
Parece que ninguno de nuestros resúmenes está completo sin mencionar los desarrollos de Open AI: en julio, el nuevo algoritmo GPT-3 se convirtió en el tema más discutido en el campo del aprendizaje automático. Técnicamente, no se trata de un modelo, sino de toda una familia, que por conveniencia se generaliza bajo un solo nombre. El modelo más grande usa 175 mil millones de parámetros, y se usó un conjunto de datos de 570 Gb para el entrenamiento, que incluía datos filtrados de archivos de Common Crawl y datos de alta calidad de WebText2, Books1, Books2 y Wikipedia.
Vale la pena señalar aquí que el modelo está preentrenado y no requiere un ajuste fino para tareas específicas: para lograr mejores resultados, se recomienda proporcionarle al menos uno (una vez) o varios (pocos ejemplos) de resolución de problemas en la entrada, pero puede prescindir de ellos (disparo cero). Para que el modelo genere una solución al problema, basta con describir el problema en inglés. En general, se cree que este es un algoritmo para generar textos, pero ya está claro que el potencial es mucho más rico.
El modelo se presentó en mayo, incluso entonces Open AI demostró que GPT-3 entrenado en los repositorios de GitHub puede generar con éxito código Python, y ahora, después de un mes y medio, los primeros afortunados obtuvieron acceso a la API y mostraron sus mejores prácticas. Los resultados son asombrosos. Nosotros, como desarrolladores, estamos interesados, por supuesto, en cuánto este algoritmo simplificará nuestra vida y tal vez creará competencia.
Ya apareció el servicio debuild.co, que, según la descripción textual de la función, crea un código de trabajo y hace un buen diseño .
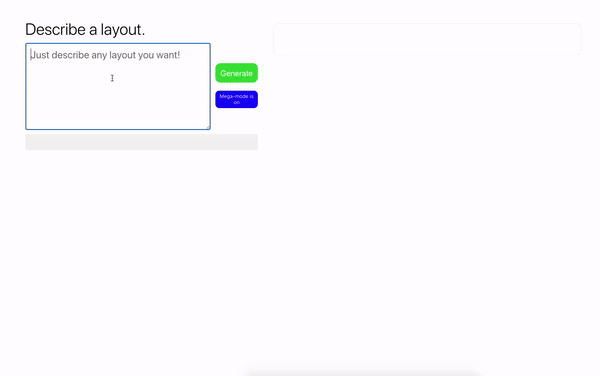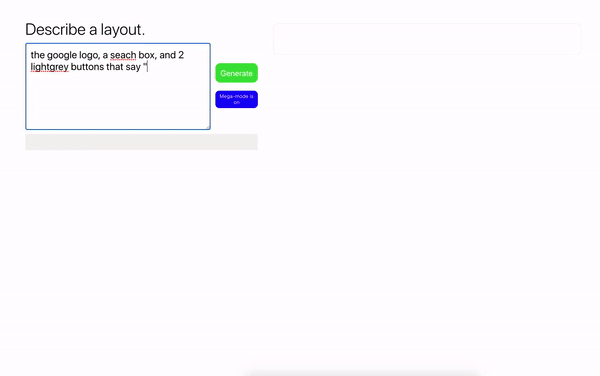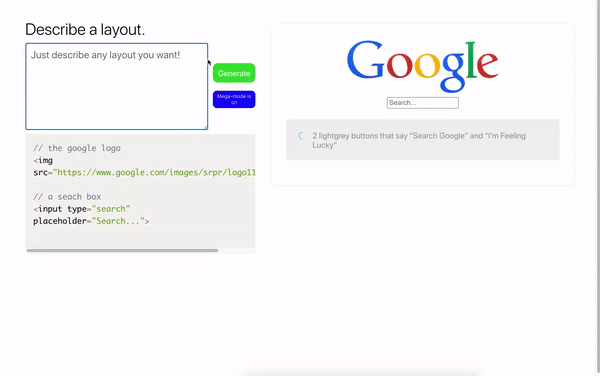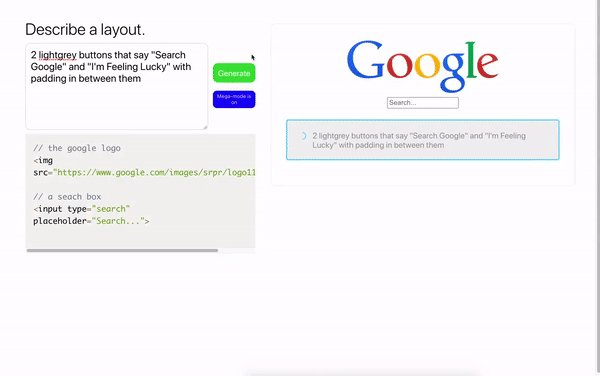
Puede utilizar las mejores prácticas no solo en programación web, sino también en diseño. El modelo es capaz de generar datos JSON por descripción de texto y traducirlos al diseño de Figma.
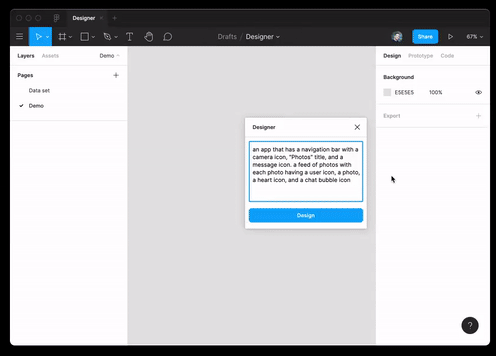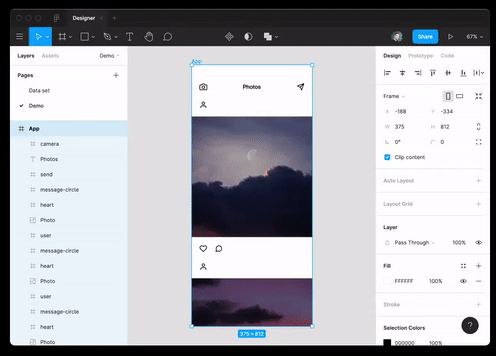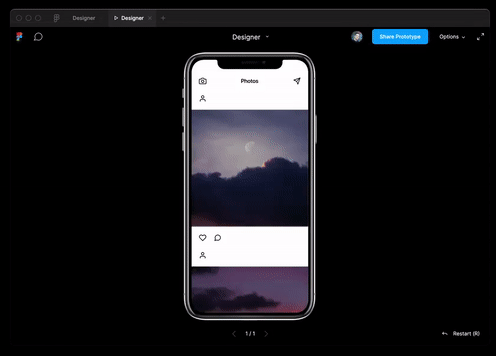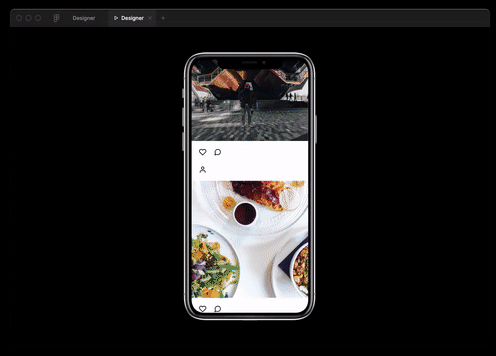
