Desde la capacidad de procesar grandes cantidades de información y usar algoritmos de aprendizaje automático de manera mucho más eficiente, hasta algoritmos de modelado cuántico que pueden mejorar los cálculos (tanto cualitativa como cuantitativamente) para el diseño de nuevos fármacos, predecir la estructura de las proteínas, analizar varios procesos en un organismo biológico y etc. Estas alucinantes perspectivas están sujetas a un abrumador bombo de información en la actualidad, lo que significa que es importante resaltar las advertencias y los desafíos de esta nueva tecnología.
Advertencia: La revisión se basa en un artículo de un grupo de investigadores europeos del Reino Unido y Suiza (Carlos Outeiral, Martin Strahm, Jiye Shi, Garrett M. Morris, Simon C. Benjamin, Charlotte M. Deane. "Las perspectivas de la computación cuántica en biología molecular computacional", WIREs Computational Molecular Science publicado por Wiley Periodicals LLC, 2020). Las partes más difíciles del artículo relacionadas con modelos matemáticos sofisticados no se incluirán en la revisión. Pero el material es inicialmente complejo y el lector debe tener conocimientos de matemáticas y física cuántica.
Pero si tiene la intención de comenzar a estudiar la aplicación de las tecnologías cuánticas en bioinformática, entonces, para entrar primero en el tema, está invitado a escuchar un breve informe de Viktor Sokolov, investigador principal de M&S Decisions, en el que se indican algunos problemas modernos de modelado de fármacos:
Introducción
Desde el advenimiento de la informática de alto rendimiento, se han utilizado algoritmos y modelos matemáticos para resolver problemas en las ciencias biológicas, desde el estudio de la complejidad del genoma humano hasta el modelado del comportamiento de biomoléculas. Los métodos computacionales se utilizan regularmente hoy en día para analizar y extraer información importante de experimentos biológicos, así como para predecir el comportamiento de objetos y sistemas biológicos. De hecho, 10 de los 25 artículos científicos más citados tratan sobre algoritmos computacionales utilizados en biología [ver p. aquí ], incluido el modelado cuántico [ aquí , aquí , aquí y aquí ], alineación de secuencias [ aquí , aquí yaquí ], genética computacional [ver. aquí ] y la difracción de rayos X en el procesamiento de datos [cf. aquí y aquí ].
A pesar de este progreso, muchos problemas en biología siguen siendo insolubles desde el punto de vista de su solución utilizando tecnologías computacionales existentes. Los mejores algoritmos para tareas como predecir el plegamiento de proteínas, calcular la afinidad de unión de un ligando a una macromolécula o encontrar la alineación genómica óptima a gran escala requieren recursos computacionales que van más allá incluso de los superordenadores más potentes disponibles en la actualidad.
La solución a estos problemas puede residir en un cambio de paradigma en la tecnología informática. En la década de 1980, de forma independiente, Richard Feynman [ver aquí ] y Yuri Manin [ver. aquí ] propuso utilizar efectos de la mecánica cuántica para crear una nueva y más poderosa generación de computadoras.
La teoría cuántica ha demostrado ser una descripción muy exitosa de la realidad física y ha llevado, desde sus inicios a principios del siglo XX, a avances como láseres, transistores y microprocesadores semiconductores. La computadora cuántica utiliza los algoritmos más eficientes, utilizando operaciones que no son posibles en las máquinas clásicas. Los procesadores cuánticos no funcionan más rápido que las computadoras clásicas, pero funcionan de una manera completamente diferente, logrando aceleraciones sin precedentes, evitando cálculos innecesarios. Por ejemplo, se espera que el cálculo de la función de onda de electrones total de la molécula de fármaco promedio en cualquier supercomputadora moderna utilizando algoritmos convencionales lleve más tiempo que la edad completa de nuestro universo [ver Ref. aquí], mientras que incluso una pequeña computadora cuántica puede resolver este problema en unos pocos días. Animados por tal promesa de ventaja cuántica, los ingenieros y científicos continúan su búsqueda de un procesador cuántico. Sin embargo, las dificultades técnicas en la fabricación, gestión y protección de los sistemas cuánticos son increíblemente complejas y los primeros prototipos solo han aparecido en la última década.
Es importante señalar que los problemas técnicos de la construcción de computadoras cuánticas no detuvieron el desarrollo de algoritmos de computación cuántica. Incluso en ausencia de hardware, los algoritmos se pueden analizar matemáticamente, y el advenimiento de los simuladores de computadora cuántica de alto rendimiento, así como los primeros prototipos en los últimos años, ha permitido avanzar en la investigación.
Varios de estos algoritmos ya han mostrado aplicaciones potenciales prometedoras en biología. Por ejemplo, un algoritmo para estimar la fase cuántica permite calcular valores propios exponencialmente más rápido [ver. aquí ], que se puede utilizar para comprender la correlación a gran escala entre partes de una proteína o para determinar la centralidad de un gráfico en una red biológica. El algoritmo cuántico de Harrow-Hasidim-Lloyd (HHL) [cf. aquí ] puede resolver algunos sistemas lineales exponencialmente más rápido que cualquier algoritmo clásico conocido, y también puede aplicar métodos de aprendizaje estadístico con un proceso de adaptación mucho más rápido y la capacidad de administrar grandes cantidades de datos.
Los algoritmos de optimización cuántica tienen un amplio campo de aplicación en el campo del plegamiento de proteínas y selección de confórmeros, así como en problemas asociados con la búsqueda de mínimos o máximos [ver. aquí ]. Por último, recientemente se ha desarrollado tecnología para simular sistemas cuánticos que prometen, por ejemplo, producir predicciones precisas de interacciones fármaco-receptor [ver Ref. aquí ] o participar en el estudio y comprensión de procesos complejos y mecanismos químicos como la fotosíntesis [ver. aquí ]. La computación cuántica puede cambiar significativamente los métodos de la biología en sí, como lo hizo la computación clásica en su tiempo.
Recientes afirmaciones de supremacía cuántica de Google [cf. aquí], aunque disputado por IBM [cf. aquí ], indican que la era de la computación cuántica no está lejos. Los primeros procesadores que utilizarán efectos cuánticos para realizar cálculos imposibles para la tecnología informática clásica se esperan dentro de la próxima década [cf. aquí ].
En esta revisión, analizaremos los puntos clave en los que la computación cuántica es prometedora para la biología computacional. Estas revisiones analizan el impacto potencial de la computación cuántica en varios campos, incluido el aprendizaje automático [ver. aquí , aquí y aquí ], química cuántica [cf. aquí , aquí y aquí ] y síntesis de fármacos [ver.aquí ]. También se publicó recientemente un informe del Taller del NIMH sobre Computación Cuántica en Ciencias de la Vida [ver aquí ].
En esta revisión, primero damos una breve descripción de lo que se entiende por computación cuántica y una breve introducción a los principios del procesamiento de información cuántica. Luego discutimos tres áreas principales de la biología computacional, donde la computación cuántica ya ha mostrado desarrollos algorítmicos prometedores: métodos estadísticos, cálculos de estructuras electrónicas y optimización. Se dejarán de lado algunos temas importantes, por ejemplo, los algoritmos de cadenas que pueden afectar el análisis de secuencias [ver. aquí ], algoritmos de imágenes médicas [ver. aquí ], algoritmos numéricos para ecuaciones diferenciales [aquí ] y otros problemas matemáticos o métodos para analizar redes biológicas [ aquí ]. Finalmente, discutimos el impacto potencial de la computación cuántica en la biología computacional a mediano y largo plazo.
1. Procesamiento de información cuántica
Las computadoras cuánticas prometen resolver problemas en las ciencias biológicas, como predecir interacciones proteína-ligando o comprender la evolución conjunta de aminoácidos en proteínas. Y no es fácil de resolver, pero hacerlo exponencialmente más rápido de lo que puede imaginar con cualquier computadora moderna. Sin embargo, este cambio de paradigma requiere un cambio fundamental en nuestro pensamiento: las computadoras cuánticas son muy diferentes de sus predecesoras clásicas. Los fenómenos físicos que subyacen a la ventaja cuántica son a menudo ilógicos y contrarios a la intuición, y el uso de un procesador cuántico requiere un cambio fundamental en nuestra comprensión de la programación. En esta sección, presentamos los principios de la información cuántica y cómo se procesa para realizar cálculos.
