
Mi nombre es Alexander Deulin, trabajo en el departamento de desarrollo de nuestro propio desarrollo "Factory of Microservices" en MegaFon. Y quiero contarles sobre el espinoso camino del surgimiento de los cachés de Tarantool en el panorama de nuestra empresa, así como también cómo implementamos la replicación desde Oracle. E inmediatamente explicaré que en este caso el caché significa una aplicación con una base de datos.
Caches de tarantool
Ya hemos hablado mucho sobre cómo implementamos la Facturación Unificada en MegaFon , no nos detendremos en esto en detalle, pero ahora el proyecto está en la etapa de finalización. Por tanto, solo un poco de estadística:
Con lo que abordamos nuestra tarea:
- 80 millones de suscriptores;
- 300 millones de perfiles de suscriptores;
- 2 mil millones de eventos transaccionales para cambiar el saldo por día;
- 250 TB de datos activos;
- > 8 PB de archivos;
- y todo esto se ubica en 5000 servidores en diferentes centros de datos.
Es decir, estamos hablando de un sistema muy cargado, en el que cada subsistema comenzó a atender a 80 millones de suscriptores. Si antes teníamos 7 instancias y escala horizontal condicional, ahora cambiamos al dominio. Solía haber un monolito, pero ahora tenemos DDD. El sistema está bien cubierto por la API, dividido en subsistemas, pero no en todas partes hay una caché. Ahora nos enfrentamos al hecho de que los subsistemas crean una carga cada vez mayor. Además, aparecen nuevos canales, que requieren brindarles 5000 solicitudes por segundo por operación con una latencia de 50 ms en el 95% de los casos, y asegurar una disponibilidad al nivel del 99,99%.
En paralelo, comenzamos a crear una arquitectura de microservicios.

Tenemos una capa separada de cachés, en la que se generan los datos de cada subsistema. Esto hace que los compuestos sean fáciles de ensamblar y aislar los sistemas maestros de las cargas de trabajo de lectura pesadas.
¿Cómo construir una caché para subsistemas cerrados?
Decidimos que necesitamos crear cachés nosotros mismos, sin depender del proveedor. La facturación unificada es un ecosistema cerrado. Contiene muchos patrones de microservicio, que tienen numerosas API y sus propias bases de datos. Sin embargo, debido a la naturaleza cerrada, es imposible modificar nada.
Empezamos a pensar en cómo deberíamos abordar nuestros sistemas maestros. Un enfoque muy popular es el diseño impulsado por eventos, cuando recibimos datos de algún tipo de bus: este es un tema de Kafka o intercambia RabbitMQ. También puede obtener datos de Oracle: mediante activadores, utilizando CQN (una herramienta gratuita de Oracle) o Golden Gate. Dado que no podemos integrarnos en la aplicación, las opciones de escritura simultánea y posterior no estaban disponibles para nosotros.
Recibir datos del bus del despachador de mensajes
Nos gusta mucho la opción con colas y gestores de mensajes. RabbitMQ y Kafka ya se utilizan en "Facturación unificada". Probamos uno de los sistemas y obtuvimos un resultado excelente. Recibimos todos los eventos de RabbitMQ y hacemos carga en frío, la cantidad de datos no es muy grande.