Y también ella prácticamente lo logróentrevista para un puesto de desarrollador Ruby.
Las noticias sobre el uso del aprendizaje automático en la programación no terminan ahí.
TransCoder La
migración de su base de código de un lenguaje de programación arcaico como COBOL a una alternativa moderna como Java o C ++ es una tarea compleja que requiere muchos recursos y requiere que los profesionales sean competentes en ambas tecnologías. Al mismo tiempo, los lenguajes arcaicos todavía se utilizan en mainframes de todo el mundo, lo que a menudo deja a los propietarios con una elección difícil: traducir manualmente el código base a un lenguaje moderno o seguir manteniendo el código heredado.
Facebook presenta un modelo de autoaprendizaje de código abierto, lo que ayudará a facilitar esta tarea. Es el primer sistema capaz de traducir código de un lenguaje de programación a otro sin requerir datos de entrenamiento en paralelo.
Los creadores estiman que el modelo traduce correctamente más del 90% de las funciones de Java a C ++, el 74,8% de las funciones de C ++ a Java y el 68,7% de las funciones de Java a Python. Que es más alto que los indicadores de análogos comerciales.
Las
herramientas de desarrollo de ContraCode utilizan cada vez más el aprendizaje automático para comprender y modificar el código escrito por humanos. La principal dificultad de trabajar con algoritmos con código es la falta de conjuntos de datos etiquetados.
Los investigadores de Berkeley sugieren resolver este problema utilizando el método ContraCode. Los autores creen que los programas con la misma funcionalidad deberían tener las mismas representaciones y viceversa. Por lo tanto, generan variantes de código para el aprendizaje contrastante. Para crear datos, se cambia el nombre de las variables, se reformatea y se ofusca el código.
En el futuro, un modelo de autoaprendizaje que utilice este método podrá predecir tipos, detectar errores, resumir código, etc. Dados estos y otros avances en el campo, es posible que las máquinas pronto aprendan a escribir código como los humanos.
DeepSIM