Explicamos cómo la información funciona de manera diferente en un sistema cuántico, dónde se almacena en qubits y cómo esa información puede manipularse utilizando puertas cuánticas. Al igual que las variables y funciones en un lenguaje de programación, los qubits y las puertas cuánticas definen los elementos básicos de cualquier algoritmo. También examinaremos por qué la creación de una computadora cuántica es técnicamente extremadamente difícil y qué se puede lograr con la ayuda de los primeros prototipos que se esperan en los próximos años. Esta introducción solo cubrirá los puntos principales; para un estudio completo, lea el libro de Nielsen y Chuang [ aquí ].
1.1. Elementos de los algoritmos cuánticos
1.1.1. Información cuántica: una introducción al qubit
El primer problema al representar la computación cuántica es comprender cómo procesa la información. En un procesador cuántico, la información generalmente se almacena en qubits, que son el análogo cuántico de los bits clásicos. Un qubit es un sistema físico, como un ion, limitado por un campo magnético [ver. aquí ] o un fotón polarizado [ver. aquí ], pero a menudo se habla de él en abstracto. Como el gato de Schrödinger, un qubit puede tomar no solo los estados 0 o 1, sino también cualquier combinación posible de ambos estados. Cuando se observa un qubit directamente, ya no estará en una superposición que colapse a uno de los estados posibles, al igual que el gato de Schrödinger está vivo o muerto después de abrir la caja [ver. aquí]. Más importante aún, cuando se combinan varios qubits, pueden correlacionarse y las interacciones con cualquiera de ellos tienen consecuencias para todo el estado colectivo. El fenómeno de correlación entre múltiples qubits, conocido como entrelazamiento cuántico, es un recurso fundamental para la computación cuántica.
En la información clásica, la unidad fundamental de información es el bit, un sistema con dos estados identificables, a menudo denominados 0 y 1. El análogo cuántico, un qubit, es un sistema de dos estados, cuyos estados se denominan | 0⟩ y | 1⟩. Usamos la notación de Dirac, donde | *⟩ identifica un estado cuántico. La principal diferencia entre la información clásica y la cuántica es que un qubit puede estar en cualquier superposición de estados | 0⟩ y | 1⟩:
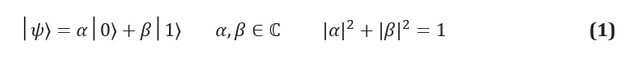
Los coeficientes complejos α y β se conocen como amplitudes de estados y están relacionados con otro concepto clave en la mecánica cuántica: el efecto de la medición física. Dado que los qubits son sistemas físicos, siempre puede crear un protocolo para medir su estado. Si, por ejemplo, los estados | 0⟩ y | 1⟩ corresponden a los estados del espín de un electrón en un campo magnético, entonces medir el estado de un qubit es simplemente medir la energía del sistema. Los postulados de la mecánica cuántica dictan que si el sistema se encuentra en una superposición de posibles resultados de medición, entonces el acto de medición debe cambiar el estado mismo. El sistema de superposición se derrumbará en la etapa de medición; la medición destruye así la información transportada por las amplitudes en el qubit.
Surgen importantes implicaciones computacionales cuando consideramos sistemas de múltiples qubits que pueden experimentar entrelazamiento cuántico. El entrelazamiento es un fenómeno en el que un grupo de qubits están correlacionados, y cualquier operación en uno de estos qubits afectará el estado general de todos ellos. Un ejemplo canónico de entrelazamiento cuántico es la paradoja de Einstein-Podolsky-Rosen, presentada en 1935 [cf. aquí ]. Considere un sistema de dos qubits, donde, dado que cada uno de los qubits individuales puede tomar cualquier superposición de estados {| 0⟩ y | 1⟩}, el sistema compuesto puede tomar cualquier superposición de estados {| 00⟩, | 01⟩, | 10⟩, | 11 ⟩} (Y, en consecuencia, el sistema de N-qubits puede tomar cualquiera de cadenas binarias, de {| 0 ... 0⟩ a | 1 ... 1⟩}. Una de las posibles superposiciones del sistema son los llamados estados de Bell, uno de los cuales tiene la siguiente forma: Si tomamos una medida en el primer qubit, solo podemos observar | 0⟩ o | 1⟩, cada uno de los cuales tendrá una probabilidad de 1/2. Esto no hace ningún cambio para el caso de un solo qubit. Si el resultado del primer qubit fue | 0⟩, el sistema colapsará en el sistema | 01⟩ y, por lo tanto, cualquier medición en el segundo qubit dará | 1⟩ con probabilidad 1; de manera similar, si la primera medida fuera | 1⟩, la medida en el segundo qubit daría | 0⟩. Una operación (en este caso, una medición con el resultado "0") aplicada al primer qubit afecta los resultados que se pueden ver cuando se mide posteriormente el segundo qubit.

La existencia de entrelazamiento es fundamental para la computación cuántica útil. Se ha demostrado que cualquier algoritmo cuántico que no utilice entrelazamiento puede aplicarse a una computadora clásica sin una diferencia significativa en la velocidad [cf. aquí y aquí ]. Intuitivamente, la razón es la cantidad de información que una computadora cuántica puede manipular. Si el sistema N qubit no está enredado, entonces amplitudes de su estado pueden describirse mediante las amplitudes de cada estado de un bit, es decir, 2N amplitudes. Sin embargo, si el sistema está entrelazado, todas las amplitudes serán independientes y el registro de qubit formaráVector 2 N -dimensional. La capacidad de las computadoras cuánticas para manipular grandes cantidades de información con múltiples operaciones es una de las principales ventajas de los algoritmos cuánticos y respalda su capacidad para resolver problemas exponencialmente más rápido que la tecnología informática clásica.
1.1.2. Puertas cuánticas
La información almacenada en qubits se procesa mediante operaciones especiales conocidas como puertas cuánticas. Las puertas cuánticas son operaciones físicas, como un pulso láser dirigido a un qubit de iones, o un conjunto de espejos y divisores de haz a través de los cuales debe viajar un qubit de fotones. Sin embargo, las puertas se ven a menudo como operaciones abstractas. Los postulados de la mecánica cuántica imponen unas condiciones estrictas sobre la naturaleza de las puertas cuánticas en sistemas cerrados, lo que permite representarlas en forma de matrices unitarias, que son operaciones lineales que preservan la normalización del sistema cuántico.
En particular, una puerta cuántica aplicada a un registro entrelazado de N qubits equivale a multiplicar la matriz × por vector de entrada . La capacidad de una computadora cuántica para almacenar y realizar cálculos de grandes cantidades de información es del orden de , manipulando múltiples elementos, de orden N, forma la base de su capacidad para proporcionar una ventaja potencialmente exponencial sobre las computadoras clásicas.
Esencialmente, las puertas cuánticas son cualquier operación permitida en un sistema qubit. Los postulados de la mecánica cuántica imponen dos restricciones estrictas sobre la forma de las puertas cuánticas. Los operadores cuánticos son lineales. La linealidad es una condición matemática que, no obstante, tiene profundas implicaciones para la física de los sistemas cuánticos y, por tanto, cómo se pueden utilizar para la computación. Si el operador lineal se aplica a la superposición de estados , el resultado es una superposición de los estados individuales, que se ven afectados por el operador. En un qubit, esto significa: Los operadores lineales se pueden representar en forma de matrices, que son simplemente tablas que indican el efecto de un operador lineal en cada estado base. La Figura 1 (c, d) muestra una representación matricial de una de dos puertas de qubit y dos de un bit. Sin embargo, no todas las matrices representan puertas cuánticas reales. Esperamos que las puertas cuánticas aplicadas a una colección de qubits den un conjunto real diferente de qubits, en particular, uno normalizado (por ejemplo, en la ecuación (3) esperamos que
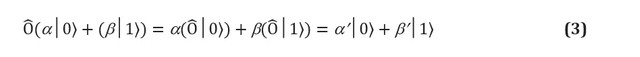
× es una puerta cuántica de N-qubit completamente válida.
