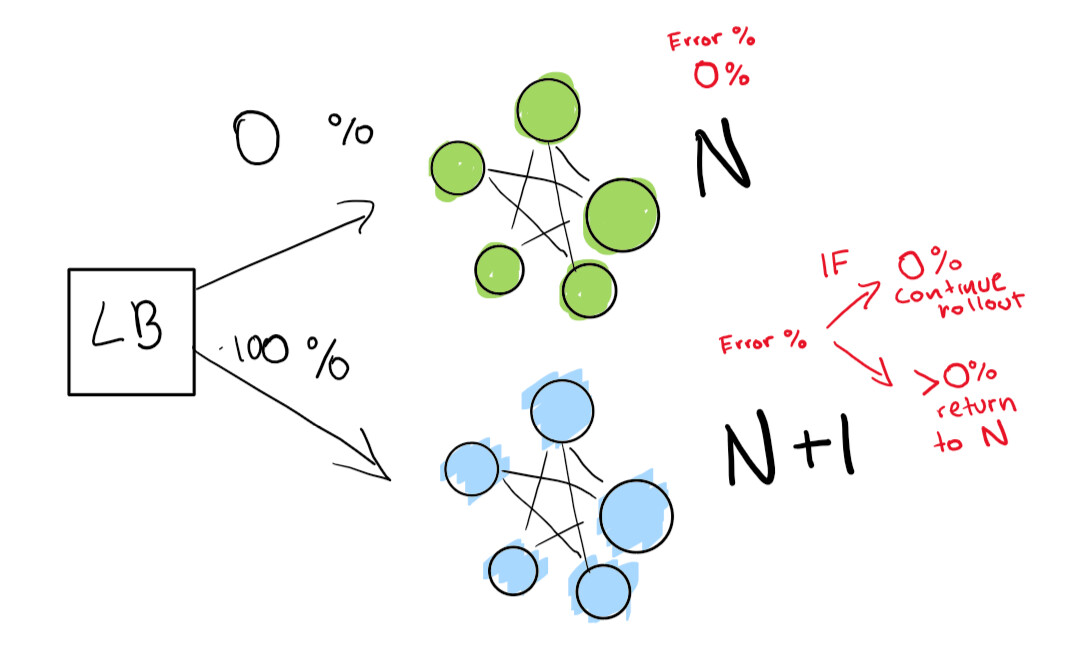
Si desea pasar a un nivel aún más avanzado, deje que todo en la implementación azul-verde se haga automáticamente.
Detección de anomalías y mitigación automática
Dado que tiene un registro centralizado y una buena recopilación de registros, ya puede establecer objetivos más altos. Por ejemplo, predecir fallas de manera proactiva. En los monitores y en los registros, se realiza un seguimiento de las funciones y se crean varios diagramas, y puede predecir de antemano lo que saldrá mal:
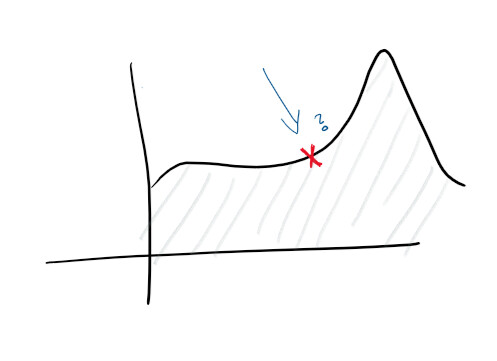
Con el descubrimiento de anomalías, comienza a estudiar algunas de las pistas que emite el servicio. Por ejemplo, un aumento en el uso de la CPU podría sugerir que un disco duro está fallando, mientras que un aumento en las solicitudes significa que debe escalar. Este tipo de estadísticas nos permite hacer que el servicio sea proactivo.
Con esta información, puede escalar en cualquier dimensión, cambiar de forma proactiva y reactiva las características de las máquinas, las bases de datos, las conexiones y otros recursos.
¡Eso es todo!
Esta lista de prioridades le ahorrará muchos problemas si está abriendo un servicio en la nube.
El autor del artículo original invita a los lectores a dejar sus comentarios y realizar cambios. El artículo se distribuye como código abierto, el autor acepta solicitudes de extracción en Github .
Qué más leer sobre el tema: