Parte 2
Parte 3
En este artículo, aprenderá:
- Qué es el aprendizaje por transferencia y cómo funciona
- Qué es la segmentación semántica / de instancias y cómo funciona
- Acerca de qué es la detección de objetos y cómo funciona
Introducción
Hay dos métodos para las tareas de detección de objetos (consulte la fuente y más detalles aquí ):
- Métodos de dos etapas, también son "métodos basados en regiones" (ing. Métodos basados en regiones) - un enfoque dividido en dos etapas. En la primera etapa, las regiones de interés (RoI) se seleccionan mediante búsqueda selectiva o utilizando una capa especial de la red neuronal, regiones que contienen objetos con una alta probabilidad. En la segunda etapa, las regiones seleccionadas son consideradas por el clasificador para determinar la pertenencia a las clases originales y por el regresor, que especifica la ubicación de los cuadros delimitadores.
- Método de una sola etapa (métodos de una sola etapa en inglés): enfoque, sin usar un algoritmo separado para generar regiones, en lugar de predecir las coordenadas cierta cantidad de cuadros delimitadores con diferentes características, como los resultados de la clasificación y el grado de confianza, y ajustar aún más el marco de ubicación.
Este artículo analiza los métodos de un solo paso.
Transferir aprendizaje
El aprendizaje por transferencia es un método de entrenamiento de redes neuronales, en el que tomamos un modelo ya entrenado con algunos datos para un entrenamiento adicional adicional para resolver otro problema. Por ejemplo, tenemos un modelo EfficientNet-B5 entrenado en un conjunto de datos ImageNet (1000 clases). Ahora, en el caso más simple, cambiamos su última capa de clasificador (digamos, para clasificar objetos de 10 clases).
Eche un vistazo a la siguiente imagen:
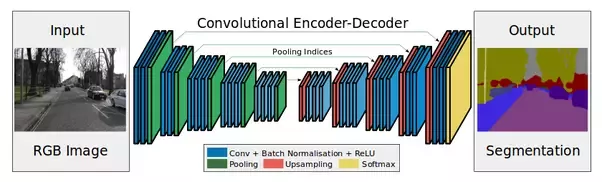
Codificador: son capas de submuestreo (convoluciones y agrupaciones).
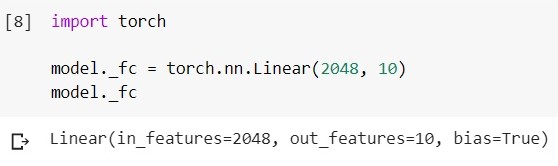
Reemplazar la última capa en el código se ve así (framework - pytorch, environment - google colab):
Cargue el modelo EfficientNet-b5 entrenado y observe su capa de clasificador:

Cambie esta capa a otra:
Se necesita decodificador, en particular, en la tarea de segmentación (sobre esto Más lejos).
Transferir estrategias de aprendizaje
Cabe agregar que, por defecto, todas las capas del modelo que queremos entrenar más son entrenables. Podemos "congelar" los pesos de algunas capas.
Para congelar todas las capas: cuantas

menos capas entrenemos, menos recursos informáticos necesitamos para entrenar el modelo. ¿Esta técnica siempre está justificada?
Dependiendo de la cantidad de datos sobre los que queramos entrenar la red, y de los datos sobre los que se entrenó la red, existen 4 opciones para el desarrollo de eventos para el aprendizaje de transferencia (en "poco" y "mucho" se puede tomar el valor condicional 10k):
- Usted tiene pocos datos , y es semejante a los datos en los que se ha entrenado la red antes. Puede intentar entrenar solo las últimas capas.
- , , . . , , , .. .
- , , . , .
- , , . .
Semantic segmentation
La segmentación semántica es cuando alimentamos una imagen en la entrada, y en la salida queremos obtener algo como esto:

Más formalmente, queremos clasificar cada píxel de nuestra imagen de entrada, para comprender a qué clase pertenece.