En la informática clásica, solo hay una puerta no trivial por bit: la puerta NOT, que convierte 0 en 1 y viceversa. En la computación cuántica, hay un número infinito de matrices unitarias de 2 × 2, y cualquiera de ellas es una posible puerta cuántica de un qubit. Uno de los primeros éxitos de la computación cuántica fue el descubrimiento de que esta amplia gama de posibilidades se podría realizar con un conjunto de puertas universales que afectan a uno y dos qubits [ver Ref. aquí]. En otras palabras, dadas las puertas cuánticas arbitrarias, hay un circuito de puertas de uno y dos qubit que puede impulsarlo con precisión arbitraria. Desafortunadamente, esto no significa que la aproximación sea efectiva. La mayoría de las puertas cuánticas solo se pueden aproximar mediante un número exponencial de puertas de nuestro conjunto universal. Incluso si estas puertas se pueden usar para resolver problemas útiles, su implementación tomará una cantidad de tiempo exponencialmente grande y puede anular cualquier ventaja cuántica. FIGURA 1 (a) Comparación de un bit clásico con un bit cuántico o "qubit". Mientras que un bit clásico solo puede tomar uno de dos estados, 0 o 1, un bit cuántico puede tomar cualquier estado de la forma

... Los qubits individuales a menudo se representan usando la representación de esfera de Bloch, donde θ y ϕ se entienden como ángulos acimutales y polares en una esfera de radio unitario. (b) Un esquema de un qubit de trampa de iones, uno de los enfoques más comunes para la computación cuántica experimental. Ion (a menudo) se mantiene en alto vacío mediante campos electromagnéticos y se expone a un fuerte campo magnético. Los niveles hiperfinos se separan según el efecto Zeeman, y los dos niveles seleccionados se seleccionan como estados | 0⟩ y | 1⟩. Las puertas cuánticas se implementan mediante pulsos de láser apropiados, que a menudo involucran otros niveles electrónicos. Este diagrama fue adaptado de [ver. aquí ]. (c) Diagrama de un circuito cuántico que implementa X o el cuanto de negación controlada (CNOT).
Se muestra la representación y el cambio en la esfera de Bloch. (d) Circuito cuántico para generar el estado de campanautilizando una puerta Hadamard y una puerta CNOT (negación controlada). La línea de puntos en el medio del contorno indica el estado después de que se aplica la válvula Hadamard.
1.2. Hardware cuántico
Los algoritmos cuánticos solo pueden resolver problemas interesantes si se ejecutan en el hardware cuántico correcto. Hay muchas propuestas en competencia para la creación de un procesador cuántico basado en iones atrapados [ver. aquí ], circuitos superconductores [ver. aquí ] y dispositivos fotónicos [ver. aquí]. Sin embargo, todos enfrentan un problema común: errores computacionales que literalmente pueden arruinar el proceso computacional. Una de las piedras angulares de la computación cuántica es el descubrimiento de que estos errores se pueden eliminar con códigos de corrección de errores cuánticos. Desafortunadamente, estos códigos también requieren un gran aumento en el número de qubits, por lo que se necesitan mejoras técnicas significativas para lograr la tolerancia a fallas.
Hay muchas fuentes de error que pueden afectar a un procesador cuántico. Por ejemplo, la conexión de un qubit con su entorno puede llevar al colapso del sistema a uno de sus estados clásicos, un proceso conocido como decoherencia.... Pequeñas fluctuaciones pueden transformar las puertas cuánticas, lo que eventualmente conducirá a resultados diferentes a los esperados. Las puertas menos propensas a errores hasta la fecha se han registrado en un procesador de iones atrapados, con una frecuencia de un error porpuertas de un qubit y con una tasa de error del 0,1% para puertas de dos qubit [ aquí y aquí ]. En comparación, un trabajo reciente de Google informó una fidelidad del 0,1% para puertas de un solo qubit y del 0,3% para puertas de dos qubit en un procesador superconductor [ver Ref. aquí ]. Dado que la falla de una puerta de enlace puede arruinar el cálculo, es fácil ver que la propagación del error puede hacer que el cálculo no tenga sentido después de una pequeña secuencia de elementos.
Una de las principales direcciones de la computación cuántica es el desarrollo de códigos de corrección de errores cuánticos. En la década de 1990, varios grupos de investigación demostraron que estos códigos pueden lograr cálculos tolerantes a fallas, siempre que las tasas de error de la puerta estén por debajo de cierto umbral, que depende del código [ver. aquí , aquí , aquí y aquí ]. Uno de los enfoques más populares, el código de superficie, puede operar con tasas de error cercanas al 1% [ver Ref. aquí ].
Desafortunadamente, los códigos de corrección de errores cuánticos requieren una gran cantidad de qubits físicos reales para codificar el qubit lógico abstracto que se usa para el cálculo, y esta sobrecarga aumenta con la tasa de error. Por ejemplo, un algoritmo cuántico para factorizar números primos [ver. aquí ] podría descomponer silenciosamente un número de 2000 bits usando aproximadamente 4000 qubits y, a 16 GHz, este proceso tomaría aproximadamente un día de trabajo. Suponiendo una tasa de error del 0.1%, el mismo algoritmo, usando el código de superficie para corregir errores ambientales, requeriría varios millones de qubits y la misma cantidad de tiempo [ver Ref. aquí]. Considerando que el récord actual para un procesador cuántico programable y controlado es de 53 qubits [ver. aquí ], todavía queda un largo camino por recorrer en esta dirección de investigación.
Muchos grupos han hecho esfuerzos para desarrollar algoritmos que puedan ejecutarse en los denominados procesadores cuánticos de ruido de escala media [cf. aquí ]. Por ejemplo, los algoritmos variacionales combinan una computadora clásica con un pequeño procesador cuántico, realizando una gran cantidad de cálculos cuánticos cortos que pueden lograrse antes de que el ruido se vuelva significativo.
Estos algoritmos a menudo usan un circuito cuántico parametrizado, que realiza una tarea particularmente difícil, y usan una computadora clásica para optimizar los parámetros. El método de resolución es una región de reducción de errores en la que, en lugar de lograr la tolerancia a fallas, se intentó minimizar los errores con un esfuerzo mínimo para impulsar circuitos de puerta más grandes. Hay varios enfoques que incluyen el uso de operaciones adicionales para descartar ejecuciones con errores [ver. aquí ] o manipulación de la tasa de error para extrapolar al resultado correcto [cf. aquí y aquí]. Aunque las aplicaciones principales requerirán computadoras cuánticas muy grandes y tolerantes a fallas; Se espera que los dispositivos disponibles durante la próxima década resuelvan estos problemas [ver aquí ].
2. Métodos estadísticos y aprendizaje automático
En biología computacional, donde el objetivo suele ser recopilar cantidades masivas de datos, los métodos estadísticos y el aprendizaje automático son técnicas clave. Por ejemplo, en genómica, los modelos ocultos de Markov (HMM) se utilizan ampliamente para anotar información sobre genes [ver. aquí ]; durante el descubrimiento de fármacos, se ha desarrollado una amplia gama de modelos estadísticos para evaluar las propiedades moleculares o para predecir la unión ligando-proteína [ver. aquí ]; y en biología estructural, las redes neuronales profundas se han utilizado tanto para predecir conexiones de proteínas [ver. aquí ] y estructura secundaria [ver. aquí ], y más recientemente también estructuras proteicas tridimensionales [ver. aquí ].
La formación y el desarrollo de estos modelos suelen requerir un uso intensivo de cálculos. Un catalizador importante de los avances recientes en el aprendizaje automático ha sido la comprensión de que las unidades de procesamiento de gráficos (GPU) de propósito general pueden acelerar drásticamente el aprendizaje. Al proporcionar algoritmos exponencialmente más rápidos para el aprendizaje automático, los modelos de computación cuántica pueden proporcionar un interés similar en el enfoque de aplicaciones para problemas científicos.
En esta sección, explicaremos cómo la computación cuántica puede acelerar numerosos métodos de aprendizaje estadístico.
