Si ha estado diseñando aplicaciones backend o bases de datos durante un tiempo, probablemente haya escrito código para ejecutar consultas paginadas. Por ejemplo, así:
SELECT * FROM table_name LIMIT 10 OFFSET 40
¿Cómo es?
Pero si así es como hizo la paginación, lamento señalar que no lo hizo de la manera más eficiente.
¿Quieres discutir conmigo? Usted no tiene que perder el tiempo . Slack , Shopify y Mixmax ya están usando los trucos de los que quiero hablar hoy.
Nombra al menos un backend de desarrollador, que nunca usó
OFFSETy LIMITpara realizar consultas con paginación. En MVP (producto mínimo viable, producto mínimo viable) y en proyectos que utilizan pequeñas cantidades de datos, este enfoque es bastante aplicable. Simplemente funciona, por así decirlo.
Pero si necesita crear sistemas confiables y eficientes desde cero, debe cuidar de antemano la eficiencia de las consultas a las bases de datos utilizadas en dichos sistemas.
Hoy hablaremos sobre los problemas asociados con implementaciones ampliamente utilizadas (lo siento) de motores de ejecución de consultas paginadas, y cómo lograr un alto rendimiento al ejecutar dichas consultas.
¿Qué pasa con OFFSET y LIMIT?
Como se ha dicho,
OFFSETy LIMITse muestra perfectamente en proyectos que no necesitan trabajar con grandes cantidades de datos.
El problema surge cuando la base de datos crece a tal tamaño que deja de caber en la memoria del servidor. Sin embargo, mientras trabaja con esta base de datos, debe utilizar consultas paginadas.
Para que este problema se manifieste es necesario que surja una situación en la que el DBMS recurra a una operación de Full Table Scan ineficiente al ejecutar cada consulta con paginación (al mismo tiempo, pueden ocurrir operaciones de inserción y eliminación de datos ¡y no necesitamos datos obsoletos!).
¿Qué es una "exploración de tabla completa" (o "exploración de tabla secuencial", exploración secuencial)? Esta es una operación durante la cual el DBMS lee secuencialmente cada fila de la tabla, es decir, los datos contenidos en ella, y los compara con una condición dada. Se sabe que este tipo de escaneo de tablas es el más lento. El hecho es que cuando se ejecuta, se realizan muchas operaciones de E / S que utilizan el subsistema de disco del servidor. La situación se ve agravada por los retrasos asociados con el trabajo con datos almacenados en discos y el hecho de que la transferencia de datos del disco a la memoria es una operación que consume muchos recursos.
Por ejemplo, tiene registros de 100.000.000 de usuarios y está ejecutando una consulta con la construcción
OFFSET 50000000... Esto significa que el DBMS tendrá que cargar todos estos registros (¡y ni siquiera los necesitamos!), Colocarlos en la memoria y, después de eso, tomar, digamos, 20 resultados informados LIMIT.
Supongamos que podría verse como "seleccionar filas 50.000 a 50020 de 100.000". Es decir, el sistema primero necesitará cargar 50.000 filas para ejecutar la consulta. ¿Ves cuánto trabajo innecesario tiene que hacer?
Si no me cree, mire el ejemplo que creé usando db-fiddle.com .

Ejemplo en db-fiddle.com
Allí, a la izquierda, en el cuadro
Schema SQL, hay un código para insertar 100.000 filas en la base de datos, y a la derecha, en el cuadroQuery SQL, se muestran dos consultas. El primero, lento, se ve así:
SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
Y el segundo, que es una solución eficaz al mismo problema, así:
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
Para cumplir con estas solicitudes, simplemente haga clic en el botón
Runen la parte superior de la página. Una vez hecho esto, comparemos la información sobre el tiempo de ejecución de la consulta. Resulta que la ejecución de una consulta ineficiente toma al menos 30 veces más que la ejecución de la segunda (este tiempo difiere de un lanzamiento a otro, por ejemplo, el sistema puede informar que la primera solicitud tardó 37 ms en completarse, y ejecución del segundo - 1 ms).
Y si hay más datos, todo se verá aún peor (para verificar esto, mire mi ejemplo con 10 millones de filas).