Los autores de este estudio muestran que una red generativa de adversarios en una sola imagen objetivo es capaz de manejar manipulaciones complejas.
El modelo aprende a hacer coincidir la representación primitiva de la imagen (por ejemplo, solo los bordes de los objetos en la foto) con la imagen en sí. Durante la manipulación, el generador le permite modificar imágenes cambiando su representación primitiva en la entrada y mapeándola a través de la red. Este enfoque resuelve el problema de DNN que requiere un enorme conjunto de datos de entrenamiento. Los resultados son impresionantes.
Inpainting de fotos 3D

Otra forma de convertir imágenes 2D RGB-D a 3D. El algoritmo recrea áreas que están ocultas por objetos en la imagen original. Se utilizó una imagen de profundidad en capas como representación base, a partir de la cual el modelo sintetiza iterativamente nuevos datos de color y profundidad para la región invisible, teniendo en cuenta el contexto. La salida son fotos, a las que puede agregar un efecto de paralaje utilizando motores gráficos estándar. Hay un colab disponible donde puede probar el modelo usted mismo.
HiDT

Un equipo de investigadores rusos presentó un algoritmo de código abierto que cambia la hora del día en las fotografías. Modelar los cambios de iluminación en fotografías de alta resolución es un desafío. El algoritmo presentado combina el modelo generativo de imagen a imagen y el esquema de muestreo superior, que permite transformaciones en imágenes de alta resolución. Es importante señalar que el modelo se entrenó con imágenes estáticas de diferentes paisajes sin marcas de tiempo.
Intercambio de codificador automático

Si HiDT es capaz de cambiar cualitativamente la iluminación en las imágenes, entonces esta red neuronal, entrenada en diferentes conjuntos de datos, puede cambiar no solo la hora del día, sino también el paisaje. Desafortunadamente, no hay oportunidad de ver el código fuente, por lo que solo podemos admirar el video que demuestra las capacidades de este modelo.
ESCANEO Una
red neuronal de código abierto que agrupa imágenes de forma independiente en grupos semánticamente significativos. La novedad del enfoque del autor es que las etapas de formación y agrupación están separadas. Primero, se inicia la tarea de enseñar características, luego el modelo se basa en los datos obtenidos en la primera etapa durante la agrupación. Esto permite mejores resultados que otros modelos similares.
RetrieveGAN

La generación de redes neuronales se está desarrollando rápidamente y RetrieveGAN es otra confirmación de esto. Un algoritmo basado en una descripción textual de una escena utiliza fragmentos de imágenes existentes para crear nuevas y únicas. Si bien las imágenes resultantes tienen muchos artefactos y no parecen muy creíbles, en el futuro esto puede abrir nuevas posibilidades en el campo del fotomontaje.
Seguimiento de pasajeros de ascensor
Gracias a los avances en visión artificial y aprendizaje automático, el seguimiento humano se está volviendo aún más efectivo. Un grupo de investigadores de Shanghai encargó a un gran desarrollador que desarrollara un sistema de control social del comportamiento en ascensores en tiempo real. El sistema es capaz de detectar actividad sospechosa en ascensores. De esta manera, los creadores esperan prevenir el vandalismo, el acoso sexual, el narcotráfico. El sistema también notará si las personas se detienen en un piso determinado con más frecuencia: por ejemplo, ya se ha podido identificar un catering que funciona ilegalmente en el apartamento. El sistema ya ha sido instalado y monitorea cientos de miles de ascensores.
Así de intenso resultó ser julio. Veamos qué novedades nos trae el próximo mes. ¡Gracias por su atención!