2.1. Ventajas y desventajas del aprendizaje automático cuántico
Primero, analizamos los beneficios que proporciona una computadora cuántica para el aprendizaje automático. Excepto por ejemplos idealizados, las computadoras cuánticas no pueden aprender más información que una computadora clásica [cf. aquí ]. Sin embargo, en principio, pueden ser mucho más rápidos y capaces de procesar muchos más datos que sus homólogos clásicos. Por ejemplo, el genoma humano contiene 3 mil millones de pares de bases, que se pueden almacenar en 1,2 ×bits clásicos: aproximadamente 1,5 gigabytes. Un registro de N qubits incluyeamplitudes, cada una de las cuales puede representar un bit clásico estableciendo la k-ésima amplitud en 0 o 1 con un factor de normalización apropiado. Por tanto, el genoma humano se puede almacenar en ~ 34 qubits. Si bien esta información no se puede extraer de una computadora cuántica, hasta que se prepare un cierto estado, se pueden ejecutar ciertos algoritmos de aprendizaje automático en ella. Más importante aún, duplicar el tamaño del registro a 68 qubits deja suficiente espacio para almacenar el genoma completo de cada persona viva en el mundo. La presentación y el análisis de cantidades tan enormes de datos serían bastante consistentes con las capacidades de incluso una pequeña computadora cuántica tolerante a fallas.
Las operaciones para procesar esta información también pueden ser exponencialmente más rápidas. Por ejemplo, varios algoritmos de aprendizaje automático se limitan a la inversión a largo plazo de la matriz de covarianza con una penalizaciónen las dimensiones de la matriz. Sin embargo, el algoritmo propuesto por Harrow, Hassidim y Lloyd [cf. aquí ], le permite invertir la matriz enbajo algunas condiciones. La idea clave es que, a diferencia de las GPU, que aceleran los cálculos a través de un paralelismo masivo, los algoritmos cuánticos tienen la ventaja de la complejidad de los algoritmos computacionales que se utilizan directamente. En algunos casos, especialmente con la aceleración exponencial actual, las computadoras cuánticas de tamaño mediano pueden resolver problemas de aprendizaje disponibles solo para las supercomputadoras clásicas más grandes disponibles en la actualidad.
La mejora del almacenamiento y procesamiento de datos tiene beneficios secundarios. Uno de los puntos fuertes de las redes neuronales es su capacidad para encontrar representaciones concisas de datos [ver. aquí]. Dado que la información cuántica es más general que la información clásica (después de todo, los estados de un bit clásico se subdividen en estados propios | 0⟩ y | 1⟩, o un qubit), es muy posible que los modelos de aprendizaje automático cuántico puedan asimilar mejor la información que los modelos clásicos. ... Por otro lado, los algoritmos cuánticos con complejidad de tiempo logarítmico también mejoran la confidencialidad de los datos [ver. aquí ]. Dado que entrenar el modelo requierey requiere la reconstrucción de la matriz, para un conjunto de datos suficientemente grande es imposible recuperar una parte significativa de la información, aunque todavía es posible un entrenamiento efectivo del modelo. En el contexto de la investigación biomédica, esto puede facilitar el intercambio de datos al tiempo que garantiza la confidencialidad.
Desafortunadamente, si bien los algoritmos de aprendizaje automático cuántico basados en papel pueden superar ampliamente a sus homólogos clásicos, aún persisten dificultades prácticas. Los algoritmos cuánticos son a menudo subrutinas que transforman la entrada en salida. Los problemas surgen precisamente en estas dos etapas: cómo preparar la entrada adecuada y cómo extraer información de la salida [ver. aquí ]. Supongamos, por ejemplo, que estamos usando el algoritmo HHL [ver. aquí ] para resolver un sistema lineal de la forma... Al final de la subrutina, el algoritmo generará el registro de qubit en el siguiente estado: Aquí
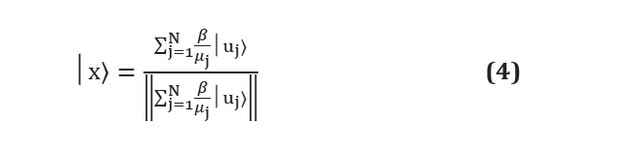
y ¿Son los autovectores y autovalores de A, y - j-ésimo coeficiente se expresa en términos de los autovectores de A, y el denominador es simplemente una constante de normalización. Se puede ver que esto corresponde a los coeficientes, que se almacenan en las amplitudes de varios estados como y no son directamente accesibles. La medición del registro de qubit conducirá a su colapso en uno de los estados del vector propio y a volver a estimar las amplitudes de cada medidas requeridas , que en primer lugar supera cualquier ventaja del algoritmo cuántico.
HHL y muchos otros algoritmos solo son útiles para calcular la propiedad global de una solución, como el valor esperado. En otras palabras, HHL no puede proporcionar una solución a un sistema de ecuaciones o invertir una matriz en tiempo logarítmico, a menos que solo estemos interesados en las propiedades globales de la solución, que se pueden obtener usando varias medidas físicamente observables. Esto restringe el uso de algunas subrutinas, pero ha habido muchas sugerencias para solucionar este problema.
Ingresar información en una computadora cuántica es un problema mucho mayor. La mayoría de los algoritmos de aprendizaje automático cuántico asumen que la computadora cuántica tiene acceso al conjunto de datos en forma de estado de superposición; por ejemplo, hay un registro de qubit que está en un estado de la forma: Aquí - | bin (j) es un estado que actúa como un índice, y

Es la amplitud correspondiente. Esto se puede utilizar, por ejemplo, para almacenar los elementos de un vector o matriz. En principio, existe un circuito cuántico que puede preparar este estado actuando en, digamos, el estado | 0 ... 0⟩. Sin embargo, su implementación puede ser muy difícil, ya que esperamos que la aproximación de un estado cuántico aleatorio sea exponencialmente difícil y destruirá cualquier posible ventaja cuántica.
La mayoría de los algoritmos cuánticos asumen el acceso a la memoria cuántica de acceso aleatorio (QRAM) [ver. aquí ], que es un dispositivo de caja negra capaz de construir esta superposición. Aunque se han propuesto algunos dibujos [ver. aquí y aquí], por lo que sabemos, todavía no hay ningún dispositivo que funcione. Además, incluso si dicho dispositivo estuviera disponible, no hay garantía de que no cree cuellos de botella que superen los beneficios del algoritmo cuántico. Por ejemplo, una propuesta reciente basada en un esquema para QRAM [cf. aquí ] muestra el inevitable costo lineal del número de estados que supera cualquier algoritmo de tiempo de registro. Finalmente, incluso si QRAM no presenta ningún costo adicional, aún será necesario realizar el preprocesamiento clásico; para el ejemplo del genoma, se requeriría acceso a 12 exabytes de almacenamiento clásico.
Finalmente, debemos enfatizar que los algoritmos de aprendizaje automático cuántico no están exentos de uno de los problemas más comunes en las aplicaciones prácticas: la falta de datos relevantes. La disponibilidad de grandes cantidades de datos es fundamental para el éxito de muchas aplicaciones prácticas de la IA en la ciencia molecular, como el desarrollo molecular de novo [ver Ref. aquí ]. Sin embargo, el poder de los algoritmos cuánticos puede ser útil como desarrollos científicos y tecnológicos como la aparición de laboratorios autogestionados [ver Ref. aquí ] proporcionan cada vez más datos.
El aprendizaje automático cuántico tiene el potencial de transformar la forma en que procesamos y analizamos los datos biológicos. Sin embargo, los problemas prácticos actuales de la implementación de tecnologías cuánticas siguen siendo importantes.
2.2. Algoritmos de aprendizaje automático cuántico
2.2.1. Aprendiendo sin maestro
El aprendizaje no supervisado incluye varias técnicas para extraer información de conjuntos de datos sin etiquetar. En biología, donde la secuenciación de próxima generación y una gran colaboración internacional han estimulado la recopilación de datos, estos métodos han encontrado un uso generalizado, por ejemplo, para identificar relaciones entre familias de biomoléculas [ver. aquí ] o genomas anotados [ver. aquí ].