Aquí hay muchos enfoques y matices. ¿Cuál es solo la arquitectura de la red ResNeSt-269 :)
Intuición: en la entrada la imagen (h, w, c), en la salida queremos obtener una máscara (h, w) o (h, w, c), donde c es el número de clases (depende de datos y modelo). Agreguemos ahora un decodificador después de nuestro codificador y entreneémoslos.
El decodificador constará, en particular, de capas de muestreo superior. Puede aumentar la dimensión simplemente "estirando" nuestro mapa de características en altura y ancho en un paso u otro. Al tirar, puede utilizarinterpolación bilineal (en el código será solo uno de los parámetros del método).
Arquitectura de red Deeplabv3 +:
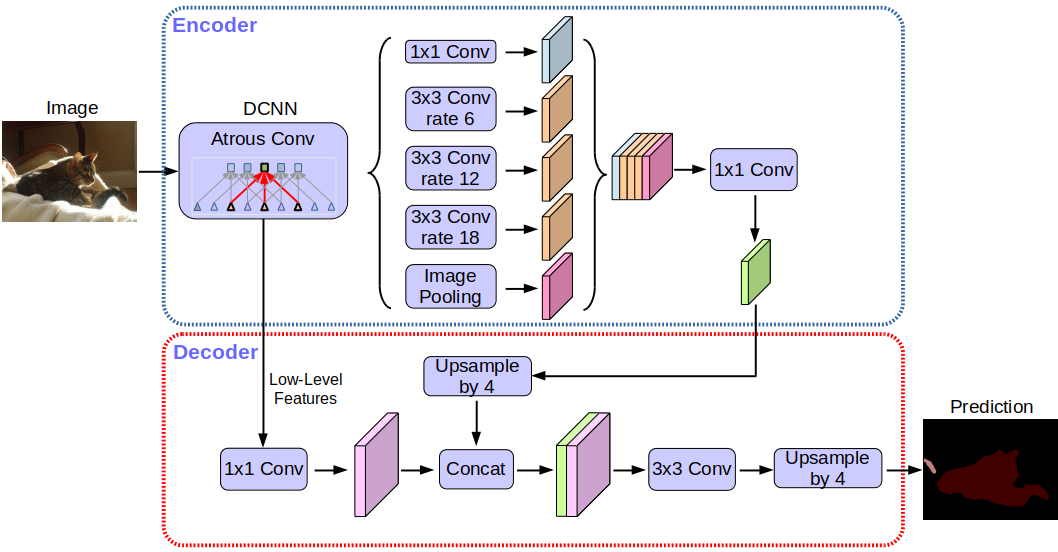
Sin entrar en detalles, notará que la red utiliza la arquitectura de codificador-decodificador.
Una versión más clásica, la arquitectura de la red U-net:
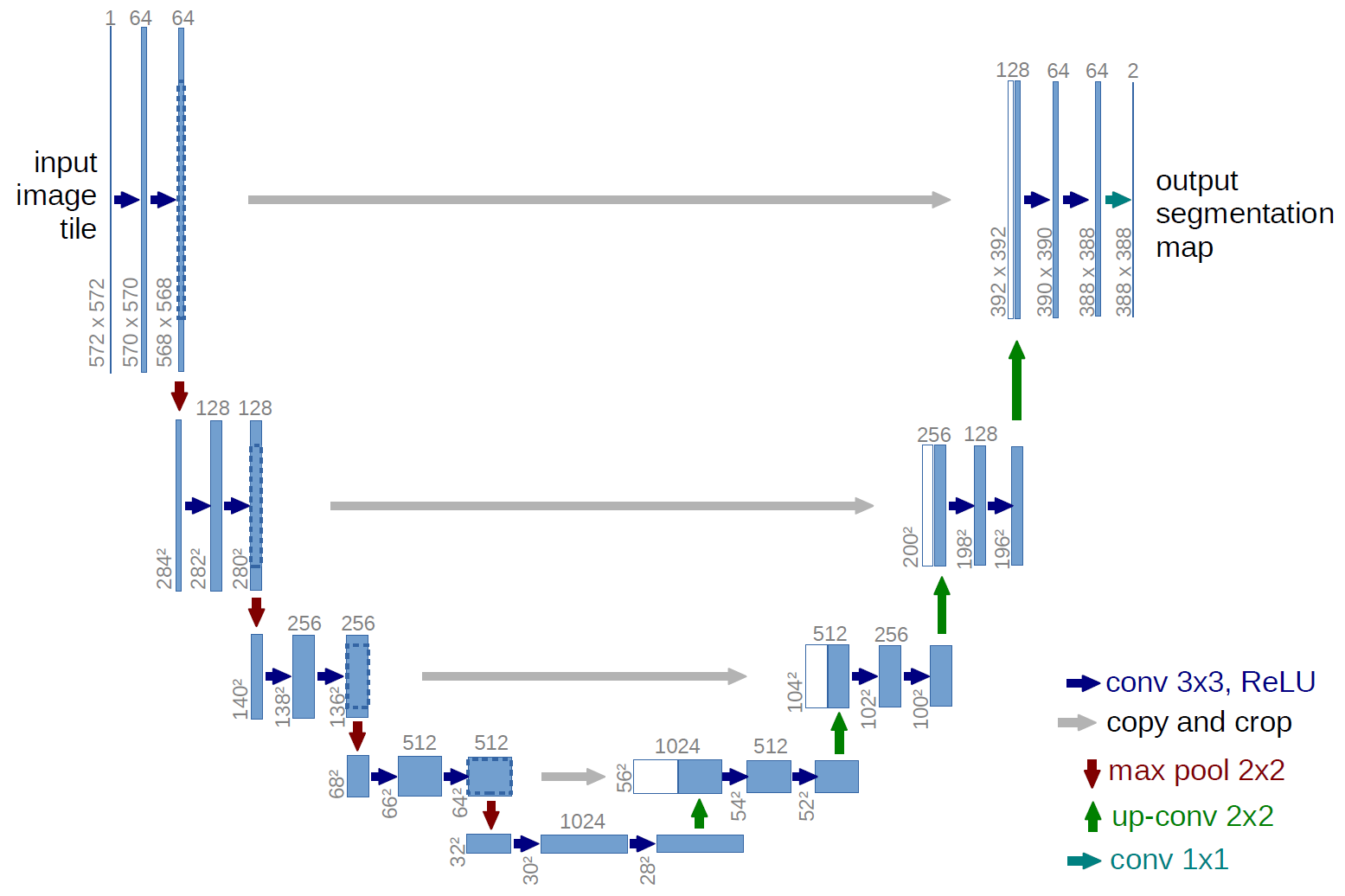
