"Reducir la velocidad de los programas es mucho más rápido que acelerar las computadoras"
Desde entonces, esta declaración se ha considerado la ley de Wirth . Efectivamente niega la Ley de Moore, que establece que el número de transistores en los procesadores se ha duplicado desde aproximadamente 1965. Esto es lo que Wirth escribe en su artículo "Call for Slim Software" :
“Hace unos 25 años, un editor de texto interactivo tenía solo 8000 bytes y un compilador de 32 kilobytes, mientras que sus descendientes modernos requieren megabytes. ¿Todo este software inflado se ha vuelto más rápido? No, todo lo contrario. Si no fuera por un hardware mil veces más rápido, el software moderno sería completamente inutilizable ".
Es difícil no estar de acuerdo con esto.
Software de obesidad
El problema de desarrollar software moderno es muy agudo. Wirth señala un aspecto importante: el tiempo. Sugiere que la razón principal del software inflado es la falta de tiempo de desarrollo.
Hoy en día existe otra razón para la obesidad en el software: la abstracción. Y este es un problema mucho más grave. Los desarrolladores nunca han escrito programas desde cero, pero esto nunca antes fue un problema.
Dijkstra y Wirth intentaron mejorar la calidad del código y desarrollaron el concepto de programación estructurada. Querían sacar la programación de la crisis y, durante algún tiempo, la programación se consideró un verdadero oficio para los verdaderos profesionales. Los programadores se preocuparon por la calidad de los programas, apreciaron la claridad y eficiencia del código.
Esos días se acabaron.
Con el surgimiento de lenguajes de alto nivel como Java, Ruby, PHP y Javascript, la programación se volvió más abstracta en 1995 cuando Wirth escribió su artículo. Los nuevos lenguajes hicieron que la programación fuera mucho más fácil y asumió mucho. Estaban orientados a objetos y venían incluidos con cosas como IDE y recolección de basura.
La vida se ha vuelto más fácil para los programadores, pero todo tiene un precio. Cuanto más fácil es vivir, menos pensar. Alrededor de mediados de los 90, los programadores dejaron de pensar en la calidad de sus programas, escribe el desarrollador Robin Martin en su artículo "Niklaus Wirth tenía razón, y ese es el problema" . Al mismo tiempo, comenzó el uso generalizado de bibliotecas, cuya funcionalidad siempre es mucho más de lo necesario para un programa en particular.
Dado que la biblioteca no está diseñada para un proyecto en particular, probablemente tenga un poco más de funcionalidad de la que realmente necesita. No hay problema, dices. Sin embargo, las cosas se acumulan bastante rápido. Incluso las personas que aman las bibliotecas no quieren reinventar la rueda. Esto conduce a lo que se llama el infierno de la dependencia. Nicola Duza escribió una publicación sobre este tema en Javascript .
Puede que el problema no parezca gran cosa, pero en realidad es más grave de lo que piensas. Por ejemplo, Nikola Dusa escribió una aplicación de lista de tareas sencilla. Funciona en su navegador con HTML y Javascript. ¿Cuántas dependencias crees que usó? 13 000. Trece. Mil. Prueba .
Los números son una locura, pero el problema solo crecerá. A medida que se crean nuevas bibliotecas, también aumentará el número de dependencias en cada proyecto.
Esto significa que el problema sobre el que advirtió Niklaus Wirth en 1995 solo empeorará con el tiempo.
¿Qué hacer?
Robin Martin sugiere que una buena forma de empezar es dividir las bibliotecas. En lugar de construir una gran biblioteca que haga lo mejor que pueda, simplemente cree muchas bibliotecas.
Así, el programador solo tiene que seleccionar las librerías que realmente necesita, ignorando la funcionalidad que no va a utilizar. No solo instala menos dependencias, sino que las bibliotecas utilizadas también tendrán menos dependencias.
Fin de la ley de Moore
Desafortunadamente, la miniaturización de los transistores no puede durar para siempre y tiene sus límites físicos. Quizás tarde o temprano la Ley de Moore dejará de operar. Algunos dicen que esto ya sucedió. En los últimos diez años, la velocidad de reloj y la potencia de los núcleos de procesadores individuales ya han dejado de crecer como solían hacerlo.
Aunque es demasiado pronto para enterrarlo. Hay una serie de nuevas tecnologías que prometen reemplazar la microelectrónica de silicio. Por ejemplo, Intel, Samsung y otras empresas están experimentando con transistores basados en nanoestructuras de carbono (nanofilamentos) y chips fotónicos.