Uno de los algoritmos de aprendizaje no supervisado más populares es el análisis de componentes principales (PCA), que intenta reducir la dimensionalidad de los datos al encontrar combinaciones lineales de características que maximizan la varianza [cf. aquí]. Este método se usa ampliamente en todo tipo de conjuntos de datos de alta dimensión, incluidos los datos de microarrays de ARN y espectrometría de masas [ver. aquí ]. Un grupo de investigadores propuso un algoritmo cuántico para PCA [ver. aquí ]. Esencialmente, este algoritmo construye una matriz de covarianza de datos en una computadora cuántica y utiliza una subrutina conocida como estimación de fase cuántica para calcular los vectores propios en tiempo logarítmico. Los datos de salida del algoritmo son un estado de superposición de la forma: Aquí

Es el j-ésimo componente principal, y - el valor propio correspondiente. Dado que el PCA está interesado en valores propios grandes, que son los principales componentes de la varianza, la medición del estado final dará un componente principal adecuado con alta probabilidad. Repetir el algoritmo varias veces proporcionará un conjunto de componentes básicos. Este procedimiento es capaz de reducir la dimensión de la gran cantidad de información que se puede almacenar en una computadora cuántica.
También se ha propuesto un algoritmo cuántico para un método particular para analizar datos topológicos, a saber, para homología estable [ver. aquí ]. El análisis de datos topológicos intenta extraer información utilizando propiedades topológicas en la geometría de conjuntos de datos; se utilizó, por ejemplo, en el estudio de la agregación de datos [ver.aquí ] y análisis de red [ver. aquí ]. Desafortunadamente, los mejores algoritmos clásicos tienen una dependencia exponencial en la dimensión del problema, lo que limita su aplicación. Algoritmo Lloyd et al. también utiliza una rutina de estimación de fase cuántica para acelerar exponencialmente la diagonalización de la matriz, alcanzando complejidad... La presencia de un algoritmo eficiente para realizar análisis topológicos puede estimular su aplicación para el análisis de problemas en las ciencias biológicas.
2.2.2. Aprendizaje supervisado
El aprendizaje supervisado se refiere a un conjunto de métodos que se pueden utilizar para hacer predicciones basadas en datos etiquetados. El objetivo es construir un modelo que pueda clasificar o predecir las propiedades de ejemplos invisibles. El aprendizaje supervisado se usa ampliamente en biología para resolver problemas tan diversos como predecir la afinidad de unión de un ligando por una proteína [ver. aquí ] y diagnóstico de enfermedades usando una computadora [ver. aquí ]. Veamos tres enfoques de aprendizaje supervisado.
Máquinas de vectores soporte(English support vector machine - SVM) es un algoritmo de aprendizaje automático que encuentra el hiperplano óptimo que separa las clases de datos. SVM se ha utilizado ampliamente en la industria farmacéutica para clasificar datos de moléculas pequeñas [cf. aquí ]. Dependiendo del kernel, el entrenamiento de SVM generalmente toma de antes de ... Rebentrost [ver. aquí ] presentó un algoritmo cuántico que puede entrenar una SVM con un núcleo polinomial en, y más tarde se extendió al núcleo de la función de base radial (RBF) [ver. aquí ]. Desafortunadamente, no está claro cómo implementar las operaciones no lineales que se utilizan ampliamente en SVM, dado que las operaciones cuánticas se limitan a ser lineales. Por otro lado, una computadora cuántica permite otros tipos de núcleos que no se pueden realizar en una computadora clásica [ver. aquí ].
La regresión del proceso gaussiano (GP) es una técnica comúnmente utilizada para construir modelos sustitutos, como en la optimización bayesiana [ver p. aquí ]. Los médicos de cabecera también se utilizan ampliamente para crear modelos cuantitativos de relación estructura-actividad (QSAR) de las propiedades de los fármacos.aquí ], y recientemente también para modelar la dinámica molecular [ver. aquí ]. Una de las desventajas de la regresión GP es el alto valorinversión de la matriz de covarianza. Zhao y colegas [ver. aquí ] sugirió usar el algoritmo HHL para sistemas lineales para invertir esta matriz, logrando una aceleración exponencial (siempre que la matriz sea escasa y bien acondicionada), una propiedad que a menudo se logra mediante matrices de covarianza. Más importante aún, este algoritmo se ha ampliado para calcular el logaritmo de la probabilidad límite [cf. aquí ], que es un paso importante para la optimización de hiperparámetros.
Uno de los métodos más comunes en biología computacional es el modelo oculto de Markov (HMM), que se usa ampliamente en la anotación computacional de genes y alineación de secuencias [cf. aquí]. Este método contiene varios estados ocultos, cada uno de los cuales está asociado con una cadena de Markov; las transiciones entre estados ocultos conducen a cambios en la distribución subyacente. Básicamente, HMM no se puede implementar directamente en una computadora cuántica: el muestreo requiere algún tipo de medición que interrumpirá el sistema. Sin embargo, existe una formulación en términos de sistemas cuánticos abiertos, es decir, un sistema cuántico que está en contacto con el entorno, que admite un sistema de Markov [ver. aquí ]. Si bien no se han propuesto mejoras al algoritmo clásico de Baum-Welch para entrenar HMM, se ha encontrado que los HMM cuánticos son más expresivos: pueden reproducir una distribución con menos estados ocultos [cf. aquí]. Esto podría conducir a una aplicación más amplia del método en biología computacional.
2.2.3. Redes neuronales y aprendizaje profundo
Los desarrollos recientes en el aprendizaje automático han sido estimulados por el descubrimiento de que múltiples capas de redes neuronales artificiales pueden detectar estructuras complejas en datos sin procesar [ver p. aquí ]. El aprendizaje profundo ha comenzado a impregnar todas las disciplinas científicas y, en biología computacional, sus avances incluyen la predicción precisa de enlaces proteicos. aquí ], mejor diagnóstico de algunas enfermedades [ver. aquí ], diseño molecular [cf. aquí ] y modelado [ver. aquí y aquí ].
Dados los avances significativos en el estudio de las redes neuronales, se ha realizado un trabajo significativo para desarrollar análogos cuánticos que puedan impulsar más avances en la tecnología.
El nombre red neuronal artificial a menudo se refiere a un perceptrón multicapa de una red neuronal, donde cada neurona toma una combinación lineal ponderada de sus entradas y devuelve el resultado a través de una función de activación no lineal. El principal desafío en el desarrollo de un análogo cuántico es cómo implementar una función de activación no lineal utilizando puertas cuánticas lineales. Últimamente ha habido muchas sugerencias y algunas ideas incluyen medidas [cf. aquí , aquí y aquí ], puertas cuánticas disipativas [ aquí], computación cuántica con una variable continua [ aquí ] y la introducción de qubits adicionales para construir puertas lineales que simulan la no linealidad [ver. aquí ]. Estos enfoques tienen como objetivo implementar una red neuronal cuántica que se espera que sea más expresiva que una red neuronal clásica debido al mayor poder de la información cuántica. Las ventajas o desventajas de escalar el entrenamiento de un perceptrón multicapa en una computadora cuántica no están claras, aunque la atención se centra en la posible mayor expresividad de estos modelos.
Una gran cantidad de esfuerzos recientes se han centrado en las máquinas de Boltzmann, redes neuronales recurrentes capaces de actuar como modelos generativos. Una vez entrenados, pueden generar nuevos patrones similares al conjunto de entrenamiento.
Los modelos generativos tienen aplicaciones importantes, por ejemplo, en el diseño molecular de novo [cf. aquí y aquí ]. Aunque las máquinas de Boltzmann son muy potentes, es necesario resolver el complejo problema del muestreo de la distribución de Boltzmann para calcular gradientes y realizar entrenamientos, lo que limita su aplicación práctica. Se han propuesto algoritmos cuánticos utilizando la máquina D-Wave [ver. aquí , aquí y aquí ] o un algoritmo de circuito [ver.aquí ]; esta muestra de la distribución de Boltzmann es cuadráticamente más rápida de lo que es posible en la versión clásica [ver. aquí ].