¿Qué son estas flechas grises? Estas son las llamadas conexiones de salto. El punto es que el codificador "codifica" nuestra imagen de entrada con pérdida. Para minimizar tales pérdidas, utilizan conexiones de salto.
En esta tarea, podemos usar el aprendizaje por transferencia; por ejemplo, podemos tomar una red con un codificador ya entrenado, agregar un decodificador y entrenarlo.
Sobre qué datos y qué modelos funcionan mejor en esta tarea en este momento, puede ver aquí...
Segmentación de instancias
Versión más compleja del problema de la segmentación. Su esencia es que queremos no solo clasificar cada píxel de la imagen de entrada, sino también seleccionar de alguna manera diferentes objetos de la misma clase:
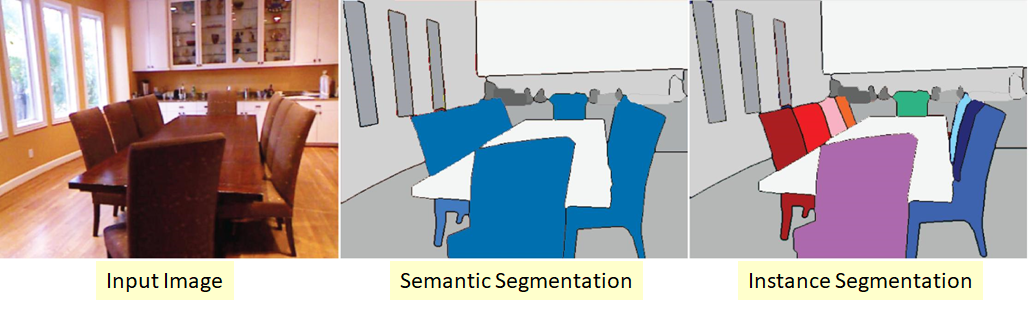
sucede que las clases son "pegajosas" o no hay un borde visible entre ellas, pero queremos delimitar objetos de la misma clase aparte.