Evolución de transistores. Ilustración: Samsung
Pero algunos investigadores adoptan un enfoque diferente. Proponen nuevos enfoques de programación de sistemas para mejorar drásticamente la eficiencia del software futuro. Por lo tanto, es posible "reiniciar" la ley de Moore mediante métodos de programa, sin importar lo fantástico que suene a la luz de las observaciones de Nicklaus Wirth sobre la obesidad del programa. Pero, ¿y si podemos revertir esta tendencia?
Técnicas de aceleración de software
Recientemente, Science publicó un interesante artículo de científicos del Laboratorio de Ciencias de la Computación e Inteligencia Artificial del Instituto de Tecnología de Massachusetts (CSAIL MIT). Destacan tres áreas prioritarias para acelerar aún más el cálculo:
- el mejor software;
- nuevos algoritmos;
- hardware más optimizado.
El autor principal del artículo de investigación Charles Leiserson confirma la tesis de la obesidad en el software . Él dice que los beneficios de miniaturizar los transistores han sido tan grandes que durante décadas, los programadores han podido priorizar hacer que el código sea más fácil de escribir en lugar de acelerar la ejecución. La ineficiencia podría tolerarse porque los chips de computadora más rápidos siempre compensan la obesidad del software.
“Pero hoy en día, los avances adicionales en áreas como el aprendizaje automático, la robótica y la realidad virtual requerirán una enorme potencia informática que la miniaturización ya no puede proporcionar”, dice Leiserson. "Si queremos aprovechar todo el potencial de estas tecnologías, debemos cambiar nuestro enfoque de la informática".
En la parte de software, se propone reconsiderar la estrategia de utilizar librerías con excesiva funcionalidad, porque esta es una fuente de ineficiencia. Los autores recomiendan concentrarse en la tarea principal: aumentar la velocidad de ejecución del programa y no en la velocidad de escritura del código.
En muchos casos, el rendimiento se puede aumentar miles de veces, y esto no es exagerado. Como ejemplo, los investigadores citan la multiplicación de dos matrices de 4096 × 4096. Comenzaron con la implementación en Python como uno de los lenguajes de alto nivel más populares. Por ejemplo, aquí hay una implementación de cuatro líneas en Python 2:
for i in xrange(4096):
for j in xrange(4096):
for k in xrange(4096):
C[i][j] += A[i][k] * B[k][j]El código tiene tres bucles anidados y el algoritmo de solución se basa en el plan de estudios de álgebra de la escuela.
Pero resulta que este enfoque ingenuo es demasiado ineficaz para la potencia informática. En una computadora moderna, funcionará durante aproximadamente siete horas, como se muestra en la siguiente tabla.
| Versión | Implementación | Tiempo de ejecución (s) | GFLOPS | Aceleración absoluta | Aceleración relativa | Porcentaje de rendimiento máximo |
|---|---|---|---|---|---|---|
| 1 | Pitón | 25552.48 | 0,005 | 1 | - | 0,00 |
| 2 | Java | 2372,68 | 0,058 | once | 10,8 | 0,01 |
| 3 | C | 542,67 | 0,253 | 47 | 4.4 | 0,03 |
| 4 | Bucles paralelos | 69,80 | 1,97 | 366 | 7.8 | 0,24 |
| cinco | Paradigma de dividir y conquistar | 3,80 | 36,18 | 6727 | 18,4 | 4.33 |
| 6 | + vectorización | 1,10 | 124,91 | 23224 | 3,5 | 14,96 |
| 7 | + intrística AVX | 0,41 | 337,81 | 52806 | 2,7 | 40,45 |
La transición a un lenguaje de programación más eficiente ya aumenta drásticamente la velocidad de ejecución del código. Por ejemplo, un programa Java se ejecutará 10,8 veces más rápido y un programa C otras 4,4 veces más rápido que Java. Por lo tanto, cambiar de Python a C significa una ejecución del programa 47 veces más rápida.
Y este es solo el comienzo de la optimización. Si escribe el código teniendo en cuenta las peculiaridades del hardware en el que se ejecutará, puede aumentar la velocidad otras 1300 veces. En este experimento, el código se ejecutó primero en paralelo en los 18 núcleos de CPU (versión 4), luego usamos la jerarquía de caché del procesador (versión 5), agregamos vectorización (versión 6) y aplicamos instrucciones específicas de Advanced Vector Extensions (AVX) en la versión 7. La última versión optimizada el código tarda solo 0,41 segundos, no 7 horas, es decir, más de 60.000 veces más rápido que el código Python original.
Es más, en una tarjeta gráfica AMD FirePro S9150, el mismo código se ejecuta en solo 70 ms, 5.4 veces más rápido que la versión 7 más optimizada en un procesador de propósito general y 360,000 veces más rápido que la versión 1.