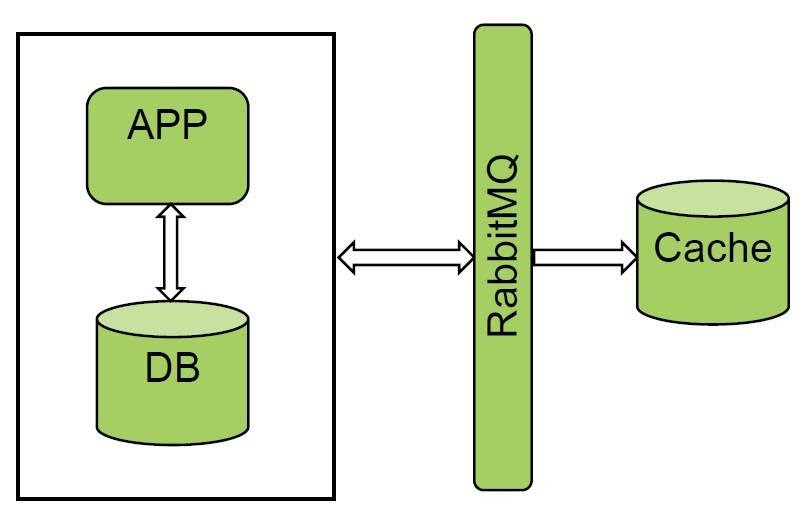
La solución funciona bien, pero no todos los sistemas pueden notificar a los buses, por lo que esta opción no nos funcionó.
Recuperando datos de la base de datos: disparadores
Todavía había una forma de obtener datos para llenar el caché de la base de datos.
La opción más simple son los disparadores. Pero no son adecuados para aplicaciones de alta carga, porque, en primer lugar, modificamos el sistema maestro en sí y, en segundo lugar, este es un punto adicional de falla. Si el disparador de repente no puede escribir en alguna placa temporal, obtenemos una degradación completa, incluido el sistema maestro.

Recuperando datos de la base de datos: CQN
La segunda opción para obtener datos de la base de datos. Usamos Oracle y el proveedor actualmente solo admite una herramienta gratuita para obtener datos de la base de datos: CQN.
Este mecanismo le permite suscribirse a notificaciones de cambio de operación DDL o DML. Allí todo es bastante sencillo. Hay notificaciones de estilo JDBC y PL / SQL.
JDBC significa que notificamos a la cola avanzada y este evento se envía al sistema externo. De hecho, se necesita un conector OSI externo. No nos gustó esta opción, porque si perdemos nuestra conexión con Oracle, no podemos leer nuestro mensaje.
Elegimos PL / SQL porque nos permite interceptar la notificación y almacenarla en una tabla temporal en la misma base de datos de Oracle. Es decir, de esta manera puede proporcionar cierta integridad transaccional.
Todo funcionó bien al principio hasta que piloteamos una base bastante cargada. Aparecieron las siguientes deficiencias:
- Carga transaccional en la base. Cuando interceptamos un mensaje de la cola de notificaciones, debemos ponerlo en la base. Es decir, la carga de escritura se duplica.
- También utiliza una cola avanzada interna. Y si su sistema maestro también lo usa, entonces puede surgir competencia por la cola.
- Tenemos un error interesante en las tablas particionadas. Si una confirmación cierra más de 100 cambios, entonces CQN no detecta dichos cambios. Abrimos un ticket en Oracle, cambiamos los parámetros del sistema, no ayudó.
Para aplicaciones pesadas, CQN definitivamente no es adecuado. Es bueno para pequeñas instalaciones, para trabajar con algún tipo de diccionarios, datos de referencia.
Recuperando datos de la base de datos: Golden Gate
El viejo Golden Gate permanece. Inicialmente, no queríamos usarlo, ya que es una solución pasada de moda, nos intimidaba la complejidad del sistema en sí.

En el propio GG, había dos instancias adicionales que debían mantenerse y no tenemos mucho conocimiento de Oracle. Inicialmente fue bastante difícil, aunque nos gustaron mucho las posibilidades de la solución.
La combinación SCN + XID nos permitió monitorear la integridad transaccional. La solución resultó ser universal, tiene un bajo impacto en el sistema maestro desde el cual podemos recibir todos los eventos. Aunque la solución requiere la compra de una licencia, esto no fue un problema para nosotros ya que la licencia ya estaba disponible. Además, las desventajas de la solución incluyen una implementación compleja y el hecho de que GG es un subsistema adicional.
conclusiones
¿Qué conclusiones se pueden sacar de lo anterior?