También hay varios enfoques aquí. La más sencilla e intuitiva es que entrenamos dos redes diferentes. Enseñamos el primero a clasificar píxeles para algunas clases (segmentación semántica), y el segundo, a clasificar píxeles entre objetos de clase. Conseguimos dos máscaras. Ahora podemos restar el segundo del primero y obtener lo que queríamos :)
Sobre qué datos y qué modelos funcionan mejor en esta tarea en este momento - puede ver aquí...
Object detection
Enviamos una imagen a la entrada, y en la salida queremos ver algo como:

Lo más intuitivo que se puede hacer es “correr” sobre la imagen con diferentes rectángulos y, usando un clasificador ya entrenado, determinar si hay un objeto de interés para nosotros en esta área. Existe tal esquema, pero obviamente no es el mejor. Tenemos capas convolucionales que de alguna manera interpretan el mapa de características "antes" (A) en el mapa de características "después" (B). En este caso, conocemos las dimensiones de los filtros de convolución => sabemos qué píxeles de A a qué píxeles B se convirtieron.
Echemos un vistazo a YOLO v3:
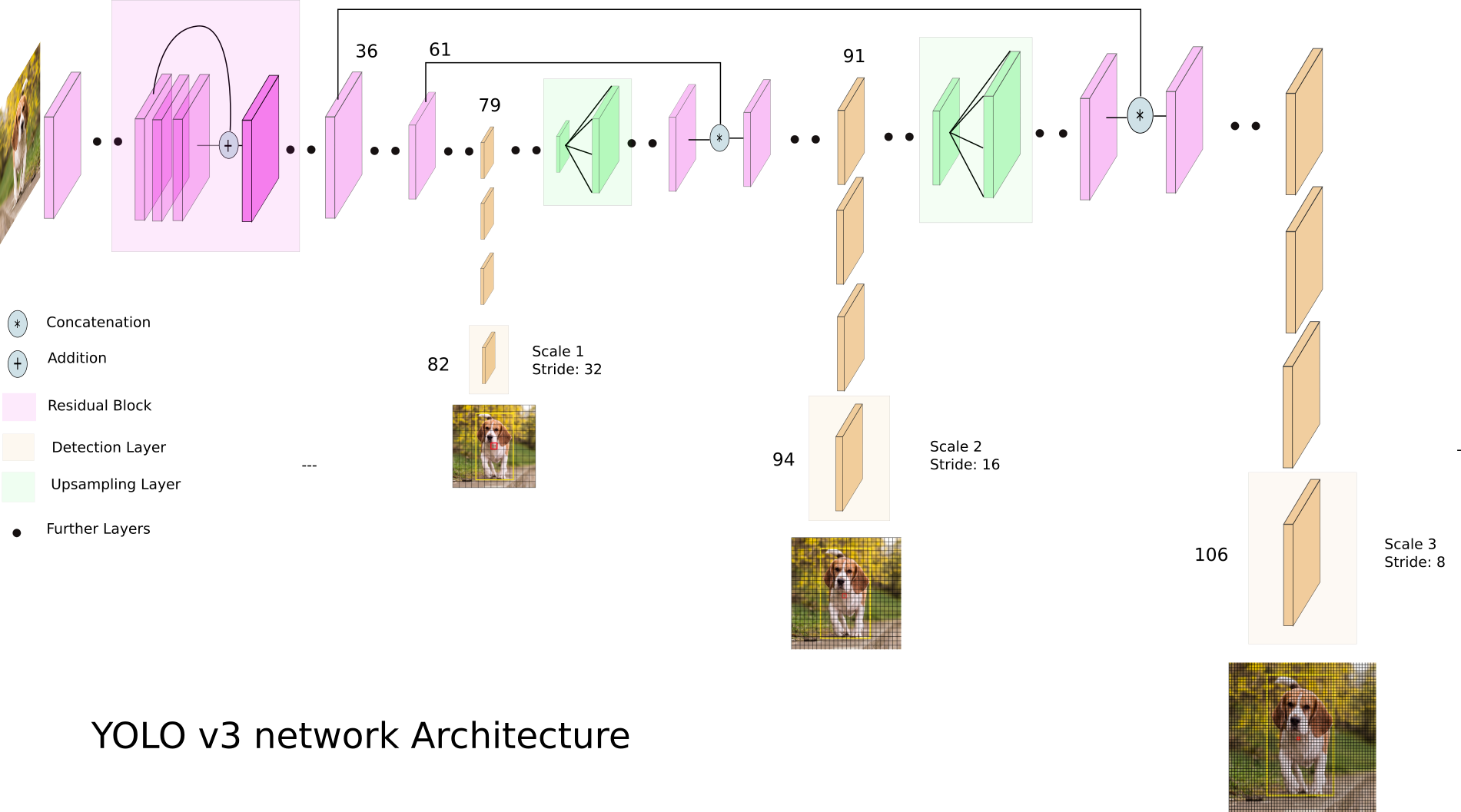