En términos de algoritmos, los investigadores proponen un enfoque de tres frentes que implica explorar nuevas áreas problemáticas, escalar los algoritmos y adaptarlos para aprovechar mejor el hardware moderno.
Por ejemplo, el algoritmo de Strassen para la multiplicación de matrices en un 10% adicional acelera la versión más rápida del número de código 7. Para otros problemas, los nuevos algoritmos proporcionan una ganancia de rendimiento aún mayor. Por ejemplo, el siguiente diagrama muestra el progreso realizado en la eficiencia de los algoritmos para resolver el problema de flujo máximo entre 1975 y 2015. Cada nuevo algoritmo aumentó la velocidad computacional literalmente en varios órdenes de magnitud, y en los años siguientes se optimizó aún más.
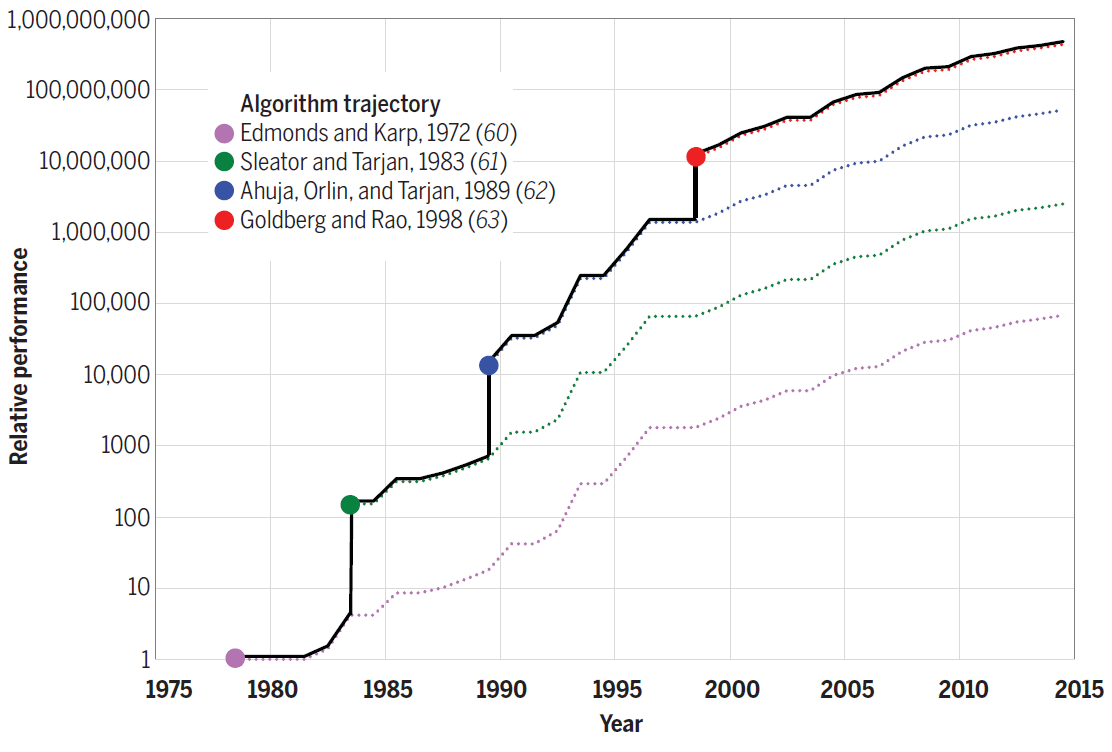
Eficiencia de los algoritmos para resolver el problema del flujo máximo en un gráfico con n = 10 12 vértices y m = n 11 aristas
Por lo tanto, la mejora de los algoritmos también contribuye a "emular" la ley de Moore mediante programación.
Finalmente, en términos de arquitectura de hardware, los investigadores abogan por optimizar el hardware para que los problemas puedan resolverse con menos transistores. La optimización implica el uso de procesadores más simples y la creación de hardware adaptado a aplicaciones específicas, como la GPU está adaptada para gráficos por computadora.
“Los equipos adaptados a áreas específicas pueden ser mucho más eficientes y utilizar muchos menos transistores, lo que permite que las aplicaciones se ejecuten decenas o cientos de veces más rápido”, dice Tao Schardl, coautor del artículo de investigación. "De manera más general, la optimización de hardware estimulará aún más la programación paralela al crear áreas adicionales en el chip para uso paralelo".
La tendencia hacia la paralelización ya es visible. Como se muestra en el diagrama, en los últimos años, el rendimiento de la CPU ha aumentado únicamente debido al aumento en la cantidad de núcleos.