Si tiene un sistema cerrado, necesita investigar la naturaleza de su carga y las formas de uso, y seleccionar la solución adecuada. En nuestra opinión, lo óptimo es el diseño basado en eventos, cuando notificamos un tema en Kafka y el agente de mensajes se convierte en el sistema maestro. Un tema es un disco de oro, el resto de los datos los toma el sistema. Para los sistemas cerrados en nuestro panorama, GG resultó ser la solución más exitosa.
PIM - escaparate de comida
Y ahora, usando el ejemplo de uno de los productos, les contaré cómo aplicamos esta solución. PIM es una vitrina de productos basada en SID. Es decir, estos son todos los productos del suscriptor que actualmente están conectados a él. Sobre su base, se calculan los gastos y se construye la lógica del trabajo.
Arquitectura
Permítanme recordarles que en este artículo, "caché" significa una combinación de una aplicación y una base de datos, este es el patrón de uso principal de Tarantool.
La peculiaridad del proyecto PIM es que el sistema maestro original de Oracle es "pequeño", sólo 10 mil millones de registros. Debe leerse. Y el mayor problema que resolvimos fue el calentamiento de la caché.
Por donde empezamos

Las 10 tablas principales dan 10 mil millones de registros. Queríamos leerlos de frente. Dado que solo generamos datos calientes en la caché y Oracle almacena, entre otras cosas, datos históricos, tuvimos que establecer una cláusula where y extraer estos 10 mil millones. Una tarea no trivial. Oracle nos dijo que esto no debería hacerse: elevó la carga del procesador al 100%. Decidimos ir por el otro lado.
Pero primero, algunas palabras sobre la arquitectura del clúster.
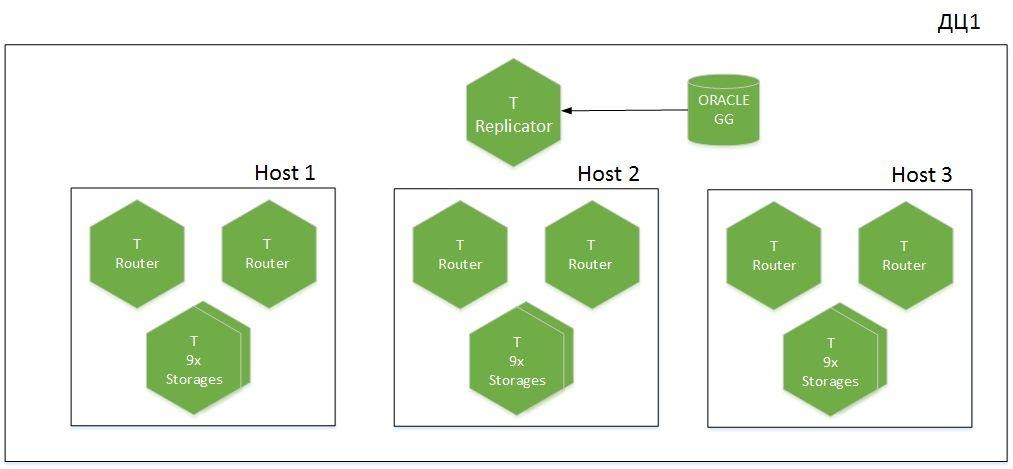
Esta es una aplicación fragmentada, 9 fragmentos en 6 hosts, distribuidos en dos centros de datos. Tenemos Tarantool con el rol de Replicador, que recibe datos de Oracle, y se usa otra instancia llamada Importador para el arranque en frío. Se genera un total de 1,1 TB de datos activos en la caché.
Arranque en frío
¿Cómo solucionamos el problema del arranque en frío? Todo resultó bastante trivial.