Recientemente, se propuso una heurística para el entrenamiento eficiente de máquinas cuánticas de Boltzmann, basada en la termalización del sistema [ver. aquí ]. Además, en algunos artículos, se han propuesto implementaciones cuánticas de redes generativas adversarias (GAN) [ver. aquí , aquí y aquí ]. Estos desarrollos implican mejorar los modelos generativos a medida que se desarrolla el hardware de computación cuántica.
3. Simulación efectiva de sistemas cuánticos
Según los modelos, la química está regulada por transferencia de electrones. Las reacciones químicas, así como las interacciones entre entidades químicas, también están controladas por la distribución de electrones y el paisaje de energía libre que forman. Problemas como predecir la unión de un ligando a una proteína o comprender la vía catalítica de una enzima se reducen a comprender el entorno electrónico. Desafortunadamente, modelar estos procesos es extremadamente difícil. El algoritmo más eficiente para calcular la energía de un sistema de electrones, la interacción de configuración completa (FCI), que escala exponencialmente a medida que crece el número de electrones, e incluso las moléculas con varios átomos de carbono apenas están disponibles para la investigación computacional [ver. aquí]. Aunque existen muchos métodos aproximados, descritos profunda y extensamente en publicaciones sobre la teoría funcional de la densidad [ver. aquí y aquí ], pueden ser imprecisos e incluso fallar abruptamente en muchas situaciones de interés, como la simulación del estado de respuesta transitorio [cf. aquí ]. Un algoritmo preciso y eficiente para estudiar la estructura electrónica proporcionaría una mejor comprensión de los procesos biológicos y también abriría oportunidades para el desarrollo de interacciones biológicas de próxima generación.
Las computadoras cuánticas se propusieron originalmente como un método para el modelado más eficiente de sistemas cuánticos. En 1996, Seth Lloyd demostró que esto es posible para ciertos tipos de sistemas cuánticos [ aquí], y una década después, Alan Aspuru-Guzik y sus colegas demostraron que los sistemas químicos son uno de esos casos [ aquí ]. Durante las últimas dos décadas, se han realizado importantes investigaciones sobre el ajuste de los métodos de modelado de sistemas químicos que pueden calcular propiedades de interés para la investigación.
3.1. Ventajas y desventajas de la simulación cuántica
En principio, una computadora cuántica es capaz de resolver de manera eficiente un problema de estructura electrónica completamente correlacionada (ecuaciones FCI), que será el primer paso para una estimación precisa de las energías de enlace, así como para modelar la dinámica de los sistemas químicos. La química computacional clásica se centró casi exclusivamente en métodos aproximados, que fueron útiles, por ejemplo, para estimar las cantidades termoquímicas de moléculas pequeñas [ aquí], pero esto puede no ser suficiente para los procesos asociados con la ruptura o formación de enlaces. En contraste, los procesadores cuánticos pueden potencialmente resolver un problema electrónico diagonalizando directamente la matriz FCI, dando un resultado preciso dentro de un determinado conjunto de bases y resolviendo así muchos de los problemas que surgen de descripciones incorrectas de la física de los procesos moleculares (por ejemplo, polarización de ligandos) ... Además, a diferencia de los enfoques clásicos, no requieren necesariamente un proceso iterativo, aunque el supuesto inicial sigue siendo importante.
Aunque las computadoras cuánticas no se comprenden bien, también superan las aproximaciones limitantes que se necesitaban en la computación clásica. Por ejemplo, la formulación de la simulación cuántica en el espacio real tiene en cuenta automáticamente la función de onda nuclear en ausencia de la aproximación de Born-Oppenheimer [ aquí ]. Esto permite estudiar los efectos no adiabáticos de algunos sistemas que se sabe que son importantes para la mutación del ADN [ver. aquí ] y el mecanismo de acción de muchas enzimas [ aquí ]. También se han propuesto aplicaciones de la computación cuántica para el modelado de sistemas relativistas [ver. aquí ], que son útiles para estudiar los metales de transición que aparecen en los centros activos de muchas enzimas.
En un artículo de Reicher y colegas [ver aquí ] se revela el concepto de escala de tiempo para calcular estructuras electrónicas en una computadora cuántica. Los autores consideraron el cofactor FeMo de la enzima nitrogenasa, cuyo mecanismo de fijación de nitrógeno aún no se ha estudiado y es demasiado complejo para estudiarlo utilizando enfoques computacionales modernos. El cálculo de la FCI de referencia mínima para FeMoCo llevará varios meses y unos 200 millones de qubits de la clase más alta disponible en la actualidad. Sin embargo, estas estimaciones deben cambiar con el rápido desarrollo de la tecnología. Durante los 3 años transcurridos desde la publicación, los avances algorítmicos ya han reducido los requisitos de tiempo en varios órdenes de magnitud [ver. aquí]. Además de los métodos más poderosos de estructura electrónica, las versiones rápidas de métodos aproximados modernos que se han investigado recientemente [cf. aquí y aquí ], puede acelerar significativamente la creación de prototipos, lo que podría ser útil, por ejemplo, al estudiar las coordenadas de reacciones de reacciones enzimáticas, cuyo área es un problema para la enzimología computacional [ aquí ]. Además, con una mejor comprensión de las interacciones intermoleculares catalizadas por el acceso a la computación totalmente correlacionada o el acceso a un ancho de banda más rápido que mejora la parametrización, el modelado cuántico puede mejorar significativamente las técnicas de modelado no cuántico, como los campos de fuerza.
Un último punto a tener en cuenta es que, a diferencia de otras áreas de investigación de algoritmos, como el aprendizaje con máquinas cuánticas, existe una serie de algoritmos de simulación cuántica a corto plazo que se pueden ejecutar en hardware preexistente y poco exigente. Numerosos grupos experimentales alrededor del mundo han informado demostraciones exitosas de estos algoritmos [ aquí , aquí , aquí y aquí ].
Desafortunadamente, también existen algunos inconvenientes en el modelado de sistemas cuánticos. Como se mencionó anteriormente, es muy difícil extraer información de una computadora cuántica. Reconstruir la función de onda completa es más difícil que calcularla de la forma clásica. Esta es una desventaja importante para los problemas químicos, donde los argumentos basados en la estructura electrónica son la principal fuente de comprensión. Sin embargo, en comparación con el aprendizaje automático, las ventajas superan con creces las desventajas, y se espera que la simulación cuántica sea una de las primeras aplicaciones útiles de la computación cuántica práctica [ver Ref. aquí ].
3.2. Computación cuántica tolerante a fallas
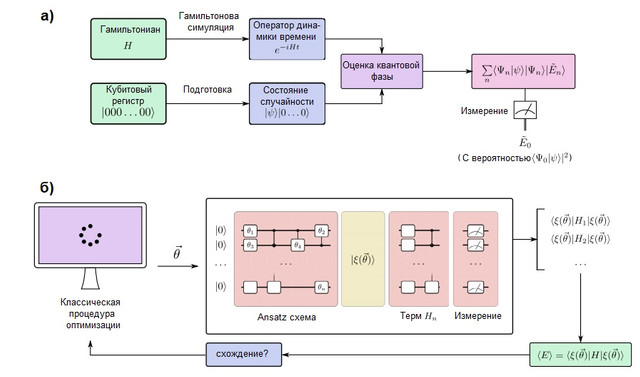
FIGURA 2. (a) Un algoritmo de simulación cuántica en una computadora cuántica tolerante a fallas. Los qubits se dividen en dos registros: uno se prepara en el estado, que se asemeja a la función de onda de destino, mientras que la otra permanece en el estado ... El algoritmo de estimación de fase cuántica (QPE) se utiliza para encontrar los valores propios del operador de evolución temporal, que se prepara utilizando los métodos de modelado hamiltoniano. Después de QPE, la medición de una computadora cuántica da la energía del estado fundamental con probabilidadpor lo que es importante preparar el estado de la suposición con superposición distinta de cero con la función de onda verdadera. (b) Un algoritmo de simulación cuántica variacional en una computadora cuántica a corto plazo. Este algoritmo combina un procesador cuántico con una rutina de optimización clásica para realizar varias ejecuciones cortas que son lo suficientemente rápidas para evitar errores. Una computadora cuántica prepara un estado de conjeturascon una cadena ansatz cuántica en función de varios parámetros... Los términos individuales del hamiltoniano se miden uno por uno (o en grupos de conmutación utilizando estrategias más avanzadas), dando una estimación de la energía esperada para un vector particular de parámetros. Luego, los parámetros se optimizan mediante el procedimiento de optimización clásico hasta la convergencia. El enfoque variacional se ha extendido a muchos problemas algorítmicos además de la simulación cuántica.