YOLO v3 utiliza mapas de características de diferentes dimensiones. Esto se hace, en particular, para detectar correctamente objetos de diferentes tamaños.
A continuación, se concatenan las tres escalas:
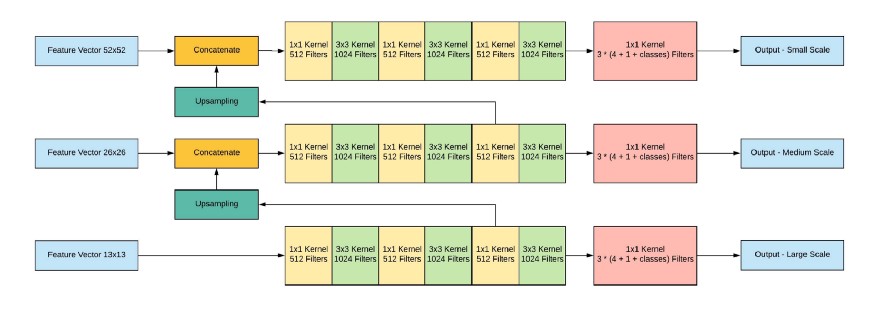
Salida de red, con una imagen de entrada de 416x416, 13x13x (B * (5 + C)), donde C es el número de clases, B es el número de cajas para cada región (YOLO v3 tiene 3 de ellas). 5 - estos son parámetros tales como: Px, Py - coordenadas del centro del objeto, Ph, Pw - altura y ancho del objeto, Pobj - la probabilidad de que el objeto esté en esta región.
Echemos un vistazo a la imagen, por lo que será un poco más claro:

YOLO filtra los datos de predicción inicialmente por puntuación de objetividad por algún valor (generalmente 0,5-0,6), y luego por supresión no máxima .
Sobre qué datos y qué modelos funcionan mejor en esta tarea en este momento, puede ver aquí .
Conclusión
Hay muchos modelos y enfoques diferentes para las tareas de segmentación y localización de objetos en estos días. Hay ciertas ideas, entendiendo las cuales, será más fácil desmontar ese zoológico de modelos y enfoques. Intenté expresar estas ideas en este artículo.
En los próximos artículos, hablaremos sobre transferencias de estilo y GAN.