¿Cómo funciona todo el mecanismo? Eliminamos la cláusula where y leímos todo. Primero, iniciamos la secuencia de rehacer registro para recibir los cambios en línea de la base de datos. Mediante el escaneo completo pasamos por subsecciones, tomando datos en lotes con normalización y filtrado. Guardamos los cambios, simultáneamente comenzamos a calentar en frío la caché y cargamos todo en archivos CSV. Hay 10 instancias de Importador ejecutándose en la caché, que, después de ser leídas desde Oracle, envían datos a las instancias de Tarantool. Para hacer esto, cada importador calcula el fragmento requerido y coloca los datos en el almacenamiento necesario por sí mismo, sin cargar los enrutadores.
Después de cargar todos los datos de Oracle, reproducimos el flujo de rastros de GG que se han acumulado durante este tiempo. Cuando SCN + XID alcanza valores aceptables con el sistema maestro, consideramos que la caché se calienta, e incluimos la carga en lectura de sistemas externos.
Algunas estadísticas. En Oracle, tenemos aproximadamente 2,5 TB de datos sin procesar. Los leemos durante 5 horas, los importamos a CSV. La carga en Tarantool con filtrado y normalización tarda 8 horas. Y durante seis horas tocamos los troncos acumulados que nos llegan del sendero. Velocidad máxima de 600 mil registros / s. hasta 1 millón en picos. Tarantool inserta 1.1 TB de datos a 200K registros / s.
Ahora, calentar el caché en frío en grandes volúmenes se ha convertido en algo común para nosotros, porque no tenemos mucho impacto en Oracle.

En lugar de la base, cargamos la E / S y la red, por lo que primero debemos asegurarnos de que tenemos un margen suficiente de ancho de banda de red, en nuestros picos llega a 400 Mbps.
Cómo funciona la cadena de replicación de Oracle a Tarantool
Al diseñar la caché, decidimos ahorrar memoria. Eliminamos toda la redundancia, combinamos cinco tablas en una y obtuvimos un esquema de almacenamiento muy compacto, pero perdimos el control sobre la coherencia. Llegamos a la conclusión de que es necesario repetir el DDL de Oracle. Esto nos permitió controlar SCN + XID almacenándolos en un espacio tecnológico separado para cada placa. Al revisarlos periódicamente, podemos comprender dónde se rompió la replicación y, en caso de problemas, volvemos a leer los registros de archivo.
Fragmentación
Un poco sobre el almacenamiento de datos lógicos. Para eliminar Map Reduce, tuvimos que introducir redundancia de datos adicional y descomponer diccionarios en nuestros propios almacenamientos. Optamos por esto deliberadamente, porque nuestro caché funciona principalmente para leer. No podemos integrarlo en el sistema maestro, ya que esta aplicación aísla la carga de canales externos del sistema maestro. Leemos todos los datos de los suscriptores de un almacenamiento. En este caso, perdemos rendimiento de escritura, pero no es tan importante para nosotros, los diccionarios se actualizan con poca frecuencia.
¿Que pasó al final?
Hemos creado un caché para nuestro sistema cerrado. Hubo algunos errores de filtrado, pero ya los hemos solucionado. Nos hemos preparado para la aparición de nuevos consumidores de alta carga. El verano pasado, apareció un nuevo sistema, que agregó de 5 a 10 mil solicitudes por segundo, y no permitimos que esta carga se incluyera en la "Facturación unificada". También aprendimos cómo preparar la replicación de Oracle a Tarantool, resolvimos la transferencia de grandes cantidades de datos sin cargar el sistema maestro.
¿Qué nos queda por hacer todavía?
Estos son principalmente escenarios operativos:
- Control automático de la coherencia de los datos.
- Elabore el script de conmutación de Oracle Active-Standby, tanto de conmutación como de conmutación por error.
- Reproducción de registros de archivo de GG.
- — DDL- -. , DDL , .
- «»: ? https://habr.com/ru/article/470842/
- : Tarantool https://habr.com/ru/company/mailru/blog/455694/
- Telegram Tarantool https://t.me/tarantool_news
- Tarantool - https://t.me/tarantoolru