Las computadoras cuánticas que pueden simular grandes sistemas químicos deben ser tolerantes a fallas para ejecutar algoritmos arbitrariamente profundos sin errores. Una computadora cuántica de este tipo es capaz de simular un sistema químico mapeando el comportamiento de sus electrones con el comportamiento de sus qubits y puertas cuánticas. El proceso de modelado cuántico es conceptualmente muy simple y se muestra en la Figura 2 (a). Prepararemos un registro de qubits que pueda almacenar la función de onda e implementar la evolución unitaria del hamiltonianoutilizando los métodos de modelado hamiltoniano, que se analizan a continuación. Con estos elementos, una subrutina cuántica conocida como estimación de fase cuántica es capaz de encontrar los autovectores y autovalores del sistema. Es decir, si el registro de qubit está inicialmente en el estado | 0⟩, el estado final será: En otras palabras, el estado final es una superposición de valores propios

y vectores propios sistemas. Luego, el estado fundamental se mide con probabilidad... Para maximizar esta probabilidad, se establece un estado de referencia como un estado fácil de preparar pero también físicamente motivado que se espera que sea similar al estado fundamental exacto. Un ejemplo típico es el estado de Hartree-Fock, aunque se han explorado otras ideas para sistemas fuertemente correlacionados [ver Ref. aquí ].
Hay dos formas comunes de representar electrones en una molécula: métodos basados en cuadrículas y orbitales o básicos (consulte McArdle y colegas para obtener un desglose completo [ aquí ]). En los métodos de conjuntos de bases, la función de onda de electrones se representa como una suma de los determinantes de Slater de los orbitales de electrones, que se pueden comparar directamente con el registro de qubit [ aquí yaquí ]. Esto requiere la elección de una base y un cálculo preliminar de integrales electrónicas. Por otro lado, en los métodos de cuadrícula, el problema se formula como una solución a una ecuación diferencial ordinaria en una cuadrícula. La ventaja del modelado basado en cuadrículas es que no se requiere una aproximación de Bourne-Oppenheimer o un conjunto base. Sin embargo, no son naturalmente antisimétricos, que es requerido por el principio de Pauli de la mecánica cuántica, por lo que es necesario proporcionar antisimetría utilizando el procedimiento de clasificación [ aquí ]. Los métodos basados en cuadrículas se han discutido en el contexto de simulaciones de dinámica química [cf. aquí ] y calculando la constante de velocidad térmica [ver. aquí]. A pesar de las diferencias, el flujo de trabajo del modelado cuántico es idéntico, como se muestra en la Figura 2.
También hay varias formas de construir el operador.... Presentaremos la técnica más simple, la trotterización, también conocida como formulación de producto [ver pág. aquí ]; para obtener una descripción general completa, consulte [ aquí y aquí ]. La trotterización se basa en la premisa de que el hamiltoniano molecular se puede dividir como la suma de términos que describen las interacciones de uno y dos electrones. Si es así, entonces el operadorse puede implementar en términos de los operadores correspondientes para cada término en el hamiltoniano usando la fórmula de Trotter-Suzuki [ aquí ]: Por ejemplo, en la segunda cuantificación, cada término en esta expresión tendrá la forma o , donde están los operadores de aniquilación y creación, respectivamente. Whitfield y sus colegas han proporcionado construcciones de esquemas explícitos y detallados que representan estos términos [cf. aquí ]. Después de calcular los miembros
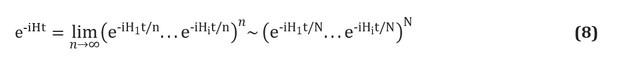

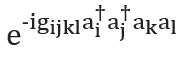
 y conocidas como integrales electrónicas, la cantidadcompletamente determinado. También puede utilizar fórmulas de Trotter - Suzuki de orden superior para reducir el error. Hay muchas otras técnicas de modelado hamiltonianas. Ejemplos de técnicas poderosas y sofisticadas son la cubitización [ aquí ] y el procesamiento de señales cuánticas [ver Ref. aquí ], que tienen una escala asintótica demostrablemente óptima, aunque no está claro si esto conducirá a mejores aplicaciones prácticas.
y conocidas como integrales electrónicas, la cantidadcompletamente determinado. También puede utilizar fórmulas de Trotter - Suzuki de orden superior para reducir el error. Hay muchas otras técnicas de modelado hamiltonianas. Ejemplos de técnicas poderosas y sofisticadas son la cubitización [ aquí ] y el procesamiento de señales cuánticas [ver Ref. aquí ], que tienen una escala asintótica demostrablemente óptima, aunque no está claro si esto conducirá a mejores aplicaciones prácticas.
4. Problemas de optimización
Muchos problemas en biología computacional y otras disciplinas se pueden formular como encontrar el mínimo o máximo global de una función compleja y multidimensional. Por ejemplo, se cree que la estructura nativa de una proteína es el mínimo global de su hipersuperficie de energía libre [ver. aquí ]. En otra área, identificar grupos en una red de proteínas u objetos biológicos que interactúan es equivalente a encontrar un subconjunto óptimo de nodos [ver. aquí]. Desafortunadamente, con la excepción de algunos sistemas simples, los problemas de optimización suelen ser muy complejos. Aunque existen heurísticas para encontrar soluciones aproximadas, generalmente solo dan mínimos locales y, en muchos casos, incluso la heurística es indecidible. Se ha investigado en detalle la capacidad de las computadoras cuánticas para acelerar las soluciones a tales problemas de optimización o para encontrar mejores soluciones.
El tema de la optimización en una computadora cuántica es complejo porque a menudo no es obvio si una computadora cuántica puede proporcionar algún tipo de aceleración. En esta sección, proporcionaremos una descripción general de algunas de las ideas de optimización cuántica. Sin embargo, las garantías de mejora no son tan claras en comparación con, por ejemplo, la simulación cuántica, que se espera sea beneficiosa a largo plazo.
4.1. Optimización en un procesador cuántico
La optimización adiabática cuántica es uno de los enfoques de optimización más populares debido a la presencia de máquinas D-Wave [ver. aquí ] que inicialmente implementan este enfoque. La computación cuántica adiabática [ aquí ] se basa en el teorema adiabático de la mecánica cuántica [cf. aquí]. Según este teorema, si se prepara un sistema en el estado fundamental del hamiltoniano, y este hamiltoniano cambia con bastante lentitud, el sistema siempre permanecerá en su estado fundamental instantáneo. Esto se puede usar para realizar cálculos codificando un problema (como una función de puntuación que esperamos minimizar) como hamiltoniano, y evolucionando gradualmente hacia este hamiltoniano a partir de algún sistema original que se puede preparar trivialmente en su estado fundamental. En general, la evolución adiabática se expresa de la siguiente manera: Aquí

y - funciones tales que y durante un cierto tiempo T. Por ejemplo, podríamos considerar un programa de recocido lineal con y ... Se han dedicado muchos artículos a discutir el tiempo de ejecución del algoritmo adiabático, pero la heurística general es que el tiempo de ejecución es máximamente proporcional al cuadrado inverso de la brecha espectral mínima (la diferencia de energía más pequeña entre el suelo y los primeros estados excitados) durante la evolución adiabática.... Se cree que la computación cuántica adiabática (y la computación cuántica en general) no es capaz de resolver eficazmente la clase de problemas NP-completos, o al menos ninguno de estos métodos ha resistido pruebas rigurosas [ver Ref. aquí ].
