
Foto del sitio web de Unsplash . Autor: Hitesh Choudhary
Obtener el mismo resultado en Python que con una consulta SQL
A menudo, cuando trabajamos en el mismo proyecto, tenemos que cambiar entre SQL y Python. Dicho esto, algunos de nosotros estamos familiarizados con la manipulación de datos en consultas SQL, pero no en Python, lo que dificulta nuestra eficiencia y productividad. De hecho, al usar Pandas, puede lograr el mismo resultado en Python que en las consultas SQL.
Inicio de obra
Necesita instalar el paquete Pandas si no está allí.
conda install pandasUsaremos el famoso Titanic Dataset de Kaggle .
Después de instalar el paquete y descargar los datos, debemos importarlo a nuestro entorno Python.

Usaremos un DataFrame para almacenar datos. Varias funciones de Pandas nos ayudarán a administrar esta estructura de datos.
SELECT, DISTINCT, COUNT, LIMIT
Comencemos con consultas SQL simples que usamos mucho.
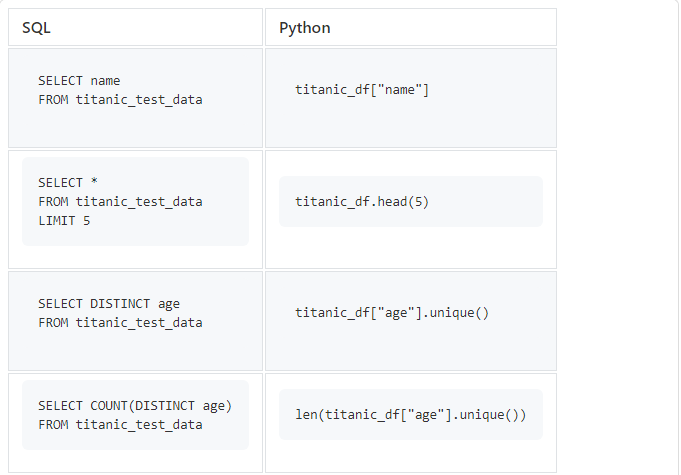
titanic_df["age"].unique()devolverá una matriz de valores únicos, por lo que tendremos que usar len()para contar su número.
SELECT, WHERE, OR, AND, IN (SELECT con condiciones)
Después de la primera parte, aprendió a explorar un DataFrame de forma sencilla. Ahora intentemos hacerlo con algunas condiciones (esta es una declaración
WHEREen SQL).

Si solo queremos seleccionar columnas específicas del DataFrame, podemos hacerlo con un par adicional de corchetes.
Nota: si selecciona varias columnas, debe colocar la matriz
["name","age"]entre corchetes.
isin()funciona exactamente igual que INen las consultas SQL. Para usar NOT IN, en Python necesitamos usar la negación (~).
AGRUPAR POR, ORDENAR POR, CONTAR
GROUP BYy ORDER BYtambién son declaraciones SQL populares para la minería de datos. Ahora intentemos usarlos en Python.

Si queremos ordenar solo una columna COUNT, simplemente podemos pasar un valor booleano al método
sort_values. Si vamos a ordenar varias columnas, entonces debemos pasar una matriz de valores booleanos al método sort_values.
El método
sum()devolverá las sumas para cada una de las columnas en el DataFrame, que se pueden agregar numéricamente. Si solo queremos una columna específica, entonces necesitamos especificar el nombre de la columna usando corchetes.
MIN, MAX, MEDIA, MEDIA
Finalmente, probemos algunas de las funciones estadísticas estándar que son importantes al explorar datos.
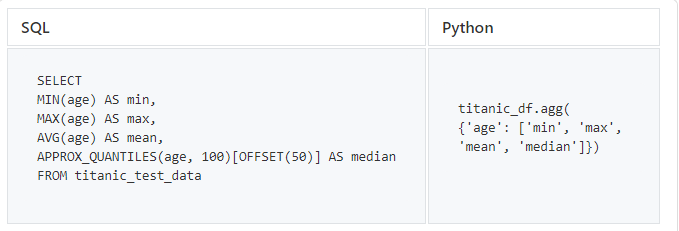
SQL no contiene operadores que devuelvan el valor mediano, por lo que usamos BigQuery para obtener el valor mediano de la columna de edad. En
APPROX_QUANTILES
Pandas, el método de agregación
.agg()también admite otras funciones, por ejemplo sum.
Ahora ha aprendido a reescribir consultas SQL en Python usando Pandas . Espero que encuentre útil este artículo.
Todo el código se puede encontrar en mi repositorio de Github .
¡Gracias por su atención!