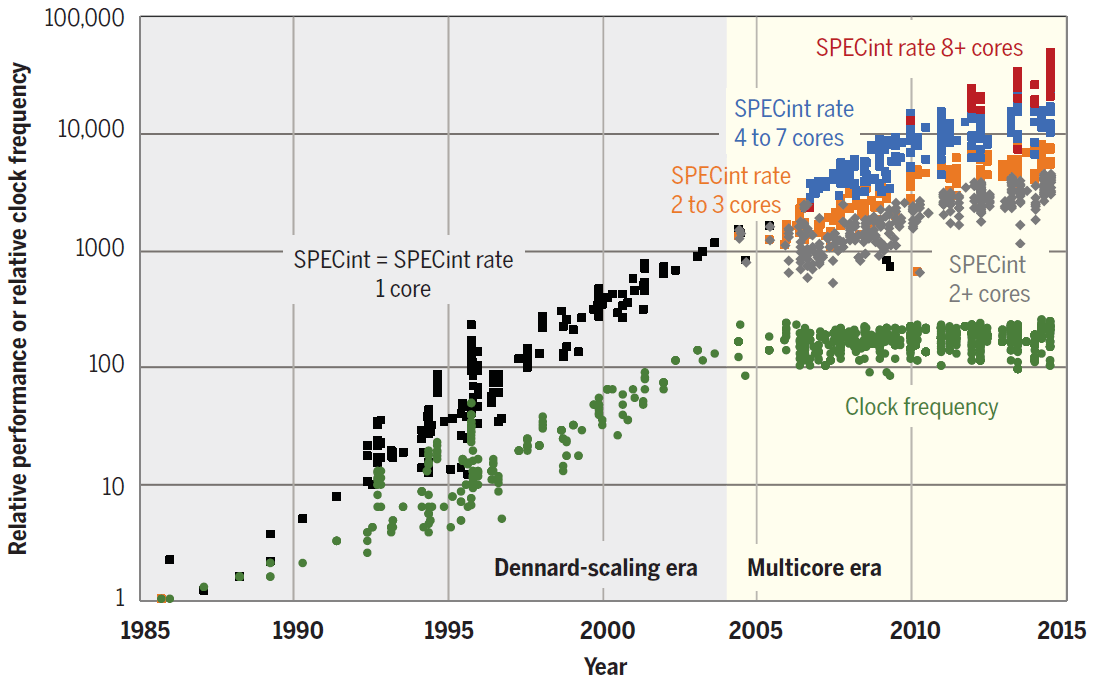
SPECint rendimiento de núcleos individuales y procesadores de uno y varios núcleos de 1985 a 2015. La unidad base es un microprocesador 80386 DX 1985
Para los operadores de centros de datos, incluso la mejora más pequeña en el rendimiento del software puede traducirse en grandes ganancias financieras. No es sorprendente que empresas como Google y Amazon estén liderando iniciativas para desarrollar sus propias CPU especializadas. Los primeros procesadores tensor (neuronales) de TPU de Google lanzados y los chips AWS Graviton se están ejecutando en los centros de datos de Amazon .
Con el tiempo, los líderes de la industria pueden ser seguidos por los propietarios de otros centros de datos, para no perder eficiencia frente a los competidores.
Los investigadores escriben que en el pasado, las explosivas ganancias de rendimiento en los procesadores de propósito general han limitado el alcance para el desarrollo de procesadores especializados. Ahora no existe tal limitación.
“Las ganancias de productividad requerirán nuevas herramientas, lenguajes de programación y hardware para permitir un diseño más eficiente teniendo en cuenta la velocidad”, dijo el profesor Charles Leiserson, coautor de la investigación. "También significa que los programadores deben comprender mejor cómo encajan el software, los algoritmos y el hardware, en lugar de mirarlos de forma aislada".
Por otro lado, los ingenieros están experimentando con tecnologías que pueden mejorar aún más el rendimiento de la CPU. Estos son la computación cuántica, el diseño 3D, los microcircuitos superconductores, la computación neuromórfica, el uso de grafeno en lugar de silicio, etc. Pero hasta ahora estas tecnologías se encuentran en la etapa de experimentos.
Si el rendimiento de la CPU realmente deja de crecer, entonces nos encontraremos en una realidad completamente diferente. Quizás realmente tengamos que reconsiderar nuestras prioridades de programación, y los especialistas en ensambladores valdrán su peso en oro.
Publicidad
¿Necesita un servidor potente ? Nuestra empresa ofrece servidores épicos: servidores virtuales con CPU AMD EPYC, frecuencia del núcleo de la CPU de hasta 3,4 GHz. La configuración máxima impresionará a cualquiera: 128 núcleos de CPU, 512 GB de RAM, 4000 GB de NVMe.