Lo que acabamos de discutir debería darle una idea de cómo se manejan realmente las consultas de la base de datos.
Tenga en cuenta que cuanto mayor sea el valor
OFFSET - más tardará la solicitud.
¿Qué se debe usar en lugar de una combinación de OFFSET y LIMIT?
En lugar de una combinación
OFFSET, LIMITvale la pena usar una estructura construida de acuerdo con el siguiente esquema:
SELECT * FROM table_name WHERE id > 10 LIMIT 20
Es la ejecución de una consulta de paginación basada en Cursor.
En lugar de almacenar localmente actual
OFFSETy LIMITy enviarlos a cada solicitud, es necesario almacenar la última clave primaria recibida (por lo general - una ID) y LIMIT, como resultado, y se le pedirá que se asemeja lo anterior, declaró.
¿Por qué? El hecho es que al especificar explícitamente el identificador de la última línea leída, le indica a su DBMS dónde debe comenzar a buscar los datos que necesita. Además, la búsqueda, gracias al uso de la tecla, se realizará de manera eficiente, el sistema no tendrá que distraerse con líneas que estén fuera del rango especificado.
Echemos un vistazo a la siguiente comparación de rendimiento de diferentes consultas. Aquí hay una consulta ineficaz.
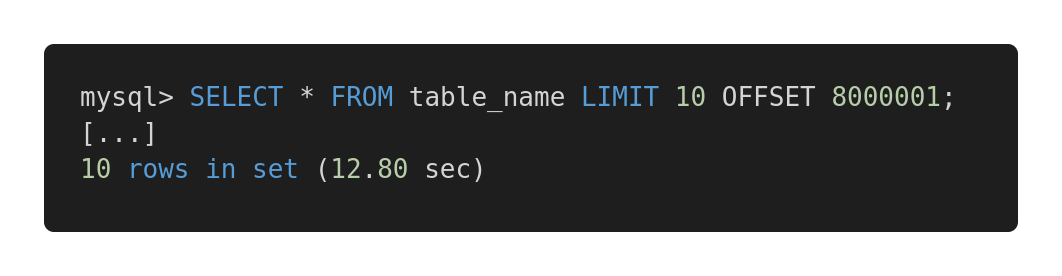
Consulta lenta
Y aquí hay una versión optimizada de esta consulta.

Consulta rápida
Ambas consultas devuelven exactamente la misma cantidad de datos. Pero el primero tarda 12,80 segundos y el segundo 0,01 segundos. ¿Sientes la diferencia?
Posibles problemas
Para que el método de ejecución de consultas propuesto funcione de manera eficiente, la tabla debe tener una columna (o columnas) que contengan índices secuenciales únicos, como un identificador de número entero. En algunos casos específicos, esto puede determinar el éxito de usar dichas consultas para aumentar la velocidad de trabajo con la base de datos.
Naturalmente, a la hora de diseñar consultas, es necesario tener en cuenta las peculiaridades de la arquitectura de las tablas y elegir aquellos mecanismos que mejor se muestren en las tablas existentes. Por ejemplo, si necesita trabajar en consultas con grandes cantidades de datos relacionados, este artículo puede resultarle interesante .
Si nos enfrentamos al problema de la ausencia de una clave primaria, por ejemplo, si hay una tabla con una relación de muchos a muchos, entonces el enfoque tradicional de usar
OFFSETy LIMITestá garantizado que funcionará para nosotros. Pero su aplicación puede conducir a la ejecución de consultas potencialmente lentas. En tales casos, recomendaría usar una clave principal de aumento automático, incluso si solo la necesita para organizar consultas paginadas.
Si está interesado en este tema, aquí , aquí y aquí , algunos materiales útiles.
Salir
La principal conclusión que podemos sacar es que siempre, independientemente del tamaño de las bases de datos de las que estemos hablando, necesitamos analizar la velocidad de ejecución de las consultas. En nuestro tiempo, la escalabilidad de las soluciones es extremadamente importante, y si diseña todo correctamente desde el comienzo del trabajo en un determinado sistema, esto, en el futuro, puede salvar al desarrollador de muchos problemas.
¿Cómo analiza y optimiza las consultas de la base de datos?