En principio, la computación cuántica adiabática es equivalente a la computación cuántica universal [cf. aquí ]. Esta universalidad tiene lugar solo si la evolución permite la no estocasticidad, lo que significa que el hamiltoniano tiene elementos no negativos fuera de la diagonal en algún punto de la evolución. La implementación experimental más popular de la computación cuántica adiabática, comercializada por D-Wave Systems Inc., utiliza hamiltonianos estocásticos y, por tanto, no es universal. Existe cierta preocupación en la literatura profesional de que esta variedad de computación cuántica pueda simularse clásicamente [ aquí ], lo que significa que la aceleración exponencial podría no ser posible. A pesar de estas preocupaciones, esta técnica se ha utilizado ampliamente como técnica de optimización metaheurística y recientemente se ha demostrado que supera al recocido simulado [consulte la Ref. aquí ].
La optimización cuántica se ha estudiado fuera del modelo adiabático. El algoritmo de optimización cuántica aproximada e (QAOA) [cf. aquí , aquí y aquí] Es un algoritmo de optimización variacional en una computadora cuántica que ha generado un interés considerable en la literatura. Ha habido varias implementaciones experimentales de QAOA en procesadores cuánticos, por ejemplo, [ver. aquí ] Figura 3. FIGURA 3. (a) Simulación de una computadora cuántica adiabática que implementa el problema de plegamiento de proteínas simplificado descrito [ aquí ]. El color codifica la probabilidad logarítmica decimal de una cadena binaria en particular. Al final del cálculo, las dos soluciones de menor energía tienen una probabilidad de medición cercana a 0.5. La evolución nunca es completamente adiabática en un tiempo finito, y otras cadenas binarias tienen probabilidades residuales de medición. (segundo)

Descripción del proceso adiabático de la computación cuántica. El potencial que impulsa a los qubits cambia lentamente, lo que hace que giren. Tenga en cuenta que la representación de la esfera de Bloch está incompleta, ya que no muestra las correlaciones entre los diferentes qubits que se requieren para la ventaja cuántica. Al final de la evolución, el sistema de qubits se encuentra en un estado clásico (o una superposición de estados clásicos), lo que representa una solución con la energía más baja. (c) Niveles de energía durante la evolución cuántica adiabática. La cantidad de tiempo necesaria para garantizar la evolución cuasi adiabática está determinada por la diferencia de energía mínima entre los niveles, que se indica mediante la línea discontinua
4.2. Predicción de la estructura de proteínas
La predicción de la estructura de la proteína sin una matriz sigue siendo un gran problema sin resolver en biología computacional. La solución a este problema encontrará una amplia aplicación en la ingeniería molecular y el diseño de fármacos. Según la hipótesis del plegamiento de proteínas, la estructura nativa de una proteína se considera un mínimo global de su energía libre [ver. aquí ], aunque hay muchos contraejemplos. Dado el vasto espacio conformacional disponible incluso para péptidos pequeños, las simulaciones clásicas exhaustivas no son factibles. Sin embargo, muchos se preguntan si la computación cuántica puede ayudar a resolver este problema.
La literatura sobre computación cuántica se centra en el modelo de red de proteínas, donde un péptido se modela como una estructura de red autopropulsada, aunque recientemente se han comenzado a aplicar varios otros modelos en la práctica computacional [cf. aquí ]. Cada sitio de celosía corresponde a un residuo, y las interacciones entre los sitios espaciales vecinos contribuyen a la función energética. Hay varios esquemas de contacto de energía, pero solo dos se han utilizado en aplicaciones cuánticas: el modelo polar hidrofóbico [ver. aquí ], que considera sólo dos clases de aminoácidos, y el modelo Miyazawa-Jernigan [cf. aquí], que contiene interacciones para cada par de residuos. Si bien estos modelos son una simplificación marcada, han proporcionado información sustancial sobre el plegamiento de proteínas [ver Ref. aquí ] y se han propuesto como una herramienta burda para estudiar el espacio conformacional antes de un refinamiento más detallado [ver. aquí y aquí ].
Casi todo el trabajo se ha centrado en la computación cuántica adiabática, ya que incluso los péptidos modelo requieren una gran cantidad de qubits, y las máquinas cuánticas D-Wave son los dispositivos cuánticos más grandes disponibles en la actualidad.
Sin embargo, en un artículo publicado recientemente por Fingerhat y colegas [ver aquí] se intentó describir el uso del algoritmo QAOA. Ambos métodos tienen características similares si el problema de la red de proteínas se codifica como el operador de Hamilton. Este método fue considerado por primera vez por Perdomo [ver. aquí ], que sugirió usar un registro qubitpara codificar coordenadas cartesianas de N aminoácidos en una red cúbica de dimensión D con lados N. La función de energía se expresa en términos que contienen hamiltonianos para recompensar los contactos con proteínas: preservar la estructura primaria y evitar coincidencias de aminoácidos. Poco después de este artículo histórico, apareció otro artículo que discutía la construcción de modelos más eficientes en bits para una red bidimensional [ver. aquí ].
Estas codificaciones se probaron en hardware real en 2012 cuando Perdomo y sus colegas [ver. aquí] calculó la conformación de energía más baja del péptido PSVKMA en una máquina cuántica D-Wave. Recientemente, el grupo de investigación de Babay extendió las codificaciones de rotación y diamante para modelos 3D e introdujo mejoras algorítmicas que reducen la complejidad y velocidad de movimiento de la codificación de Hamilton [ver Ref. aquí ]. Utilizaron un procesador D-Wave 2000Q para determinar el estado fundamental de la higolina (10 residuos) en una red cuadrada y el triptófano (8 residuos) en una red cúbica, que son los péptidos más grandes investigados hasta la fecha. Estas implementaciones experimentales utilizan un método en el que se fija una parte del péptido. Esto permite introducir grandes problemas en una computadora cuántica debido a la posibilidad de investigación.el número de parámetros problemáticos estudiados.
Encontrar la conformación de energía más baja en el modelo de celosía es un problema NP difícil [ver. aquí y aquí ], lo que significa que bajo hipótesis estándar no existe un algoritmo clásico para resolver. Además, actualmente se cree que las computadoras cuánticas no pueden ofrecer una aceleración exponencial para problemas NP-completos y más complejos [cf. aquí ], aunque pueden ofrecer los beneficios del escalado, que se conocen en la literatura como "aceleración cuántica limitada" [cf. aquí]. Recientemente, el grupo de investigación de Outerel aplicó simulaciones numéricas para investigar este hecho, concluyendo que hay evidencia de aceleración cuántica limitada, aunque este resultado puede requerir máquinas adiabáticas que usen corrección de errores o simulaciones cuánticas en máquinas de propósito general tolerantes a fallas [cf. aquí ].
Aunque la mayor parte de la literatura se ha centrado en el modelo de red de proteínas, un artículo reciente [ aquí ] intentó usar el recocido cuántico para muestrear rotámeros en la función de energía de Rosetta [ver Ref. aquí ]. Los autores utilizaron el procesador D-Wave 2000Qpara encontrar una escala que parecía casi constante en comparación con el recocido simulado clásico. El grupo Marchand presentó un enfoque muy similar [véase. aquí ] para una selección de conformadores.
conclusiones
Una computadora cuántica puede almacenar y manipular grandes cantidades de información y ejecutar algoritmos a un ritmo exponencialmente más rápido que cualquier tecnología informática clásica. El potencial de incluso las pequeñas computadoras cuánticas puede superar fácilmente a las mejores supercomputadoras que existen en la actualidad, que al final, en el marco de ciertas tareas, pueden tener un efecto transformador para la biología computacional, prometiendo transferir problemas de la categoría de insoluble a difícil y complejo a la rutina. Se espera que los primeros procesadores cuánticos que pueden resolver problemas útiles aparezcan en la próxima década. Por lo tanto, comprender lo que las computadoras cuánticas pueden y no pueden hacer es una prioridad para todo científico computacional.
Aunque estamos entrando en la era de la computación cuántica práctica, ya podemos ver los contornos de una nueva biología computacional cuántica para las próximas décadas. Esperamos que esta revisión genere interés entre los biólogos computacionales por tecnologías que pronto puedan cambiar su campo de experimentación e investigación. Y los especialistas en computación cuántica, a su vez, podrán ayudar a los biólogos a desarrollar significativamente el nivel de biología computacional y bioinformática, de los cuales se esperan muchos resultados significativos para toda la humanidad.